Recognition: unknown
Spatiotemporal Convolutions on EEG signal -- A Representation Learning Perspective on Efficient and Explainable EEG Classification with Convolutional Neural Nets
Pith reviewed 2026-05-07 16:15 UTC · model grok-4.3
The pith
2D spatiotemporal convolutions reduce training time on high-dimensional EEG data while maintaining performance and creating distinct representational geometries compared with concatenated 1D convolutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
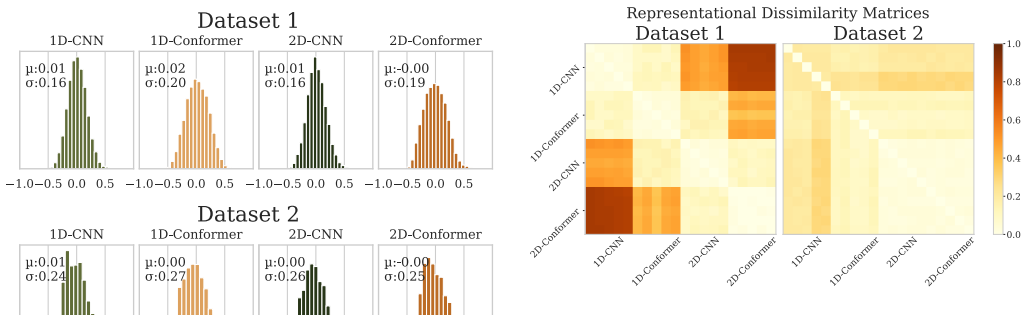
2D convolutions significantly reduce training time in high-dimensional tasks while maintaining performance and yield vastly different representational geometries than 1D models.
Load-bearing premise
That the observed difference in representational similarity and training time is caused by the convolution dimensionality rather than by other unstated differences in model capacity or optimization.
Figures


read the original abstract
Classification of EEG signals using shallow Convolutional Neural Networks (CNNs) is a prevalent and successful approach across a variety of fields. Most of these models use independent one-dimensional (1D) convolutional layers along the spatial and temporal dimensions, which are concatenated without a non-linear activation layer between. In this paper, we investigate an alternative encoding that operates a bi-dimensional (2D) spatiotemporal convolution. While 2D convolutions are numerically identical to two concatenated 1D convolutions along the two dimensions, the impact on learning is still uncertain. We test 1D and 2D CNNs and a CNN+transformer hybrid model in a low-dimensional (3-channel) and a high-dimensional (22-channel) BCI motor imagery classification task. We observe that 2D convolutions significantly reduce training time in high-dimensional tasks while maintaining performance. We investigate the root of this improvement and find no difference in spectral feature importance. However, a clear pattern emerges in representational similarity across models: 1D and 2D models yield vastly different representational geometries. Overall, we suggest an improved model with a 2D convolutional layer for faster training and inference. We also highlight the importance of architecturally-driven encoding when processing complex multivariate signals, as reflected in internal representations rather than purely in performance metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares 1D and 2D convolutional layers in shallow CNNs (and a CNN+transformer hybrid) for EEG-based motor imagery classification on low-dimensional (3-channel) and high-dimensional (22-channel) BCI datasets. It asserts that 2D spatiotemporal convolutions are numerically identical to concatenated 1D temporal-then-spatial convolutions without intervening activations, yet observes that 2D models reduce training time in high-dimensional tasks while preserving accuracy, produce distinct representational geometries (via similarity analysis), and show no difference in spectral feature importance. The authors recommend 2D convolutions for efficiency and emphasize architecturally driven encoding effects visible in internal representations.
Significance. If the empirical patterns hold after correcting the architectural premise, the work would usefully illustrate how convolution dimensionality influences optimization speed and learned representations in multivariate time-series tasks, beyond raw accuracy. The representational similarity analysis is a positive element that moves discussion past performance metrics alone. However, the absence of error bars, statistical tests, and controlled capacity comparisons limits the strength of the efficiency and geometry claims.
major comments (3)
- [Abstract] Abstract and introduction: the repeated claim that '2D convolutions are numerically identical to two concatenated 1D convolutions along the two dimensions' is incorrect. The composition of independent 1D temporal and 1D spatial convolutions yields only rank-1 (separable) effective kernels, whereas a general 2D kernel can realize non-separable space-time filters. This expressivity gap means the observed differences in training time and representational geometry cannot be unambiguously attributed to 'spatiotemporal encoding' or dimensionality per se; they may simply reflect the greater capacity of the 2D model. The central recommendation for 2D layers therefore rests on an unexamined premise.
- [Results] Experimental section (results on high-dimensional task): no error bars, no statistical significance tests, and no description of data splits, cross-validation procedure, or hyperparameter search are reported. Without these, the claims of 'maintaining performance' and 'significantly reduce training time' cannot be evaluated reliably, especially given the reader's note on partial support for the performance and geometry observations.
- [Representational similarity analysis] Representational similarity analysis: the assertion of 'vastly different representational geometries' between 1D and 2D models requires quantitative controls for the capacity difference identified above (e.g., matching effective kernel rank or parameter count). Without such controls, it is unclear whether the geometry divergence is caused by the convolution type or by the architectural mismatch.
minor comments (3)
- Clarify the precise 1D and 2D model architectures, including kernel sizes, whether any non-linearity is placed between the temporal and spatial 1D layers, and how the 2D kernel is initialized and regularized.
- Provide details on the CNN+transformer hybrid architecture and its relative performance to isolate the contribution of the convolutional front-end.
- Add a brief discussion of how the 2D model could be made parameter-matched to the 1D baseline (e.g., via depthwise-separable 2D convolutions) to strengthen the causal attribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which has helped us clarify key distinctions in our work and strengthen the experimental reporting. We address each major comment below, with revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract] the repeated claim that '2D convolutions are numerically identical to two concatenated 1D convolutions along the two dimensions' is incorrect. The composition of independent 1D temporal and 1D spatial convolutions yields only rank-1 (separable) effective kernels, whereas a general 2D kernel can realize non-separable space-time filters. This expressivity gap means the observed differences in training time and representational geometry cannot be unambiguously attributed to 'spatiotemporal encoding' or dimensionality per se; they may simply reflect the greater capacity of the 2D model.
Authors: We acknowledge the imprecision in our original statement. Sequential 1D convolutions without an intervening non-linearity are indeed equivalent to separable (rank-1) 2D kernels, while standard 2D convolutions support non-separable filters and thus greater expressivity. We have revised the abstract and introduction to correct this description, explicitly noting the capacity difference and that observed efficiency gains and representational distinctions may partly stem from it. The empirical benefits for high-dimensional EEG tasks remain, and we now frame the recommendation around both efficiency and the ability to learn joint spatiotemporal patterns. revision: yes
-
Referee: [Results] no error bars, no statistical significance tests, and no description of data splits, cross-validation procedure, or hyperparameter search are reported. Without these, the claims of 'maintaining performance' and 'significantly reduce training time' cannot be evaluated reliably.
Authors: We agree that the experimental details were incomplete. The revised manuscript now reports error bars (standard deviation over multiple random seeds), includes statistical significance tests (paired t-tests on accuracy and training time), and fully describes the data splits (following BCI competition subject-specific protocols), cross-validation procedure, and hyperparameter search. These additions support reliable evaluation of the performance and efficiency claims. revision: yes
-
Referee: [Representational similarity analysis] the assertion of 'vastly different representational geometries' between 1D and 2D models requires quantitative controls for the capacity difference identified above (e.g., matching effective kernel rank or parameter count). Without such controls, it is unclear whether the geometry divergence is caused by the convolution type or by the architectural mismatch.
Authors: We accept the need for capacity controls. In the revision we add experiments that match parameter counts between 1D and 2D models (by scaling filter numbers) and include comparisons to explicitly separable 2D kernels. The representational similarity analysis still indicates distinct geometries linked to the spatiotemporal convolution choice, which we now discuss with these controls in place. revision: yes
Circularity Check
No significant circularity; experimental comparison on external benchmarks
full rationale
The paper conducts direct empirical tests of 1D vs. 2D CNN architectures (plus a hybrid) on standard BCI motor-imagery datasets, measuring training time, accuracy, spectral importance, and representational similarity via independent metrics. No derivation chain reduces claims to fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes smuggled from prior author work. The central observations about representational geometries and training-time differences are obtained from the experiments themselves rather than from any self-referential construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- network depth, width, and learning-rate schedule
axioms (1)
- domain assumption Convolutional layers with identical receptive fields extract comparable features regardless of whether they are factored into 1D or kept as 2D.
Reference graph
Works this paper leans on
-
[1]
An automated system for epilepsy detection using EEG brain signals based on deep learning approach,
I. Ullah, M. Hussain, E.-u.-H. Qazi, and H. Aboalsamh, “An automated system for epilepsy detection using EEG brain signals based on deep learning approach,” vol. 107, pp. 61–71
-
[2]
A novel deep learning approach for classifi- cation of EEG motor imagery signals,
Y . R. Tabar and U. Halici, “A novel deep learning approach for classifi- cation of EEG motor imagery signals,”Journal of Neural Engineering, vol. 14, no. 1, p. 016003, Nov. 2016
2016
-
[3]
EEG-based deep learning model for the automatic detection of clinical depression,
P. P. Thoduparambil, A. Dominic, and S. M. Varghese, “EEG-based deep learning model for the automatic detection of clinical depression,” Physical and Engineering Sciences in Medicine, vol. 43, no. 4, pp. 1349– 1360, December 2020
2020
-
[4]
Performance Analysis of Deep Learning Models for Detection of Autism Spectrum Disorder from EEG Signals,
M. Radhakrishnan, K. Ramamurthy, K. K. Choudhury, D. Won, and T. A. Manoharan, “Performance Analysis of Deep Learning Models for Detection of Autism Spectrum Disorder from EEG Signals,”Traitement du Signal, vol. 38, no. 3, pp. 853–863, June 2021
2021
-
[5]
Deep learning-based EEG analysis to classify normal, mild cognitive impairment, and dementia: Algorithms and dataset,
M.-j. Kim, Y . C. Youn, and J. Paik, “Deep learning-based EEG analysis to classify normal, mild cognitive impairment, and dementia: Algorithms and dataset,”NeuroImage, vol. 272, p. 120054, May 2023
2023
-
[6]
SleepTransformer: Automatic Sleep Staging With Interpretability and Uncertainty Quantification,
H. Phan, K. Mikkelsen, O. Y . Ch´en, P. Koch, A. Mertins, and M. De V os, “SleepTransformer: Automatic Sleep Staging With Interpretability and Uncertainty Quantification,”IEEE Transactions on Biomedical Engi- neering, vol. 69, no. 8, pp. 2456–2467, August 2022
2022
-
[7]
Brain decoding: Toward real-time reconstruction of visual perception,
Y . Benchetrit, H. Banville, and J.-R. King, “Brain decoding: Toward real-time reconstruction of visual perception,” March 2024
2024
-
[8]
A Survey on Deep Learning based Brain Computer Interface: Recent Advances and New Frontiers,
X. Zhang, L. Yao, X. Wang, J. Monaghan, D. McAlpine, and Y . Zhang, “A Survey on Deep Learning based Brain Computer Interface: Recent Advances and New Frontiers,”Journal of Neural Engineering, vol. 1, no. 1, 2016
2016
-
[9]
Deep learning with convolutional neural networks for EEG decoding and visualization,
R. T. Schirrmeister, J. T. Springenberg, L. D. J. Fiederer, M. Glasstetter, K. Eggensperger, M. Tangermann, F. Hutter, W. Burgard, and T. Ball, “Deep learning with convolutional neural networks for EEG decoding and visualization,”Human Brain Mapping, vol. 38, no. 11, pp. 5391– 5420, 2017
2017
-
[10]
EEGNet: A Compact Convolutional Network for EEG-based Brain-Computer Interfaces,
V . J. Lawhern, A. J. Solon, N. R. Waytowich, S. M. Gordon, C. P. Hung, and B. J. Lance, “EEGNet: A Compact Convolutional Network for EEG-based Brain-Computer Interfaces,”Journal of Neural Engineering, vol. 15, no. 5, p. 056013, October 2018
2018
-
[11]
EEG Conformer: Convolutional Transformer for EEG Decoding and Visualization,
Y . Song, Q. Zheng, B. Liu, and X. Gao, “EEG Conformer: Convolutional Transformer for EEG Decoding and Visualization,”IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 31, pp. 710– 719, 2023
2023
-
[12]
Peeling the Onion of Brain Representations,
N. Kriegeskorte and J. Diedrichsen, “Peeling the Onion of Brain Representations,”Annual Review of Neuroscience, vol. 42, pp. 407–432
-
[13]
A Shared Vision for Machine Learning in Neuroscience,
M.-A. T. Vu, T. Adalı, D. Ba, G. Buzs ´aki, D. Carlson, K. Heller, C. Liston, C. Rudin, V . S. Sohal, A. S. Widge, H. S. Mayberg, G. Sapiro, and K. Dzirasa, “A Shared Vision for Machine Learning in Neuroscience,”Journal of Neuroscience, vol. 38, no. 7, pp. 1601–1607
-
[14]
Relational inductive biases, deep learning, and graph networks,
P. W. Battaglia, J. B. Hamrick, V . Bapst, A. Sanchez-Gonzalez, V . Zambaldi, M. Malinowski, A. Tacchetti, D. Raposo, A. Santoro, R. Faulkner, C. Gulcehre, F. Song, A. Ballard, J. Gilmer, G. Dahl, A. Vaswani, K. Allen, C. Nash, V . Langston, C. Dyer, N. Heess, D. Wierstra, P. Kohli, M. Botvinick, O. Vinyals, Y . Li, and R. Pascanu, “Relational inductive b...
-
[15]
Relational inductive biases, deep learning, and graph networks
[Online]. Available: http://arxiv.org/abs/1806.01261
work page internal anchor Pith review arXiv
-
[16]
Electroencephalog- raphy Signal Processing: A Comprehensive Review and Analysis of Methods and Techniques,
A. Chaddad, Y . Wu, R. Kateb, and A. Bouridane, “Electroencephalog- raphy Signal Processing: A Comprehensive Review and Analysis of Methods and Techniques,”Sensors (Basel, Switzerland), vol. 23, no. 14, p. 6434, July 2023
2023
-
[17]
Emotion Recognition based on EEG using LSTM Recurrent Neural Network,
S. Alhagry, A. Aly, and R. A., “Emotion Recognition based on EEG using LSTM Recurrent Neural Network,”International Journal of Advanced Computer Science and Applications, vol. 8, no. 10, 2017
2017
-
[18]
Zhang and L
X. Zhang and L. Yao,Deep Learning for EEG-Based Brain-Computer Interfaces: Representations, Algorithms and Applications. WORLD SCIENTIFIC (EUROPE), October 2021
2021
-
[19]
Epileptic Seizure Detection Based on EEG Signals and CNN,
M. Zhou, C. Tian, R. Cao, B. Wang, Y . Niu, T. Hu, H. Guo, and J. Xiang, “Epileptic Seizure Detection Based on EEG Signals and CNN,”Frontiers in Neuroinformatics, vol. 12, December 2018
2018
-
[20]
EEG Emotion Recognition Using Dynamical Graph Convolutional Neural Networks,
T. Song, W. Zheng, P. Song, and Z. Cui, “EEG Emotion Recognition Using Dynamical Graph Convolutional Neural Networks,”IEEE Trans- actions on Affective Computing, vol. 11, no. 3, pp. 532–541, July 2020
2020
-
[21]
Cross-Subject EEG Emotion Recognition With Self-Organized Graph Neural Network,
J. Li, S. Li, J. Pan, and F. Wang, “Cross-Subject EEG Emotion Recognition With Self-Organized Graph Neural Network,”Frontiers in Neuroscience, vol. 15, June 2021
2021
-
[22]
Goodfellow, Y
I. Goodfellow, Y . Bengio, and A. Courville,Deep Learning. MIT Press, 2016
2016
-
[23]
MOABB: Trustworthy algorithm bench- marking for BCIs,
V . Jayaram and A. Barachant, “MOABB: Trustworthy algorithm bench- marking for BCIs,”Journal of Neural Engineering, vol. 15, no. 6, p. 066011, September 2018
2018
-
[24]
Review of the BCI Competition IV,
M. Tangermann, K.-R. M ¨uller, A. Aertsen, N. Birbaumer, C. Braun, C. Brunner, R. Leeb, C. Mehring, K. J. Miller, G. R. M ¨uller-Putz, G. Nolte, G. Pfurtscheller, H. Preissl, G. Schalk, A. Schl¨ogl, C. Vidaurre, S. Waldert, and B. Blankertz, “Review of the BCI Competition IV,” Frontiers in Neuroscience, vol. 6, p. 55, 2012
2012
-
[25]
MEG and EEG data analysis with MNE-Python,
A. Gramfort, “MEG and EEG data analysis with MNE-Python,”Fron- tiers in Neuroscience, vol. 7, 2013
2013
-
[26]
What is the fast Fourier transform?
W. Cochran, J. Cooley, D. Favin, H. Helms, R. Kaenel, W. Lang, G. Maling, D. Nelson, C. Rader, and P. Welch, “What is the fast Fourier transform?”Proceedings of the IEEE, vol. 55, no. 10, pp. 1664–1674, October 1967
1967
-
[27]
Representational similarity analysis - connecting the branches of systems neuroscience,
N. Kriegeskorte, M. Mur, and P. A. Bandettini, “Representational similarity analysis - connecting the branches of systems neuroscience,” Frontiers in Systems Neuroscience, vol. 2, November 2008
2008
-
[28]
Similarity of Neural Network Representations Revisited,
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, “Similarity of Neural Network Representations Revisited,” inProceedings of the 36th International Conference on Machine Learning. PMLR, May 2019, pp. 3519–3529
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.