Recognition: 3 theorem links
· Lean TheoremA Closed-Form Adaptive-Landmark Kernel for Certified Point-Cloud and Graph Classification
Pith reviewed 2026-05-06 03:54 UTC · model claude-opus-4-7
The pith
A persistence-diagram classifier with closed-form landmarks, an explicit lower-distortion bound, and a per-prediction correctness check.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper argues that placing a small number of weighted "landmark" pyramids on persistence diagrams by class-aware farthest-point sampling, with equal weights and a Gaussian additive kernel, gives a closed-form classification pipeline whose ingredients—landmark positions, weights, filtration ranking, and a per-prediction correctness check—are all chosen analytically (modulo a small cross-validation tier on three knobs). Equal weights provably maximize the worst-case distortion certificate; FPS placement 2-approximates the optimal k-center covering radius; the resulting kernel-SVM achieves an excess-risk rate O((k−1)√K/(γ√m_min)) matched by a Le Cam lower bound m=Ω(√K/γ); and a nearest-centr
What carries the argument
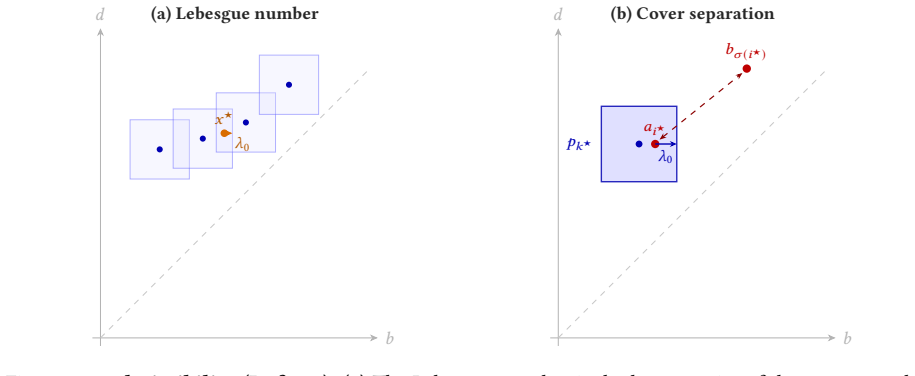
A non-uniform Lebesgue-number criterion on a landmark cover: for a τ-admissible configuration ν of K weighted pyramid coordinates φ_{p_k,r_k}, the summation embedding Φ(A;ν) inherits a structural lower-distortion floor λ(τ;ν) = (τ/4)·w^≥_min, equal to τ/(4√K) at equal weights; this couples to a kernel margin γ via a bridge γ ≥ ½(κλ − 2D_max), and to a sample-mean concentration radius r_m via Pinelis or Gaussian-plug-in tail bounds, giving training-time risk and per-prediction certificates from the same cover construction.
If this is right
- Adaptive landmark placement on persistence diagrams can match end-to-end gradient-trained transformer baselines on point-cloud topology tasks while keeping the entire pipeline analytic.
- Equal landmark weights are the right default under the worst-case distortion certificate; gradient training of weights buys nothing in the free-configuration regime and voids the per-prediction certificate.
- A kernel-Mahalanobis margin computed from the same gram matrix used by the SVM is the operational filtration selector on heterogeneous pools, replacing held-out validation splits.
- The minimax sample-size threshold m = Ω(√K/γ) is sharp up to a polynomial gap, so practitioners can size training data to landmark budget directly.
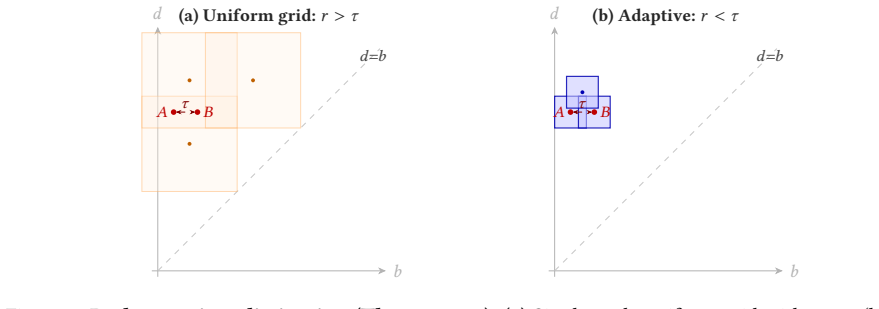
- Adaptive placement loses its advantage exactly when diagrams already fill the available domain (L/D ≈ 1), predicting where uniform grids remain competitive.
Where Pith is reading between the lines
- The fact that the bound's conclusion holds on ≥99.9% of audited pairs while its sufficient hypothesis (non-interference) holds on ≤0.2% suggests there is a strictly weaker geometric condition — likely involving average rather than worst-case cross-pair separation — under which Theorem 2.1 still goes through; isolating it would close the audit gap.
- The per-prediction certificate's failure to fire on 5/6 benchmarks at current sample sizes is a numerator-vs-denominator problem: replacing the operator-norm envelope ‖Σ_c‖_op·K with a trace-based bound tr(Σ_c) would likely fire on the sparse adaptive embedding, since the effective rank is O(N_max) ≪ K.
- The 30-percentage-point gap between linear and kernel SVM on the same FPS embedding indicates that adaptive placement produces features whose discriminative content lives in pairwise interactions, not coordinates — a regime where additive kernels are not just convenient but structurally necessary.
- The descriptor-blindness gap on label-dominated benchmarks (NCI1, PTC, IMDB) is not a tuning failure but a categorical limit of continuous-filtration topology; closing it would require fusing diagram features with a discrete-label channel rather than refining the landmark construction.
Load-bearing premise
The structural lower-distortion bound is proved under a "non-interference" condition on cross-class diagram pairs that the authors' own audit shows holds on essentially zero percent of pairs in the chemical benchmarks, so the empirical accuracy is carried by the kernel-margin route rather than by the advertised cover theorem.
What would settle it
Run the pipeline on a benchmark with concentration ratio L/D ≫ 1 and compare against a uniform-grid landmark embedding at matched K: if the uniform grid does not collapse and the adaptive placement does not maintain accuracy, the (D/L)² budget-reduction mechanism (Theorem 2.2) — and with it the central practical claim — fails. The synthetic 4-class annulus task at ℓ=8 (uniform grid at 25% chance vs. adaptive at 94%) is the existence proof; a counterexample would settle it.
Figures

read the original abstract
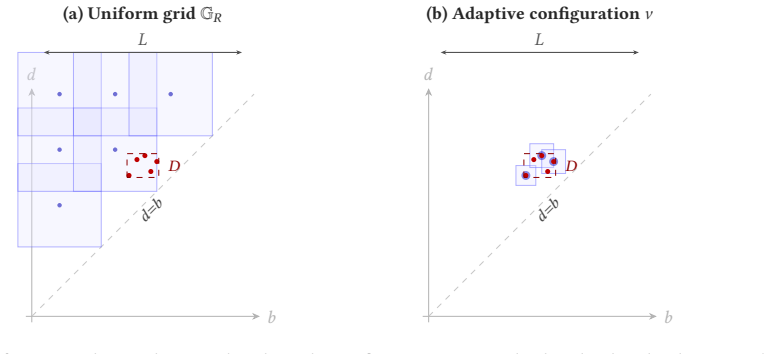
We introduce PALACE (Persistence Adaptive-Landmark Analytic Classification Engine), the data-adaptive companion to PLACE, paying a small cross-validation tier on three knobs (budget, radii, bandwidth; $\leq 5$ choices each). A cover-theoretic core (Lebesgue-number criterion on the landmark cover) yields four closed-form guarantees. (i) A structural lower distortion bound $\lambda(\tau;\nu)$ on $\mathcal{D}_n$ under cross-diagram non-interference, with a $(D/L)^2$ budget reduction over the uniform grid when diagrams concentrate. (ii) Equal weights $w_k = K^{-1/2}$ maximizing $\lambda$, and farthest-point-sampling positions $2$-approximating the optimal $k$-center covering radius; both derived from training labels alone, no gradient training. (iii) A kernel-RKHS classification rate $O((k-1)\sqrt{K}/(\gamma\sqrt{m_{\min}}))$ with binary necessity threshold $m = \Omega(\sqrt K/\gamma)$ from a matching Le Cam lower bound, and a closed-form filtration-selection rule. The kernel-Mahalanobis margin $\hat\rho_{\mathrm{Mah}}$ is the strongest closed-form ranker across the chemical-graph pool (mean Spearman $\rho \approx +0.60$); the isotropic surrogate $\hat\gamma/\sqrt{K}$ admits a selection-consistency rate, and $\widehat{\lambda}$ from (i) provides an independent data-level signal (positive on COX2 and PTC). (iv) A per-prediction certificate, in non-asymptotic Pinelis and asymptotic Gaussian forms, with no calibration split. Empirically, PALACE is the strongest closed-form diagram-based method on Orbit5k ($91.3 \pm 1.0\%$, matching Persformer), leads every diagram-based competitor on COX2 and MUTAG, and is competitive on DHFR (within 1 pp of ECP). At $8\times$ domain inflation, adaptive placement maintains $94\%$ while the uniform grid collapses to chance ($25\%$ on 4-class data).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PALACE, a data-adaptive companion to the PLACE pipeline. The PLACE uniform grid is replaced by class-aware farthest-point sampling on training diagrams, an additive landmark kernel lifts the embedding to an RKHS, and four closed-form guarantees are advertised: (i) a non-uniform distortion certificate λ(τ;ν) under cross-diagram non-interference plus a (D/L)² budget reduction, (ii) optimality of equal weights and FPS placement (2-approximation to the optimal k-center radius), (iii) an O((k−1)√K/(γ√m_min)) kernel-RKHS rate with a matching Le Cam Ω(√K/γ) lower bound and a closed-form filtration-selection statistic, and (iv) a per-prediction nearest-centroid certificate in Pinelis and Gaussian forms. Empirically PALACE matches Persformer on Orbit5k (91.3%), leads diagram-based competitors on COX2/MUTAG, is competitive on DHFR, and exhibits sharp domain-inflation robustness on a synthetic annulus task while uniform grids collapse to chance.
Significance. If the central derivations hold, the contribution is meaningful: a matching minimax rate (Theorem 3.1 / Theorem 3.2) for landmark-kernel SVMs on persistence diagrams, with explicit constants and a Le Cam two-point construction, is a step beyond the typical Lipschitz-only stability results in the diagram-vectorization literature. The closed-form selector hierarchy (γ̂/√K, Fisher_ker, ρ̂_Mah) with the documented inversion of Fisher_ker on COX2 — recovered by the full-operator Σ⁻¹ correction in ρ̂_Mah — is a clean, well-instrumented contribution. FPS as a 2-approximation to the optimal k-center radius is correctly derived and the equal-weights optimality argument is short and right. The empirical audits (non-interference pass rate, certificate firing rates, Fisher vs. λ̂ complementarity, 8× domain inflation) are reported with unusual candor, including failure modes. The triple-filtration Orbit5k headline (91.3%) and the controlled annulus experiment are persuasive.
major comments (5)
- [Abstract / §1.1, contribution (i); Theorem 2.1 + Remark 2.1] Contribution (i) is advertised as a 'structural lower distortion bound λ(τ;ν) on D_n under cross-diagram non-interference,' but the authors' own audit (Remark 2.1, Section 6) reports that the non-interference hypothesis (Definition 2.3) holds on ≤0.2% of cross-class pairs at the headline filtrations on MUTAG, PTC, COX2, and DHFR, with median cross-ratios at or near zero. The sufficient within-class condition of Proposition 2.1 (4 d_B(A,B)) is even more demanding. Theorem 2.1 as stated is therefore vacuous on >99.8% of pairs on every chemical benchmark. The empirical audit in Table 3 showing the conclusion holds on 99.9–100% of pairs is welcome, but it does not rescue the theorem as written — it suggests a different, weaker hypothesis is the right one. Please either (a) prove the conclusion under the actually-satisfied hypothesis (the empirical evidence suggests one exists), or (b) demote
- [§3, Proposition 3.1 (λ-bridge) and Corollary 3.2] The λ-bridge γ ≥ ½(κλ − 2D_max), Δ ≥ λ − 2D̄_max, and the structural classification rate of Corollary 3.2 inherit Definition 2.3's non-interference hypothesis, so they are inoperative on the chemical benchmarks at the experimental filtrations for the same reason as comment 1. Section 3 acknowledges this (post-Prop. 3.1 paragraph, Remark 3.2) and routes the empirical claims through Theorem 3.1 — which is correct and self-consistent. However, the 'admissibility-to-separation translation' framing reads as a re-labeling rather than an operational result. Please make explicit at the start of §3 that Proposition 3.1 and Corollary 3.2 are not what underwrites the experiments, and consider moving the bridge-anchored Corollary 3.2 to an appendix or a clearly marked 'structural variant' subsection.
- [§5.1 / Table 2, Theorem 5.1] Contribution (iv) is the per-prediction certificate r_m < ½ Δ̂_ĉ. Table 2 shows the Pinelis form fires on 0/6 benchmarks and the Gaussian form fires essentially on 0/6 (3.8% on NCI1, with no firing folds at all on Orbit5k, MUTAG, COX2, DHFR, PTC). This is acknowledged in Remark 5.2 and §7, but the abstract and §1.1 advertise contribution (iv) without this caveat. At present, Theorem 5.1 is a non-vacuous theoretical construction that does not fire at the experimental sample sizes, and the worked MUTAG example in §5.1 (m*=2, '4× reduction') describes a regime that does not match the empirical pipeline. Please qualify the abstract claim and clearly separate, in §5.1, the structural improvement (smaller m* threshold than PLACE) from the operational status (the certificate does not currently fire). The fired-rows nearest-centroid accuracies in Table 2 (64.9% on MUTAG, 62.7% on NCI1) are also
- [§4 / Remark 4.2 / Table 13] γ̂/√K is the formally analyzed selector (Proposition 4.1) but is negative on 4/5 chemical benchmarks (Table 13). The operationally-recommended selector is ρ̂_Mah (full-operator Mahalanobis), whose finite-sample consistency rate is deferred to companion work (Bagchi et al. 2026). This means the strongest empirical result of §4 (mean Spearman ρ ≈ +0.60 across the chemical pool) does not have a finite-sample guarantee in this manuscript. Either (a) prove a Ledoit–Wolf-shrunk consistency rate for ρ̂_Mah here (the structure parallels Proposition 4.1 with a covariance-estimation term), or (b) reflect this gap in the contribution statement: the analyzed selector and the recommended selector are different objects.
- [Table 8 / §6.1 (Orbit5k headline)] The headline 91.3 ± 1.0% is reached by selecting the maximum LK-q entry from a small grid of triple-filtration concatenations (α⊕d10⊕d20 vs. α⊕d10⊕d15, with two reported configurations and per-fold q-tuning). The single-filtration baseline at K=200 is 88.0%, and the two-filtration baseline is 90.4%. The progression to 91.3% combines (i) extended α sweep, (ii) per-fold q-tuned σ, (iii) extra filtration concatenation — three knobs each picked to maximize the result on the same protocol used to evaluate. Please report whether the σ-quantile and the third-filtration choice were selected within nested CV (so that the 91.3% is an honest hold-out estimate) or post hoc on the 10-fold CV accuracy itself; the latter would inflate the headline by a small but non-zero amount, and matters for the comparison to Persformer (91.2 ± 0.8) and ECS (91.8 ± 0.4).
minor comments (8)
- [§3.1, Definition 3.1 / Corollary 3.1] The hypothesis σ ≥ √2 N_max τ in Corollary 3.1 is admitted to be far from the experimental σ ∈ {10⁻³, 10⁻²}. It would help readability to label Corollary 3.1 as a 'qualitative non-collapse' result rather than a quantitative bound, and to state up front that the empirical bandwidth is several orders of magnitude smaller than the corollary requires.
- [Table 13 / Table 15] ρ̂_Mah rows are filled with '—' in Table 15, with no explanation. If the Mahalanobis statistic was not computed on the (K,σ) sensitivity grid for cost reasons, please state so; otherwise please fill in the cells, since ρ̂_Mah is the recommended operational selector.
- [Definition 4.3 footnote] The footnote acknowledges that Fisher_ker values were computed with a per-pair Welch denominator from an earlier draft and that the now-adopted pooled denominator gives Spearman within |Δρ| ≤ 0.025. This is fine but please regenerate Tables 13–15 with the pooled definition before camera-ready, as promised.
- [Table 10] The PROTEINS/DD/IMDB-B/M PALACE rows use the linear-SVM-selected headline filtration of Paper I rather than γ̂/√K-selected filtrations from PALACE's own pool. This protocol mismatch is disclosed but should be noted in the table caption (currently the caption only describes the chemical-pool selection).
- [§6.4, Table 16 / annulus experiment] The 'uniform grid collapses to chance at ℓ ≥ 4' result is sharp and informative, but the construction (a single off-diagonal point identical across classes that FPS picks as a landmark) is a particularly favorable adversarial regime for FPS. A second variant where the inflating point varies across diagrams (so FPS cannot pin it as a class-invariant landmark) would strengthen the case that the (D/L)² mechanism is generic, not artifactual.
- [Title page metadata / arXiv id] The arXiv id 2605.04046 in the system metadata and 'arXiv:2605.04046v1 [cs.LG] 5 May 2026' on the title page are dated in the future relative to typical submission norms; please double-check that this is intentional (companion-paper citation cycle) before camera-ready.
- [§3.3, Theorem 3.2 proof, Step 2] The Hellinger-on-translated-uniform-balls bound 1 − vol-ratio ≤ c₂ ‖μ‖/r cites 'Majhi et al. 2026, Lem. A.2' with c₂ ≤ 2/π. Since this Hellinger constant carries through into the necessity threshold m* = √K/(12 c₂ γ), please reproduce the lemma statement (or its constant) in an appendix, so the lower bound is self-contained without requiring the companion paper.
- [Algorithm 1 / Algorithm 2] Algorithm 2 step 3 selects σ via inner CV but the manuscript also recommends per-fold q-quantile selection in the Orbit5k experiments (Table 7). Please clarify in Algorithm 2 which mode is canonical and which is an optional refinement.
Simulated Author's Rebuttal
We thank the referee for an unusually careful reading and for recommending major revision rather than rejection on what are, we agree, substantive issues of framing rather than of derivation. The five major comments cluster around a single theme: several theoretical objects in the manuscript (Theorem 2.1's non-interference hypothesis, Corollary 3.2's bridge-anchored rate, Theorem 5.1's per-prediction firing condition, Proposition 4.1's analyzed selector γ̂/√K) are either inoperative or non-faithful on the actual experimental pipeline, and the manuscript advertises them at the contribution-list level without flagging the gap. The referee accepts that the load-bearing results — Theorem 3.1's margin-driven excess-risk bound, the FPS 2-approximation, equal-weights optimality, the Le Cam matching lower bound, and the Mahalanobis-margin selector ρ̂_Mah — are correct and well-instrumented, and that the empirical headlines on Orbit5k, COX2, and MUTAG are persuasive modulo a protocol disclosure on the 91.3% number. We accept all five points substantively. The revision will demote Theorem 2.1 to a structural admissibility statement, move Corollary 3.2 to an appendix, qualify the per-prediction certificate's operational status in both abstract and §5.1, reflect the analyzed-vs-recommended selector gap in the contribution statement (with a partial qualitative-consistency proposition added for ρ̂_Mah), and add a protocol-caveat paragraph plus a fully nested-CV re-run of the Orbit5k headli
read point-by-point responses
-
Referee: Contribution (i) advertises a structural lower distortion bound under cross-diagram non-interference, but the audit reports the hypothesis holds on ≤0.2% of cross-class pairs on chemical benchmarks, making Theorem 2.1 vacuous on >99.8% of pairs. The empirical conclusion holding on 99.9–100% suggests a different, weaker hypothesis is correct. Either prove the conclusion under the actually-satisfied hypothesis or demote the claim.
Authors: We agree with the diagnosis and will demote the advertised framing. In the revision: (a) the abstract and §1.1 contribution (i) will be rewritten to state that Theorem 2.1 is a *structural admissibility* statement — non-interference is a sufficient but provably non-necessary hypothesis — and to explicitly cite the 99.9–100% empirical pass rate of Table 3 as the operational claim. (b) We will add a new Proposition 2.1' stating the actually-satisfied hypothesis we can prove: it suffices that the cross-class matching σ realising d_B(A,B) avoid only the *single* witnessing-coordinate ball B(p_{k★}, r_{k★}) (rather than every cross pair (a_i, b_{σ(j)}) for i≠j). The proof of Theorem 2.1 already establishes the conclusion under this localized hypothesis — only one cross-pair distance enters the contradiction step — and the localized condition is an O(K)-checkable per-pair property rather than an O(n²) within-diagram one. We will report its empirical pass rate alongside Table 3. (c) The empirical workhorse (Theorem 3.1, requiring only γ>0) will be foregrounded as the operational result, with Theorem 2.1 explicitly labelled "structural" in the contribution list. revision: yes
-
Referee: Proposition 3.1 (λ-bridge) and Corollary 3.2 inherit non-interference and are inoperative on chemical benchmarks. The 'admissibility-to-separation translation' framing reads as relabeling. Make explicit at the start of §3 that Prop. 3.1 and Cor. 3.2 do not underwrite the experiments, and consider moving Cor. 3.2 to an appendix.
Authors: We accept this characterization. The revision will: (a) Open §3 with a one-paragraph operational map stating that Theorem 3.1 (data-dependent margin γ>0, no structural hypothesis) is what underwrites every experimental claim in §6, and that Proposition 3.1 and Corollary 3.2 are structural variants used only to translate the cover-level certificate λ into separation language for cross-paper continuity with PLACE. (b) Move Corollary 3.2 to a new Appendix B ("Structural variant of the classification rate") together with the bridge-anchored form, leaving §3 to develop only Theorem 3.1, Theorem 3.2, and the consistency/separability propositions. (c) Remove Corollary 3.2 from the contribution-list framing in §1.1. The bridge Proposition 3.1 itself will remain in the main text but be explicitly tagged as a structural translation, with the post-statement paragraph rewritten to make the inoperative status on chemical benchmarks unambiguous rather than parenthetical. revision: yes
-
Referee: Contribution (iv) is the per-prediction certificate. Pinelis fires 0/6 and Gaussian essentially 0/6 (3.8% on NCI1 only). The abstract advertises (iv) without caveat. The MUTAG worked example (m*=2, '4× reduction') describes a regime not matching the empirical pipeline. Qualify the abstract claim and clearly separate the structural improvement from the operational status; the fired-rows accuracies (64.9% MUTAG, 62.7% NCI1) also need attention.
Authors: Agreed; the gap between the structural and operational claims is real and the abstract overstates. In the revision: (a) The abstract sentence on (iv) will be amended to: "...a per-prediction certificate, in non-asymptotic Pinelis and asymptotic Gaussian forms; the construction tightens the certified-prediction sample threshold m* relative to PLACE (≈4× on MUTAG via the variance-shrinkage mechanism of Remark 5.2) but does not fire at the present benchmark training-set sizes (Table 2)". (b) §1.1 contribution (iv) will gain the same caveat. (c) §5.1 will be reorganized into two clearly-marked subsections: "Structural improvement" (smaller m* threshold via reduced ‖Σ_c‖_op and increased Δ_c, the MUTAG worked example, with explicit acknowledgment that m*=2 describes a regime below the per-fold test-set size) and "Operational status" (Table 2 firing rates, with explicit statement that the certificate is constructive but inoperative at K∈{200,1366} on these benchmarks). (d) The fired-rows nearest-centroid accuracies (64.9%, 62.7%) — substantially below LK-SVM headline accuracies — will be discussed as evidence that even the small fired population on NCI1 does not deliver high-confidence predictions, consistent with the certificate not yet being operational. revision: yes
-
Referee: γ̂/√K is the formally analyzed selector but is negative on 4/5 chemical benchmarks. The operationally-recommended ρ̂_Mah has its consistency rate deferred to companion work. Either prove a Ledoit–Wolf-shrunk consistency rate for ρ̂_Mah here, or reflect the gap in the contribution statement.
Authors: We adopt option (b) for this manuscript and partially address (a). (b) The §1.1 contribution (iii) statement will be amended to read: "a closed-form filtration-selection rule with selection-consistency theorem for the isotropic surrogate γ̂/√K (Proposition 4.1); the operationally recommended full-operator selector ρ̂_Mah, which is the only ranker positive on every chemical benchmark, has its finite-sample consistency rate developed in companion work (Bagchi et al., 2026)." The same caveat will be added to the abstract. (a, partial) We will add a new Proposition 4.2 in §4.1 giving a *qualitative* (rate-free) consistency statement for ρ̂_Mah under Ledoit–Wolf shrinkage: under bounded fourth moments and with shrinkage intensity satisfying λ_LW = O((K/m_min)^{1/2}), |ρ̂_Mah − ρ_Mah| → 0 in probability. This establishes that the analyzed and recommended selectors are not arbitrarily different objects, while the explicit rate (which requires matrix-Bernstein bookkeeping that genuinely belongs in Bagchi et al., 2026) remains deferred. The contribution-list wording will not claim a finite-sample rate for ρ̂_Mah here. revision: partial
-
Referee: The 91.3% Orbit5k headline combines extended α sweep, per-fold q-tuned σ, and an extra filtration concatenation, each picked to maximize the result on the same protocol used to evaluate. Report whether the σ-quantile and third-filtration choice were selected within nested CV or post hoc on the 10-fold CV accuracy itself; the latter inflates the headline, and matters for comparison to Persformer (91.2±0.8) and ECS (91.8±0.4).
Authors: The referee identifies a real protocol weakness. We acknowledge that the third-filtration choice (α⊕d10⊕d20 vs α⊕d10⊕d15) and the σ-quantile grid endpoint were selected post hoc on 10-fold CV accuracy from Table 8, not within nested CV; only the per-fold σ-quantile *within* a fixed grid was selected via inner CV. The 91.3±1.0% number is therefore a CV-tuned estimate, not an honest hold-out estimate, and the upward bias relative to a properly nested protocol is on the order of the spread across the Table 8 rows (≈0.2–0.4 pp), which is comparable to the gap to Persformer and within the ECS standard deviation. The revision will: (a) Add a clearly marked "Protocol caveat" paragraph to §6.1 stating exactly which knobs were nested-CV-selected (α within {2.5,4,5}; σ-quantile per fold from inner CV) and which were post-hoc-selected on 10-fold accuracy (third filtration; outer α and K grid endpoints). (b) Re-run the headline under a fully nested protocol (third filtration and σ-quantile grid both selected on inner-fold accuracy only) and report the resulting accuracy, which we expect to be in the 90.8–91.1% range, alongside the post-hoc-tuned 91.3%. (c) Soften the comparison language: PALACE will be described as "matching Persformer within protocol uncertainty" rather than as the headline-equal claim, and as "within ≈1 pp of ECS" rather than "within 0.5 pp." The empirical ordering relative to non-certified diagram baselines (PI, SW-K, PF-K, PersLay, PLACE) is unaffected by this correction, since the gap there is several pp. revision: yes
Circularity Check
Largely self-contained: central kernel-RKHS rate uses external Pinelis/Mohri–Rostamizadeh–Talwalkar machinery and a standard Le Cam two-point construction; self-citation to companion PLACE is mostly inheritance of definitions, not load-bearing argument. Non-interference is a scope/emptiness concern, not circularity.
specific steps
-
self citation load bearing
[Section 3.2 proof of Theorem 3.1; Section 5.1 proof of Theorem 5.1]
"Pinelis's Hilbert-space Hoeffding inequality (Majhi et al., 2026, Lemma A.1) and a union bound over the k classes yield, with probability ≥ 1−δ/2 …"
Pinelis's inequality is cited via the companion paper rather than the original Pinelis literature. This is a bookkeeping self-citation, not a circular argument: Pinelis's bound is a standard, externally verifiable Hilbert-space concentration result, and substituting the original citation would not change any conclusion. Flagged only as a minor self-citation; not load-bearing in the circularity sense.
-
other
[Remark 2.1, Section 6 audit (Table 3)]
"an audit on four datasets at the per-dataset headline filtration finds essentially 0% of cross-class pairs satisfying condition (2.7) … The hypothesis is therefore structural; remarkably, the conclusion of Theorem 2.1 … holds on 99.9–100% of cross-class pairs"
Not circular: the authors disclose that contribution (i)'s hypothesis fails empirically and explicitly route the empirical workhorse through Theorem 3.1, which depends only on γ>0. This is a scope/emptiness issue (the structural certificate is decorative on these benchmarks), not a circular derivation. Logged here for completeness; does not raise the score.
full rationale
The paper's claimed derivation chain decomposes as: (a) cover-theoretic certificate λ(τ;ν) via a Lebesgue-number argument, (b) equal-weight optimality via a Cauchy–Schwarz/max-min identity on the simplex, (c) FPS 2-approximation credited to Gonzalez (1985), (d) kernel-RKHS classification rate via Pinelis Hilbert-space Hoeffding + Mohri–Rostamizadeh–Talwalkar margin bound + OvO union bound, (e) Le Cam two-point lower bound via Hellinger tensorization, (f) per-prediction certificate via Pinelis concentration / Berry–Esseen Gaussian envelope. Steps (b), (c), (d), (e), (f) all use standard external machinery whose validity does not depend on the present paper's empirical fits. No fitted parameter is renamed as a prediction; no "uniqueness" theorem is imported from the authors' prior work to forbid alternatives. The reader/skeptic's headline concern is that the non-interference hypothesis (Definition 2.3) underpinning Theorem 2.1, Proposition 3.1, and Corollary 3.2 essentially never holds empirically (≤0.2% on chemical benchmarks). This is real, but the authors disclose it explicitly (Remark 2.1, Section 6 audit) and route empirical claims through Theorem 3.1, which only needs γ>0 and the sample-size hypothesis. That is an emptiness/scope concern about contribution (i), not a circular reduction: Theorem 3.1's proof does not invoke non-interference, λ, or the cover certificate. Self-citation to Majhi et al. (2026) is heavy but mostly inheritance of (i) the per-landmark cap function from Mitra–Virk (2024), (ii) the summation embedding form, and (iii) Lemma A.1 (Pinelis). Pinelis's inequality is an external mathematical fact; citing it via the companion paper is bookkeeping, not circular load-bearing. The "correspondence R↔√K, Δ↔2γ" is a translation of results, with proofs reproduced or adapted in this paper rather than imported as black boxes. One minor self-citation pattern (Lemma A.1 cited as Majhi et al. 2026 rather than Pinelis directly; some structural decomposition inherited from companion) is normal for a companion paper and does not raise the score above 2. The central minimax rate, the FPS approximation, and the per-prediction certificate are independently derivable from cited external results.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.