Are LLMs Ready for Conflict Monitoring? Empirical Evidence from West Africa
Pith reviewed 2026-05-08 17:44 UTC · model grok-4.3
The pith
Current LLMs show systematic biases in classifying West African conflict events and are not ready for unsupervised deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
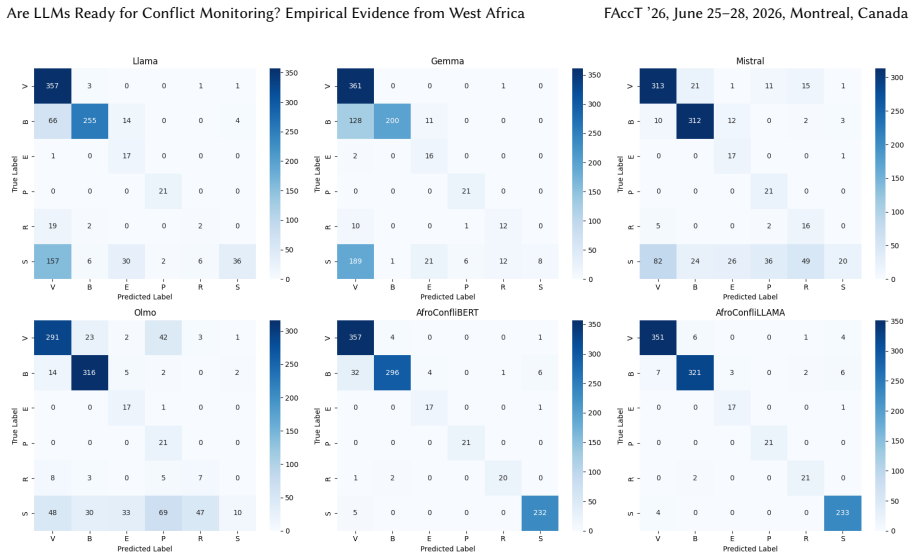
The evaluation reveals a bifurcated divergence: open-weight models exhibit statistically significant false illegitimation bias by misclassifying legitimate battles as civilian-targeted violence while committing zero false legitimation errors, whereas domain-adapted models like AfroConfliBERT and AfroConfliLLAMA achieve near-directional neutrality but retain actor-based selection bias that legitimizes state actors 36.5 percent more often than non-state actors in identical tactical contexts in Nigeria. Vanilla model outputs prove fragile to delegitimizing lexical framing with flip rates reaching 66.7 percent in Cameroon, and error trace analysis shows they mask bias through unfaithful rational
What carries the argument
Comparison of model classifications to ACLED-verified events to quantify normative directionality bias, actor-based selection bias, and classification flip rates under lexical perturbations.
If this is right
- Domain adaptation can neutralize directional illegitimation bias but leaves actor selection bias intact.
- Lexical perturbations tied to specific geographies cause high classification instability in vanilla models.
- Models frequently generate unfaithful rationales that hide normative biases from users.
- Fairness-aware fine-tuning, mandatory robustness checks against lexical manipulation, and region-calibrated human oversight are required before unsupervised deployment.
Where Pith is reading between the lines
- Similar actor bias patterns may appear in other regions where state versus non-state framing differs in local reporting.
- Combining LLM outputs with multi-source verification systems could offset some selection biases in practice.
- The geographic specificity of lexical sensitivity suggests that monitoring tools may need per-context tuning rather than global deployment.
- Ongoing audits of deployed models against fresh ground-truth data would help track whether fine-tuning reduces the observed fragilities.
Load-bearing premise
The ACLED dataset provides an objective ground truth without its own normative biases, and the tested models plus perturbations represent real-world usage.
What would settle it
A follow-up test that collects new independently verified conflict events from the same regions, applies natural report variations, and measures whether bias rates and flip rates drop below statistical significance thresholds.
Figures






read the original abstract
As LLMs enter conflict monitoring, understanding systematic distortions in their outputs is critical for humanitarian accountability. We evaluate four vanilla open-weight models Gemma 3 4B, Llama 3.2 3B, Mistral 7B, and OLMo 2 7B and two domain-adapted models, AfroConfliBERT and AfroConfliLLAMA, on Nigeria and Cameroon conflict-event classification against ACLED, a gold-standard dataset with multi-stage verification. We find a bifurcated divergence in normative directionality. Open-weight models exhibit statistically significant False Illegitimation bias: Gemma misclassifies to 18.29% of legitimate battles as civilian-targeted violence while making zero False Legitimation errors. By contrast, AfroConfliBERT and AfroConfliLLAMA achieve near-directional neutrality, with Legitimization Bias differences indistinguishable from zero. Yet domain adaptation does not eliminate actor-based selection bias. Both adapted models show statistically significant actor bias comparable to vanilla LLMs; in Nigeria, state actors are legitimized 36.5% more often than non-state actors in identical tactical contexts. Open-weight outputs are also fragile to geography-specific lexical framing: delegitimizing phrases produce flip rates up to 66.7% in Cameroon and 34.2% in Nigeria, while perturbations salient in one context may not matter in another. Error trace profiling shows models mask normative bias through unfaithful rationale confabulations. In contrast, AfroConfliBERT and AfroConfliLLAMA are largely robust, with near-zero flip rates across perturbation categories. Overall, current models are not ready for unsupervised deployment in conflict monitoring. We call for fairness-aware fine-tuning to reduce actor-based selection bias, mandatory adversarial robustness evaluation against lexical manipulation, and context-specific human-in-the-loop oversight calibrated to regional difficulty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates four vanilla open-weight LLMs (Gemma 3 4B, Llama 3.2 3B, Mistral 7B, OLMo 2 7B) and two domain-adapted models (AfroConfliBERT, AfroConfliLLAMA) on Nigeria and Cameroon conflict-event classification against the ACLED dataset. It reports bifurcated results: vanilla models exhibit statistically significant false illegitimation bias (e.g., Gemma misclassifies 18.29% of legitimate battles as civilian-targeted violence with zero false legitimation errors), while adapted models achieve near-directional neutrality but retain actor-based selection bias (e.g., state actors legitimized 36.5% more often than non-state actors in identical tactical contexts in Nigeria). Vanilla outputs show high fragility to geography-specific lexical perturbations (flip rates up to 66.7% in Cameroon), whereas adapted models are robust with near-zero flip rates. Error analysis indicates vanilla models mask bias via unfaithful rationales. The paper concludes current models are not ready for unsupervised deployment and recommends fairness-aware fine-tuning, mandatory adversarial robustness testing, and context-specific human oversight.
Significance. If the results hold, the work is significant for highlighting practical risks of LLM deployment in humanitarian conflict monitoring, a domain where output distortions carry accountability implications. Strengths include the multi-model comparison, use of concrete percentages and statistical significance claims, lexical perturbation testing across regions, and error trace profiling. These elements provide falsifiable, actionable evidence that could guide domain adaptation practices. The distinction between directional neutrality and actor selection bias is a useful conceptual contribution.
major comments (2)
- [Abstract] Abstract: The headline claim that 'current models are not ready for unsupervised deployment' is derived from divergence statistics against ACLED labels (false illegitimation rates, actor-legitimation differentials, flip rates). However, the manuscript provides no external validation—such as inter-expert agreement metrics on the same events or comparison to an alternative coding scheme—that ACLED's interpretive judgments on actor intent, targeting, and legitimacy are free of normative or source-selection biases. This assumption is load-bearing for interpreting model divergences as errors rather than potentially defensible alternative framings.
- [Abstract] Abstract (results on actor bias): The report of statistically significant actor bias in adapted models (36.5% higher legitimation for state vs. non-state actors in Nigeria 'in identical tactical contexts') lacks accompanying details on sample size, how tactical contexts were matched or controlled, the exact statistical test, and effect size. Without these, it is difficult to assess whether the bias magnitude is robust or practically meaningful relative to the directional neutrality result.
minor comments (2)
- [Abstract] Abstract: The term 'error trace profiling' is introduced without a definition or example of the method; this should be expanded in the methods section with concrete traces to allow replication.
- [Abstract] Abstract: Exact model checkpoints, prompt templates, and ACLED subset sizes (Nigeria/Cameroon events) are not specified; these details are needed for reproducibility even if relegated to an appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating planned revisions to improve clarity and transparency while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that 'current models are not ready for unsupervised deployment' is derived from divergence statistics against ACLED labels (false illegitimation rates, actor-legitimation differentials, flip rates). However, the manuscript provides no external validation—such as inter-expert agreement metrics on the same events or comparison to an alternative coding scheme—that ACLED's interpretive judgments on actor intent, targeting, and legitimacy are free of normative or source-selection biases. This assumption is load-bearing for interpreting model divergences as errors rather than potentially defensible alternative framings.
Authors: We acknowledge that ACLED labels involve interpretive judgments on intent and legitimacy, and that the manuscript does not include new inter-expert agreement metrics or direct comparisons to alternative coding schemes. The paper positions ACLED as a benchmark citing its published multi-stage verification process. In the revised manuscript we will add an explicit discussion in the Limitations section addressing potential normative or source-selection biases in ACLED, referencing relevant literature on the dataset, and qualifying that some model divergences could represent defensible alternative framings rather than errors. This will not alter the empirical patterns of systematic bias we document but will strengthen the interpretive framing. revision: yes
-
Referee: [Abstract] Abstract (results on actor bias): The report of statistically significant actor bias in adapted models (36.5% higher legitimation for state vs. non-state actors in Nigeria 'in identical tactical contexts') lacks accompanying details on sample size, how tactical contexts were matched or controlled, the exact statistical test, and effect size. Without these, it is difficult to assess whether the bias magnitude is robust or practically meaningful relative to the directional neutrality result.
Authors: The full methodological details for the actor-bias analysis—including sample size, matching procedure for tactical contexts, statistical test, and effect size—are reported in Section 3.3 and Appendix C. To address the concern directly, we will revise the abstract to include a concise parenthetical summary of these elements (sample size, matching criteria, test, and effect size) so that the robustness of the 36.5% differential can be evaluated without requiring readers to consult the body text. revision: yes
Circularity Check
Empirical evaluation against external ACLED dataset exhibits no circularity
full rationale
This is a purely empirical study that compares LLM classifications of conflict events to labels in the independent ACLED dataset. No mathematical derivation, equations, fitted parameters, or self-referential definitions are present. All reported statistics (bias rates, flip rates, actor differentials) are direct measurements against an external benchmark rather than quantities that reduce to the paper's own inputs or prior self-citations by construction. The analysis is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ACLED dataset is a reliable gold-standard with multi-stage verification
Lean theorems connected to this paper
-
IndisputableMonolith.Cost (Jcost)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the Legitimization Bias Difference (ΔLB) as the difference between the False Illegitimation rate (εFI) and the False Legitimation rate (εFL)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Long Ouyang and Jeff Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul Christiano and Jan Leike and Ryan Lowe , isbn =. Traini...
-
[2]
Tim Menzner and Jochen L. Leidner , journal =. Improved Models for Media Bias Detection and Subcategorization , url =
-
[3]
Large Language Models in Crisis Informatics for Zero and Few-Shot Classification , volume =
Cinthia Sánchez and Andrés Abeliuk and Barbara Poblete , doi =. Large Language Models in Crisis Informatics for Zero and Few-Shot Classification , volume =. ACM Transactions on the Web , keywords =
-
[4]
Apollinaire Poli Nemkova and Sarath Chandra Lingareddy and Sagnik Ray Choudhury and Mark V. Albert , keywords =. Do Large Language Models Know Conflict? Investigating Parametric vs. Non-Parametric Knowledge of LLMs for Conflict Forecasting , url =
-
[5]
Explainable Multi-Granularity Attribution Reasoning Framework for Fake News Detection , url =
Wei Ji and Hongzhen Lv and Hanbin Zhao and Roger Zimmermann , doi =. Explainable Multi-Granularity Attribution Reasoning Framework for Fake News Detection , url =
-
[6]
Arpish R. Solanki , doi =. LLM-Inferred Narrative Frames in Geopolitical Conflict Reporting: An Exploratory Zero-Shot Approach , url =
-
[7]
A Pipeline for Extracting Data from Videos of Complex Political Events , url =
Mirya Holman and Andreas Küpfer and Tyler Simko , doi =. A Pipeline for Extracting Data from Videos of Complex Political Events , url =
-
[8]
Camilo Cristancho , doi =. Measuring the Protest Paradigm: LLM coding and machine learning approaches to Selection and Framing , url =
-
[9]
Andrew Schwartz and Dirk Hovy , doi =
Deven Shah and H. Andrew Schwartz and Dirk Hovy , doi =. Predictive biases in natural language processing models: A conceptual framework and overview , year =. Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages =
-
[10]
Selim Fekih and Nicolò Tamagnone and Benjamin Minixhofer and Ranjan Shrestha and Ximena Contla and Ewan Oglethorpe and Navid Rekabsaz , doi =. HUMSET: Dataset of Multilingual Information Extraction and Classification for Humanitarian Crisis Response , year =. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages =
work page 2022
-
[11]
Clustering of Social Media Messages for Humanitarian Aid Response during Crisis , url =
Swati Padhee and Tanay Kumar Saha and Joel Tetreault and Alejandro Jaimes , month =. Clustering of Social Media Messages for Humanitarian Aid Response during Crisis , url =
-
[12]
Language (Technology) is power: A critical survey of ⇜bias” in NLP , year =
Su Lin Blodgett and Solon Barocas and Hal Daumé and Hanna Wallach , doi =. Language (Technology) is power: A critical survey of ⇜bias” in NLP , year =. Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages =
-
[13]
Roberta Rocca and Nicolò Tamagnone and Selim Fekih and Ximena Contla and Navid Rekabsaz , doi =. Natural language processing for humanitarian action: Opportunities, challenges, and the path toward humanitarian NLP , volume =. Frontiers in Big Data , keywords =
-
[14]
Hemank Lamba and Anton Abilov and Ke Zhang and Elizabeth M. Olson and Henry K. Dambanemuya and João C. Bárcia and David S. Batista and Christina Wille and Aoife Cahill and Joel Tetreault and Alex Jaimes , doi =. HumVI: A Multilingual Dataset for Detecting Violent Incidents Impacting Humanitarian Aid , url =. EMNLP 2024 - 2024 Conference on Empirical Metho...
work page 2024
-
[15]
AI in Social Good: LLM powered Interventions in Crisis Management and Disaster Response , volume =
O Odubola and T S Adeyemi and O O Olajuwon , doi =. AI in Social Good: LLM powered Interventions in Crisis Management and Disaster Response , volume =. J Artif Intell Mach Learn & Data Sci | , keywords =
-
[16]
Yibo Hu and Mohammad Saleh Hosseini and Erick Skorupa Parolin and Javier Osorio and Latifur Khan and Patrick T. Brandt and Vito J. D'Orazio , doi =. ConfliBERT: A Pre-trained Language Model for Political Conflict and Violence , url =. NAACL 2022 - 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Languag...
work page 2022
-
[17]
ConfliBERT: A Language Model for Political Conflict , url =
Patrick T Brandt and Ut Dallas and utdallasedu Sultan Alsarra and Vito J D and Dagmar Heintze and Latifur Khan and Javier Osorio and Marcus Sianan and Michael Alvarez and Ben Bagozzi and Rebecca Cordell and Ryan Kennedy and Hyein Kim and Shahryar Minhas and Philip Schrodt and Nora Webb Williams , month =. ConfliBERT: A Language Model for Political Conflic...
-
[18]
Event Detection in the Socio Political Domain , year =
Emmanuel Cartier and Hristo Tanev , pages =. Event Detection in the Socio Political Domain , year =
-
[19]
CEHA: A Dataset of Conflict Events in the Horn of Africa , url =
Rui Bai and Di Lu and Shihao Ran and Elizabeth Olson and Hemank Lamba and Aoife Cahill and Joel Tetreault and Alex Jaimes , month =. CEHA: A Dataset of Conflict Events in the Horn of Africa , url =
-
[20]
How user language affects conflict fatality estimates in ChatGPT , volume =
Christoph Valentin Steinert and Daniel Kazenwadel , doi =. How user language affects conflict fatality estimates in ChatGPT , volume =. Journal of Peace Research , keywords =
-
[21]
Zifu Wang , pages =. Optimizing Location Extraction, Information Classification, and Visualization With Large Language Models for Humanitarian Crises , url =
-
[22]
Laura Braun and Christian Oswald , doi =. Automated information extraction from text variables in event datasets with large language models , url =
-
[23]
arXiv preprint arXiv:2405.02764 , year=
Assessing Adversarial Robustness of Large Language Models: An Empirical Study , author=. arXiv preprint arXiv:2405.02764 , year=
-
[24]
arXiv preprint arXiv:2511.16689 , year=
Concept-Based Interpretability for Toxicity Detection , author=. arXiv preprint arXiv:2511.16689 , year=
-
[25]
Performance and biases of Large Language Models in public opinion simulation , volume =
Yao Qu and Jue Wang , doi =. Performance and biases of Large Language Models in public opinion simulation , volume =. Humanities and Social Sciences Communications 2024 11:1 , keywords =
work page 2024
-
[26]
The African Languages Lab: A Collaborative Approach to Advancing Low-Resource African NLP , url =
Sheriff Issaka and Keyi Wang and Yinka Ajibola and Oluwatumininu Samuel-Ipaye and Zhaoyi Zhang and Nicte Aguillon Jimenez and Evans Kofi Agyei and Abraham Lin and Rohan Ramachandran and Sadick Abdul Mumin and Faith Nchifor and Mohammed Shuraim and Lieqi Liu and Erick Rosas Gonzalez and Sylvester Kpei and Jemimah Osei and Carlene Ajeneza and Persis Boateng...
-
[27]
A Survey on Multilingual Large Language Models: Corpora, Alignment, and Bias , volume =
Yuemei Xu and Ling Hu and Jiayi Zhao and Zihan Qiu and Kexin XU and Yuqi Ye and Hanwen Gu , doi =. A Survey on Multilingual Large Language Models: Corpora, Alignment, and Bias , volume =. Frontiers of Computer Science , keywords =
-
[28]
Ryan and William Held and Diyi Yang , doi =
Michael J. Ryan and William Held and Diyi Yang , doi =. Unintended Impacts of LLM Alignment on Global Representation , volume =. Proceedings of the Annual Meeting of the Association for Computational Linguistics , month =
-
[29]
Global Terrorism Index 2015: Measuring and Understanding the Impact of Terrorism , year =
work page 2015
-
[30]
Gillian Dunn , doi =. The impact of the Boko Haram insurgency in Northeast Nigeria on childhood wasting: a double-difference study , volume =. Conflict and Health 2018 12:1 , keywords =
work page 2018
-
[31]
Global Report on Internal Displacement 2024 , year =
work page 2024
-
[32]
Marc, Alexandre and Verjee, Neelam and Mogaka, Stephen , title =. 2015 , publisher =
work page 2015
- [33]
- [34]
-
[35]
The Anglophone problem in Cameroon , volume =
Piet Konings and Francis B Nyamnjoh , issue =. The Anglophone problem in Cameroon , volume =. Journal of Modern African Studies , keywords =
-
[36]
Piet Konings and Francis B. Nyamnjoh , doi =. Anglophone Secessionist Movements in Cameroon , url =. Secessionism in African Politics , pages =
-
[37]
Decentring foreign peace mediation in the case of Cameroon’s Anglophone Crisis , volume =
Jacqui Cho , doi =. Decentring foreign peace mediation in the case of Cameroon’s Anglophone Crisis , volume =. African Affairs , month =
-
[38]
Henry Ngenyam Bang and Roland Azibo Balgah , doi =. The ramification of Cameroon’s Anglophone crisis: conceptual analysis of a looming “Complex Disaster Emergency” , volume =. Journal of International Humanitarian Action , month =
-
[39]
M.-A. Pérouse de Montclos , isbn =. Boko Haram: Islamism, politics, security and the state in Nigeria , volume =. Internal Security Management in Nigeria , keywords =
-
[40]
Victor H. Mlambo , doi =. Unravelling Africa’s misgovernment: How state failures fuel the emergence of violent non-state actors: Selected case studies , volume =. Cogent Social Sciences , keywords =
-
[41]
Rebels, Victims, Peacebuilders: Women in Cameroon's Anglophone Conflict , year =
-
[42]
Global Terrorism Index , title =
-
[43]
Sub-Saharan Africa Regional Economic Outlook: Recovery Amid Elevated Uncertainty , url =
International Monetary Fund , month =. Sub-Saharan Africa Regional Economic Outlook: Recovery Amid Elevated Uncertainty , url =
- [44]
-
[45]
Violent conflicts and civil strife in West Africa: Causes, challenges and prospects , volume =
Nancy Annan , doi =. Violent conflicts and civil strife in West Africa: Causes, challenges and prospects , volume =. Stability , publisher =
- [46]
-
[47]
Schrodt, Philip A. and Gerner, Deborah J. , title =. American Journal of Political Science , volume =
-
[48]
Gerner, Deborah J. and Schrodt, Philip A. and Yilmaz,. The Creation of. Proceedings of the American Political Science Association Annual Meeting , address =
- [49]
-
[50]
Jesse Hammond and Nils B. Weidmann , doi =. Using machine-coded event data for the micro-level study of political violence , volume =. Research and Politics , keywords =
-
[51]
ChatGPT outperforms crowd workers for text-annotation tasks , journal =
Gilardi, Fabrizio and Alizadeh, Meysam and Kubli, Ma. ChatGPT outperforms crowd workers for text-annotation tasks , journal =. 2023 , doi =
work page 2023
-
[52]
T. Large Language Models Outperform Expert Coders and Supervised Classifiers at Annotating Political Social Media Messages , journal =. 2024 , doi =
work page 2024
-
[53]
Journal of Peace Research , volume =
Hegre, H. Journal of Peace Research , volume =. 2019 , doi =
work page 2019
-
[54]
Journal of Peace Research , volume =
Hegre, H. Journal of Peace Research , volume =. 2021 , doi =
work page 2021
-
[55]
Tao, Yan and Viberg, Olga and Baker, Ryan S. and Kizilcec, Ren. Cultural bias and cultural alignment of large language models , journal =. 2024 , doi =
work page 2024
-
[56]
and Ritter, Alan and Xu, Wei , title =
Naous, Tarek and Ryan, Michael J. and Ritter, Alan and Xu, Wei , title =. Proceedings of the 62nd Annual Meeting of the ACL , year =
-
[57]
Proceedings of ACL 2020 , year =
Joshi, Pratik and Santy, Sebastin and Buber, Amar and others , title =. Proceedings of ACL 2020 , year =
work page 2020
-
[58]
and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =. Proceedings of FAccT 2021 , pages =. 2021 , doi =
work page 2021
-
[59]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert-Voss and Gretchen Krueger and Tom Henighan and Rewon Child and Aditya Ramesh and Daniel M. Ziegler and Jeffrey Wu and Clemens Winter and ...
- [60]
-
[61]
Bowman and Newton Cheng and Esin Durmus and Zac Hatfield-Dodds and Scott R
Mrinank Sharma and Meg Tong and Tomasz Korbak and David Duvenaud and Amanda Askell and Samuel R. Bowman and Newton Cheng and Esin Durmus and Zac Hatfield-Dodds and Scott R. Johnston and Shauna Kravec and Timothy Maxwell and Sam McCandlish and Kamal Ndousse and Oliver Rausch and Nicholas Schiefer and Da Yan and Miranda Zhang and Ethan Perez , journal =. To...
-
[62]
Humanities and Social Sciences Communications , volume =
Raleigh, Clionadh and Kishi, Roudabeh and Linke, Andrew , title =. Humanities and Social Sciences Communications , volume =. 2023 , doi =
work page 2023
-
[63]
Nathalie Bussemaker and Mark Freeman , title =. 2025 , month =. doi:10.5281/zenodo.16598073 , url =
-
[64]
International Studies Quarterly , volume =
Author names from ISQ paper , title =. International Studies Quarterly , volume =. 2024 , doi =
work page 2024
-
[65]
Journal of Public Administration Research and Theory , volume =
Saar Alon-Barkat and Madalina Busuioc , title =. Journal of Public Administration Research and Theory , volume =. 2023 , doi =
work page 2023
-
[66]
T., Wu, T., Guestrin, C., and Singh, S
Ribeiro, Marco Tulio and Wu, Tongshuang and Guestrin, Carlos and Singh, Sameer. Beyond Accuracy: Behavioral Testing of NLP Models with C heck L ist. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.442
-
[67]
and Mulcaire, Phoebe and Ning, Qiang and Singh, Sameer and Smith, Noah A
Gardner, Matt and Artzi, Yoav and Basmov, Victoria and Berant, Jonathan and Bogin, Ben and Chen, Sihao and Dasigi, Pradeep and Dua, Dheeru and Elazar, Yanai and Gottumukkala, Ananth and Gupta, Nitish and Hajishirzi, Hannaneh and Ilharco, Gabriel and Khashabi, Daniel and Lin, Kevin and Liu, Jiangming and Liu, Nelson F. and Mulcaire, Phoebe and Ning, Qiang ...
-
[68]
Robustness Gym: Unifying the NLP Evaluation Landscape
Goel, Karan and Rajani, Nazneen Fatema and Vig, Jesse and Taschdjian, Zachary and Bansal, Mohit and R \'e , Christopher. Robustness Gym: Unifying the NLP Evaluation Landscape. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Demonstrations. 2021. doi:10.18653/v1...
-
[69]
Advances in neural information processing systems , volume=
What uncertainties do we need in bayesian deep learning for computer vision? , author=. Advances in neural information processing systems , volume=
-
[70]
Passonneau, Rebecca J. and Carpenter, Bob. The Benefits of a Model of Annotation. Transactions of the Association for Computational Linguistics. 2014. doi:10.1162/tacl_a_00185
-
[71]
Truth is a lie: Crowd truth and the seven myths of human annotation , author=. AI magazine , volume=
-
[72]
Advances in neural information processing systems , volume=
The unreliability of explanations in few-shot prompting for textual reasoning , author=. Advances in neural information processing systems , volume=
-
[73]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
International conference on machine learning , pages=
Axiomatic attribution for deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[75]
A primer on the inner workings of transformer-based language models , author=. arXiv preprint arXiv:2405.00208 , year=
-
[76]
Leaving the barn door open for
Lorenzo Pacchiardi and Marko Te. Leaving the barn door open for. 2024 , eprint =
work page 2024
-
[77]
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
work page 2022
-
[78]
Distinction between Civilians and Combatants (Rules 1–6) , booktitle=
Henckaerts, Jean-Marie and Doswald-Beck, Louise and Alvermann, Carolin and Dörmann, Knut and Rolle, Baptiste , year=. Distinction between Civilians and Combatants (Rules 1–6) , booktitle=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.