Recognition: unknown
Can Transformers predict system collapse in dynamical systems?
Pith reviewed 2026-05-07 03:53 UTC · model grok-4.3
The pith
Transformers fail to predict catastrophic collapse in unseen parameter regimes of dynamical systems
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
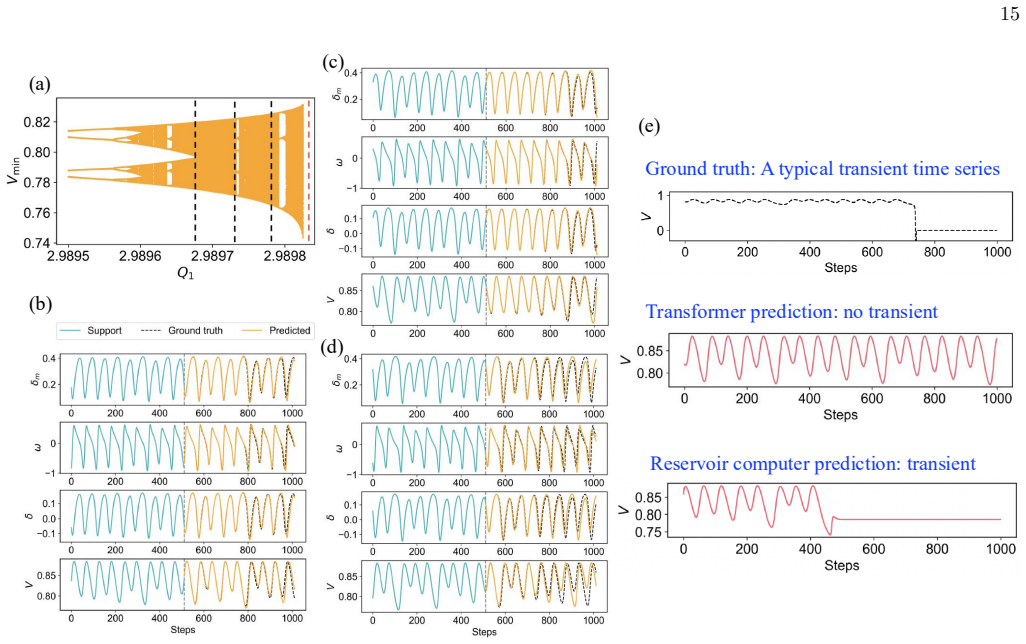
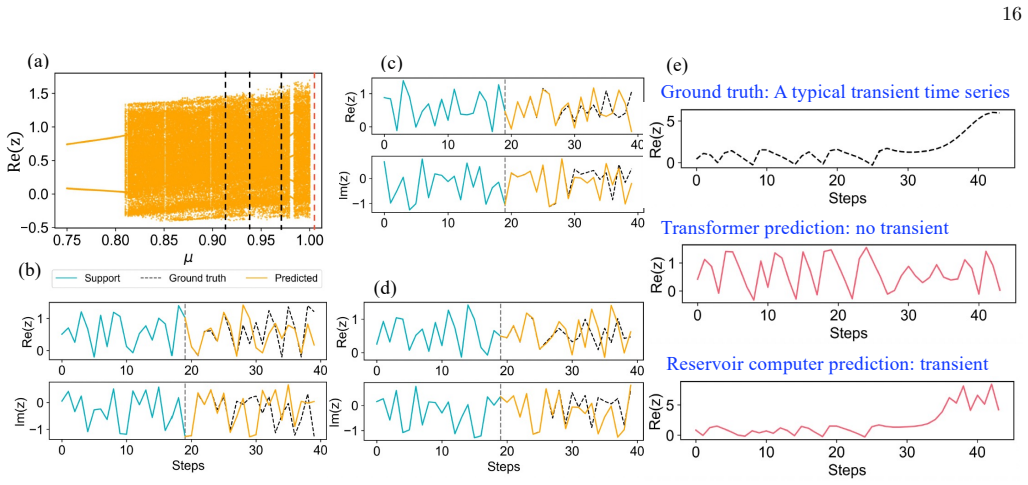
Across multiple configurations, Transformer models trained exclusively on trajectories from normal parameter regimes are unable to capture the dynamics leading to system collapse when tested in previously unseen regimes where a bifurcation parameter surpasses its critical value. In comparison, reservoir computing approaches reliably predict these transitions. The study concludes that this highlights limitations in the generalization capabilities of Transformers for dynamical systems.
What carries the argument
Catastrophic collapse prediction as a benchmark for parameter-space extrapolation in dynamical systems, pitting Transformer attention mechanisms against reservoir computing.
If this is right
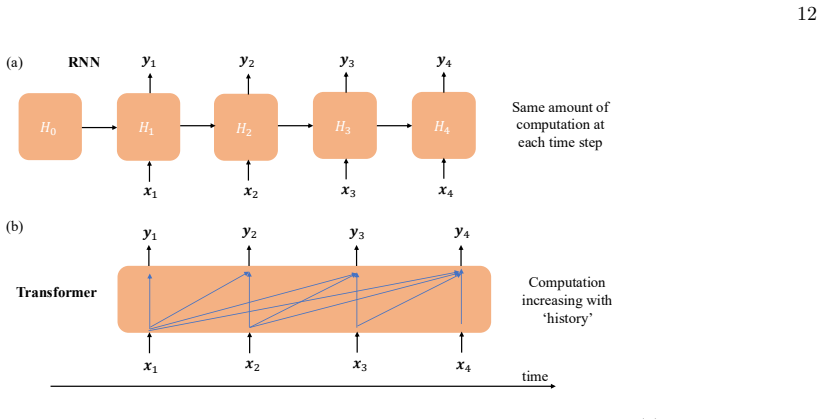
- Transformers' permutation-invariant attention mechanisms limit their capacity to capture how temporal structure evolves with changing parameters.
- Reservoir computing can be trained to capture both the dynamical climate and its variation with parameters.
- Generalization of Transformers to dynamical systems in extrapolation tasks requires further investigation.
Where Pith is reading between the lines
- Architectures may need explicit conditioning on parameters to handle extrapolation in physical dynamics.
- Similar collapse-prediction tests could apply to other critical transitions such as those in climate or power-grid models.
- Hybrid models combining attention with recurrent elements might overcome the observed extrapolation limits.
Load-bearing premise
That the observed failure of Transformers to predict collapse in held-out regimes indicates they do not capture the underlying physical dynamics rather than resulting from specific architectural or training limitations.
What would settle it
Demonstrating success in collapse prediction by Transformers after training on a diverse set of dynamical systems that include collapsing examples or after modifying the architecture to incorporate explicit parameter conditioning.
Figures











read the original abstract
Transformer architectures have recently surged as promising solutions for nonlinear dynamical systems, proposed as foundation models capable of zero-shot dynamics reconstruction and forecasting. Despite this success, it remains unclear whether they can truly serve as reliable digital twins of dynamical systems, i.e., whether they capture the underlying physical dynamics in distinct parameter regimes, especially in parameter regimes from which no training data is taken. For parameter-space extrapolation in nonlinear dynamical systems, reservoir computing has demonstrated broad success, as proper training can turn it into an intrinsic dynamical system capable of capturing not only the dynamical climate of the target system but more importantly, how the climate changes with parameter. Transformers, in contrast, rely on permutation-invariant attention mechanisms that can limit their ability to capture how temporal structure changes with parameter. To determine if Transformers have the capability of dynamics extrapolation, we take predicting catastrophic collapse, which occurs when a bifurcation parameter crosses a critical threshold, as a benchmark task. Models are trained on trajectories in normal parameter regimes and then tested on parameters in an unseen regime with system collapse. Our results show that Transformers, across configurations, consistently fail to capture collapse, while reservoir computing reliably predicts the transitions. This surprising finding raises questions about the generalization ability of Transformers to dynamical systems, a topic warranting future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Transformer architectures fail to predict catastrophic collapse in nonlinear dynamical systems when trained on trajectories from stable parameter regimes and tested on unseen regimes where a bifurcation parameter crosses a critical threshold, while reservoir computing (RC) models reliably capture the transitions. The authors attribute the difference to the permutation-invariant attention mechanisms in Transformers, which purportedly prevent capturing how temporal structure evolves with the bifurcation parameter. The work positions this as evidence against using Transformers as reliable digital twins or foundation models for dynamical systems extrapolation.
Significance. If substantiated with rigorous controls, the result would meaningfully constrain claims about Transformers as general-purpose models for nonlinear dynamics, particularly for parameter-space extrapolation tasks such as tipping-point prediction. It would also reinforce the utility of RC for embedding parameter-dependent climate changes in dynamical systems. The comparison highlights inductive-bias differences between architectures and could guide model selection in applications like climate or engineering systems. However, the absence of quantitative metrics, implementation details, and statistical validation substantially weakens the immediate significance and generalizability of the reported outcome.
major comments (3)
- [Abstract] Abstract: The central claim that 'Transformers, across configurations, consistently fail to capture collapse' while 'reservoir computing reliably predicts the transitions' is presented without any quantitative metrics (e.g., prediction error, success rate, or horizon), error bars, or statistical significance tests. This omission makes it impossible to determine whether the reported difference is robust or sensitive to implementation choices.
- [Abstract] Abstract: The explanation that Transformers 'rely on permutation-invariant attention mechanisms that can limit their ability to capture how temporal structure changes with parameter' does not address the standard inclusion of positional encodings (sinusoidal, learned, or rotary) in Transformer pipelines for sequential data, which explicitly break permutation invariance. The manuscript must clarify whether such encodings (or other temporal biases such as causal masking) were used in the tested configurations; if omitted, the observed failure may reflect a missing inductive bias rather than an inherent architectural limitation.
- [Results / Methods] Results / Methods (presumed sections): No details are supplied on model sizes, training protocols, data-generation procedures, the specific dynamical systems or bifurcation types tested, or the quantitative criteria used to declare 'failure' versus 'success.' These elements are load-bearing for the extrapolation claim and must be provided to allow assessment of reproducibility and fairness of the Transformer-RC comparison.
minor comments (2)
- [Abstract] The abstract contains several long, compound sentences that reduce readability; splitting them would improve clarity.
- [Title / Abstract] The title is phrased as a question, yet the abstract delivers a definitive negative verdict without qualification; consider adjusting the title or abstract to better reflect the scope of the tested systems and configurations.
Simulated Author's Rebuttal
We are grateful to the referee for their detailed and constructive comments on our manuscript. These have highlighted important areas for improvement in terms of quantitative rigor, architectural transparency, and reproducibility. We have addressed all points by planning substantial revisions to the abstract, methods, and results sections. Our point-by-point responses are as follows:
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Transformers, across configurations, consistently fail to capture collapse' while 'reservoir computing reliably predicts the transitions' is presented without any quantitative metrics (e.g., prediction error, success rate, or horizon), error bars, or statistical significance tests. This omission makes it impossible to determine whether the reported difference is robust or sensitive to implementation choices.
Authors: We agree that the abstract's claims would benefit from supporting quantitative evidence. In the revised version, we will augment the abstract with key quantitative results, such as average prediction horizons before divergence, normalized mean squared errors for both models across multiple trials, and p-values from statistical comparisons. Detailed metrics, including error bars from 10 independent runs with different random seeds, will be presented in the Results section. This will allow readers to assess the robustness of the observed performance gap. revision: yes
-
Referee: [Abstract] Abstract: The explanation that Transformers 'rely on permutation-invariant attention mechanisms that can limit their ability to capture how temporal structure changes with parameter' does not address the standard inclusion of positional encodings (sinusoidal, learned, or rotary) in Transformer pipelines for sequential data, which explicitly break permutation invariance. The manuscript must clarify whether such encodings (or other temporal biases such as causal masking) were used in the tested configurations; if omitted, the observed failure may reflect a missing inductive bias rather than an inherent architectural limitation.
Authors: Thank you for pointing this out. Our Transformer implementations did include sinusoidal positional encodings and causal masking, as is standard for sequence modeling tasks. We will revise the manuscript to explicitly describe these components in the Methods section and discuss how, despite these temporal biases, the models still failed to extrapolate the bifurcation-induced changes. This supports our interpretation that the core attention mechanism struggles with parameter-space extrapolation in this context, rather than the issue being solely due to missing positional information. revision: yes
-
Referee: [Results / Methods] Results / Methods (presumed sections): No details are supplied on model sizes, training protocols, data-generation procedures, the specific dynamical systems or bifurcation types tested, or the quantitative criteria used to declare 'failure' versus 'success.' These elements are load-bearing for the extrapolation claim and must be provided to allow assessment of reproducibility and fairness of the Transformer-RC comparison.
Authors: We acknowledge that the current manuscript lacks sufficient implementation details, which is a significant oversight. In the revision, we will expand the Methods section to include: model architectures (e.g., Transformer with 4 layers, 8 heads, d_model=256; RC with reservoir size 1000, spectral radius 0.9), training details (Adam optimizer with lr=1e-4, 100 epochs, MSE loss), data generation (e.g., Lorenz system with bifurcation parameter rho from 20-24 for training, tested on rho=28 where collapse occurs; 1000 trajectories per regime), and success criteria (e.g., failure if prediction error exceeds 10% of attractor size within 50 time steps). We will also include a table summarizing hyperparameters and make the code available upon acceptance to ensure full reproducibility. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivation chain
full rationale
The manuscript is an empirical benchmark study: Transformers and reservoir computing are trained on trajectories from normal parameter regimes of specific dynamical systems and evaluated on held-out parameter values where collapse occurs. No equations, ansatzes, or derivations are offered whose outputs reduce to the inputs by construction. The architectural remark on permutation-invariant attention is a general property of the model family (not a self-referential definition), and the reported failure is a direct experimental outcome rather than a fitted or renamed quantity. Any self-citations to prior reservoir-computing results are external benchmarks, not load-bearing for the Transformer-negative finding. The work is therefore self-contained against external replication.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
How- ever, standard RNNs are difficult to train on chaotic time series [43]
Machine learning for dynamical systems Recurrent neural networks (RNNs) are designed to capture temporal dependencies in sequential data. How- ever, standard RNNs are difficult to train on chaotic time series [43]. Gated architectures such as LSTM (Long Short-Term Memory) networks or GRUs (Gated Recur- rent Units) [44], with strong stability constraints, ...
-
[2]
Machine learning for critical transitions Critical transitions and tipping are abrupt and often irreversible changes in system state that occur once a stability threshold is crossed. Machine learning, in par- ticular reservoir computing, has been introduced to this field, where the model is trained on trajectories from known parameters and then used to in...
-
[3]
saw” from the noun “saw
Reservoir computing Reservoir computing is a recurrent neural network framework particularly well suited for modeling dynam- ical systems. Its main idea is to embed the input time series into a high-dimensional dynamical network with fixed random connections, while only training a linear readout layer. To capture parameter-induced regime changes, we emplo...
-
[4]
T” in ChatGPT stands for “Transformer
T ransformer The Transformer is a deep learning architecture that has become the foundation for most modern natural lan- guage processing (NLP) systems, including large lan- guage models such as ChatGPT (in fact, the last letter “T” in ChatGPT stands for “Transformer”), as well as tools for machine translation and summarization. The architecture typically...
2017
-
[5]
In reser- voir computing, the input terms in Eq
Parameter-adaptable reservoir computing and T ransformer For both Transformer and reservoir computing, we use the same (d+ 1)-dimensional input: thed-dimensional state concatenated with a parameter channel. In reser- voir computing, the input terms in Eq. (B1) can be writ- ten as Win ·X(t) +W pp= Win,W p · X(t), p ⊺ ,(B11) forp 0 = 0, demonstrating that t...
-
[6]
System description We consider an electrical power systems including volt- age collapse [68, 69]
Power system a. System description We consider an electrical power systems including volt- age collapse [68, 69]. The system exhibits transient chaos prior to collapse, making it an appropriate testbed for critical transition prediction. The model consists of four coupled differential equations, describing the rotor angle δm, rotor speedω, load voltage ph...
-
[7]
are defined [6] in terms 15 Ground truth: A typical transient time series Transformer prediction: no transient Reservoir computer prediction: transient (a) (b) (c) (d) (e) FIG. 8. Critical transition prediction in the power system. (a) Bifurcation diagram with training parameters (black dashed) and the testing parameter beyond the critical point (red dash...
-
[8]
System description The Ikeda map describes the dynamics of a laser pulse propagating through a nonlinear optical cavity [70, 71]
Ikeda map a. System description The Ikeda map describes the dynamics of a laser pulse propagating through a nonlinear optical cavity [70, 71]. The map is defined on a complex variablez∈Cand takes the form zn+1 =µ+γz n exp iκ− iν 1 +|z n|2 ,(C7) whereµis the dimensionless laser input amplitude,γis the reflectivity coefficient of the cavity mirrors,κis the ...
-
[9]
Kuramoto-Sivashinsky system a. System description The Kuramoto-Sivashinsky (KS) system, as described by nonlinear partial differential equation, is a prototypi- cal model for studying nonlinear spatiotemporal dynam- ics. It was originally derived to model instabilities in laminar flame fronts, and later applied to other physical systems, such as trapped-i...
-
[10]
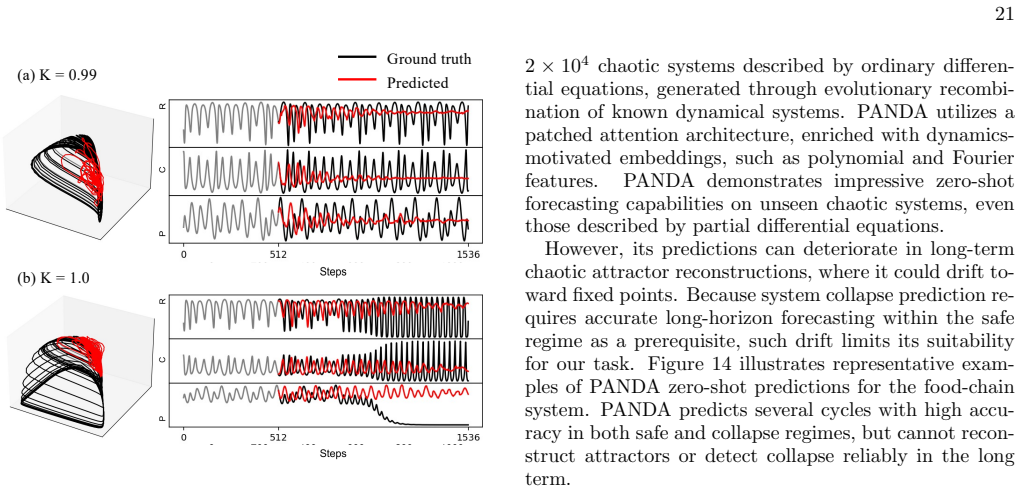
P ANDA PANDA is a pretrained forecast model specifically de- signed for nonlinear and chaotic dynamics [65]. It is trained on an extensive synthetic dataset of more than 2×10 4 chaotic systems described by ordinary differen- tial equations, generated through evolutionary recombi- nation of known dynamical systems. PANDA utilizes a patched attention archit...
-
[11]
It incorporates cross-channel attention and can process multivariate tra- jectories, making it applicable to our tasks
Chronos-2 Chronos-2 [76] is the recently released multivariate ex- tension of the Chronos family, designed as a general foun- dation model for time series forecasting. It incorporates cross-channel attention and can process multivariate tra- jectories, making it applicable to our tasks. The model is trained using large-scale probabilistic objectives on di...
-
[12]
Grebogi, E
C. Grebogi, E. Ott, and J. A. Yorke, Crises, sudden changes in chaotic attractors, and transient chaos, Phys- ica D7, 181 (1983)
1983
-
[13]
Lai and T
Y.-C. Lai and T. T´ el,Transient chaos: Complex dynam- ics on finite time scales, Vol. 173 (Springer Science & Business Media, 2011)
2011
-
[14]
Dhamala and Y.-C
M. Dhamala and Y.-C. Lai, Controlling transient chaos in deterministic flows with applications to electrical power systems and ecology, Phys. Rev. E59, 1646 (1999)
1999
-
[15]
Z.-M. Zhai, M. Moradi, S. Panahi, Z.-H. Wang, and Y.-C. Lai, Machine-learning nowcasting of the Atlantic Meridional Overturning Circulation, APL Mach. Learn. 2(2024)
2024
-
[16]
Chakraborty and S
S. Chakraborty and S. Adhikari, Machine learning based digital twin for dynamical systems with multiple time- scales, Comput. Struct.243, 106410 (2021)
2021
-
[17]
Kong, H.-W
L.-W. Kong, H.-W. Fan, C. Grebogi, and Y.-C. Lai, Ma- chine learning prediction of critical transition and system collapse, Phys. Rev. Res.3, 013090 (2021)
2021
-
[18]
Patel, D
D. Patel, D. Canaday, M. Girvan, A. Pomerance, and E. Ott, Using machine learning to predict statistical properties of non-stationary dynamical processes: Sys- tem climate, regime transitions, and the effect of stochas- ticity, Chaos31(2021)
2021
-
[19]
L.-W. Kong, Y. Weng, B. Glaz, M. Haile, and Y.-C. Lai, Reservoir computing as digital twins for nonlinear dy- namical systems, Chaos33(2023)
2023
-
[20]
Panahi, L.-W
S. Panahi, L.-W. Kong, M. Moradi, Z.-M. Zhai, B. Glaz, 22 M. Haile, and Y.-C. Lai, Machine learning prediction of tipping in complex dynamical systems, Phys. Rev. Res. 6, 043194 (2024)
2024
-
[21]
M. Yan, C. Huang, P. Bienstman, P. Tino, W. Lin, and J. Sun, Emerging opportunities and challenges for the future of reservoir computing, Nat. Commun.15, 2056 (2024)
2056
-
[22]
Zhuge, J
C. Zhuge, J. Li, and W. Chen, Deep learning for predict- ing the occurrence of tipping points, R. Soc. Open Sci. 12, 242240 (2025)
2025
-
[23]
echo state
H. Jaeger, The “echo state” approach to analysing and training recurrent neural networks-with an erratum note, Bonn, Germany: German National Research Center for Information Technology GMD Technical Report148, 13 (2001)
2001
-
[24]
Jaeger and H
H. Jaeger and H. Haas, Harnessing nonlinearity: Predict- ing chaotic systems and saving energy in wireless com- munication, Science304, 78 (2004)
2004
-
[25]
Pathak, Z
J. Pathak, Z. Lu, B. Hunt, M. Girvan, and E. Ott, Using machine learning to replicate chaotic attractors and cal- culate Lyapunov exponents from data, Chaos27, 121102 (2017)
2017
-
[26]
Z. Lu, J. Pathak, B. Hunt, M. Girvan, R. Brockett, and E. Ott, Reservoir observers: Model-free inference of un- measured variables in chaotic systems, Chaos27, 041102 (2017)
2017
-
[28]
A. Hart, J. Hook, and J. Dawes, Embedding and approx- imation theorems for echo state networks, Neural Netw. 128, 234 (2020)
2020
-
[29]
D. J. Gauthier, E. Bollt, A. Griffith, and W. A. Barbosa, Next generation reservoir computing, Nat. Commun.12, 5564 (2021)
2021
-
[30]
Pecora and T
L. Pecora and T. Carroll, Statistics for differential topo- logical properties between datasets with an application to reservoir computers, Chaos35, 073153 (2025)
2025
-
[31]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, Attention is all you need, Adv. Neural Inf. Process. Syst. 30(2017)
2017
-
[38]
Y. Zhang and W. Gilpin, Context parroting: A simple but tough-to-beat baseline for foundation models in sci- entific machine learning, arXiv preprint arXiv:2505.11349 (2025)
-
[39]
A. Zeng, M. Chen, L. Zhang, and Q. Xu, Are transform- ers effective for time series forecasting?, inProc. AAAI Conf. Artif. Intell., Vol. 37 (2023) pp. 11121–11128
2023
-
[40]
L.-W. Kong, H. Fan, C. Grebogi, and Y.-C. Lai, Emer- gence of transient chaos and intermittency in machine learning, J. Phys. Complex.2, 035014 (2021)
2021
-
[41]
Panahi, L.-W
S. Panahi, L.-W. Kong, B. Glaz, M. Haile, and Y.-C. Lai, Unsupervised learning for anticipating critical tran- sitions, Phys. Rev. Lett.136, 077301 (2026)
2026
-
[42]
W.-X. Wang, R. Yang, Y.-C. Lai, V. Kovanis, and C. Grebogi, Predicting catastrophes in nonlinear dynami- cal systems by compressive sensing, Phys. Rev. Lett.106, 154101 (2011)
2011
-
[43]
S. L. Brunton, J. L. Proctor, and J. N. Kutz, Discovering governing equations from data by sparse identification of nonlinear dynamical systems, Proc. Nat. Acad. Sci. (USA)113, 3932 (2016)
2016
-
[44]
Lai, Finding nonlinear system equations and com- plex network structures from data: A sparse optimization approach, Chaos31, 082101 (2021)
Y.-C. Lai, Finding nonlinear system equations and com- plex network structures from data: A sparse optimization approach, Chaos31, 082101 (2021)
2021
-
[45]
Jaeger, M
H. Jaeger, M. Lukoˇ seviˇ cius, D. Popovici, and U. Siew- ert, Optimization and applications of echo state net- works with leaky-integrator neurons, Neural Netw.20, 335 (2007)
2007
-
[46]
Z.-M. Zhai, B. Glaz, M. Haile, A. Hastings, and Y.- C. Lai, Learning to learn ecosystems from limited data, Proc. Nat. Acad. Sci. (USA)122, e2525347122 (2025)
2025
- [47]
-
[48]
Edelman, N
E. Edelman, N. Tsilivis, B. Edelman, E. Malach, and S. Goel, The evolution of statistical induction heads: In- context learning Markov chains, Adv. Neural Inf. Pro- cess. Syst.37, 64273 (2024)
2024
-
[49]
S. Chen, H. Sheen, T. Wang, and Z. Yang, Unveiling induction heads: Provable training dynamics and feature learning in transformers, Adv. Neural Inf. Process. Syst. 37, 66479 (2024)
2024
-
[50]
K¨ oster, K
F. K¨ oster, K. Kanno, J. Ohkubo, and A. Uchida, Attention-enhanced reservoir computing, Phys. Rev. Appl.22, 014039 (2024)
2024
- [51]
-
[52]
Y. Chen, K. Ren, Y. Wang, Y. Fang, W. Sun, and D. Li, Contiformer: Continuous-time transformer for irregular time series modeling, Adv. Neural Inf. Process. Syst.36, 47143 (2023)
2023
-
[53]
Gu and T
A. Gu and T. Dao, Mamba: Linear-time sequence mod- eling with selective state spaces, inProc. Conf. Lang. Model.(2024)
2024
-
[54]
Mikhaeil, Z
J. Mikhaeil, Z. Monfared, and D. Durstewitz, On the difficulty of learning chaotic dynamics with RNNs, Adv. Neural Inf. Process. Syst.35, 11297 (2022)
2022
-
[55]
Vlachas, J
P.-R. Vlachas, J. Pathak, B. R. Hunt, T. P. Sapsis, M. Girvan, E. Ott, and P. Koumoutsakos, Backpropa- gation algorithms and reservoir computing in recurrent neural networks for the forecasting of complex spatiotem- poral dynamics, Neural Netw.126, 191 (2020)
2020
- [56]
-
[57]
Pathak, B
J. Pathak, B. Hunt, M. Girvan, Z. Lu, and E. Ott, Model- free prediction of large spatiotemporally chaotic systems from data: A reservoir computing approach, Phys. Rev. Lett.120, 024102 (2018)
2018
-
[58]
Fan, L.-W
H. Fan, L.-W. Kong, Y.-C. Lai, and X. Wang, Anticipat- ing synchronization with machine learning, Phys. Rev. Res.3, 023237 (2021)
2021
-
[59]
Canaday, A
D. Canaday, A. Pomerance, and D. J. Gauthier, Model- free control of dynamical systems with deep reservoir computing, J. Phys. Complex.2, 035025 (2021)
2021
-
[60]
Flynn, V
A. Flynn, V. A. Tsachouridis, and A. Amann, Seeing double with a multifunctional reservoir computer, Chaos 33(2023)
2023
-
[61]
J. Z. Kim and D. S. Bassett, A neural machine code and programming framework for the reservoir computer, Nat. Mach. Intell.5, 622 (2023)
2023
-
[62]
Z.-M. Zhai, M. Moradi, L.-W. Kong, B. Glaz, M. Haile, and Y.-C. Lai, Model-free tracking control of complex dynamical trajectories with machine learning, Nat. Com- mun.14, 5698 (2023)
2023
-
[63]
Z. Lin, Z. Lu, Z. Di, and Y. Tang, Learning noise-induced transitions by multi-scaling reservoir computing, Nat. Commun.15, 6584 (2024)
2024
- [64]
-
[65]
Cuomo, V
S. Cuomo, V. S. Di Cola, F. Giampaolo, G. Rozza, M. Raissi, and F. Piccialli, Scientific machine learning through physics-informed neural networks: Where we are and what’s next, J. Sci. Comput.92, 88 (2022)
2022
-
[66]
Z. Du, H. Balim, S. Oymak, and N. Ozay, Can transform- ers learn optimal filtering for unknown systems?, IEEE Control Syst. Lett.7, 3525 (2023)
2023
-
[67]
J. Z. Kim, Z. Lu, E. Nozari, G. J. Pappas, and D. S. Bas- sett, Teaching recurrent neural networks to infer global temporal structure from local examples, Nat. Mach. In- tell.3, 316 (2021)
2021
-
[68]
T. M. Bury, R. Sujith, I. Pavithran, M. Scheffer, T. M. Lenton, M. Anand, and C. T. Bauch, Deep learning for early warning signals of tipping points, Proc. Natl. Acad. Sci. U.S.A.118, e2106140118 (2021)
2021
-
[69]
Huang, S
Y. Huang, S. Bathiany, P. Ashwin, and N. Boers, Deep learning for predicting rate-induced tipping, Nat. Mach. Intell.6, 1556 (2024)
2024
-
[70]
Fabiani, N
G. Fabiani, N. Evangelou, T. Cui, J. M. Bello-Rivas, C. P. Martin-Linares, C. Siettos, and I. G. Kevrekidis, Task- oriented machine learning surrogates for tipping points of agent-based models, Nat. Commun.15, 4117 (2024)
2024
-
[71]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, Attention is all you need, in31st Conference on Neu- ral Information Processing Systems (NIPS 2017), Vol. 30 (2017) pp. 11121–11128
2017
-
[72]
L. Su, X. Zuo, R. Li, X. Wang, H. Zhao, and B. Huang, A systematic review for transformer-based long-term series forecasting, Artif. Intell. Rev.58, 80 (2025)
2025
-
[73]
Selva, A
J. Selva, A. S. Johansen, S. Escalera, K. Nasrollahi, T. B. Moeslund, and A. Clap´ es, Video transformers: A sur- vey, IEEE Trans. Pattern Anal. Mach. Intell.45, 12922 (2023)
2023
-
[74]
Y. Zhang and W. Gilpin, Zero-shot forecasting of chaotic systems, arXiv preprint arXiv:2409.15771 (2024)
-
[75]
Z.-M. Zhai, B. D. Stern, and Y.-C. Lai, Bridging known and unknown dynamics by transformer-based machine- learning inference from sparse observations, Nat. Com- mun.16, 8053 (2025)
2025
- [76]
-
[77]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
A. Power, Y. Burda, H. Edwards, I. Babuschkin, and V. Misra, Grokking: Generalization beyond over- fitting on small algorithmic datasets, arXiv preprint arXiv:2201.02177 (2022)
work page internal anchor Pith review arXiv 2022
-
[78]
M. C. Mackey and L. Glass, Oscillation and chaos in physiological control systems, Science197, 287 (1977)
1977
-
[79]
Dobson and H.-D
I. Dobson and H.-D. Chiang, Towards a theory of voltage collapse in electric power systems, Syst. Control Lett.13, 253 (1989)
1989
-
[80]
H. O. Wang, E. H. Abed, and A. M. Hamdan, Bifurca- tions, chaos, and crises in voltage collapse of a model power system, IEEE Trans. Circuits Syst. I Fundam. Theory Appl.41, 294 (1994)
1994
-
[81]
Ikeda, H
K. Ikeda, H. Daido, and O. Akimoto, Optical turbulence: Chaotic behavior of transmitted light from a ring cavity, Phys. Rev. Lett.45, 709 (1980)
1980
-
[82]
V. In, M. L. Spano, and M. Ding, Maintaining chaos in high dimensions, Phys. Rev. Lett.80, 700 (1998)
1998
-
[83]
R. E. LaQuey, S. Mahajan, P. Rutherford, and W. Tang, Nonlinear saturation of the trapped-ion mode, Phys. Rev. Lett.34, 391 (1975)
1975
-
[84]
A. F. Ansari, L. Stella, C. Turkmen, X. Zhang, P. Mer- cado, H. Shen, O. Shchur, S. S. Rangapuram, S. P. Arango, S. Kapoor,et al., Chronos: Learning the lan- guage of time series, arXiv preprint arXiv:2403.07815 (2024)
work page internal anchor Pith review arXiv 2024
-
[85]
A. Das, W. Kong, R. Sen, and Y. Zhou, A decoder-only foundation model for time-series forecasting, inInt. Conf. Mach. Learn.(2024)
2024
-
[86]
Liang, H
Y. Liang, H. Wen, Y. Nie, Y. Jiang, M. Jin, D. Song, S. Pan, and Q. Wen, Foundation models for time series analysis: A tutorial and survey, inProc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Min.(2024) pp. 6555– 6565
2024
-
[87]
Fatir Ansari, O
A. Fatir Ansari, O. Shchur, J. K¨ uken, A. Auer, B. Han, P. Mercado, S. Sundar Rangapuram, H. Shen, L. Stella, X. Zhang,et al., Chronos-2: From univariate to universal forecasting, arXiv e-prints , arXiv (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.