Recognition: unknown
Beyond Rules: LLM-Powered Linting for Quantum Programs
Pith reviewed 2026-05-07 03:41 UTC · model grok-4.3
The pith
Large language models with targeted prompting and knowledge retrieval detect quantum programming problems more accurately than rule-based linting tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that LLM-based linting methods called LintQ-LLM+CoT and LintQ-LLM+RAG, which apply chain-of-thought prompting and retrieval-augmented generation grounded in a knowledge base of quantum problems and best practices, outperform the existing rule-based tool LintQ. On a corpus of 55 Qiskit programs the LLM approaches achieved higher correctness and completeness in identifying quantum programming problems, with the RAG variant further lowering incorrect detections.
What carries the argument
The central mechanisms are chain-of-thought prompting, which forces the LLM to reason through quantum-specific constraints step by step, and retrieval-augmented generation, which supplies the model with verified examples from a curated knowledge base before it analyzes new code.
If this is right
- Quantum programming problems that depend on context or span multiple API calls become detectable without writing new static rules for each change.
- The retrieval-augmented variant reduces the number of false positives that waste developer time compared with ungrounded prompting.
- Maintenance effort shifts from updating rule sets to curating and expanding the underlying knowledge base of quantum practices.
- The same LLM foundation can serve as the starting point for linters that also explain detected issues to developers.
Where Pith is reading between the lines
- The same prompting and retrieval pattern could be applied to linting in other rapidly evolving domains such as machine-learning pipelines or smart-contract languages.
- Embedding these LLM checks inside quantum development environments would allow problems to be flagged while the programmer is still writing the code rather than after compilation.
- Cross-framework testing on code written for Cirq, Q#, or other quantum SDKs would show whether the advantage generalizes beyond the Qiskit programs used in the study.
- Over time the curated knowledge base itself could become a living reference that captures community-agreed quantum best practices.
Load-bearing premise
The manual evaluation performed on 55 Qiskit programs gives an unbiased and representative picture of how the methods would behave across the full range of quantum programs and as quantum APIs continue to evolve.
What would settle it
A larger, independently assembled collection of quantum programs drawn from multiple frameworks and API versions that shows rule-based linting matching or exceeding the LLM approaches in both precision and recall would falsify the central claim.
Figures




read the original abstract
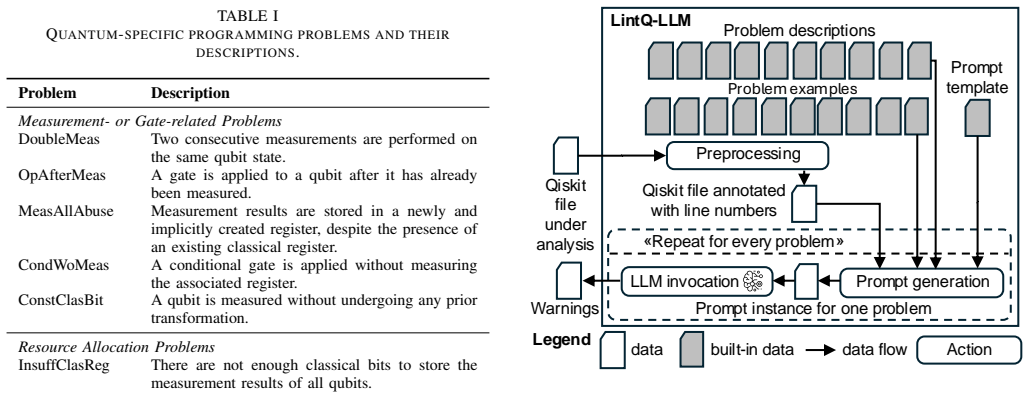
As quantum computing transitions from theoretical experimentation to its practical application, the reliability of quantum software has become a critical bottleneck. Traditional static analysis techniques for quantum programs, primarily rule-based linters, are increasingly inadequate; they struggle to keep pace with rapidly evolving APIs and fail to capture complex, context-dependent quantum programming problems. This results in high maintenance overhead and limited detection capabilities. In this paper, we introduce LintQ-LLM+CoT and LintQ-LLM+RAG, novel approaches that redefine the detection of quantum programming problems by employing Large Language Models (LLMs) specialized, respectively, via Chain-of-Thought (CoT) prompting and a Retrieval-Augmented Generation (RAG) system that grounds the model's reasoning in a curated knowledge base of verified quantum programming problems and best practices. We conducted a rigorous and manual comparative evaluation against the state-of-the-art rule-based tool, LintQ, using a corpus of 55 Qiskit programs. Our results show that LLM-based approaches, with and without RAG, outperform LintQ in terms of quantum programming problems detection correctness (precision) and completeness (recall). Overall, LLM-based approaches were more effective than LintQ (F1-score equal to 0.70 and 0.68 vs. 0.41). Furthermore, the RAG-enhanced variant demonstrated a slightly superior precision, effectively reducing false positives. Our findings suggest that LLMs provide a scalable and adaptive foundation for the next generation of linters in quantum software engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LintQ-LLM+CoT and LintQ-LLM+RAG, LLM-based linting approaches for quantum programs that use Chain-of-Thought prompting and Retrieval-Augmented Generation over a curated knowledge base. It reports a manual evaluation on a fixed corpus of 55 Qiskit programs in which the LLM variants achieve F1 scores of 0.70 and 0.68, outperforming the rule-based baseline LintQ (F1 = 0.41), and concludes that LLM-powered methods provide a more effective, adaptive solution for detecting context-dependent and API-evolution-related quantum programming problems.
Significance. If the performance advantage is shown to be robust, the work would be significant for quantum software engineering. It directly addresses the well-known limitations of static rule-based linters in a domain with rapidly changing APIs and subtle, context-sensitive bugs, and supplies concrete empirical evidence that LLM augmentation can improve both precision and recall on real Qiskit code. The RAG variant’s modest precision gain is also noteworthy as a practical engineering insight.
major comments (1)
- [Evaluation] Evaluation section (and abstract): The headline F1 comparison (0.70/0.68 vs. 0.41) rests entirely on human judgments of true/false positives produced by the three tools on the 55-program corpus. The manuscript supplies no sampling protocol, no stratification by program size or problem category, no description of how ground-truth labels were obtained, and no inter-rater agreement statistic. Because these details are load-bearing for the central empirical claim, the reported superiority cannot yet be assessed for reproducibility or generalizability.
minor comments (2)
- [Abstract] The abstract states that the evaluation is 'rigorous' yet omits the methodological details required to substantiate that adjective; a one-sentence summary of labeling and agreement procedures would strengthen the abstract without lengthening it appreciably.
- [Results] Table or figure presenting per-problem-type precision/recall would make the claim that LLM methods handle 'complex, context-dependent' issues more transparent; currently the aggregate F1 scores are the only quantitative result shown.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address the single major comment point by point below and will revise the manuscript to strengthen the reporting of our evaluation methodology.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (and abstract): The headline F1 comparison (0.70/0.68 vs. 0.41) rests entirely on human judgments of true/false positives produced by the three tools on the 55-program corpus. The manuscript supplies no sampling protocol, no stratification by program size or problem category, no description of how ground-truth labels were obtained, and no inter-rater agreement statistic. Because these details are load-bearing for the central empirical claim, the reported superiority cannot yet be assessed for reproducibility or generalizability.
Authors: We appreciate the referee highlighting the need for greater transparency in our evaluation protocol. The 55 Qiskit programs form a fixed corpus assembled specifically to cover a range of quantum programming issues (including context-dependent and API-evolution-related problems) rather than being drawn as a sample from a larger population; consequently, no sampling protocol or stratification by program size or problem category was performed. Ground-truth labels for true and false positives were established through manual review of each tool output against the source code and established quantum programming practices by the authors. We did not compute a formal inter-rater agreement statistic. In the revised manuscript we will expand the Evaluation section with a dedicated subsection that (i) describes the corpus construction and selection criteria, (ii) details the ground-truth labeling process, (iii) explains the decision not to apply sampling or stratification, and (iv) states the labeling consistency measures employed. We will also ensure the abstract references this expanded description. These additions will directly address the concerns about reproducibility and generalizability while preserving the original empirical results. revision: yes
Circularity Check
No circularity: direct empirical comparison on fixed corpus
full rationale
The paper reports an empirical evaluation of two LLM-based linting approaches (LintQ-LLM+CoT and LintQ-LLM+RAG) against the rule-based LintQ tool. Performance is measured via precision, recall, and F1-score computed from manual labeling of detections on a fixed corpus of 55 Qiskit programs. No equations, fitted parameters, or derivations appear in the abstract or described methodology. The central claim (LLM approaches achieve F1 0.70/0.68 vs. 0.41) is a direct reporting of observed counts on that corpus rather than any self-referential reduction, self-citation load-bearing premise, or ansatz smuggled via prior work. Potential limitations in corpus sampling or inter-rater reliability affect external validity but do not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The corpus of 55 Qiskit programs is representative of typical quantum programming problems and API usage patterns.
- domain assumption The manual identification of quantum programming problems provides accurate and unbiased ground truth.
Reference graph
Works this paper leans on
-
[1]
I. Quantum. (2024) Qiskit: An open-source framework for quantum computing. [Online]. Available: https://qiskit.org/
2024
-
[2]
Analyzing quantum programs with lintq: A static analysis framework for qiskit,
M. Paltenghi and M. Pradel, “Analyzing quantum programs with lintq: A static analysis framework for qiskit,” inProceedings of the ACM on Software Engineering, vol. 1, no. FSE, 2024, pp. 2144–2166
2024
-
[3]
Quantum program linting with llms: Emerging results from a comparative study,
S. Y . Shin, F. Pastore, and D. Bianculli, “Quantum program linting with llms: Emerging results from a comparative study,” in2025 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 02, 2025, pp. 181–186
2025
-
[4]
Qdiff: Differential testing of quantum software stacks,
J. Wang, Q. Zhang, G. H. Xu, and M. Kim, “Qdiff: Differential testing of quantum software stacks,” in36th IEEE/ACM International Conference on Automated Software Engineering, 2021
2021
-
[5]
Morphq: Metamorphic testing of the qiskit quantum computing platform,
M. Paltenghi and M. Pradel, “Morphq: Metamorphic testing of the qiskit quantum computing platform,” inProceedings of the 45th International Conference on Software Engineering, 2023
2023
-
[6]
Fuzz4all: Universal fuzzing with large language models,
C. S. Xia, M. Paltenghi, J. L. Tian, M. Pradel, and L. Zhang, “Fuzz4all: Universal fuzzing with large language models,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024
2024
-
[7]
Is your quantum program bug-free?
A. Miranskyy, L. Zhang, and J. Doliskani, “Is your quantum program bug-free?”Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering: New Ideas and Emerging Results, 2020
2020
-
[8]
Assessing the effectiveness of input and output coverage criteria for testing quantum programs,
S. Ali, P. Arcaini, X. Wang, and T. Yue, “Assessing the effectiveness of input and output coverage criteria for testing quantum programs,” in 14th IEEE Conference on Software Testing, Verification and Validation, 2021
2021
-
[9]
Poster: Fuzz testing of quantum program,
J. Wang, F. Ma, and Y . Jiang, “Poster: Fuzz testing of quantum program,” in14th IEEE Conference on Software Testing, Verification and Validation, 2021
2021
-
[10]
Statistical assertions for validating patterns and finding bugs in quantum programs,
Y . Huang and M. Martonosi, “Statistical assertions for validating patterns and finding bugs in quantum programs,” inProceedings of the 46th International Symposium on Computer Architecture, 2019
2019
-
[11]
Projection- based runtime assertions for testing and debugging quantum programs,
G. Li, L. Zhou, N. Yu, Y . Ding, M. Ying, and Y . Xie, “Projection- based runtime assertions for testing and debugging quantum programs,” Proceedings of the ACM on Programming Languages, vol. 4, no. OOPSLA, 2020
2020
-
[12]
The smelly eight: An empirical study on the prevalence of code smells in quantum computing,
Q. Chenet al., “The smelly eight: An empirical study on the prevalence of code smells in quantum computing,” inProceedings of the 45th IEEE/ACM International Conference on Software Engineering, 2023, pp. 358–370
2023
-
[13]
Qchecker: Detecting bugs in quantum programs via static analysis,
P. Zhao, X. Wu, Z. Li, and J. Zhao, “Qchecker: Detecting bugs in quantum programs via static analysis,” inProceedings of the 4th IEEE/ACM International Workshop on Quantum Software Engineering, 2023, pp. 50–57
2023
-
[14]
A uniform representation of clas- sical and quantum source code for static code analysis,
M. Kaul, A. K ¨uchler, and C. Banse, “A uniform representation of clas- sical and quantum source code for static code analysis,” inProceedings of the 2023 IEEE International Conference on Quantum Computing and Engineering, 2023, pp. 1013–1019
2023
-
[15]
QL: Object- oriented queries on relational data,
P. Avgustinov, O. de Moor, M. P. Jones, and M. Sch ¨afer, “QL: Object- oriented queries on relational data,” in30th European Conference on Object-Oriented Programming (ECOOP 2016). Schloss Dagstuhl– Leibniz-Zentrum fuer Informatik, 2016, pp. 2:1–2:25
2016
-
[16]
Prompt optimization cookbook,
OpenAI, “Prompt optimization cookbook,” 2025. [On- line]. Available: https://developers.openai.com/cookbook/examples/ gpt-5/prompt-optimization-cookbook
2025
-
[17]
Text embedding 3 large: Model card,
——, “Text embedding 3 large: Model card,” 2024. [Online]. Available: https://developers.openai.com/api/docs/models/text-embedding-3-large
2024
-
[18]
How to count tokens with tiktoken,
——, “How to count tokens with tiktoken,” 2022. [On- line]. Available: https://cookbook.openai.com/examples/how to count tokens with tiktoken
2022
-
[19]
M. Douze, A. Guzhva, C. Deng, J. Johnson, G. Szilvasy, P.-E. Mazar ´e, M. Lomeli, L. Hosseini, and H. J ´egou, “The faiss library,” 2025. [Online]. Available: https://arxiv.org/abs/2401.08281
work page internal anchor Pith review arXiv 2025
-
[20]
Assessing dependability with software fault injection: A survey,
R. Natella, D. Cotroneo, and H. S. Madeira, “Assessing dependability with software fault injection: A survey,”ACM Comput. Surv., 2016
2016
-
[21]
Replication package,
“Replication package,” 2026. [Online]. The repository link will be made publicly available upon acceptance
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.