Recognition: no theorem link
Validity-Calibrated Reasoning Distillation
Pith reviewed 2026-05-12 02:26 UTC · model grok-4.3
The pith
Reasoning distillation improves when update strength is modulated by the local validity of each next step rather than by exact trajectory imitation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Validity-calibrated reasoning distillation treats the problem as local learning-signal allocation rather than path alignment. Instead of enforcing token-level imitation, the method compares the student's and teacher's proposed next-step actions under the same prefix and uses their relative local validity to modulate the strength of the distillation update. This produces a context-dependent supervision mechanism that adapts to the under-specified character of intermediate reasoning steps.
What carries the argument
The validity calibration mechanism, which quantifies relative local validity of next-step actions under shared prefixes to dynamically adjust distillation update strength.
If this is right
- The method outperforms strong distillation baselines on mathematical reasoning benchmarks.
- It delivers improved performance on code generation tasks.
- It yields gains on instruction-following evaluations.
- Effective reasoning distillation is governed by principled locally calibrated allocation of learning signal rather than rigid trajectory imitation.
Where Pith is reading between the lines
- The calibration approach may reduce sensitivity to suboptimal intermediate choices in teacher outputs, allowing use of noisier or more diverse trajectories.
- Similar local validity modulation could apply to other sequential generation settings where steps are locally under-specified.
- Implementation would benefit from studying how validity scores are computed in practice and whether they require separate estimators.
Load-bearing premise
The relative local validity of next-step actions under the same prefix can be reliably quantified and used to modulate updates without introducing biases or requiring additional unstated mechanisms for validity assessment.
What would settle it
A benchmark or set of prefixes where relative local validity between student and teacher proposals cannot be consistently quantified or where the modulated updates produce no gain or worse results than standard trajectory imitation on the mathematical reasoning, code generation, and instruction-following tasks.
Figures

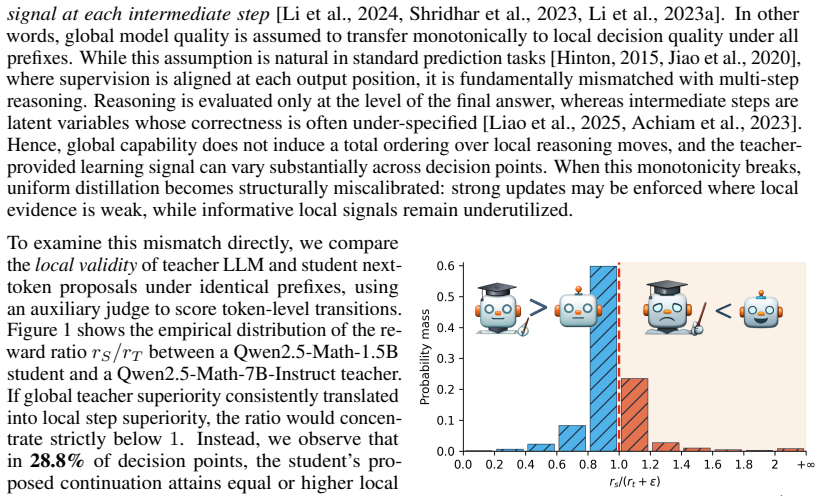
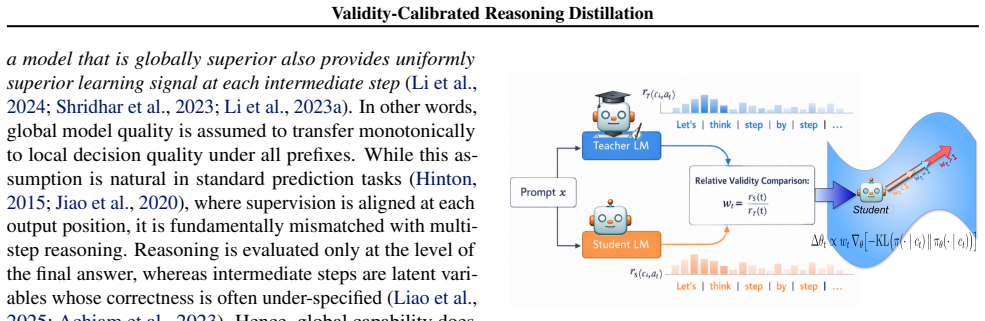


read the original abstract
Reasoning distillation aims to transfer multi-step reasoning capabilities from large language models to smaller, more efficient ones. While recent methods have shown promising gains, they typically rely on static teacher-student hierarchies and frame distillation as trajectory imitation. This is misaligned with the structure of reasoning, where intermediate steps are often locally under-specified: global correctness constrains the final answer, but does not uniquely determine each intermediate move. We propose validity-calibrated reasoning distillation, a framework that treats reasoning distillation as a problem of local learning-signal allocation rather than path alignment. Instead of enforcing token-level imitation, we compare the student's and teacher's proposed next-step actions under the same prefix and use their relative local validity to modulate the strength of the distillation update. This yields a dynamic, context-dependent supervision mechanism that preserves the teacher's structural guidance while adapting update strength to local reasoning quality. Across mathematical reasoning, code generation, and instruction-following benchmarks, our method consistently outperforms strong distillation baselines. These results indicate that effective LLM reasoning distillation is governed not by rigid trajectory imitation, but by principled, locally calibrated allocation of learning signal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes validity-calibrated reasoning distillation as an alternative to standard trajectory-imitation approaches in transferring multi-step reasoning from large to small LLMs. It frames distillation as local learning-signal allocation: under a shared prefix, the student's and teacher's next-step proposals are compared via their relative local validity, which then modulates the strength of the distillation update to produce dynamic, context-dependent supervision. The abstract claims this yields consistent outperformance over strong baselines across mathematical reasoning, code generation, and instruction-following benchmarks, implying that effective reasoning distillation depends on principled local calibration rather than rigid path alignment.
Significance. If the local-validity computation proves reproducible, free of unstated external oracles or biases, and the reported gains survive proper controls, the work could meaningfully advance LLM distillation by replacing static imitation with adaptive signal allocation. This would provide a concrete mechanism for handling the under-specification of intermediate reasoning steps and could influence how future distillation methods allocate learning signal in multi-step tasks.
major comments (2)
- [Abstract / Method description] The procedure for computing relative local validity of next-step actions (the core of the proposed modulation) is not defined: the abstract and visible description supply no equation, algorithm, pseudocode, or explicit components (e.g., whether it uses teacher log-probabilities, an external verifier, or another heuristic). This is load-bearing for the central claim, because the outperformance is attributed specifically to this validity-calibrated allocation rather than standard distillation; without the definition it is impossible to assess novelty, reproducibility, or whether the method collapses to existing techniques.
- [Experimental results] The experimental claim of consistent outperformance supplies no implementation details, validity metrics, experimental controls, benchmark specifications, baseline reproductions, or data on how local validity was actually computed during training. This leaves the results unsupported and prevents evaluation of whether gains arise from the claimed mechanism or from unstated factors such as data filtering or regularization.
minor comments (1)
- [Abstract] The abstract uses the phrase 'principled, locally calibrated allocation of learning signal' without a preceding formalization or reference to the specific validity function, which reduces clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity and completeness, particularly around the core method definition and experimental reporting. We address each point below and have prepared revisions to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract / Method description] The procedure for computing relative local validity of next-step actions (the core of the proposed modulation) is not defined: the abstract and visible description supply no equation, algorithm, pseudocode, or explicit components (e.g., whether it uses teacher log-probabilities, an external verifier, or another heuristic). This is load-bearing for the central claim, because the outperformance is attributed specifically to this validity-calibrated allocation rather than standard distillation; without the definition it is impossible to assess novelty, reproducibility, or whether the method collapses to existing techniques.
Authors: We agree that the abstract and high-level description do not supply the explicit formulation. In the revised manuscript we have added Equation (2) in Section 3.2, which defines relative local validity as the normalized difference in next-token log-probabilities between teacher and student under the identical prefix, together with the modulation factor applied to the distillation loss. We also include Algorithm 1 (pseudocode) that shows the full local-signal allocation procedure and a short discussion contrasting it with standard trajectory imitation. These additions make the mechanism fully specified, reproducible, and clearly distinct from prior work. revision: yes
-
Referee: [Experimental results] The experimental claim of consistent outperformance supplies no implementation details, validity metrics, experimental controls, benchmark specifications, baseline reproductions, or data on how local validity was actually computed during training. This leaves the results unsupported and prevents evaluation of whether gains arise from the claimed mechanism or from unstated factors such as data filtering or regularization.
Authors: We acknowledge the need for greater transparency. The revised experimental section now contains: complete training hyperparameters and the exact procedure for computing local validity (teacher log-probabilities only, no external verifier), full benchmark specifications with data splits, reproduction instructions and hyperparameter settings for every baseline, an ablation table isolating the contribution of validity calibration, and additional controls that rule out simple data filtering or regularization effects. These changes allow direct assessment of whether the reported gains stem from the proposed mechanism. revision: yes
Circularity Check
No significant circularity detected; method introduces independent local validity modulation.
full rationale
The paper proposes validity-calibrated reasoning distillation as a new framework that compares student and teacher next-step proposals under identical prefixes and modulates updates by their relative local validity. This is framed as an alternative to trajectory imitation rather than a derivation that reduces to fitted inputs or self-referential definitions. No equations or steps in the abstract reduce the claimed allocation mechanism to its own outputs by construction, and benchmark outperformance is evaluated against external tasks without load-bearing self-citations or uniqueness theorems. The central claim remains independent of the inputs it seeks to explain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Local validity of proposed next reasoning steps can be meaningfully compared between models under identical prefixes
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
AI-MO. Amc 2023 dataset. https://huggingface.co/datasets/AI-MO/ aimo-validation-amc,
work page 2023
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Mixed distillation helps smaller language models reason better
Li Chenglin, Qianglong Chen, Liangyue Li, Caiyu Wang, Feng Tao, Yicheng Li, Zulong Chen, and Yin Zhang. Mixed distillation helps smaller language models reason better. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 1673–1690,
work page 2024
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Enhancing chat language models by scaling high-quality instructional conversations
10 Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3029–3051,
work page 2023
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computational Linguistics: ACL 2023, pages 8003–8017,
work page 2023
-
[12]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
TinyBERT: Distilling BERT for natural language understanding
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. TinyBERT: Distilling BERT for natural language understanding. In Trevor Cohn, Yulan He, and Yang Liu, editors,Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4163–4174, Online, November
work page 2020
-
[14]
LongEval: Guidelines for human evaluation of faithfulness in long-form summariza- tion
Association for Computational Linguistics. doi: 10.18653/v1/ 2020.findings-emnlp.372. URL https://aclanthology.org/2020.findings-emnlp.372/. Yoon Kim and Alexander M. Rush. Sequence-level knowledge distillation. In Jian Su, Kevin Duh, and Xavier Carreras, editors,Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages...
-
[15]
Sequence-Level Knowledge Distillation
Association for Computational Linguistics. doi: 10.18653/v1/D16-1139. URL https://aclanthology.org/ D16-1139/. Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. Distillm: Towards streamlined distillation for large language models. InInternational Conference on Machine Learning, pages 24872–24895. PMLR,
-
[16]
Explanations from large language models make small reasoners better.arXiv preprint arXiv:2210.06726,
Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai Wei Chang, and Yejin Choi. Symbolic chain-of-thought distillation: Small models can also “think” step-by-step. In61st Annual Meeting of the Association for Computational Linguistics, ACL 2023, pages 2665–2679. Association for Computational Linguistics (ACL), 2023a. Shiyang Li, Jianshu Chen, Yelon...
-
[17]
Xiang Li, Shizhu He, Jiayu Wu, Zhao Yang, Yao Xu, Yang jun Jun, Haifeng Liu, Kang Liu, and Jun Zhao. Mode-cotd: Chain-of-thought distillation for complex reasoning tasks with mixture of de- coupled lora-experts. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), page...
work page 2024
-
[18]
Alpacaeval: an automatic evaluator of instruction-following models (2023)
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, CG Ishaan Gulrajani, P Liang, and TB Hashimoto. Alpacaeval: an automatic evaluator of instruction-following models (2023). URL https://github. com/tatsu-lab/alpaca_eval, 2023b. Baohao Liao, Yuhui Xu, Hanze Dong, Junnan Li, Christof Monz, Silvio Savarese, Doyen Sahoo, and Caiming Xiong. Reward-guided spec...
work page 2023
-
[19]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
arXiv preprint arXiv:2402.14830 , year=
12 Arindam Mitra, Hamed Khanpour, Corby Rosset, and Ahmed Awadallah. Orca-math: Unlocking the potential of slms in grade school math.arXiv preprint arXiv:2402.14830,
-
[21]
Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of gpt-4.arXiv preprint arXiv:2306.02707,
-
[22]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2080–2094,
work page 2021
-
[23]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reason- ing in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Kumar Shridhar, Alessandro Stolfo, and Mrinmaya Sachan. Distilling reasoning capabilities into smaller language models.Findings of the Association for Computational Linguistics: ACL 2023, pages 7059–7073,
work page 2023
-
[25]
Cmath: Can your language model pass chinese elementary school math test?arXiv:2306.16636,
Tianwen Wei, Jian Luan, Wei Liu, Shuang Dong, and Bin Wang. Cmath: Can your language model pass chinese elementary school math test?arXiv preprint arXiv:2306.16636,
-
[26]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jian- hong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Reasonflux: Hierarchical LLM reasoning via scaling thought templates
Ling Yang, Zhaochen Yu, Bin Cui, and Mengdi Wang. Reasonflux: Hierarchical llm reasoning via scaling thought templates.arXiv preprint arXiv:2502.06772, 2025a. Ling Yang, Zhaochen Yu, Tianjun Zhang, Minkai Xu, Joseph E Gonzalez, Bin CUI, and Shuicheng YAN. Supercorrect: Advancing small llm reasoning with thought template distillation and self- correction. ...
-
[28]
arXiv:2305.12474 (2023).https://doi.org/10.48550/ arXiv.2305.12474
Xiaotian Zhang, Chunyang Li, Yi Zong, Zhengyu Ying, Liang He, and Xipeng Qiu. Evaluating the performance of large language models on gaokao benchmark.arXiv preprint arXiv:2305.12474,
-
[29]
Agieval: A human-centric benchmark for evaluating foundation models
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. Agieval: A human-centric benchmark for evaluating foundation models. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 2299–2314,
work page 2024
-
[30]
James drives at 30 mph for half an hour. Then he drives at twice the speed for twice as long, which means he drives at a speed of 3×30 = 6· · ·2×30 = 6· · ·0.360 0.827 2.30 Student. “Twice the speed” requires multiply- ing by 2, giving2×30 = 60mph. 7 Related Work Reasoning.Recent advances in large language model reasoning have been driven by explicit mult...
work page 2022
-
[31]
3): The MATH dataset contains thousands of competition-style mathematical questions spanning algebra, geometry, combinatorics, number theory, probability, and more. It includes detailed step-by-step solutions generated from a procedural codebase, enabling rigorous evaluation of a model’s ability to perform symbolic and multi-step mathematical reasoning at...
work page 2021
-
[32]
6): Gaokao2023-EN contains English translations of math questions from the 2023 Chinese National College Entrance Examination (Gaokao). The dataset features concise, exam-style problems across algebra, geometry, trigonometry, and applied math. Its formulation emphasizes careful reading, multi-step reasoning, and robustness to linguistically minimal prompt...
work page 2023
-
[33]
8): AMC23 contains problems from the 2023 American Mathematics Competition, focusing on algebra, geometry, combinatorics, and number theory at the mid-competition level. The dataset evaluates a model’s ability to navigate moderately challenging problems that require structured reasoning rather than memorized patterns. AIME24(mathematical reasoning; MAA
work page 2023
-
[34]
9): AIME24 consists of problems from the 2024 American Invitational Mathematics Examination. These questions demand multi-step derivations, precise algebraic manipulation, and careful numerical reasoning, providing a sensitive test of a model’s ability to avoid compounding local reasoning errors. SAT-Math(mathematical reasoning; Zhong et al
work page 2024
-
[35]
10): SAT-Math evaluates models on algebra, arithmetic reasoning, function interpretation, and geometry tasks from the SAT exam. While less challenging than competition benchmarks, the dataset tests robustness under shorter, mixed-format reasoning questions. CMATH(mathematical reasoning; Wei et al. [2023]): CMATH is a curated collection covering a broad se...
work page 2023
-
[36]
13): MBPP contains approximately 1,000 crowdsourced Python programming tasks aimed at entry-level programmers. Each problem includes a description and test cases covering basic programming constructs such as loops, list manipulation, strings, and simple algorithms. MBPP is widely used to measure fundamental code-generation abilities and correctness. MBPP+...
work page 2022
-
[37]
Following the setup of Ko et al
Student models are first initialized via supervised finetuning on task-specific datasets with ground-truth responses, after which validity- calibrated distillation is applied. Following the setup of Ko et al. [2025], we do not use any language- modeling loss on pretraining corpora. For all experiments, we used FlashAttention and bf16 precision. For mathem...
work page 2025
-
[38]
Mathematical reasoning performance is measured using the EvalPlus framework [Liu et al., 2023], which executes predicted solutions to verify correctness. For code generation, we use the HumanEval, HumanEval+, MBPP, and MBPP+ evaluation suites, all executed with their official test harnesses to ensure consistency and prevent overfitting to reference implem...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.