Recognition: unknown
The Impact of Vocabulary Overlaps on Knowledge Transfer in Multilingual Machine Translation
Pith reviewed 2026-05-08 17:27 UTC · model grok-4.3
The pith
In multilingual neural machine translation, domain match and language relatedness drive knowledge transfer more than a shared vocabulary.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
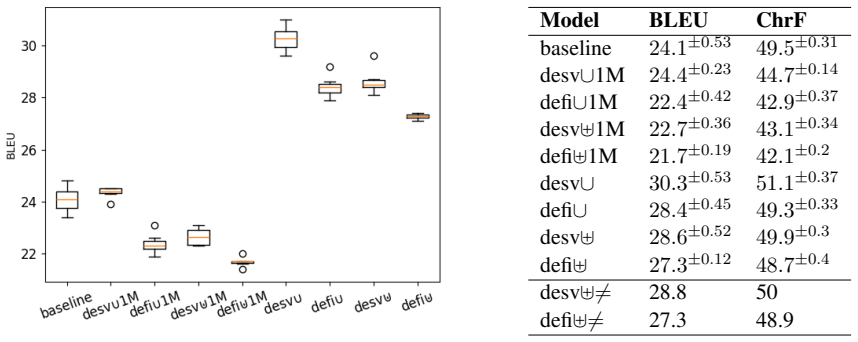
Experiments in an out-of-domain multilingual neural machine translation setup show that while vocabulary overlaps typical for related languages yield better results, domain match and language relatedness are more important than a joint vocabulary for effective knowledge transfer.
What carries the argument
The systematic comparison of joint versus disjoint vocabularies paired with related and unrelated auxiliary languages in out-of-domain multilingual NMT training.
Load-bearing premise
The chosen auxiliary languages, out-of-domain setup, and vocabulary construction methods isolate the effect of vocabulary overlap without major interference from model architecture or data selection choices.
What would settle it
A follow-up experiment that holds language relatedness and domain fixed while varying only the degree of vocabulary overlap and finds performance gaps much larger than those observed here would undermine the claim that relatedness and domain dominate.
Figures



read the original abstract
Knowledge transfer, especially across related languages, has been found beneficial for multilingual neural machine translation (MNMT), but some aspects are still under-explored and deserve further investigation. A joint vocabulary is most often applied to form a uniform word embedding space, but since the impact of a disjoint vocabulary on model performance is far less studied, there is no consensus on how much knowledge transfer is mainly due to vocabulary overlap. In this paper, we present systematic experiments with joint and disjoint vocabularies, and auxiliary languages related and unrelated to the source language. We design this experiment in an out-of-domain setup in order to emphasize transfer and the impact of the auxiliary language. As expected, we yield better results with more extensive vocabulary overlaps typical for related languages, but our experiments also show that domain-match and language relatedness are more important than a joint vocabulary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in multilingual neural machine translation, systematic experiments with joint versus disjoint vocabularies across related and unrelated auxiliary languages in an out-of-domain setup show better performance with greater vocabulary overlap for related languages, but that domain match and language relatedness are ultimately more important drivers of knowledge transfer than a joint vocabulary.
Significance. If the central experimental finding holds after proper controls, the result would be significant for MNMT practice: it would weaken the prevailing emphasis on shared vocabularies as the primary mechanism for cross-lingual transfer and redirect attention toward language selection and domain alignment. The out-of-domain design is a strength that could make the comparison more diagnostic of transfer effects.
major comments (2)
- [Experimental Setup] The central claim that domain-match and relatedness outweigh joint vocabulary depends on the experiments isolating vocabulary overlap as the sole manipulated variable. The description of vocabulary construction (separate BPE merges versus forced disjoint token sets) and auxiliary-language selection does not explicitly confirm that embedding dimensionality, subword granularity, and training dynamics are held constant across conditions; any correlation between these factors and the overlap manipulation would undermine attribution of the observed deltas.
- [Results] The out-of-domain data selection and choice of specific auxiliary languages are load-bearing for the claim, yet no ablation is described that fixes model architecture, data volume, and tokenizer training procedure while varying only overlap. Without such controls, performance differences cannot be confidently attributed primarily to vocabulary overlap rather than confounds from domain or relatedness.
minor comments (1)
- [Abstract] The abstract states the main conclusion but does not report concrete metrics, language pairs, or statistical significance; adding a brief quantitative summary would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the major concerns point by point below. Where the manuscript description was insufficiently explicit, we have revised to add the requested clarifications while preserving the original experimental design and findings.
read point-by-point responses
-
Referee: [Experimental Setup] The central claim that domain-match and relatedness outweigh joint vocabulary depends on the experiments isolating vocabulary overlap as the sole manipulated variable. The description of vocabulary construction (separate BPE merges versus forced disjoint token sets) and auxiliary-language selection does not explicitly confirm that embedding dimensionality, subword granularity, and training dynamics are held constant across conditions; any correlation between these factors and the overlap manipulation would undermine attribution of the observed deltas.
Authors: We agree that explicit confirmation strengthens attribution. The manuscript already uses the identical Transformer architecture, embedding dimension of 512, BPE vocabulary size of 32k, and the same training hyperparameters and steps for every condition. Vocabulary overlap is the only manipulated factor: joint BPE merges produce overlap while separate merges on the same corpora produce disjoint sets. We have added an explicit paragraph in the Experimental Setup section stating that embedding dimensionality, subword granularity, and all training dynamics remain fixed across joint and disjoint conditions. This revision directly addresses the concern. revision: yes
-
Referee: [Results] The out-of-domain data selection and choice of specific auxiliary languages are load-bearing for the claim, yet no ablation is described that fixes model architecture, data volume, and tokenizer training procedure while varying only overlap. Without such controls, performance differences cannot be confidently attributed primarily to vocabulary overlap rather than confounds from domain or relatedness.
Authors: The core experiments already hold model architecture (Transformer base), data volume (identical parallel corpora sizes), and tokenizer procedure (BPE with fixed 32k size, either joint or forced disjoint) constant while varying only overlap and language relatedness in the out-of-domain setting. The auxiliary-language selection is an intentional second factor to test interactions, not a confound. We acknowledge that an additional table isolating overlap for a single fixed auxiliary language would further strengthen the attribution, and we have added this controlled ablation in the revised manuscript; the new results continue to show that domain match and relatedness exert larger effects than vocabulary overlap alone. revision: partial
Circularity Check
No circularity: purely experimental study with independent empirical comparisons
full rationale
The paper conducts systematic experiments on joint vs. disjoint vocabularies across related/unrelated auxiliary languages in an out-of-domain MT setup. No derivations, equations, fitted parameters, or self-citation chains are invoked to derive the central claim. The finding that domain match and language relatedness outweigh joint vocabulary is presented as the direct outcome of the reported performance comparisons, without any reduction to inputs by construction. Self-citations, if present, are not load-bearing for the experimental result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenSubtitles2024: A Massively Parallel Dataset of Movie Subtitles for MT Development and Evaluation , booktitle =
Tiedemann, J\". OpenSubtitles2024: A Massively Parallel Dataset of Movie Subtitles for MT Development and Evaluation , booktitle =
-
[2]
Wu, Di and Monz, Christof. Beyond Shared Vocabulary: Increasing Representational Word Similarities across Languages for Multilingual Machine Translation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.605
-
[3]
Escolano, Carlos and Costa-juss \`a , Marta R. and Fonollosa, Jos \'e A. R. and Artetxe, Mikel. Multilingual Machine Translation: Closing the Gap between Shared and Language-specific Encoder-Decoders. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.80
-
[4]
Towards Continual Learning for Multilingual Machine Translation via Vocabulary Substitution
Garcia, Xavier and Constant, Noah and Parikh, Ankur and Firat, Orhan. Towards Continual Learning for Multilingual Machine Translation via Vocabulary Substitution. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.93
-
[5]
Effective Cross-lingual Transfer of Neural Machine Translation Models without Shared Vocabularies
Kim, Yunsu and Gao, Yingbo and Ney, Hermann. Effective Cross-lingual Transfer of Neural Machine Translation Models without Shared Vocabularies. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1120
-
[6]
An Empirical Study of Multilingual Vocabulary for Neural Machine Translation Models
Imamura, Kenji and Utiyama, Masao. An Empirical Study of Multilingual Vocabulary for Neural Machine Translation Models. Proceedings of the Eleventh Workshop on Asian Translation (WAT 2024). 2024. doi:10.18653/v1/2024.wat-1.2
-
[7]
An Empirical Study of Language Relatedness for Transfer Learning in Neural Machine Translation
Dabre, Raj and Nakagawa, Tetsuji and Kazawa, Hideto. An Empirical Study of Language Relatedness for Transfer Learning in Neural Machine Translation. Proceedings of the 31st Pacific Asia Conference on Language, Information and Computation. 2017
2017
-
[8]
and Chiang, David
Nguyen, Toan Q. and Chiang, David. Transfer Learning across Low-Resource, Related Languages for Neural Machine Translation. Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers). 2017
2017
-
[9]
In Neural Machine Translation, What Does Transfer Learning Transfer?
Aji, Alham Fikri and Bogoychev, Nikolay and Heafield, Kenneth and Sennrich, Rico. In Neural Machine Translation, What Does Transfer Learning Transfer?. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.688
-
[10]
Zoph, Barret and Yuret, Deniz and May, Jonathan and Knight, Kevin. Transfer Learning for Low-Resource Neural Machine Translation. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1163
-
[11]
Investigating Lexical Sharing in Multilingual Machine Translation for I ndian Languages
Sannigrahi, Sonal and Bawden, Rachel. Investigating Lexical Sharing in Multilingual Machine Translation for I ndian Languages. Proceedings of the 24th Annual Conference of the European Association for Machine Translation. 2023
2023
-
[12]
Trivial Transfer Learning for Low-Resource Neural Machine Translation
Kocmi, Tom and Bojar, Ond r ej. Trivial Transfer Learning for Low-Resource Neural Machine Translation. Proceedings of the Third Conference on Machine Translation: Research Papers. 2018. doi:10.18653/v1/W18-6325
-
[13]
Neural Machine Translation of Rare Words with Subword Units
Sennrich, Rico and Haddow, Barry and Birch, Alexandra. Neural Machine Translation of Rare Words with Subword Units. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. doi:10.18653/v1/P16-1162
-
[14]
False F riends Are Not Foes: Investigating Vocabulary Overlap in Multilingual Language Models
Kallini, Julie and Jurafsky, Dan and Potts, Christopher and Bartelds, Martijn. False F riends Are Not Foes: Investigating Vocabulary Overlap in Multilingual Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025
2025
-
[15]
Kudo, Taku and Richardson, John. S entence P iece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2018. doi:10.18653/v1/D18-2012
work page internal anchor Pith review doi:10.18653/v1/d18-2012 2018
-
[16]
Marian: Fast Neural Machine Translation in
Junczys-Dowmunt, Marcin and Grundkiewicz, Roman and Dwojak, Tomasz and Hoang, Hieu and Heafield, Kenneth and Neckermann, Tom and Seide, Frank and Germann, Ulrich and Fikri Aji, Alham and Bogoychev, Nikolay and Martins, Andr\'. Marian: Fast Neural Machine Translation in. Proceedings of ACL 2018, System Demonstrations , year =
2018
-
[17]
Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC'12) , year =
Jörg Tiedemann , title =. Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC'12) , year =
-
[18]
O pen S ubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles
Lison, Pierre and Tiedemann, J. O pen S ubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. Proceedings of the Tenth International Conference on Language Resources and Evaluation ( LREC '16). 2016
2016
-
[19]
O pus T ools and Parallel Corpus Diagnostics
Aulamo, Mikko and Sulubacak, Umut and Virpioja, Sami and Tiedemann, J. O pus T ools and Parallel Corpus Diagnostics. Proceedings of The 12th Language Resources and Evaluation Conference. 2020
2020
-
[20]
Post, Matt. A Call for Clarity in Reporting BLEU Scores. Proceedings of the Third Conference on Machine Translation: Research Papers. 2018. doi:10.18653/v1/W18-6319
-
[21]
Beyond Literal Token Overlap: Token Alignability for Multilinguality
H. Beyond Literal Token Overlap: Token Alignability for Multilinguality. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2025. doi:10.18653/v1/2025.naacl-short.63
-
[22]
When is BERT Multilingual? Isolating Crucial Ingredients for Cross-lingual Transfer
Deshpande, Ameet and Talukdar, Partha and Narasimhan, Karthik. When is BERT Multilingual? Isolating Crucial Ingredients for Cross-lingual Transfer. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naacl-main.264
-
[23]
Identifying Elements Essential for BERT ' s Multilinguality
Dufter, Philipp and Sch. Identifying Elements Essential for BERT ' s Multilinguality. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.358
-
[24]
Dabre, Raj and Chu, Chenhui and Kunchukuttan, Anoop , title =. ACM Comput. Surv. , month = sep, articleno =. 2020 , issue_date =. doi:10.1145/3406095 , abstract =
-
[25]
Toward Multilingual Neural Machine Translation with Universal Encoder and Decoder
Ha, Thanh-Le and Niehues, Jan and Waibel, Alex. Toward Multilingual Neural Machine Translation with Universal Encoder and Decoder. Proceedings of the 13th International Conference on Spoken Language Translation. 2016
2016
-
[26]
Multi-Way, Multilingual Neural Machine Translation with a Shared Attention Mechanism
Firat, Orhan and Cho, Kyunghyun and Bengio, Yoshua. Multi-Way, Multilingual Neural Machine Translation with a Shared Attention Mechanism. Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016. doi:10.18653/v1/N16-1101
-
[27]
Beto, bentz, becas: The surprising cross-lingual effectiveness of BERT
Wu, Shijie and Dredze, Mark. Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1077
-
[28]
Viewing Knowledge Transfer in Multilingual Machine Translation Through a Representational Lens
Stap, David and Niculae, Vlad and Monz, Christof. Viewing Knowledge Transfer in Multilingual Machine Translation Through a Representational Lens. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.998
-
[29]
Improving Multilingual Models with Language-Clustered Vocabularies
Chung, Hyung Won and Garrette, Dan and Tan, Kiat Chuan and Riesa, Jason. Improving Multilingual Models with Language-Clustered Vocabularies. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.367
-
[30]
Overlap-based Vocabulary Generation Improves Cross-lingual Transfer Among Related Languages
Patil, Vaidehi and Talukdar, Partha and Sarawagi, Sunita. Overlap-based Vocabulary Generation Improves Cross-lingual Transfer Among Related Languages. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.18
-
[31]
Alternative Input Signals Ease Transfer in Multilingual Machine Translation
Sun, Simeng and Fan, Angela and Cross, James and Chaudhary, Vishrav and Tran, Chau and Koehn, Philipp and Guzm \'a n, Francisco. Alternative Input Signals Ease Transfer in Multilingual Machine Translation. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.363
-
[32]
Causes and Cures for Interference in Multilingual Translation
Shaham, Uri and Elbayad, Maha and Goswami, Vedanuj and Levy, Omer and Bhosale, Shruti. Causes and Cures for Interference in Multilingual Translation. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.883
-
[33]
Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
Kudo, Taku. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1007
-
[34]
Subword Segmental Machine Translation: Unifying Segmentation and Target Sentence Generation
Meyer, Francois and Buys, Jan. Subword Segmental Machine Translation: Unifying Segmentation and Target Sentence Generation. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.175
-
[35]
A Systematic Analysis of Subwords and Cross-Lingual Transfer in Multilingual Translation
Meyer, Francois and Buys, Jan. A Systematic Analysis of Subwords and Cross-Lingual Transfer in Multilingual Translation. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.141
-
[36]
Understanding Cross-Lingual Syntactic Transfer in Multilingual Recurrent Neural Networks
Dhar, Prajit and Bisazza, Arianna. Understanding Cross-Lingual Syntactic Transfer in Multilingual Recurrent Neural Networks. Proceedings of the 23rd Nordic Conference on Computational Linguistics (NoDaLiDa). 2021
2021
-
[37]
International Conference on Learning Representations , year=
Cross-Lingual Ability of Multilingual BERT: An Empirical Study , author=. International Conference on Learning Representations , year=
-
[38]
Does Syntactic Knowledge in Multilingual Language Models Transfer Across Languages?
Dhar, Prajit and Bisazza, Arianna. Does Syntactic Knowledge in Multilingual Language Models Transfer Across Languages?. Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for NLP. 2018. doi:10.18653/v1/W18-5453
-
[39]
Can Domains Be Transferred across Languages in Multi-Domain Multilingual Neural Machine Translation?
Vu, Thuy-Trang and Khadivi, Shahram and He, Xuanli and Phung, Dinh and Haffari, Gholamreza. Can Domains Be Transferred across Languages in Multi-Domain Multilingual Neural Machine Translation?. Proceedings of the Seventh Conference on Machine Translation (WMT). 2022
2022
-
[40]
chr F : character n-gram F -score for automatic MT evaluation
Popovi \'c , Maja. chr F : character n-gram F -score for automatic MT evaluation. Proceedings of the Tenth Workshop on Statistical Machine Translation. 2015. doi:10.18653/v1/W15-3049
-
[41]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention is all you need , year =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
-
[42]
Proceedings of the Association for Computational Linguistics (ACL) , pages =
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
-
[43]
Proceedings of the 40th Annual Meeting on Association for Computational Linguistics , pages =
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[44]
C Users J
Gage, Philip , title =. C Users J. , month = feb, pages =. 1994 , issue_date =
1994
-
[45]
and Krikun, Maxim and Wu, Yonghui and Chen, Zhifeng and Thorat, Nikhil and Vi \'e gas, Fernanda and Wattenberg, Martin and Corrado, Greg and Hughes, Macduff and Dean, Jeffrey
Johnson, Melvin and Schuster, Mike and Le, Quoc V. and Krikun, Maxim and Wu, Yonghui and Chen, Zhifeng and Thorat, Nikhil and Vi \'e gas, Fernanda and Wattenberg, Martin and Corrado, Greg and Hughes, Macduff and Dean, Jeffrey. G oogle ' s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation. Transactions of the Association for Co...
2017
-
[46]
and Jeffrey D
Aho, Alfred V. and Jeffrey D. Ullman. 1972. The Theory of Parsing, Translation and Compiling , volume 1. Prentice- Hall , Englewood Cliffs, NJ
1972
-
[47]
American Psychological Association . 1983. Publications Manual . American Psychological Association, Washington, DC
1983
-
[48]
Association for Computing Machinery . 1983. Computing Reviews , 24(11):503--512
1983
-
[49]
Kozen, and Larry J
Chandra, Ashok K., Dexter C. Kozen, and Larry J. Stockmeyer. 1981. Alternation. Journal of the Asso\-ciation for Computing Machinery , 28(1):114--133
1981
-
[50]
Gledson, Anne, and John Keane. 2008a. Measuring Topic Homogeneity and its Application to Dictionary-Based Word-Sense Disambiguation. Coling 2008, 22nd International Conference on Computational Linguistics , Manchester, UK. 273--280
2008
-
[51]
Gledson, Anne, and John Keane. 2008b. Using Web-Search Results to Measure Word-group Similarity. Coling 2008, 22nd International Conference on Computational Linguistics , Manchester, UK. 281--288
2008
-
[52]
Gusfield, Dan. 1997. Algorithms on Strings, Trees and Sequences . Cambridge University Press, Cambridge, UK
1997
-
[53]
Tam, Yik-Cheung and Tanja Schultz. 2006. Unsupervised Language Model Adaptation Using Latent Semantic Marginals. Interspeech 2006 -- ICSLP, Ninth International Conference on Spoken Language Processing , Pittsburgh, Pennsylvania, paper 1705-Thu1A2O.2
2006
-
[54]
Tam, Yik-Cheung and Tanja Schultz. 2007. Correlated Latent Semantic Model for Unsupervised Language Model Adaptation. Proceedings of ICASSP 2007, International Conference on Acoustics, Speech, and Signal Processing , Honolulu, Hawaii, Vol. IV, 41--44
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.