Recognition: 2 theorem links
Transformers with Selective Access to Early Representations
Pith reviewed 2026-05-08 18:06 UTC · model grok-4.3
The pith
SATFormer improves Transformer performance by using a learned gate for selective access to early-layer representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SATFormer preserves the first-layer value pathway while controlling access with a context-dependent gate, consistently improving validation loss and zero-shot accuracy over static value-residual and Transformer baselines, with strongest gains of approximately 1.5 average points on retrieval-intensive benchmarks.
What carries the argument
Context-dependent gate that selectively modulates access to the first-layer value projection V_1
Load-bearing premise
A learned context-dependent gate will discover and exploit varying needs for early representation access without harming efficiency or generalization.
What would settle it
Train identical models with the gate replaced by a fixed uniform coefficient or random values and check whether the performance advantage on retrieval benchmarks disappears.
Figures





read the original abstract
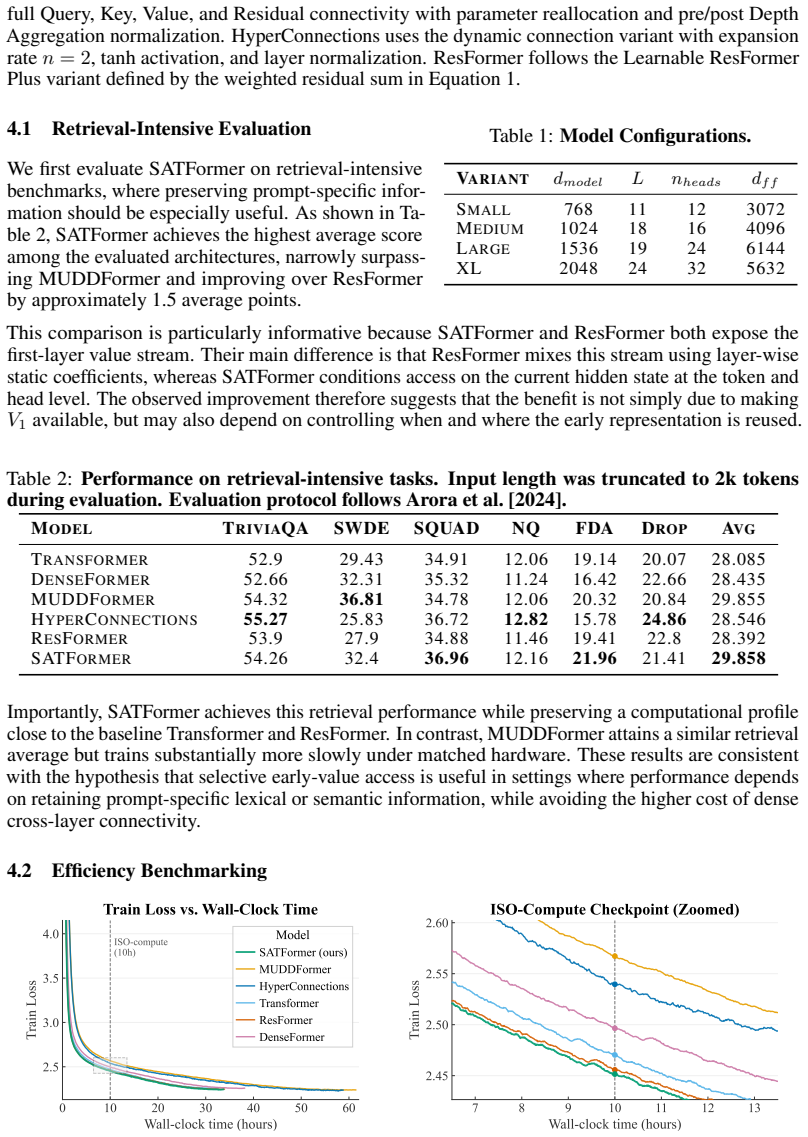
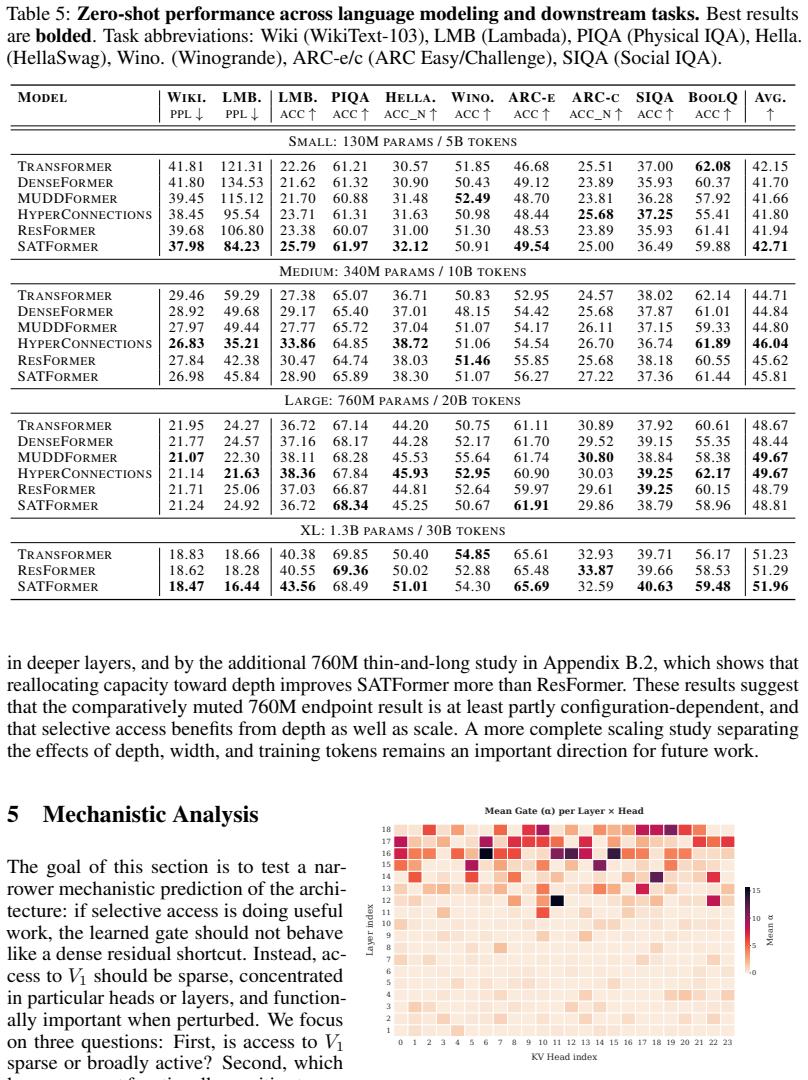
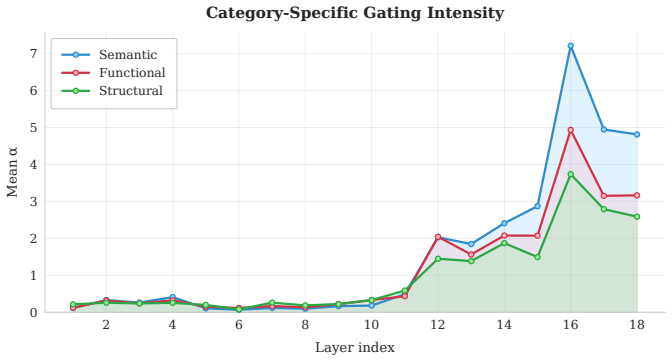
Several recent Transformer architectures expose later layers to representations computed in the earliest layers, motivated by the observation that low-level features can become harder to recover as the residual stream is repeatedly transformed through depth. The cheapest among these methods add static value residuals: learned mixing coefficients that expose the first-layer value projection V_1 uniformly across tokens and heads. More expressive dense or dynamic alternatives recover finer-grained access, but at higher memory cost and lower throughput. The usefulness of V_1 is unlikely to be constant across tokens, heads, and contexts; different positions plausibly require different amounts of access to early lexical or semantic information. We therefore treat early-representation reuse as a retrieval problem rather than a connectivity problem, and introduce Selective Access Transformer (SATFormer), which preserves the first-layer value pathway while controlling access with a context-dependent gate. Across models from 130M to 1.3B parameters, SATFormer consistently improves validation loss and zero-shot accuracy over the static value-residual and Transformer baselines. Its strongest gains appear on retrieval-intensive benchmarks, where it improves over static value residuals by approximately 1.5 average points, while maintaining throughput and memory usage close to the baseline Transformer. Gate analyses suggest sparse, depth-dependent, head-specific, and category-sensitive access patterns, supporting the interpretation that SATFormer learns selective reuse of early representations rather than uniform residual copying. Our code is available at https://github.com/SkyeGunasekaran/SATFormer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Selective Access Transformer (SATFormer), which augments Transformers by preserving the first-layer value projection V_1 while controlling access via a learned context-dependent gate. It reports consistent gains in validation loss and zero-shot accuracy over both standard Transformer and static value-residual baselines across 130M–1.3B parameter scales, with the largest improvements (~1.5 points) on retrieval-intensive benchmarks, while maintaining comparable throughput and memory. Gate analyses are presented as evidence of sparse, depth-dependent, head-specific, and category-sensitive access patterns.
Significance. If the reported gains prove robust, the work provides a lightweight, retrieval-oriented alternative to static or dense early-representation reuse in Transformers, directly addressing the hypothesis that low-level features become harder to recover with depth. The public code release is a clear strength for reproducibility. The selective-gate design and accompanying analyses offer a plausible mechanistic interpretation that could inform future work on depth-dependent sparsity.
major comments (2)
- [Abstract / Experiments] Abstract and experimental results: the headline claim of consistent ~1.5-point gains on retrieval benchmarks (and smaller gains elsewhere) is presented without error bars, standard deviations across seeds, or multi-run statistics. Zero-shot retrieval metrics are known to fluctuate several points across independent trainings; without this information it is impossible to determine whether the observed deltas exceed training variance and therefore whether the central empirical claim holds.
- [§3 / §4] §3 (architecture) and §4 (experiments): the precise parameterization of the context-dependent gate (input features, activation, output dimensionality, and how it modulates the V_1 pathway) is described at a high level but lacks the level of detail needed to reproduce the exact implementation from the text alone. Because the gate is the novel component whose selectivity is being claimed, this detail is load-bearing for verifying both the efficiency claims and the mechanistic analyses.
minor comments (2)
- [Tables / Figures] Table captions and figure legends should explicitly state the number of seeds or runs underlying each reported number; this is a minor but important clarity fix.
- [Abstract] The abstract states that throughput and memory remain 'close to the baseline Transformer,' but no quantitative numbers (tokens/s, peak memory) are given in the abstract itself; a single sentence with the measured deltas would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our work. We address each major comment below and have revised the manuscript to strengthen the presentation of results and reproducibility.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental results: the headline claim of consistent ~1.5-point gains on retrieval benchmarks (and smaller gains elsewhere) is presented without error bars, standard deviations across seeds, or multi-run statistics. Zero-shot retrieval metrics are known to fluctuate several points across independent trainings; without this information it is impossible to determine whether the observed deltas exceed training variance and therefore whether the central empirical claim holds.
Authors: We agree that the lack of error bars and multi-run statistics weakens the ability to assess whether the reported gains exceed typical training variance, especially for zero-shot metrics. In the revised manuscript we have added results from three independent random seeds for the primary experiments (130M and 1.3B scales), reporting means and standard deviations for validation loss and zero-shot accuracies in both the abstract and §4. The gains on retrieval benchmarks remain consistent across seeds and continue to exceed the observed variance. revision: yes
-
Referee: [§3 / §4] §3 (architecture) and §4 (experiments): the precise parameterization of the context-dependent gate (input features, activation, output dimensionality, and how it modulates the V_1 pathway) is described at a high level but lacks the level of detail needed to reproduce the exact implementation from the text alone. Because the gate is the novel component whose selectivity is being claimed, this detail is load-bearing for verifying both the efficiency claims and the mechanistic analyses.
Authors: We acknowledge that the original description of the gate was insufficiently precise for text-only reproduction. We have expanded §3 with the exact parameterization, including the gate's input features, activation function, output dimensionality, and the precise mechanism by which it modulates the V_1 pathway. These additions, together with the already-released code, now allow full reproduction of the model and the accompanying analyses from the text. revision: yes
Circularity Check
No circularity: empirical evaluation of new gating architecture
full rationale
The paper introduces SATFormer as a new architecture that adds a learned context-dependent gate to control access to the first-layer value projection V_1. All reported results are direct empirical measurements of validation loss and zero-shot accuracy on held-out benchmarks across model scales. No equation or claim reduces a performance delta to a fitted parameter by construction, nor does any load-bearing premise rest on a self-citation whose content is itself defined by the present work. The gate is an independent learned component whose selectivity is verified post-hoc by analysis rather than presupposed. The derivation chain is therefore self-contained and consists of standard training plus evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-level features become harder to recover as the residual stream is repeatedly transformed through depth
invented entities (1)
-
Context-dependent gate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2502.12170 , year=
Muddformer: Breaking residual bottlenecks in transformers via multiway dynamic dense connections , author=. arXiv preprint arXiv:2502.12170 , year=
-
[2]
Advances in neural information processing systems , volume=
Denseformer: Enhancing information flow in transformers via depth weighted averaging , author=. Advances in neural information processing systems , volume=
-
[3]
arXiv preprint arXiv:2409.19606 , year=
Hyper-connections , author=. arXiv preprint arXiv:2409.19606 , year=
-
[4]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Value residual learning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[6]
Proceedings of the 56th annual meeting of the association for computational linguistics (Volume 1: Long papers) , pages=
The best of both worlds: Combining recent advances in neural machine translation , author=. Proceedings of the 56th annual meeting of the association for computational linguistics (Volume 1: Long papers) , pages=
-
[7]
Just read twice: Closing the recall gap for recurrent language models, 2024
Just read twice: closing the recall gap for recurrent language models , author=. arXiv preprint arXiv:2407.05483 , year=
-
[8]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review arXiv
-
[9]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[10]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
-
[11]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Gated delta networks: Improving mamba2 with delta rule , author=. arXiv preprint arXiv:2412.06464 , year=
work page internal anchor Pith review arXiv
-
[12]
Forty-first International Conference on Machine Learning , year=
Mobilellm: Optimizing sub-billion parameter language models for on-device use cases , author=. Forty-first International Conference on Machine Learning , year=
-
[13]
Uncertainty in artificial intelligence , pages=
Rezero is all you need: Fast convergence at large depth , author=. Uncertainty in artificial intelligence , pages=. 2021 , organization=
2021
-
[14]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Going deeper with image transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[15]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Deepnet: Scaling transformers to 1,000 layers , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2024 , publisher=
2024
-
[16]
Highway networks , author=. arXiv preprint arXiv:1505.00387 , year=
-
[17]
arXiv preprint arXiv:2512.24880 , year=
mhc: Manifold-constrained hyper-connections , author=. arXiv preprint arXiv:2512.24880 , year=
-
[18]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Densely connected convolutional networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[19]
Deep contextualized word representations
Peters, Matthew E. and Neumann, Mark and Iyyer, Mohit and Gardner, Matt and Clark, Christopher and Lee, Kenton and Zettlemoyer, Luke. Deep Contextualized Word Representations. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10...
-
[20]
arXiv preprint arXiv:2302.03985 , year=
Cross-layer retrospective retrieving via layer attention , author=. arXiv preprint arXiv:2302.03985 , year=
-
[21]
arXiv preprint arXiv:2411.07501 , year=
Laurel: Learned augmented residual layer , author=. arXiv preprint arXiv:2411.07501 , year=
-
[22]
arXiv preprint arXiv:2603.15031 (2026)
Attention residuals , author=. arXiv preprint arXiv:2603.15031 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.