Recognition: 3 theorem links
· Lean TheoremContinual Distillation of Teachers from Different Domains
Pith reviewed 2026-05-10 18:12 UTC · model grok-4.3
The pith
A student model can sequentially distill knowledge from heterogeneous teachers across domains by preserving logits on external unlabeled data, reducing forgetting while improving generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By using only external unlabeled data and preserving the logits that each successive teacher produces on that data, a student can acquire and retain unseen knowledge from teachers with varying expertise, thereby reducing Unseen Knowledge Forgetting and improving cross-domain generalization in continual distillation settings.
What carries the argument
Self External Data Distillation (SE2D), a technique that preserves logits on external data to stabilize learning across heterogeneous teachers.
If this is right
- The student acquires information from domains absent from its own training data but known to the current teacher.
- Knowledge transferred from earlier teachers is retained rather than lost after training on later teachers.
- Cross-domain generalization improves on multiple standard benchmarks.
- All learning occurs using only external unlabeled data without any need to store or revisit prior teachers.
Where Pith is reading between the lines
- The approach could lower overall storage costs for large-scale models by allowing knowledge to be transferred without keeping every teacher in memory.
- It may support privacy-sensitive settings where original training sets cannot be shared but external data is available.
- Testing with gradually refreshed external data streams could reveal whether the method remains stable when the unlabeled pool evolves over time.
Load-bearing premise
That a fixed pool of external unlabeled data remains representative and sufficient to preserve logits across all successive teachers without introducing domain-specific bias.
What would settle it
An experiment in which the external data pool is drawn from a narrow distribution that misses several teacher domains, after which measured Unseen Knowledge Forgetting rises sharply compared with the paper's reported results.
Figures




read the original abstract
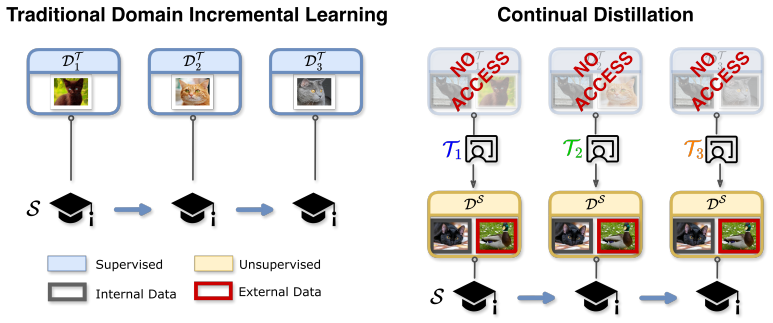
Deep learning models continue to scale, with some requiring more storage than many large-scale datasets. Thus, we introduce a new paradigm: Continual Distillation (CD), where a student learns sequentially from a stream of teacher models without retaining access to earlier teachers. CD faces two challenges: teacher training data is unavailable, and teachers have varying expertise. We show that external unlabeled data enables Unseen Knowledge Transfer (UKT), allowing the student to acquire information from domains not present in the training data, while known to the teacher. We also show that sequential distillation causes Unseen Knowledge Forgetting (UKF) when transferred knowledge is lost after training on later teachers. To better trade off between UKT and UKF, we propose Self External Data Distillation (SE2D), a method that preserves logits on external data to stabilize learning across heterogeneous teachers. Experiments on multiple benchmarks show that SE2D reduces UKF and improves cross-domain generalization. The code and implementation for this work are publicly available at: https://github.com/Nicolas1203/continual_distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Continual Distillation (CD), a paradigm in which a student model sequentially distills from a stream of heterogeneous teacher models without access to their original training data. It defines Unseen Knowledge Transfer (UKT) via external unlabeled data and Unseen Knowledge Forgetting (UKF) as the loss of prior transferred knowledge upon subsequent distillation steps. The proposed Self External Data Distillation (SE2D) method preserves teacher logits on a fixed external unlabeled pool to stabilize training and trade off UKT against UKF. Experiments across multiple benchmarks are reported to show that SE2D reduces UKF and improves cross-domain generalization, with code released publicly.
Significance. If the empirical claims hold under rigorous controls, the work addresses a practical gap in continual distillation under data-access constraints and heterogeneous teachers. The logit-preservation approach on external data is a lightweight stabilization technique that could extend to other sequential transfer settings. Public code release is a clear strength that supports reproducibility.
major comments (2)
- §4 (Experiments): The reported positive results on multiple benchmarks provide no quantitative details on the specific baselines, statistical significance tests, data splits, number of runs, or controls for post-hoc hyperparameter choices. Because the central claim that SE2D reduces UKF and improves generalization rests entirely on these empirical outcomes, the absence of such controls prevents verification of the effect sizes and reliability.
- §3.2 (SE2D method) and §4.2 (ablation studies): The method assumes a single fixed external unlabeled pool suffices to preserve logits from all successive heterogeneous teachers without domain bias or under-representation. No validation of pool coverage across teacher domains, no sensitivity analysis to pool composition, and no ablation removing or varying the pool are presented; if the pool skews toward any subset of domains, logit preservation could amplify rather than mitigate UKF, directly undermining the stabilization claim.
minor comments (2)
- §2 (Preliminaries): Formal definitions of UKT and UKF are given only procedurally; adding explicit mathematical statements (e.g., a forgetting metric over external data) would improve precision and allow direct comparison with related continual-learning metrics.
- Figure 1 and §3.1: The schematic of the CD pipeline would benefit from explicit annotation of the external data pool and the logit-preservation loss term to clarify the data flow.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, agreeing where the manuscript requires strengthening and outlining the planned revisions.
read point-by-point responses
-
Referee: §4 (Experiments): The reported positive results on multiple benchmarks provide no quantitative details on the specific baselines, statistical significance tests, data splits, number of runs, or controls for post-hoc hyperparameter choices. Because the central claim that SE2D reduces UKF and improves generalization rests entirely on these empirical outcomes, the absence of such controls prevents verification of the effect sizes and reliability.
Authors: We agree that the current experimental section lacks sufficient detail for full verification. In the revised manuscript we will expand §4 to report: the exact baseline implementations and their metrics, statistical significance results (paired t-tests with p-values across runs), precise data splits used for each benchmark, the number of independent runs (means and standard deviations over five random seeds), and the hyperparameter selection protocol (grid search performed on a held-out validation set prior to final testing). These additions will make the reported effect sizes and reliability transparent. revision: yes
-
Referee: §3.2 (SE2D method) and §4.2 (ablation studies): The method assumes a single fixed external unlabeled pool suffices to preserve logits from all successive heterogeneous teachers without domain bias or under-representation. No validation of pool coverage across teacher domains, no sensitivity analysis to pool composition, and no ablation removing or varying the pool are presented; if the pool skews toward any subset of domains, logit preservation could amplify rather than mitigate UKF, directly undermining the stabilization claim.
Authors: The referee correctly notes that the manuscript does not provide explicit validation or sensitivity analysis for the external pool. We will revise §3.2 to describe the pool construction process and add to §4.2: (i) quantitative coverage statistics across teacher domains, (ii) sensitivity experiments varying pool size and domain composition, and (iii) an ablation that removes or alters the pool (including domain-skewed variants) to measure impact on UKF. These results will clarify whether the chosen pool mitigates or risks amplifying forgetting. revision: yes
Circularity Check
No circularity: SE2D is a procedural method with empirical validation
full rationale
The paper defines Continual Distillation, introduces UKT and UKF as descriptive terms for transfer and forgetting phenomena, and proposes SE2D as an explicit procedure (preserve logits on a fixed external unlabeled pool to stabilize sequential distillation). The central claim that SE2D reduces UKF and improves cross-domain generalization is presented as an experimental outcome on benchmarks, not as a quantity derived by algebraic equivalence or redefinition from the method itself. No equations, fitted parameters renamed as predictions, self-citation load-bearing steps, or uniqueness theorems appear in the derivation chain. The external-data assumption is a substantive (and potentially falsifiable) modeling choice rather than a tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- logit-preservation weighting coefficient
axioms (1)
- domain assumption External unlabeled data drawn from a generic distribution can represent unseen knowledge possessed by each teacher
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SE2D ... preserves logits on external data to stabilize learning across heterogeneous teachers
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Unseen Knowledge Transfer (UKT) ... Unseen Knowledge Forgetting (UKF)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fixed external unlabeled data ... distillation dataset DS = De ∪ Di
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Foundation models defining a new era in vision: a survey and outlook
Muhammad Awais, Muzammal Naseer, Salman Khan, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Foundation models defining a new era in vision: a survey and outlook. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 47(4):2245–2264, 2025. 1
2025
-
[3]
Dark experience for general continual learning: a strong, simple baseline
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. Dark experience for general continual learning: a strong, simple baseline. InAdvances in Neural Information Processing Systems, pages 15920– 15930, 2020. 2
2020
-
[4]
Medium-difficulty samples constitute smoothed decision boundary for knowledge distillation on pruned datasets
Yudong Chen, Xuwei Xu, Frank de Hoog, Jiajun Liu, and Sen Wang. Medium-difficulty samples constitute smoothed decision boundary for knowledge distillation on pruned datasets. InThe Thirteenth International Conference on Learning Representations, 2025. 5
2025
-
[5]
Lifelong machine learning
Zhiyuan Chen and Bing Liu. Lifelong machine learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 12(3):1–207, 2018. 2
2018
-
[6]
Deep Learning for Classical Japanese Literature
Tarin Clanuwat, Mikel Bober-Irizar, Asanobu Kitamoto, Alex Lamb, Kazuaki Yamamoto, and David Ha. Deep learning for classical japanese literature.arXiv preprint arXiv:1812.01718, 2018. 5
work page Pith review arXiv 2018
-
[7]
Scaling multimodal founda- tion models in torchmultimodal with pytorch distributed
Ankita De, Edward Wang, Rohan Varma, Anjali Sridhar, and Kartikay Khandelwal. Scaling multimodal founda- tion models in torchmultimodal with pytorch distributed. https://pytorch.org/blog/scaling-multimodal-foundation- models-in-torchmultimodal-with-pytorch-distributed, 2025. 1
2025
-
[8]
A continual learning survey: Defying for- getting in classification tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3366–3385, 2021
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Ale ˇs Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying for- getting in classification tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3366–3385, 2021. 1
2021
-
[9]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1 (long and short papers), pages 4171– 4186, 2019. 1
2019
-
[10]
Class-incremental object detection.Pattern Recogni- tion, 139:109488, 2023
Na Dong, Yongqiang Zhang, Mingli Ding, and Yancheng Bai. Class-incremental object detection.Pattern Recogni- tion, 139:109488, 2023. 2
2023
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representa- tions, 2021. 1
2021
-
[12]
Podnet: Pooled outputs distil- lation for small-tasks incremental learning
Arthur Douillard, Matthieu Cord, Charles Ollion, Thomas Robert, and Eduardo Valle. Podnet: Pooled outputs distil- lation for small-tasks incremental learning. In16th Euro- pean Conference on Conputer Vision (ECCV), pages 86–102,
-
[13]
Domain-adversarial train- ing of neural networks
Yaroslav Ganin, Evgeniya Ustinova, Hubert Ajakan, Pas- cal Germain, Hugo Larochelle, Franc ¸ois Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial train- ing of neural networks. InInternational Conference on Ma- chine Learning, 2016. 5
2016
-
[14]
Resurrecting old classes with new data for exemplar- free continual learning
Dipam Goswami, Albin Soutif-Cormerais, Yuyang Liu, Sandesh Kamath, Bart Twardowski, Joost Van De Weijer, et al. Resurrecting old classes with new data for exemplar- free continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28525–28534, 2024. 3
2024
-
[15]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Yen-Chang Hsu, Yen-Cheng Liu, Anita Ramasamy, and Zsolt Kira. Re-evaluating continual learning scenarios: A categorization and case for strong baselines.arXiv preprint arXiv:1810.12488, 2018. 5
-
[17]
Jonathan J. Hull. A database for handwritten text recogni- tion research.IEEE Transactions on Pattern Analysis and Machine Intelligence, 16(5):550–554, 2002. 5
2002
-
[18]
Courier Corporation, 1997
Solomon Kullback.Information theory and statistics. Courier Corporation, 1997. 5
1997
-
[19]
The mnist database of handwritten digits
Yann LeCun. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/, 1998. 5
1998
-
[20]
Learning without forgetting
Zhizhong Li and Derek Hoiem. Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 40(12):2935–2947, 2017. 3, 4
2017
-
[21]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettle- moyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[22]
Rethinking momentum knowledge distillation in online continual learning
Nicolas Michel, Maorong Wang, Ling Xiao, and Toshihiko Yamasaki. Rethinking momentum knowledge distillation in online continual learning. InProceedings of the 41st In- ternational Conference on Machine Learning, pages 35607– 35622. PMLR, 2024. 2, 3, 5
2024
-
[23]
Reading digits in natural images with unsupervised feature learning
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bis- sacco, Baolin Wu, Andrew Y Ng, et al. Reading digits in natural images with unsupervised feature learning. InNIPS workshop on deep learning and unsupervised feature learn- ing, page 7, 2011. 5
2011
-
[24]
Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71,
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71,
-
[25]
Moment matching for multi-source domain adaptation
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 1406–1415,
-
[26]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational Conference on Machine Learning, pages 8748–8763, 2021. 1, 2
2021
-
[27]
Encoder based lifelong learning
Amal Rannen, Rahaf Aljundi, Matthew B Blaschko, and Tinne Tuytelaars. Encoder based lifelong learning. InPro- ceedings of the IEEE International Conference on Computer Vision, pages 1320–1328, 2017. 4
2017
-
[28]
icarl: Incremental classi- fier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classi- fier and representation learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017. 2, 5
2001
-
[29]
FitNets: Hints for Thin Deep Nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets.arXiv preprint arXiv:1412.6550,
work page internal anchor Pith review arXiv
-
[30]
Incremental object learning from contigu- ous views
Stefan Stojanov, Samarth Mishra, Ngoc Anh Thai, Nikhil Dhanda, Ahmad Humayun, Chen Yu, Linda B Smith, and James M Rehg. Incremental object learning from contigu- ous views. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8777– 8786, 2019. 5
2019
-
[31]
Logit standardization in knowledge distillation
Shangquan Sun, Wenqi Ren, Jingzhi Li, Rui Wang, and Xi- aochun Cao. Logit standardization in knowledge distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15731–15740, 2024. 5
2024
-
[32]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Three types of incremental learning.Nature Machine Intelligence, 4(12):1185–1197, 2022
Gido M van de Ven, Tinne Tuytelaars, and Andreas S To- lias. Three types of incremental learning.Nature Machine Intelligence, 4(12):1185–1197, 2022. 5
2022
-
[34]
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Be- longie. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technol- ogy, 2011. 5
2011
-
[35]
A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 1
2024
-
[36]
De-confounded data-free knowledge distillation for handling distribution shifts
Yuzheng Wang, Dingkang Yang, Zhaoyu Chen, Yang Liu, Siao Liu, Wenqiang Zhang, Lihua Zhang, and Lizhe Qi. De-confounded data-free knowledge distillation for handling distribution shifts. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 12615–12625, 2024. 1, 2
2024
-
[37]
Memory replay gans: Learning to generate new categories without forgetting.Advances in Neural Information Processing Systems, 31, 2018
Chenshen Wu, Luis Herranz, Xialei Liu, Joost Van De Wei- jer, Bogdan Raducanu, et al. Memory replay gans: Learning to generate new categories without forgetting.Advances in Neural Information Processing Systems, 31, 2018. 3
2018
-
[38]
A gift from knowledge distillation: Fast optimization, network minimization and transfer learning
Junho Yim, Donggyu Joo, Jihoon Bae, and Junmo Kim. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 4133–4141, 2017. 2
2017
-
[39]
Decoupled knowledge distillation
Borui Zhao, Quan Cui, Renjie Song, Yiyu Qiu, and Jiajun Liang. Decoupled knowledge distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11953–11962, 2022. 2, 5 A. Experimental Setup A.1. Implementation Details For training, we start from pre-trained weights and use the Adam optimizer with a learning rate...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.