Recognition: unknown
Single-Position Intervention Fails: Distributed Output Templates Drive In-Context Learning
Pith reviewed 2026-05-10 16:43 UTC · model grok-4.3
The pith
Task identity for in-context learning is encoded as output format templates distributed across demonstration tokens rather than localized at single positions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In-context learning task identity is encoded as output format templates distributed across demonstration tokens. Single-position activation interventions achieve 0 percent task transfer despite 100 percent probing accuracy at the same positions. Simultaneous multi-position intervention on all demonstration output tokens achieves up to 96 percent transfer at layer 8, with a universal window near 30 percent network depth across LLaMA, Qwen, and Gemma families. The query position is strictly necessary while no individual demonstration position is, and transfer depends on internal representation compatibility rather than surface similarity.
What carries the argument
Multi-position activation intervention that simultaneously replaces activations at all demonstration output tokens to test transfer of task identity.
Load-bearing premise
The interventions isolate task identity without unintended effects on other model computations.
What would settle it
A single model or task in which single-position activation intervention produces substantial task transfer while multi-position intervention does not.
Figures



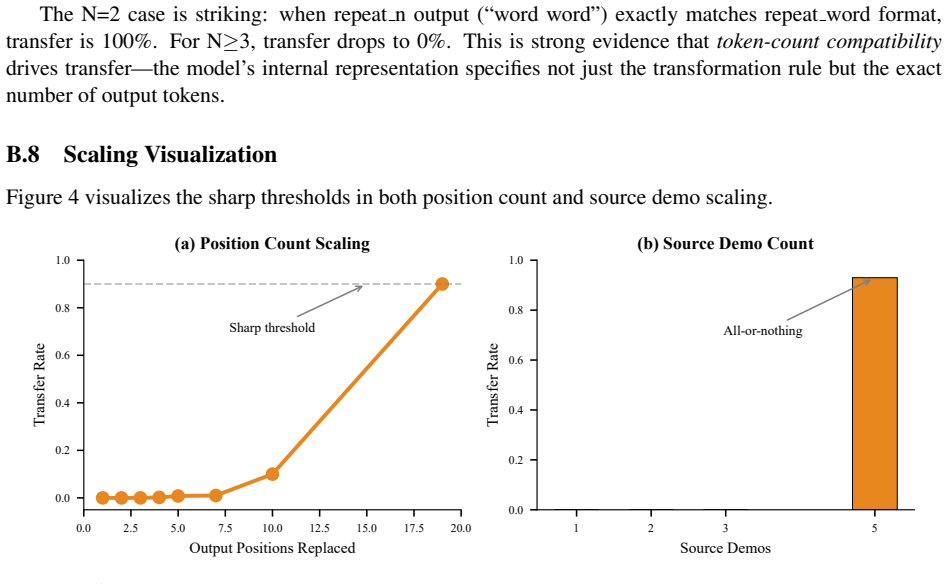
read the original abstract
Understanding how large language models encode task identity from few-shot demonstrations is a central open problem in mechanistic interpretability. Prior work uses linear probing to localize task representations, reporting high classification accuracy at specific layers. We reveal a striking dissociation: probing accuracy completely fails to predict causal importance. Single-position activation intervention achieves 0% task transfer across all 28 layers of Llama-3.2-3B-despite 100% probing accuracy at those same positions. This null result is itself a key finding, demonstrating that task encoding is fundamentally distributed. Multi-position intervention-replacing activations at all demonstration output tokens simultaneously-achieves up to 96% transfer (N=50, 95% CI: [87%, 99%]) at layer 8, pinpointing for the first time the causal locus of ICL task identity. We establish the generality of these findings across four models spanning three architecture families (LLaMA, Qwen, Gemma), discovering a universal intervention window at ~30% network depth. Causal tracing uncovers an asymmetric architecture: the query position is strictly necessary (53-100% disruption) while no individual demonstration position is necessary (0% disruption)-resolving a key ambiguity in prior accounts. Crucially, transfer depends on internal representation compatibility, not surface similarity (r=-0.05 vs r=0.31), ruling out trivial explanations. These results establish the distributed template hypothesis: ICL task identity is encoded as output format templates distributed across demonstration tokens, fundamentally reshaping our understanding of how in-context learning operates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in-context learning (ICL) task identity in LLMs is encoded as distributed output format templates across demonstration tokens rather than at single positions. This is evidenced by a dissociation where single-position activation interventions yield 0% task transfer across all 28 layers of Llama-3.2-3B despite 100% probing accuracy at those positions, while simultaneous multi-position interventions replacing activations at all demonstration output tokens achieve up to 96% transfer (N=50, 95% CI [87%, 99%]) at layer 8. The findings generalize across four models from three architecture families with a universal intervention window at ~30% network depth; causal tracing shows the query position is necessary (53-100% disruption) but no individual demonstration is; and transfer correlates with internal representation compatibility (r=0.31) rather than surface similarity (r=-0.05).
Significance. If the central dissociation and causal specificity hold, this work would be significant for mechanistic interpretability by demonstrating that linear probing accuracy does not predict causal importance for ICL and by providing the first intervention-based localization of task identity to distributed output templates. The manuscript earns credit for reporting concrete transfer rates with confidence intervals, cross-model consistency across LLaMA, Qwen, and Gemma families, and falsifiable predictions about intervention windows and compatibility. These elements strengthen the empirical foundation even if interpretive controls need strengthening.
major comments (2)
- [multi-position intervention results] The multi-position intervention results (abstract and results section): the claim that simultaneous replacement at all demonstration output tokens isolates task identity as distributed output templates is load-bearing but under-supported without controls that hold total intervention magnitude constant while varying task content. Replacing a large set of activations at once could produce transfer via broad disruption to attention patterns, residual streams, or value vectors rather than selective template transfer; the moderate compatibility correlation (r=0.31) does not yet rule this out.
- [causal tracing experiments] Causal tracing paragraph (abstract): the asymmetric finding that the query position is strictly necessary while individual demonstrations are not is presented as resolving prior ambiguities, but the manuscript does not test whether the joint multi-position effect is additive versus interactive in a task-specific way. An ablation comparing joint replacement to summed single-position effects would directly address whether the locus is specifically the output templates.
minor comments (2)
- [abstract] The abstract and methods should explicitly define the transfer rate metric, including how baselines and chance levels are computed, to allow readers to assess the 0% and 96% figures.
- [results figures] Figure or table captions reporting the N=50, 95% CI, and layer-8 results should include details on error bar computation and any multiple-comparison corrections applied.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript to incorporate the suggested controls and ablations where feasible.
read point-by-point responses
-
Referee: The multi-position intervention results (abstract and results section): the claim that simultaneous replacement at all demonstration output tokens isolates task identity as distributed output templates is load-bearing but under-supported without controls that hold total intervention magnitude constant while varying task content. Replacing a large set of activations at once could produce transfer via broad disruption to attention patterns, residual streams, or value vectors rather than selective template transfer; the moderate compatibility correlation (r=0.31) does not yet rule this out.
Authors: We agree that controls holding total intervention magnitude constant while varying task content would strengthen the isolation of template-specific transfer. Single-position interventions already apply comparable per-position activation replacements yet produce 0% transfer, indicating the effect is not driven by scale alone. The compatibility correlation provides supporting evidence of specificity. We will add new experiments intervening on matched numbers of positions but with task-mismatched templates to directly test against non-specific disruption. revision: yes
-
Referee: Causal tracing paragraph (abstract): the asymmetric finding that the query position is strictly necessary while individual demonstrations are not is presented as resolving prior ambiguities, but the manuscript does not test whether the joint multi-position effect is additive versus interactive in a task-specific way. An ablation comparing joint replacement to summed single-position effects would directly address whether the locus is specifically the output templates.
Authors: The causal tracing results show 0% disruption from any single demonstration position, which already implies the multi-position effect cannot be explained by simple addition of independent contributions and instead reflects a distributed, interactive mechanism. We nevertheless agree that an explicit ablation comparing joint multi-position replacement to the summed effects of single-position interventions would provide clearer evidence and will include this analysis in the revision. revision: yes
Circularity Check
No significant circularity in empirical derivation chain
full rationale
The paper reports direct experimental results from activation interventions, linear probing, and causal tracing on multiple LLMs. No mathematical derivations, parameter fits presented as predictions, or self-citations are used to establish the central claims. The dissociation between probing accuracy and intervention transfer, the multi-position patching results, and the query-position necessity findings are measured outcomes rather than quantities that reduce to their own inputs by construction. This matches the default expectation for experimental mechanistic interpretability work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation interventions at chosen positions isolate task identity without collateral effects on unrelated model computations.
invented entities (1)
-
distributed output templates
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and others , title =. Advances in Neural Information Processing Systems , volume =
-
[2]
Advances in Neural Information Processing Systems , volume =
Garg, Shivam and Tsipras, Dimitris and Liang, Percy and Valiant, Gregory , title =. Advances in Neural Information Processing Systems , volume =
-
[3]
Findings of the Association for Computational Linguistics: ACL 2023 , pages =
Dai, Damai and Sun, Yutao and Dong, Li and Hao, Yaru and Ma, Shuming and Sui, Zhifang and Wei, Furu , title =. Findings of the Association for Computational Linguistics: ACL 2023 , pages =
2023
-
[4]
Transformer Circuits Thread , year =
Olsson, Catherine and Elhage, Nelson and Nanda, Neel and Joseph, Nicholas and DasSarma, Nova and Henighan, Tom and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and others , title =. Transformer Circuits Thread , year =
-
[5]
Transformer Circuits Thread , year =
Elhage, Nelson and Nanda, Neel and Olsson, Catherine and Henighan, Tom and Joseph, Nicholas and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and others , title =. Transformer Circuits Thread , year =
-
[6]
International Conference on Learning Representations , year =
Todd, Eric and Li, Millicent L and Sharma, Arnab Sen and Mueller, Aaron and Wallace, Byron C and Bau, David , title =. International Conference on Learning Representations , year =
-
[7]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
Hendel, Roee and Geva, Mor and Globerson, Amir , title =. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
2023
-
[8]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
Ravfogel, Shauli and Elazar, Yanai and Gonen, Hila and Twiton, Michael and Goldberg, Yoav , title =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
-
[9]
Transactions of the Association for Computational Linguistics , volume =
Elazar, Yanai and Ravfogel, Shauli and Jacovi, Alon and Goldberg, Yoav , title =. Transactions of the Association for Computational Linguistics , volume =
-
[10]
Advances in Neural Information Processing Systems , volume =
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Singer, Yaron and Shieber, Stuart , title =. Advances in Neural Information Processing Systems , volume =
-
[11]
Advances in Neural Information Processing Systems , volume =
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , title =. Advances in Neural Information Processing Systems , volume =
-
[12]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics , pages =
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus , title =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics , pages =
-
[13]
International Conference on Machine Learning , pages =
Zhao, Zihao and Wallace, Eric and Feng, Shi and Klein, Dan and Singh, Sameer , title =. International Conference on Machine Learning , pages =
-
[14]
Steering Language Models With Activation Engineering
Turner, Alexander Matt and Thiergart, Lisa and Udell, David and Leech, Gavin and Mini, Ulisse and MacDiarmid, Monte , title =. arXiv preprint arXiv:2308.10248 , year =
work page internal anchor Pith review arXiv
-
[15]
Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Vol.\ 1 , publisher =
Hinton, Geoffrey E and McClelland, James L and Rumelhart, David E , title =. Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Vol.\ 1 , publisher =
-
[16]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages =
Min, Sewon and Lyu, Xinxi and Holtzman, Ari and Artetxe, Mikel and Lewis, Mike and Hajishirzi, Hannaneh and Zettlemoyer, Luke , title =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages =
2022
-
[17]
Bai, Jinze and Bai, Shuai and Chu, Yunfei and Cui, Zeyu and Dang, Kai and Deng, Xiaodong and Fan, Yang and Ge, Wenbin and Han, Yu and Huang, Fei and others , title =. arXiv preprint arXiv:2309.16609 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Gemma: Open Models Based on Gemini Research and Technology
Gemma: Open models based on. arXiv preprint arXiv:2403.08295 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Transactions of the Association for Computational Linguistics , volume =
Belinkov, Yonatan and Glass, James , title =. Transactions of the Association for Computational Linguistics , volume =
-
[20]
Advances in Neural Information Processing Systems , volume =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , title =. Advances in Neural Information Processing Systems , volume =
-
[21]
Transactions on Machine Learning Research , year =
Wei, Jason and Tay, Yi and Bommasani, Rishi and Raffel, Colin and Zoph, Barret and Borgeaud, Sebastian and Yogatama, Dani and Bosma, Maarten and Zhou, Denny and Metzler, Donald and others , title =. Transactions on Machine Learning Research , year =
-
[22]
Transformers learn in-context by gradient descent , booktitle =
Von Oswald, Johannes and Niklasson, Eyvind and Randazzo, Ettore and Sacramento, Jo. Transformers learn in-context by gradient descent , booktitle =
-
[23]
What learning algorithm is in-context learning? Investigations with linear models , booktitle =
Aky. What learning algorithm is in-context learning? Investigations with linear models , booktitle =
-
[24]
Transformer Circuits Thread , year =
Elhage, Nelson and Hume, Tristan and Olsson, Catherine and Schiefer, Nicholas and Henighan, Tom and Kravec, Shauna and Hatfield-Dodds, Zac and Lasenby, Robert and Drain, Dawn and Chen, Carol and others , title =. Transformer Circuits Thread , year =
-
[25]
International Conference on Learning Representations , year =
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , title =. International Conference on Learning Representations , year =
-
[26]
Towards automated circuit discovery for mechanistic interpretability , journal =
Conmy, Arthur and Mavor-Parker, Augustine N and Lynch, Aengus and Heimersheim, Stefan and Garriga-Alonso, Adri. Towards automated circuit discovery for mechanistic interpretability , journal =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.