Recognition: unknown
AsymmetryZero: A Framework for Operationalizing Human Expert Preferences as Semantic Evals
Pith reviewed 2026-05-10 13:05 UTC · model grok-4.3
The pith
Human expert preferences can be operationalized as explicit semantic evaluation contracts where compact model juries achieve high agreement with frontier juries at much lower cost and latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By fixing the evaluation contracts and testing frontier versus compact juries, the work shows that criterion-level agreement reaches 75.9 to 89.6 percent and strict agreement 77.8 to 92.1 percent, with compact juries using 4.2 to 5.6 percent of the cost and 21.7 to 27.1 percent of the latency while keeping aggregated outcomes stable. This supports the idea that expert preferences can be faithfully encoded into semantic evals via explicit contracts.
What carries the argument
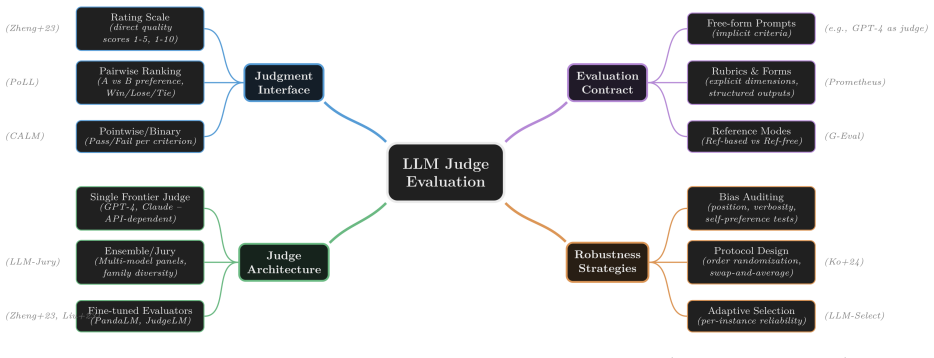
The evaluation contract, which explicitly defines the grading criteria, judgment process for each, and aggregation rules into a task outcome, serving as the fixed structure executed by model juries.
If this is right
- Frontier and compact juries agree on 75.9 to 89.6 percent of criterion judgments.
- Compact juries display higher internal dissent with 28.7 to 32.4 percent three-to-two splits versus 6.1 to 11.5 percent for frontier juries.
- Per-criterion judging costs for compact juries fall to 4.2 to 5.6 percent of frontier jury costs.
- Latency for compact juries is reduced to 21.7 to 27.1 percent of frontier levels.
- Task-level outcomes remain comparatively stable even with jury differences.
Where Pith is reading between the lines
- Designing stable contracts upfront could decouple evaluation quality from the scale of the judging models.
- Disagreements within compact juries might serve as signals for refining contract criteria in future iterations.
- Similar contract-based approaches could apply to other fields requiring consistent application of expert judgment, such as legal review or quality assurance.
Load-bearing premise
Human expert preferences can be faithfully captured in stable, explicit evaluation contracts without significant information loss or introduction of new biases.
What would settle it
Finding that human experts, when applying the contracts themselves to sample tasks, produce judgments that systematically differ from those of either jury on a large fraction of criteria would falsify the claim of faithful capture.
Figures


read the original abstract
Much of the focus in RL today is on evaluation design: building meaningful evals that serve simultaneously as benchmarks and as well-defined reward signals for post-training. Yet, many real-world tasks are governed by subjective, procedural, and domain-specific requirements that are difficult to encode as exact-match targets or open-ended preference judgments frequently used in RL pipelines today. In this work, we present AsymmetryZero, a framework for operationalizing human expert preferences as semantic evals. AsymmetryZero represents each task as a stable evaluation contract that makes grading criteria explicit: what is being graded, how each criterion is judged, and how criterion-level decisions are aggregated into a task outcome. The same contract can be executed using Inspect for model-only evaluations, as well as the Harbor Framework for agentic evaluations, enabling comparable scores and shared audit artifacts across both settings. We argue that the central challenge in post-training today is the faithful encoding of expert requirements into the evaluation itself. To that end, we present a study using Harbor that holds task contracts fixed and compares a five-model frontier jury against a five-model compact jury across four frontier-class solvers (Claude Opus 4.6, GPT-5.4, Grok-4.20, Gemini-3.1-Pro). We find that criterion-level frontier-vs-compact agreement ranges from $75.9\%$ to $89.6\%$ (strict common-subset agreement: $77.8\%$ to $92.1\%$), while compact juries exhibit substantially higher internal dissent (3--2 split rate $28.7\%$--$32.4\%$) than frontier juries ($6.1\%$--$11.5\%$). Verifier traces further show that compact juries reduce per-criterion judging cost to roughly $4.2\%$--$5.6\%$ of frontier and latency to roughly $21.7\%$--$27.1\%$, even as aggregated task-level outcomes often remain comparatively stable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AsymmetryZero, a framework that encodes tasks as explicit evaluation contracts specifying grading criteria, judgment procedures, and aggregation rules to operationalize human expert preferences as semantic evaluations usable with both model-only (Inspect) and agentic (Harbor) setups. It reports an empirical study holding contracts fixed while comparing a five-model frontier jury to a five-model compact jury across four frontier solvers, finding criterion-level agreement of 75.9–89.6% (strict common-subset 77.8–92.1%), higher internal dissent in compact juries (28.7–32.4% 3–2 splits vs. 6.1–11.5%), and compact-jury cost/latency reductions to roughly 4.2–5.6% and 21.7–27.1% of frontier values, with task-level outcomes remaining comparatively stable.
Significance. If the contracts prove to be faithful encodings of expert preferences, the framework offers a route to more auditable, reproducible, and cost-efficient semantic evaluations that could serve as both benchmarks and reward signals in post-training. The reported cost and latency savings, together with the fixed-contract design that enables direct jury comparisons, are concrete strengths that would be valuable if the fidelity claim is substantiated.
major comments (2)
- [Abstract and empirical study] Abstract and the empirical study: the central claim that evaluation contracts faithfully operationalize human expert preferences without significant information loss or new biases is not directly tested. The study measures only inter-model agreement and cost/latency deltas between frontier and compact juries on fixed contracts; it reports no human-expert ratings of the same contracts, no inter-rater reliability between humans and contract-derived judgments, and no ablation of contract wording against original expert intent. This leaves the proxy validity of model-jury agreement unestablished.
- [Abstract] Abstract: specific numerical claims (agreement ranges, 3–2 split rates, cost reductions to 4.2–5.6% and latency to 21.7–27.1%) are presented without accompanying details on contract construction process, data exclusion rules, statistical significance testing, or full methodology, which undercuts the ability to assess the robustness of the reported agreement and stability results.
minor comments (1)
- The paper would benefit from an explicit section or appendix detailing the contract template, example contracts, and the exact aggregation rule used to produce task-level outcomes from criterion decisions.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below, clarifying the scope of the empirical study and committing to revisions where appropriate to improve clarity and precision.
read point-by-point responses
-
Referee: [Abstract and empirical study] Abstract and the empirical study: the central claim that evaluation contracts faithfully operationalize human expert preferences without significant information loss or new biases is not directly tested. The study measures only inter-model agreement and cost/latency deltas between frontier and compact juries on fixed contracts; it reports no human-expert ratings of the same contracts, no inter-rater reliability between humans and contract-derived judgments, and no ablation of contract wording against original expert intent. This leaves the proxy validity of model-jury agreement unestablished.
Authors: We agree with this assessment. The empirical study is specifically designed to hold evaluation contracts fixed and compare the behavior of frontier versus compact model juries in terms of agreement rates, internal consistency, and computational cost. It does not include direct human validation or ablation studies against original expert intent. The claim that the framework operationalizes human preferences is supported by the explicit contract design and its executability in both model-only and agentic settings, but the reported numbers reflect model-model agreement rather than human-model fidelity. We will revise the abstract to explicitly state that the study evaluates inter-jury agreement and efficiency under fixed contracts, without claiming direct empirical validation of preference encoding fidelity. This will better align the abstract with the study's actual contributions. revision: yes
-
Referee: [Abstract] Abstract: specific numerical claims (agreement ranges, 3–2 split rates, cost reductions to 4.2–5.6% and latency to 21.7–27.1%) are presented without accompanying details on contract construction process, data exclusion rules, statistical significance testing, or full methodology, which undercuts the ability to assess the robustness of the reported agreement and stability results.
Authors: The abstract is intended as a high-level summary, with full methodological details—including contract construction, model specifications, aggregation procedures, and any data handling—provided in the dedicated Experimental Setup and Results sections of the manuscript. We did not perform formal statistical significance testing on the agreement metrics, as the study reports descriptive comparisons across fixed contracts rather than inferential statistics. To improve accessibility, we will revise the abstract to briefly reference the methodology and direct readers to the full paper for details on contract construction and data processing. We can also note the descriptive nature of the results. revision: partial
Circularity Check
Framework definition and empirical jury comparisons are independent measurements with no reductions to inputs by construction
full rationale
The paper defines AsymmetryZero as an explicit evaluation contract framework and reports direct empirical results from a fixed-contract study: criterion-level agreement rates (75.9–89.6%), internal dissent splits, and cost/latency deltas between frontier and compact model juries. These quantities are measured outputs, not derived from or equivalent to the framework definition. No equations, fitted parameters presented as predictions, self-citations, or ansatzes appear in the load-bearing steps. The central claims rest on observable agreement and resource metrics rather than tautological re-labeling or self-referential justification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human expert preferences for complex tasks can be operationalized into stable, explicit criteria, judgment rules, and aggregation functions without substantial loss of fidelity.
invented entities (1)
-
Evaluation contract
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Humans or LLM s as the Judge? A Study on Judgement Bias
Chen, Guiming Hardy and Chen, Shunian and Liu, Ziche and Jiang, Feng and Wang, Benyou , booktitle =. Humans or. 2024 , address =. doi:10.18653/v1/2024.emnlp-main.474 , url =
-
[2]
GPTS core: Evaluate as You Desire
Fu, Jinlan and Ng, See-Kiong and Jiang, Zhengbao and Liu, Pengfei , booktitle =. 2024 , address =. doi:10.18653/v1/2024.naacl-long.365 , url =
-
[3]
A Survey on
Gu, Jiawei and Jiang, Xuhui and Shi, Zhichao and Tan, Hexiang and Zhai, Xuehao and Xu, Chengjin and Li, Wei and Shen, Yinghan and Ma, Shengjie and Liu, Honghao and Wang, Saizhuo and Zhang, Kun and Wang, Yuanzhuo and Gao, Wen and Ni, Lionel and Guo, Jian , howpublished =. A Survey on. 2024 , url =
2024
-
[4]
Hashemi, Helia and Eisner, Jason and Rosset, Corby and Van Durme, Benjamin and Kedzie, Chris , booktitle =. 2024 , address =. doi:10.18653/v1/2024.acl-long.745 , url =
-
[5]
International Conference on Learning Representations , year =
Prometheus: Inducing Fine-Grained Evaluation Capability in Language Models , author =. International Conference on Learning Representations , year =
-
[6]
Proceedings of the 24th Annual Conference of the European Association for Machine Translation , year =
Large Language Models Are State-of-the-Art Evaluators of Translation Quality , author =. Proceedings of the 24th Annual Conference of the European Association for Machine Translation , year =
-
[7]
Findings of the Association for Computational Linguistics: ACL 2024 , year =
Benchmarking Cognitive Biases in Large Language Models as Evaluators , author =. Findings of the Association for Computational Linguistics: ACL 2024 , year =. doi:10.18653/v1/2024.findings-acl.29 , url =
-
[8]
International Conference on Learning Representations , year =
Generative Judge for Evaluating Alignment , author =. International Conference on Learning Representations , year =
-
[9]
Who Judges the Judge?
Li, Xiaochuan and Wang, Ke and Gouda, Girija Manash and Choudhary, Shubham and Wang, Yaqun and Hu, Linwei and Vaughan, Joel and Lecue, Freddy , howpublished =. Who Judges the Judge?. 2025 , url =
2025
-
[10]
2004 , address =
Lin, Chin-Yew , booktitle =. 2004 , address =
2004
-
[11]
G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =. 2023 , address =. doi:10.18653/v1/2023.emnlp-main.153 , url =
-
[12]
and Feng, Shi , booktitle =
Panickssery, Arjun and Bowman, Samuel R. and Feng, Shi , booktitle =. 2024 , url =
2024
-
[13]
Proceedings of the 40th Annual Meeting on Association for Computational Linguistics , pages =
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , booktitle =. 2002 , address =. doi:10.3115/1073083.1073135 , url =
-
[14]
Journal of Informatics and Web Engineering , year =
HybridEval: An Improved Novel Hybrid Metric for Evaluation of Text Summarization , author =. Journal of Informatics and Web Engineering , year =. doi:10.33093/jiwe.2024.3.3.15 , url =
-
[15]
Judging the Judges: A Systematic Study of Position Bias in
Shi, Lin and Ma, Chiyu and Liang, Wenhua and Diao, Xingjian and Ma, Weicheng and Vosoughi, Soroush , booktitle =. Judging the Judges: A Systematic Study of Position Bias in. 2025 , address =
2025
-
[16]
Play Favorites: A Statistical Method to Measure Self-Bias in
Spiliopoulou, Evangelia and Fogliato, Riccardo and Burnsky, Hanna and Soliman, Tamer and Ma, Jie and Horwood, Graham and Ballesteros, Miguel , howpublished =. Play Favorites: A Statistical Method to Measure Self-Bias in. 2025 , url =
2025
-
[17]
2024 , url =
Large Language Models are Inconsistent and Biased Evaluators , author =. 2024 , url =
2024
-
[18]
Replacing Judges with Juries: Evaluating
Verga, Pat and Hofstatter, Sebastian and Althammer, Sophia and Su, Yixuan and Piktus, Aleksandra and Arkhangorodsky, Arkady and Xu, Minjie and White, Naomi and Lewis, Patrick , howpublished =. Replacing Judges with Juries: Evaluating. 2024 , url =
2024
-
[19]
2026 , url =
Vidgen, Bertie and Mann, Austin and Fennelly, Abby and Stanly, John Wright and Rothman, Lucas and Burstein, Marco and Benchek, Julien and Ostrofsky, David and Ravichandran, Anirudh and Sur, Debnil and Venugopal, Neel and Hsia, Alannah and Robinson, Isaac and Huang, Calix and Varones, Olivia and Khan, Daniyal and Haines, Michael and Bridges, Austin and Boy...
2026
-
[20]
2024 , url =
Wang, Yidong and Yu, Zhuohao and Yao, Wenjin and Zeng, Zhengran and Yang, Linyi and Wang, Cunxiang and Chen, Hao and Jiang, Chaoya and Xie, Rui and Wang, Jindong and Xie, Xing and Ye, Wei and Zhang, Shikun and Zhang, Yue , booktitle =. 2024 , url =
2024
-
[21]
Justice or Prejudice? Quantifying Biases in
Ye, Jiayi and Wang, Yanbo and Huang, Yue and Chen, Dongping and Zhang, Qihui and Moniz, Nuno and Gao, Tian and Geyer, Werner and Huang, Chao and Chen, Pin-Yu and Chawla, Nitesh V and Zhang, Xiangliang , booktitle =. Justice or Prejudice? Quantifying Biases in. 2025 , url =
2025
-
[22]
2021 , url =
Yuan, Weizhe and Neubig, Graham and Liu, Pengfei , booktitle =. 2021 , url =
2021
-
[23]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , url =
2023
-
[24]
Towards a Unified Multi-Dimensional Evaluator for Text Generation
Towards a Unified Multi-Dimensional Evaluator for Text Generation , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year =. doi:10.18653/v1/2022.emnlp-main.131 , url =
-
[25]
2025 , url =
Zhu, Lianghui and Wang, Xinggang and Wang, Xinlong , booktitle =. 2025 , url =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.