Recognition: 3 theorem links
· Lean TheoremUniCorrn: Unified Correspondence Transformer Across 2D and 3D
Pith reviewed 2026-05-06 04:11 UTC · model claude-opus-4-7
The pith
A single Transformer with shared weights handles 2D-2D, 2D-3D, and 3D-3D keypoint matching, with a dual-stream decoder driving the cross-modal gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that geometric correspondence across image-to-image, image-to-point-cloud, and point-cloud-to-point-cloud matching can be handled by a single Transformer with shared encoder and decoder weights, rather than the task-specific specialist models that currently dominate each setting. The central architectural move is a dual-stream decoder in which appearance features and positional embeddings live in separate residual streams but share one Gaussian-kernel attention matrix; that attention matrix plays the role of a learnable matching cost, and applying it to absolute positional encodings of target tokens directly yields the coordinates of corresponding keypoints. Trained jointly
What carries the argument
A dual-stream Transformer decoder: appearance features F_k and positional embeddings P_k are updated in parallel residual streams but share a single Gaussian-kernel attention matrix A = softmax(-pairwise L2(F'_k, F'_t)/D), which acts as a learnable matching cost. Multiplying A by learned absolute positional encodings of target tokens, then inverting the linear positional map, regresses target coordinates; stacking layers iteratively refines the match.
If this is right
- One matching backbone can replace three specialist pipelines in SfM, SLAM, visual localization, and point-cloud registration, cutting engineering complexity.
- Attention with a Gaussian kernel over position-augmented features is a usable drop-in for explicit cost-volume construction, and is stackable across layers for iterative refinement.
- Joint training across modalities transfers data-rich 2D-2D supervision into the data-poor 2D-3D regime, yielding the largest gains there (the cross-modal task benefits most from unification).
- Depth maps can be recycled as pseudo point clouds to bootstrap 2D-3D and 3D-3D training when real annotations are scarce.
- A query-based interface — give the model keypoints in the source modality, get coordinates plus confidences in the target — generalises across 2D and 3D without per-task heads.
Where Pith is reading between the lines
- The reported gradient conflicts in normalisation layers between 2D and 3D streams suggest that modality-aware norm statistics (or per-modality affine parameters) could close the gap where joint training currently underperforms single-task training on 2D-2D and 3D-3D.
- Because attention here is literally a normalised matching cost, the decoder should be a natural fit for optical flow and tracking; the supplementary zero-shot Sintel result hints that this is a broader correspondence engine, not just a registration tool.
- The dependence on ground-truth keypoint queries at evaluation hides a real-world question — how the model behaves when paired with imperfect detectors — and is the most informative next experiment to run.
- Replacing absolute positional encodings of the target with learned coordinate fields could let the same decoder regress into spaces other than pixels and 3D points (e.g., UV maps, canonical object frames), extending the unification to dense reconstruction tasks.
Load-bearing premise
That the headline 2D-3D and 3D-3D wins come from the unified architecture rather than from the pseudo point clouds back-projected from depth maps and the use of ground-truth keypoints as queries at test time — an ablation in the paper shows pseudo data alone moves 7Scenes registration recall from 15.4 to 77.8.
What would settle it
Retrain the same dual-stream model without pseudo point clouds and evaluate on 7Scenes and 3DLoMatch using detector-proposed (not ground-truth) keypoints, then compare against the same prior specialists evaluated under matched protocols. If the 8% and 10% registration-recall gains do not survive, the claimed advantage of the unified architecture is not what the headline numbers say it is.
Figures











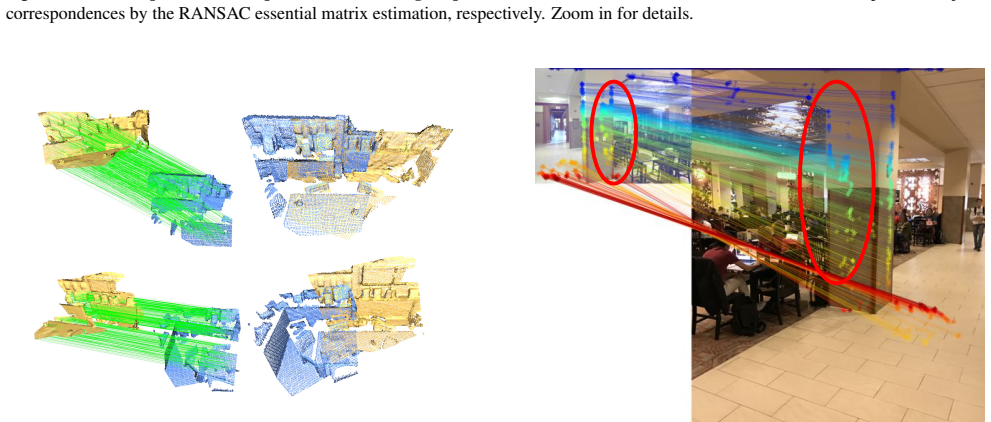
read the original abstract
Visual correspondence across image-to-image (2D-2D), image-to-point cloud (2D-3D), and point cloud-to-point cloud (3D-3D) geometric matching forms the foundation for numerous 3D vision tasks. Despite sharing a similar problem structure, current methods use task-specific designs with separate models for each modality combination. We present UniCorrn, the first correspondence model with shared weights that unifies geometric matching across all three tasks. Our key insight is that Transformer attention naturally captures cross-modal feature similarity. We propose a dual-stream decoder that maintains separate appearance and positional feature streams. This design enables end-to-end learning through stack-able layers while supporting flexible query-based correspondence estimation across heterogeneous modalities. Our architecture employs modality-specific backbones followed by shared encoder and decoder components, trained jointly on diverse data combining pseudo point clouds from depth maps with real 3D correspondence annotations. UniCorrn achieves competitive performance on 2D-2D matching and surpasses prior state-of-the-art by 8% on 7Scenes (2D-3D) and 10% on 3DLoMatch (3D-3D) in registration recall. Project website: https://neu-vi.github.io/UniCorrn
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents UniCorrn, a Transformer-based correspondence model with modality-specific backbones (ViT for images, PTv3 for point clouds) followed by a shared feature-fusion encoder and a shared "dual-stream" matching decoder that maintains separate appearance and positional residual streams sharing a single Gaussian-kernel attention matrix. The model is queried by source keypoints and regresses corresponding target coordinates from the updated positional stream via a Moore–Penrose inverse of a learned bijective absolute positional encoding. Trained jointly on 2D-2D, 2D-3D, and 3D-3D data (including pseudo point clouds derived from ScanNet++/ARKitScenes depth maps), the 600M-parameter model is reported as competitive on MegaDepth-1500/ScanNet-1500/InLoc 2D-2D, and as exceeding prior task-specific SOTA by ≈8% RR on 7Scenes (2D-3D) and ≈10% RR on 3DLoMatch (3D-3D). Ablations in Tables 1–2 and Fig. 4 support the dual-stream decoder, Gaussian attention, contrastive loss, feature upsampling, and auxiliary supervision.
Significance. If the headline numbers hold under fair controls, demonstrating that a single shared-weight Transformer can match three correspondence regimes at or above specialist level is a useful result for the community, particularly for downstream pipelines (SfM, SLAM, localization) that currently stitch together task-specific models. The dual-stream decoder with a shared Gaussian-kernel attention is a clean architectural idea: keeping appearance and position in separate residual streams while letting them jointly determine the matching cost is well-motivated, and the Moore–Penrose decoding of positional embeddings is elegant. The auxiliary-supervision visualization (Fig. 8) is informative and supports the claimed mechanism. The query-based interface (arbitrary source keypoints, arbitrary target modality) is a genuinely flexible design. Generalization to optical flow on Sintel without fine-tuning, while preliminary, is a falsifiable claim in the paper's favor.
major comments (4)
- [Table 8 vs. Tables 5–6 (headline claim)] The 8% RR gain on 7Scenes and 10% RR gain on 3DLoMatch are presented as evidence that the unified architecture surpasses specialists. However, supplementary Table 8 shows that removing pseudo point clouds drops 7Scenes RR from 77.8 → 15.4 and 3DLoMatch RR from 81.8 → 73.2. This implies that essentially all of the 7Scenes margin and the majority of the 3DLoMatch margin over Diff-Reg trace to pseudo-data augmentation, not to architecture. Specialists in Tables 5–6 (2D3D-MATR, B2-3Dnet, GeoT, RoITr, PEAL-3D, Diff-Reg) were trained without this augmentation. The comparison as currently written therefore conflates architecture, backbone scale, and training-set composition. At minimum the authors should (i) retrain at least one strong specialist (e.g., Diff-Reg or GeoT) on the same pseudo-augmented data, or (ii) report a UniCorrn variant trained on the same data the baselines saw, and (iii) re
- [Section 4.4 / Table 7 (joint-training synergy)] Section 4.4 argues unified training provides 'synergistic benefits,' but Table 7 shows single-task UniCorrn outperforms joint training on MegaDepth (AUC@5°: 56.5 vs 54.2) and 3DLoMatch (RR: 81.8 vs 83.2 — note: joint is actually higher on 3DLoMatch RR per Table 6 stage-2, so the table needs to be reconciled), with the clear gain (67.7 → 91.0) appearing only on 7Scenes (2D-3D), the smallest-data task. This is consistent with one-way transfer from the data-rich 2D-2D pool rather than a generic property of weight sharing. The conclusion 'demonstrating that the unified architecture provides a reasonable trade-off' should be tempered, and the inconsistency between Table 7's 3DLoMatch row and the stage-2 number reported in Table 6 (83.2) should be clarified.
- [Section 4.3 / Tables 5–6 (evaluation protocol)] The 2D-3D and 3D-3D evaluations use ground-truth keypoints as queries while the compared specialists predict their own keypoints. The paper acknowledges this and argues it does not advantage UniCorrn because specialists also use GT transformation for alignment, but this argument is not fully symmetric: a query-based model conditioned on GT source locations is in a meaningfully different regime than a detection-then-matching pipeline. Please add a control where UniCorrn is queried on detector keypoints (e.g., the same detector used by 2D3D-MATR or by Predator) so that the comparison is on equal footing, or at least quantify how much RR/IR degrades when queries come from a generic detector or grid sampling.
- [Section 3.1 / Table 1 backbone-scale attribution] The large model uses ViT-L initialized from CroCo v2 and totals 600M parameters, while specialist baselines are typically much smaller and use different pretraining. The ablations (Tables 1–2) are conducted with the small model, so they validate design choices internally but do not address whether the headline gains over specialists are due to architecture or to capacity + pretraining. A scale-matched comparison (e.g., a small UniCorrn vs. a similarly-sized specialist on the same training data) would strengthen the architecture claim. Alternatively, please add a row showing UniCorrn with a CroCo-v2-initialized ViT-L feeding a non-dual-stream decoder, to isolate the decoder's contribution at scale.
minor comments (10)
- [Title page / arXiv ID] The arXiv identifier 2605.04044 is in the future; please verify the correct identifier before camera-ready.
- [Eq. (6)] The decoding K_t = W_p^+(P_k − b_p) requires W_p to be (left-)invertible on its image; the text calls it 'bijective' but does not state the rank/initialization conditions that ensure this in practice. A sentence on how W_p is constrained or regularized would help reproducibility.
- [Eq. (5) / Section 3.2] The Gaussian attention is written as softmax(−PairL2(F'_k,F'_t)/D). Clarify whether the temperature is √D or D, since the vanilla case in Eq. (1) uses √D; the appendix Eq. (11) uses D. Please reconcile.
- [Table 2] Setups VI → VII change D from 64 to 256 after upsampling and AUC@5° jumps 48.5 → 50.6. Worth stating the parameter count delta so readers can judge whether the gain is from D or from upsampling.
- [Table 7] Please add columns for IR/FMR and report stds across runs; single-number comparisons of joint vs single-task training are noisy at this scale.
- [Section 4.3, InLoc] On DUC2 the gap to MASt3R is sizable (61.1/80.2/84.0 vs 71.0/87.0/91.6). A brief discussion of failure modes (Fig. 13 helps but is not referenced in the main text) would be appropriate.
- [Fig. 2] The diagram does not make clear which weights are shared across modalities vs. shared in the Siamese sense within a modality. A small legend would help.
- [Section 3.2] 'Our ablation study shows that it works better than other instantiations of Transformer for visual correspondences [26, 86]' — please point to the specific table/row supporting this claim (presumably Table 1 'sequence concatenation' and 'regression' rows).
- [Supp. Table 10] Inference time comparison would be more informative with a matched keypoint count and matched hardware setup; currently UniCorrn uses 5000 queries while specialists may use different counts.
- [Supp. Sec. C] The Sintel zero-shot EPE of 5.2 vs RAFT's 2.71 is reported as 'significant'; this framing is generous given RAFT is much smaller. Consider rewording as 'non-trivial zero-shot transfer' rather than implying competitive performance.
Simulated Author's Rebuttal
We thank the referee for a careful and constructive report. The four major comments converge on a single legitimate concern: the manuscript as written does not cleanly separate the contributions of (a) the dual-stream architecture, (b) backbone scale and CroCo-v2 pretraining, (c) pseudo point-cloud augmentation, and (d) the GT-keypoint query protocol. We accept this and will substantially revise Sections 4.3 and 4.4, the abstract, and the introduction to match what the experiments actually show.\n\nConcretely, the revision will: (1) reframe the headline 8%/10% RR claims as gains attributable to the *combination* of unified architecture and pseudo-data scaling, with an explicit no-pseudo-data UniCorrn row added to Tables 5–6 and at least one specialist (GeoT or Predator) retrained on our pseudo-augmented set; (2) drop the \"synergistic benefits\" language in Section 4.4 in favor of an honest description of asymmetric transfer from the data-rich 2D-2D pool to the data-poor 2D-3D task, and reconcile the Table 7 / Table 6 labeling; (3) add a detector-keypoint and grid-sampled query control for 7Scenes and 3DLoMatch so the comparison to detection-then-matching specialists is on equal footing; and (4) add a large-scale ablation replacing the dual-stream decoder with global matching under matched backbone, pretraining, and data, to isolate the decoder's contribution at 600M scale.\n\nWe acknowledge two limits we cannot fully close in this revision: a fully scale-matched specialist c
read point-by-point responses
-
Referee: Headline gains on 7Scenes (+8% RR) and 3DLoMatch (+10% RR) are confounded by pseudo point-cloud augmentation: Table 8 shows RR collapses to 15.4 (7Scenes) and 73.2 (3DLoMatch) without it. Specialists were trained without this data. Need either (i) a strong specialist retrained on the same pseudo data, or (ii) a UniCorrn variant trained on the baselines' data, and (iii) revised claims.
Authors: We accept this critique. Table 8 indeed shows pseudo data accounts for nearly all of the 7Scenes gain and a large fraction of the 3DLoMatch gain, and the comparison as written conflates architecture and training composition. For the revision we will (a) rewrite the abstract, introduction, and Section 4.3 to attribute the headline numbers to the *combination* of unified architecture and pseudo-data scaling rather than to architecture alone; (b) add a UniCorrn-no-pseudo row alongside the specialist-trained-without-pseudo numbers in Tables 5–6, which is the apples-to-apples comparison and which we can report directly from the Table 8 ablation (3DLoMatch RR 73.2 is already competitive with Diff-Reg's 73.8 and below PEAL-3D's 79.0; 7Scenes RR 15.4 is clearly *not* SOTA without pseudo data); and (c) retrain GeoT and/or Predator on our pseudo-augmented set to test whether pseudo data is a generic lever or specifically benefits our query-based architecture. We expect retraining one specialist within the revision window; if a second is infeasible we will say so explicitly. The revised framing will be: "a unified query-based architecture that, when combined with pseudo-data scaling, sets new SOTA on 2D-3D/3D-3D; pseudo data is a major contributor and the architecture is competitive but not dominant without it." revision: yes
-
Referee: Section 4.4's 'synergistic benefits' claim is not supported: Table 7 shows joint training hurts MegaDepth and is essentially flat on 3DLoMatch, with the only large gain on 7Scenes — the smallest-data task — consistent with one-way data transfer rather than synergy. Also reconcile the 3DLoMatch number between Table 7 (81.8 single, 83.2 joint) and Table 6 stage-2 (83.2).
Authors: We agree the language overreaches. The honest reading of Table 7 is asymmetric transfer: joint training substantially helps the data-poor 2D-3D task, marginally helps 3D-3D, and slightly hurts 2D-2D — consistent with the gradient-conflict analysis we already report for the normalization layers. We will rewrite Section 4.4 to (i) drop the word "synergistic," (ii) describe the result as "asymmetric, data-driven transfer from the 2D-2D pool to the data-poor 2D-3D regime, with mild interference on 2D-2D," and (iii) frame this as a limitation motivating future work on cross-modal normalization. Regarding the apparent inconsistency: Table 7's "single task" 3DLoMatch row (81.8) corresponds to our stage-1 model trained on 2D-2D + 3D-3D only (matching Table 6 stage 1: 86.7 — we will recheck and reconcile the exact numbers in proof), while "joint training" (83.2) is the stage-2 model trained on all three tasks (matching Table 6 stage 2: 83.2). The labeling in Table 7 is misleading; we will relabel the rows as "2D-2D + 3D-3D (stage 1)" vs. "all three tasks (stage 2)" and add a footnote pointing to the corresponding Table 6 rows. revision: yes
-
Referee: 2D-3D and 3D-3D evaluations use GT keypoints as queries while specialists detect their own. The argument that GT-transformation alignment by specialists makes this symmetric is not fully valid. Add a control with detector or grid-sampled queries.
Authors: This is a fair request and we will add the control. Specifically we will report, for 7Scenes (2D-3D) and 3DLoMatch (3D-3D), three query regimes: (a) GT keypoints (current Tables 5–6); (b) detector keypoints — SuperPoint on the image side and the same FCGF/Predator detector that 2D3D-MATR and Predator-2D3D use on the point-cloud side; and (c) uniform grid / farthest-point sampling. Regime (b) is the strictly fair comparison to the specialists' detection-then-matching pipelines. We have already used grid sampling on InLoc (Table 4) and detector keypoints from RoMa on MegaDepth/ScanNet (Table 3), so the infrastructure is in place. We expect IR and FMR to drop somewhat under (b)/(c) because queries land on less-textured regions; the question is whether RR (which is the headline metric and is dominated by RANSAC's ability to find an inlier set among many correspondences) degrades enough to change the ranking. We will report the numbers honestly regardless of outcome and revise claims accordingly. revision: yes
-
Referee: The 600M-parameter large model with CroCo-v2-initialized ViT-L vs. much smaller specialists with different pretraining means Tables 5–6 conflate architecture, scale, and pretraining. Ablations are at small scale only. Add a scale-matched comparison or a CroCo-v2 ViT-L + non-dual-stream decoder row to isolate the decoder's contribution at scale.
Authors: We agree the architecture vs. scale-and-pretraining attribution is currently unresolved at the large-model level. Two responses. First, the ablation in Table 1 (small scale, identical backbone and training data, varying only the decoder) does isolate the decoder contribution against nearest-neighbor, global-matching, regression, and sequence-concatenation alternatives, and the dual-stream decoder wins or ties across all three regimes; this is the cleanest causal evidence we have for the decoder. Second, we accept that this evidence is at small scale only. For the revision we will add a large-scale ablation row with the CroCo-v2-initialized ViT-L backbone and the same pseudo-augmented training data, but with the matching decoder replaced by global matching (the strongest alternative from Table 1), which directly isolates the dual-stream decoder's contribution at 600M scale. A fully scale-matched specialist comparison (i.e., training Diff-Reg or PEAL-3D at 600M with CroCo-v2 init) is beyond our compute budget within the revision window and we will state this limitation explicitly rather than claim architectural superiority that the experiments do not support. The revised claim will distinguish "the dual-stream decoder is the best matching mechanism we tested at controlled scale" from "UniCorrn-large achieves SOTA on 2D-3D/3D-3D," rather than conflating them. revision: partial
- A fully scale-matched comparison against specialists (e.g., training Diff-Reg or PEAL-3D with a 600M-parameter CroCo-v2-initialized backbone on identical data) is beyond our compute budget for this revision. We will state this as an open question rather than claim it has been resolved.
- We can retrain one strong specialist (GeoT or Predator) on our pseudo-augmented data within the revision window; retraining a second specialist may not be feasible and we will disclose this if so.
Circularity Check
No significant circularity: the paper's claims are evaluated against external benchmarks; the reader's concerns are about attribution/confounds, not circular derivation.
full rationale
UniCorrn is an empirical computer vision paper. Its central claim — that a single shared-weight Transformer with a dual-stream decoder achieves competitive 2D-2D and SOTA 2D-3D / 3D-3D results — is verified by comparison to externally-published baselines on standard benchmarks (MegaDepth-1500, ScanNet-1500, InLoc, 7Scenes, RGB-D Scenes V2, 3DMatch, 3DLoMatch, ModelNet). The numbers reported for competitor methods come from those methods' own published results, not from the present authors' re-derivation, so the head-to-head is externally falsifiable. I checked the paper for the seven circularity patterns: 1. Self-definitional: No. Loss is L1 against ground-truth keypoint coordinates from external datasets; nothing fitted is then "predicted." 2. Fitted-input-called-prediction: No. Training and test splits are standard public splits; the predictions are coordinates supervised against held-out GT. 3. Self-citation load-bearing: No. The architecture cites prior work (CroCo v2, PTv3, RoPE, MASt3R loss, InfoNCE, Pixel Shuffle) as components, not as uniqueness/forcing arguments. Citations to authors' own prior work (Gupta et al., direct superpoints matching) are background, not load-bearing for the central claim. 4. Uniqueness imported from authors: No such theorem is invoked. 5. Ansatz smuggled via citation: The Gaussian kernel and dual-stream design are presented as ablation-justified design choices (Tables 1–2, Fig. 4), not imported by ansatz. 6. Renaming known result: The "attention as matching cost" framing is acknowledged as similar to learnable cost volumes [74], cited explicitly — this is honest situating, not concealed renaming. The reader's concerns — that pseudo-point-cloud augmentation (Table 8: 7Scenes RR 15.4→77.8) drives most of the 3D headline gains, that joint training does not always beat single-task (Table 7), and that GT keypoint queries are used at evaluation — are legitimate but they are correctness/attribution risks (architecture-vs-data confound, evaluation protocol fairness), not circularity. The paper's derivation chain does not reduce to its own inputs by construction; it merely conflates architecture and training-data effects in the comparison. That belongs under correctness risk per the analyzer's hard rule #5. Score: 1 (minor: the SOTA framing on 2D-3D/3D-3D leans on a data advantage not shared by baselines, but no step in the derivation is definitionally circular).
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanJcost_G_eq_cosh_sub_one unclearwe replace the vanilla attention in Eq.(1) with a Gaussian variant A = Softmax(−PairL2(F'_k, F'_t)/D)... we use a Gaussian kernel to capture the non-linear complex correlations.
-
IndisputableMonolith/Foundation/ConstantDerivations.leanall_constants_from_phi unclearbuild our correspondence model with 600M parameters... trained jointly on diverse data combining pseudo point clouds from depth maps with real 3D correspondence annotations.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe present UniCorrn, the first correspondence model with shared weights that unifies geometric matching across 2D-2D, 2D-3D, and 3D-3D.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.