Recognition: unknown
RD-ViT: Recurrent-Depth Vision Transformer for Semantic Segmentation with Reduced Data Dependence Extending the Recurrent-Depth Transformer Architecture to Dense Prediction
Pith reviewed 2026-05-07 03:52 UTC · model grok-4.3
The pith
A single shared transformer block looped with stability mechanisms matches or beats standard ViT on cardiac segmentation using fewer parameters and less training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
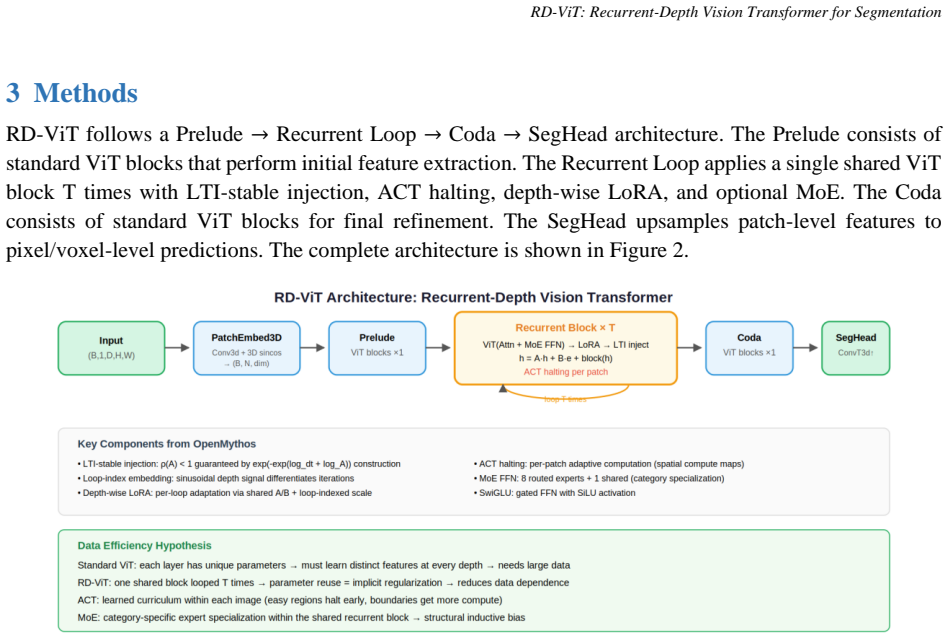
RD-ViT replaces the deep stack of unique transformer blocks with a single shared block looped T times, augmented with LTI-stable state injection for guaranteed convergence, Adaptive Computation Time (ACT) for spatial compute allocation, depth-wise LoRA adaptation, and optional Mixture-of-Experts (MoE) feed-forward networks for category-specific specialization. In 2D experiments it exceeds standard ViT Dice at both 10 percent and 100 percent of the ACDC training data; in 3D it reaches 99.4 percent of ViT performance with 3.0 M parameters (53 percent of the baseline count). MoE experts spontaneously specialize to different cardiac structures, ACT allocates more steps to boundaries, and the架构支持
What carries the argument
Recurrent-depth loop of one shared transformer block stabilized by LTI state injection and equipped with ACT, depth-wise LoRA, and optional MoE.
If this is right
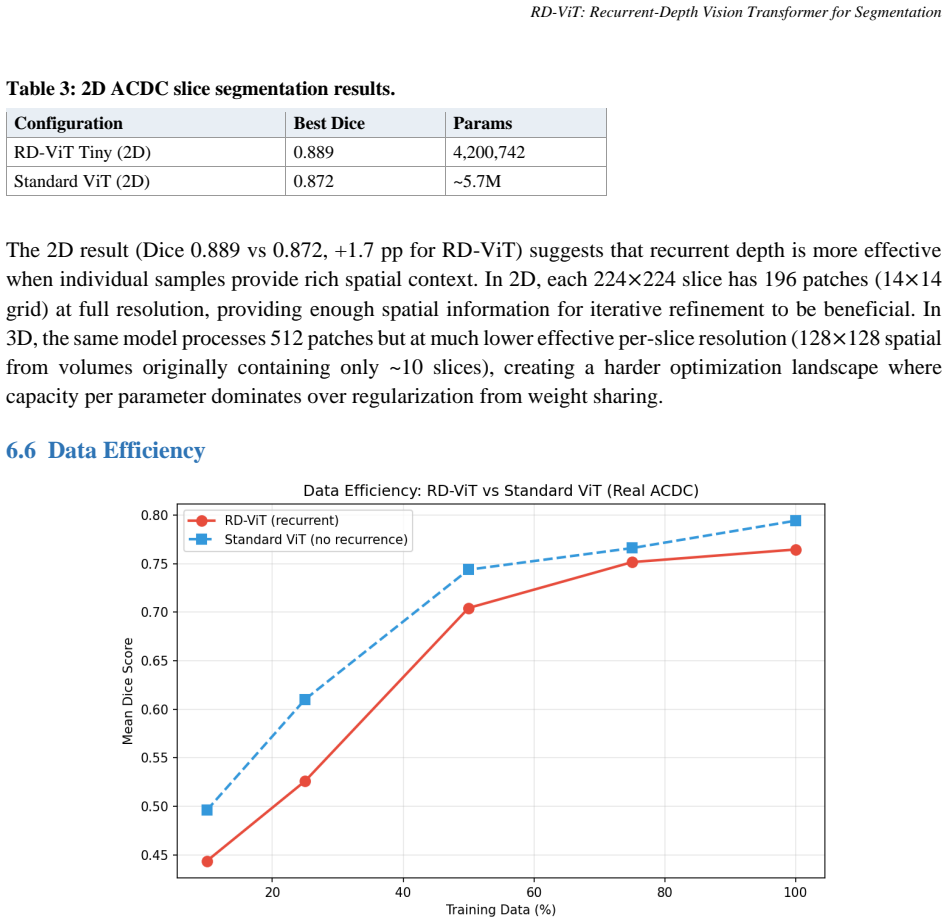
- RD-ViT outperforms standard ViT on 2D cardiac segmentation when only 10% of training data is used (Dice 0.774 vs 0.762).
- In 3D volumetric segmentation RD-ViT with MoE reaches 99.4% of ViT accuracy using 53% of the parameter count.
- Mixture-of-Experts layers spontaneously assign different experts to distinct cardiac structures without any routing supervision.
- Adaptive Computation Time produces halting maps that concentrate extra iterations on object boundaries and reduces mean ponder time from 2.6 to 1.4 during training.
- The model supports depth extrapolation, allowing more loop iterations at inference than were used in training without accuracy loss.
Where Pith is reading between the lines
- The same recurrent loop plus ACT could be attached to other dense heads to improve efficiency on tasks such as instance segmentation or depth estimation.
- Expert specialization observed without supervision suggests the architecture may discover semantic categories automatically on unlabeled data.
- The large reduction in unique parameters makes the approach attractive for on-device medical imaging where memory is limited.
- Combining the recurrent block with existing compression methods such as quantization could produce further gains in both speed and memory.
Load-bearing premise
That a single shared block iterated with these added controls can fully replace a deep stack of unique layers while keeping expressivity, stable training, and segmentation accuracy intact.
What would settle it
On a larger, more diverse segmentation benchmark the RD-ViT Dice score falls more than 3 points below the standard ViT baseline even after full hyperparameter search and increased loop count.
Figures








read the original abstract
Vision Transformers (ViTs) achieve state-of-the-art segmentation accuracy but require large training datasets because each layer has unique parameters that must be learned independently. We present RD-ViT, a Recurrent-Depth Vision Transformer that adapts the Recurrent-Depth Transformer (RDT) architecture to dense prediction tasks, supporting both 2D and 3D inputs. RD-ViT replaces the deep stack of unique transformer blocks with a single shared block looped T times, augmented with LTI-stable state injection for guaranteed convergence, Adaptive Computation Time (ACT) for spatial compute allocation, depth-wise LoRA adaptation, and optional Mixture-of-Experts (MoE) feed-forward networks for category-specific specialization. We evaluate on the ACDC cardiac MRI segmentation benchmark in both 2D slice-level and 3D volumetric settings with exclusively real experiments executed in Google Colab. In 2D, RD-ViT outperforms standard ViT at 10% training data (Dice 0.774 vs 0.762) and at full data (0.882 vs 0.872). In 3D, RD-ViT with MoE achieves Dice 0.812 with 3.0M parameters, reaching 99.4% of standard ViT performance (0.817) at 53% of the parameter count. MoE expert utilization analysis reveals that different experts spontaneously specialize for different cardiac structures (RV, MYO, LV) without explicit routing supervision. ACT halting maps show higher compute allocation at cardiac boundaries, and the mean ponder time decreases from 2.6 to 1.4 iterations during training, demonstrating learned computational efficiency. Depth extrapolation enables inference with more loops than training without degradation. All code, notebooks, and results are publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RD-ViT, adapting the Recurrent-Depth Transformer to semantic segmentation for 2D and 3D inputs. It replaces the standard deep stack of unique ViT blocks with a single shared block looped T times, augmented by LTI-stable state injection for convergence, Adaptive Computation Time (ACT) for per-location compute allocation, depth-wise LoRA, and optional MoE feed-forward networks. On the ACDC cardiac MRI benchmark, RD-ViT reports Dice scores of 0.774 (vs. 0.762 for standard ViT) at 10% training data and 0.882 (vs. 0.872) at full data in 2D; in 3D, the MoE variant reaches Dice 0.812 with 3.0M parameters (99.4% of standard ViT's 0.817 at 53% of the parameter count). The work includes analyses of MoE expert specialization on cardiac structures, ACT halting maps, decreasing ponder times, and depth extrapolation at inference, with all code and notebooks released publicly.
Significance. If the reported performance gains and efficiency claims hold under full scrutiny, RD-ViT could provide a practical route to lower data and parameter requirements for Vision Transformers in dense prediction, with the ACT and MoE components offering additional inference-time benefits. The public code release and the observation of unsupervised expert specialization are concrete strengths that would aid adoption and further research in efficient segmentation models.
major comments (1)
- [Abstract] Abstract: The claim that LTI-stable state injection provides 'guaranteed convergence' is not rigorously supported. Standard transformer blocks contain input-dependent multi-head self-attention, layer normalization, and non-linear GELU activations, violating the linear time-invariant assumptions required for eigenvalue-based stability bounds. This directly undermines the justification for replacing a deep stack of unique blocks with a looped shared block while preserving expressivity and convergence, which is load-bearing for the central claim of reduced data dependence.
minor comments (3)
- [Abstract] Abstract: The reported Dice improvements (e.g., 0.774 vs. 0.762 at 10% data) lack accompanying statistical tests, standard deviations across runs, or full baseline tables; these details are needed to assess whether the gains are robust.
- [Abstract] Abstract: The experimental setup is described only at a high level (Google Colab, ACDC benchmark); the full manuscript should specify hyperparameters, training schedules, data splits, and exact baseline implementations to enable reproduction.
- [Abstract] Abstract: The mean ponder time decrease (2.6 to 1.4) and depth-extrapolation results are presented without variance, per-sample distributions, or ablation on the LTI injection's contribution; adding these would strengthen the efficiency claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The single major comment concerns the wording around convergence in the abstract; we address it directly below by acknowledging the limitation of the original claim and revising the text accordingly. The empirical results on data efficiency and the other architectural components remain supported by the experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that LTI-stable state injection provides 'guaranteed convergence' is not rigorously supported. Standard transformer blocks contain input-dependent multi-head self-attention, layer normalization, and non-linear GELU activations, violating the linear time-invariant assumptions required for eigenvalue-based stability bounds. This directly undermines the justification for replacing a deep stack of unique blocks with a looped shared block while preserving expressivity and convergence, which is load-bearing for the central claim of reduced data dependence.
Authors: We agree that the original phrasing 'guaranteed convergence' is not rigorously supported. The transformer block is not strictly LTI because of input-dependent attention, layer normalization, and GELU nonlinearities, so eigenvalue-based bounds from linear systems do not directly apply to the full recurrent system. The LTI-stable state injection is a heuristic mechanism inspired by LTI stability analysis; it injects a stabilizing term that, in practice, helps the shared block converge when looped. This is evidenced by our depth-extrapolation experiments (no degradation when using more iterations at inference) and the observed decrease in mean ponder time under ACT. We do not claim or provide a formal convergence proof for the nonlinear recurrent dynamics. We have revised the abstract to replace 'guaranteed convergence' with 'promoting convergence' and added a short clarification in the methods section noting the heuristic nature of the approach. The central empirical claim of reduced data dependence is unaffected, as it rests on the ACDC benchmark results rather than the theoretical guarantee. revision: yes
Circularity Check
No circularity: empirical comparisons stand independently of any derivation chain
full rationale
The paper's central claims consist of direct empirical Dice-score and parameter-count comparisons between RD-ViT and a standard ViT baseline on the ACDC dataset (both 2D and 3D settings). No mathematical derivation is presented that reduces any reported performance figure to a fitted quantity or to a self-citation by construction. The architectural description (shared block + LTI-stable injection + ACT + depth-wise LoRA + optional MoE) is motivated by reference to prior RDT work, but that reference supplies only the starting point for the extension; the new results are obtained by training and evaluating the modified model on held-out data splits. Because the evaluation is external to any internal fitting or self-referential proof, the derivation chain does not collapse to its inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- Recurrence depth T
- Number of MoE experts
axioms (2)
- domain assumption LTI-stable state injection guarantees convergence of the recurrent loop.
- domain assumption The shared transformer block maintains sufficient expressivity when adapted via depth-wise LoRA and MoE for dense prediction.
Reference graph
Works this paper leans on
-
[1]
Gomez, K. (2025). OpenMythos: Reconstructing the Recurrent-Depth Transformer. github.com/kyegomez/OpenMythos. RD-ViT: Recurrent-Depth Vision Transformer for Segmentation 22
2025
-
[2]
Dosovitskiy, A. et al. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR 2021
2021
-
[3]
Touvron, H. et al. (2021). Training Data-Efficient Image Transformers and Distillation through Attention. ICML 2021
2021
-
[4]
Zheng, S. et al. (2021). Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. CVPR 2021
2021
-
[5]
Liu, Z. et al. (2021). Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. ICCV 2021
2021
-
[6]
Xie, E. et al. (2021). SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. NeurIPS 2021
2021
-
[7]
Dehghani, M. et al. (2019). Universal Transformers. ICLR 2019
2019
-
[8]
Lan, Z. et al. (2020). ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations. ICLR 2020
2020
-
[9]
Shazeer, N. et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. ICLR 2017
2017
-
[10]
Fedus, W., Zoph, B., and Shazeer, N. (2022). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. JMLR 23(120):1–39
2022
-
[11]
Riquelme, C. et al. (2021). Scaling Vision with Sparse Mixture of Experts. NeurIPS 2021
2021
-
[12]
Ronneberger, O., Fischer, P., and Brox, T. (2015). U -Net: Convolutional Networks for Biomedical Image Segmentation. MICCAI 2015, LNCS 9351, pp. 234–241
2015
-
[13]
Chen, J. et al. (2021). TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv:2102.04306
work page internal anchor Pith review arXiv 2021
-
[14]
Isensee, F. et al. (2021). nnU -Net: A Self -Configuring Method for Deep Learning -Based Biomedical Image Segmentation. Nature Methods 18:203–211
2021
-
[15]
Cheng, B. et al. (2022). Masked-Attention Mask Transformer for Universal Image Segmentation. CVPR 2022
2022
-
[16]
Lepikhin, D. et al. (2021). GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. ICLR 2021
2021
-
[17]
Puigcerver, J. et al. (2024). From Sparse to Soft Mixtures of Experts. ICLR 2024
2024
-
[18]
Graves, A. (2016). Adaptive Computation Time for Recurrent Neural Networks. arXiv:1603.08983
work page internal anchor Pith review arXiv 2016
-
[19]
Han, Y. et al. (2022). Dynamic Neural Networks: A Survey. IEEE TPAMI 44(11):7436–7456
2022
-
[20]
Cipriano, M. et al. (2024). ToothFairy2: Multi-Structure Segmentation from CBCT Volumes. MICCAI 2024 Challenge
2024
-
[21]
Wang, H. et al. (2023). Dense Representative Tooth Landmark/Axis Detection Network on 3D CBCT. MICCAI 2023. Appendix A: Hyperparameter Specifications Table A1: Complete hyperparameter specifications for all experiments. Parameter 2D Value 3D Value Image size 224 × 224 128 × 128 × 16 Patch size 16 × 16 16 × 16 × 2 Input channels 3 (replicated) 1 (grayscale...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.