Recognition: 3 theorem links
· Lean TheoremThe Anatomy of Silent Data Corruption: GPU Error Pattern Study and Modeling Guidance
Pith reviewed 2026-05-08 17:59 UTC · model grok-4.3
The pith
Large-scale GPU fault injection shows silent corruptions rarely produce NaN or infinity values and exhibit multi-bit flips with periodic addresses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A campaign of over three million simulator hours of gate-level stuck-at fault injection on production-class data-center GPUs and 63 CUDA micro-benchmarks establishes that NaN/+INF/-INF outcomes constitute only 1.01% of silent data corruptions, single-bit flips account for less than 40% of all bit-flip events, and corruption addresses display clear periodicity. These statistics are extracted from corruption types, bit-flip behavior, and warp-aligned spatial correlations, directly motivating the construction of distribution-aware high-level fault models and realistic software-based fault injection techniques for evaluating GPU resilience.
What carries the argument
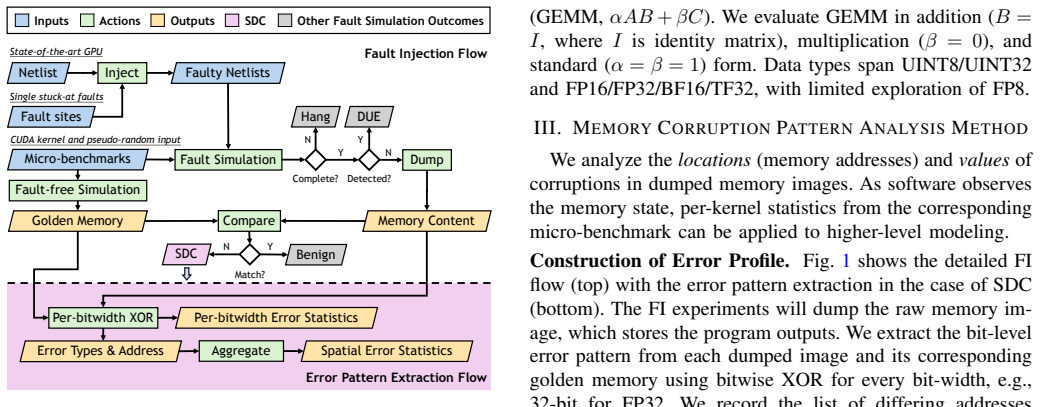
Gate-level stuck-at fault injection performed across 63 CUDA micro-benchmarks on a production-class data-center GPU, used to collect statistics on corruption outcome types, bit-flip multiplicity, and periodic address patterns.
If this is right
- High-level fault models must incorporate the full observed distribution of corruption outcomes instead of focusing primarily on NaN and infinity values.
- Software-based fault injection campaigns should replicate multi-bit flips and periodic address patterns to produce realistic resilience estimates.
- Resilience evaluations for production GPU architectures can use these empirical distributions to guide targeted error detection and recovery mechanisms.
- Micro-benchmark results provide a basis for scaling fault models to larger workloads while preserving the measured bit-flip and spatial characteristics.
Where Pith is reading between the lines
- If the periodic address pattern arises from fixed hardware structures, targeted hardware monitoring at those locations could detect corruptions earlier than generic checks.
- The low rate of special-value corruptions suggests that floating-point exception handlers alone will miss most silent errors in large-scale training runs.
- Extending the injection methodology to full application workloads instead of micro-benchmarks would test whether the same distributions appear outside controlled settings.
Load-bearing premise
Gate-level stuck-at fault injection on micro-benchmarks accurately captures the distribution and spatial patterns of real silent data corruptions that occur in production data-center GPUs running full workloads.
What would settle it
Direct measurement of silent data corruptions during real production GPU workloads that shows NaN or infinity values occurring at rates well above 1.01% or lacking periodic address structure would contradict the reported statistics.
Figures






read the original abstract
Silent data corruption (SDC) threatens the reliability of large-scale GPU clusters used for training large language models, yet its rarity and lack of explicit error signals make accurate high-level modeling challenging. To address this gap, we conducted a large-scale gate-level stuck-at fault injection on a production-class data-center GPU, consuming over three million simulator hours across 63 CUDA micro-benchmarks. We extracted GPU SDC characteristics in terms of corruption types, bit-flip behavior, and warp-aligned spatial correlation. Our results show that NaN/+INF/-INF account for only 1.01% of SDC outcomes, that single-bit flips constitute less than 40% of bit-flip events, and that corruption addresses exhibit periodicity. These statistics motivate distribution-aware high-level fault modeling and realistic software-based fault injection for resilience evaluation of production-class GPU architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from a large-scale gate-level stuck-at fault injection campaign consuming over three million simulator hours across 63 CUDA micro-benchmarks on a production-class data-center GPU. It claims that NaN/+INF/-INF account for only 1.01% of SDC outcomes, single-bit flips constitute less than 40% of bit-flip events, and corruption addresses exhibit periodicity. These empirical statistics are presented as motivation for distribution-aware high-level fault modeling and realistic software-based fault injection for resilience evaluation of production GPUs.
Significance. If the observed patterns are representative, the study offers concrete, large-scale empirical data on SDC characteristics that could improve high-level fault models beyond simplistic assumptions. The scale of the simulation campaign (over 3M simulator hours) is a clear strength, providing direct counts rather than purely theoretical derivations, which could help guide more accurate resilience techniques for data-center GPU workloads.
major comments (1)
- [Abstract and Methods] Abstract and Methods: The headline statistics and call for distribution-aware modeling rest on the representativeness of gate-level stuck-at injection in 63 micro-benchmarks. However, the manuscript does not validate these distributions against real field SDC logs from production GPUs or compare them to alternative mechanisms such as transient soft errors or voltage droops under full-scale workloads (e.g., LLM training kernels). Micro-benchmarks exercise narrower control flow and utilization than production code, making generalization a load-bearing assumption for the modeling guidance.
minor comments (1)
- [Abstract] The abstract would benefit from stating the total number of fault injections performed to better contextualize the reported percentages such as 1.01%.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the scale of our simulation campaign. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods: The headline statistics and call for distribution-aware modeling rest on the representativeness of gate-level stuck-at injection in 63 micro-benchmarks. However, the manuscript does not validate these distributions against real field SDC logs from production GPUs or compare them to alternative mechanisms such as transient soft errors or voltage droops under full-scale workloads (e.g., LLM training kernels). Micro-benchmarks exercise narrower control flow and utilization than production code, making generalization a load-bearing assumption for the modeling guidance.
Authors: We agree that the choice of micro-benchmarks and the stuck-at fault model limits direct generalization to all production scenarios. The 63 micro-benchmarks were selected to enable exhaustive, controlled injection across diverse CUDA primitives and utilization levels while remaining computationally feasible; full-scale kernels such as LLM training would make the 3M+ simulator-hour campaign intractable. The reported statistics are presented as empirical observations from this specific injection methodology to motivate distribution-aware modeling, not as universal claims. We will revise the manuscript to add an explicit limitations subsection discussing the scope (stuck-at faults, micro-benchmarks), the absence of direct comparison to transient soft errors or voltage droops, and the value of future validation against real field data. revision: partial
- Validation of the observed distributions against real field SDC logs from production GPUs, as such detailed proprietary data is not available to the authors.
Circularity Check
No circularity: empirical counts from fault-injection campaign
full rationale
The paper reports direct observational statistics obtained from over three million simulator hours of gate-level stuck-at fault injection across 63 CUDA micro-benchmarks. Key results (NaN/+INF/-INF fraction of 1.01%, single-bit flips <40% of events, address periodicity) are presented as raw counts and spatial patterns extracted from the injection outcomes. No equations, parameter fits, or derivations are claimed; the text contains no self-citation load-bearing steps, uniqueness theorems, or ansatzes that reduce any result to its own inputs by construction. The study is therefore self-contained as a measurement campaign.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gate-level stuck-at fault injection produces error patterns representative of real silent data corruption in production GPUs
Lean theorems connected to this paper
-
Foundation/Breath1024.lean (period8 := 8)period8 unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
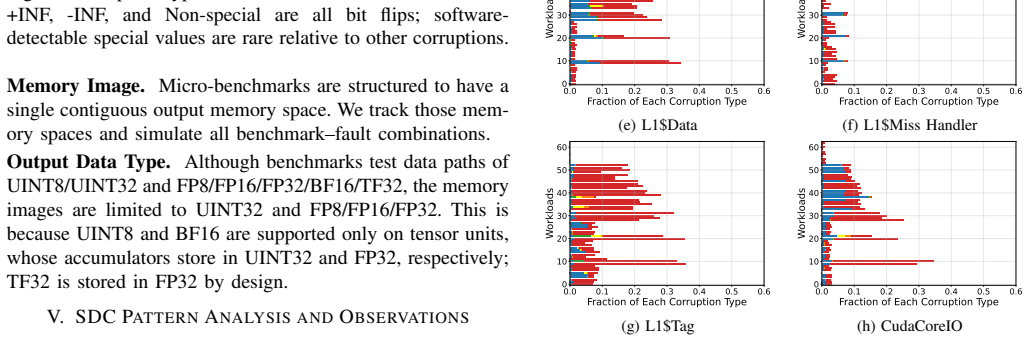
Grouping corrupted addresses modulo the warp size (W=32) reveals periodic corruption patterns at the warp granularity... periodicity at multiple granularities, e.g., 16, 8, 4, 2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Silent data corruption in AI
N. George, H. D. Dixit, E. Goksu, B. Parthasarathy, A. Huffman, S. Gu- rumurthi, V . Sridharan, T. Macieira, A. Sinha, L. Minwell, D. Liberty, and R. Chappell, “Silent data corruption in AI.” https://www.opencomp ute.org/documents/sdc-in-ai-ocp-whitepaper-final-pdf, 2025. Online; accessed Oct 5, 2025
2025
-
[2]
Cores that don’t count,
P. H. Hochschild, P. Turner, J. C. Mogul, R. Govindaraju, P. Ran- ganathan, D. E. Culler, and A. Vahdat, “Cores that don’t count,” in Proc. ACM HotOS, 2021
2021
-
[3]
Silent data corruptions at scale
H. D. Dixit, S. Pendharkar, M. Beadon, C. Mason, T. Chakravarthy, B. Muthiah, and S. Sankar, “Silent data corruptions at scale,”arXiv preprint arXiv:2102.11245, 2021
-
[4]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell,et al., “Language models are few-shot learners,” inProc. NeurIPS, 2020
2020
-
[5]
Efficient large-scale language model training on GPU clusters using Megatron-LM,
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V . Kor- thikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro,et al., “Efficient large-scale language model training on GPU clusters using Megatron-LM,” inProc. ACM/IEEE SC, 2021
2021
-
[6]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan,et al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Understanding silent data corruptions in a large production CPU population,
S. Wang, G. Zhang, J. Wei, Y . Wang, J. Wu, and Q. Luo, “Understanding silent data corruptions in a large production CPU population,” inProc. ACM SOSP, 2023
2023
-
[8]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican,et al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page Pith review arXiv 2023
-
[9]
Understanding and mitigating hardware failures in deep learning training systems,
Y . He, M. Hutton, S. Chan, R. De Gruijl, R. Govindaraju, N. Patil, and Y . Li, “Understanding and mitigating hardware failures in deep learning training systems,” inProc. ACM/IEEE ISCA, 2023
2023
-
[10]
Detection and correction of silent data corruption for large-scale high-performance computing,
D. Fiala, F. Mueller, C. Engelmann, R. Riesen, K. Ferreira, and R. Brightwell, “Detection and correction of silent data corruption for large-scale high-performance computing,” inProc. ACM/IEEE SC, 2012
2012
-
[11]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen,et al., “Gem- ini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
work page Pith review arXiv 2025
-
[12]
Understanding silent data corruption in LLM training,
J. Ma, H. Pei, L. Lausen, and G. Karypis, “Understanding silent data corruption in LLM training,”Proc. ACL (Long Papers), 2025
2025
-
[13]
Dynamic task remapping for reliable CNN training on ReRAM crossbars,
C.-H. Tung, B. K. Joardar, P. P. Pande, J. R. Doppa, H. H. Li, and K. Chakrabarty, “Dynamic task remapping for reliable CNN training on ReRAM crossbars,” inProc. IEEE DATE, 2023
2023
-
[14]
Resiliency of automotive object detection networks on GPU architectures,
A. Lotfi, S. Hukerikar, K. Balasubramanian, P. Racunas, N. Saxena, R. Bramley, and Y . Huang, “Resiliency of automotive object detection networks on GPU architectures,” inProc. IEEE ITC, 2019
2019
-
[15]
Optimiz- ing large-scale fault injection experiments through martingale hypoth- esis: A systematic approach for reliability assessment of safety-critical systems,
S. Hukerikar, A. Lotfi, Y . Huang, J. Campbell, and N. Saxena, “Optimiz- ing large-scale fault injection experiments through martingale hypoth- esis: A systematic approach for reliability assessment of safety-critical systems,” inProc. IEEE/IFIP DSN-S, 2024
2024
-
[16]
Resilience of deep learning applications: A systematic literature review of analysis and hardening techniques,
C. Bolchini, L. Cassano, and A. Miele, “Resilience of deep learning applications: A systematic literature review of analysis and hardening techniques,”Comput. Sci. Rev., vol. 54, p. 100682, 2024
2024
-
[17]
NVBitFI: Dynamic fault injection for GPUs,
T. Tsai, S. K. S. Hari, M. Sullivan, O. Villa, and S. W. Keckler, “NVBitFI: Dynamic fault injection for GPUs,” inProc. IEEE/IFIP DSN, 2021
2021
-
[18]
PyTorchFI: A runtime perturbation tool for DNNs,
A. Mahmoud, N. Aggarwal, A. Nobbe, J. R. S. Vicarte, S. V . Adve, C. W. Fletcher, I. Frosio, and S. K. S. Hari, “PyTorchFI: A runtime perturbation tool for DNNs,” inProc. IEEE/IFIP DSN-W, 2020
2020
-
[19]
TensorFI: A flexible fault injection framework for Tensor- flow applications,
Z. Chen, N. Narayanan, B. Fang, G. Li, K. Pattabiraman, and N. De- Bardeleben, “TensorFI: A flexible fault injection framework for Tensor- flow applications,” inProc. IEEE ISSRE, 2020
2020
-
[20]
FIdelity: Efficient resilience analysis framework for deep learning accelerators,
Y . He, P. Balaprakash, and Y . Li, “FIdelity: Efficient resilience analysis framework for deep learning accelerators,” inProc. IEEE/ACM MICRO, 2020
2020
-
[21]
Tehranipoor, K
M. Tehranipoor, K. Peng, and K. Chakrabarty,Test and diagnosis for small-delay defects. Springer, 2011
2011
-
[22]
Cell-aware test,
F. Hapke, W. Redemund, A. Glowatz, J. Rajski, M. Reese, M. Hustava, M. Keim, J. Schloeffel, and A. Fast, “Cell-aware test,”IEEE Trans. Comput.-Aided Design Integr. Circuits Syst., vol. 33, no. 9, pp. 1396– 1409, 2014
2014
-
[23]
PEPR: Pseudo-exhaustive physically-aware region testing,
W. Li, C. Nigh, D. Duvalsaint, S. Mitra, and R. D. Blanton, “PEPR: Pseudo-exhaustive physically-aware region testing,” inProc. IEEE ITC, 2022
2022
-
[24]
Error model (EM)—a new way of doing fault simulation,
N. Saxena and A. Lotfi, “Error model (EM)—a new way of doing fault simulation,” inProc. IEEE ITC, 2022
2022
-
[25]
Mersenne twister: a 623- dimensionally equidistributed uniform pseudo-random number genera- tor,
M. Matsumoto and T. Nishimura, “Mersenne twister: a 623- dimensionally equidistributed uniform pseudo-random number genera- tor,”ACM Trans. Model. Comput. Simul., vol. 8, no. 1, pp. 3–30, 1998
1998
-
[26]
A design of programmable logic arrays with universal tests,
H. Fujiwara and K. Kinoshita, “A design of programmable logic arrays with universal tests,”IEEE Trans. Comput., vol. c-30, no. 11, pp. 823– 828, 1981
1981
-
[27]
A new PLA design for universal testability,
H. Fujiwara, “A new PLA design for universal testability,”IEEE Trans. Comput., vol. c-33, no. 8, pp. 745–750, 1984
1984
-
[28]
The design of easily testable VLSI array multipliers,
J. P. Shen and F. J. Ferguson, “The design of easily testable VLSI array multipliers,”IEEE Trans. Comput., vol. c-33, no. 6, pp. 554–560, 1984
1984
-
[29]
Runtime fault diagnostics for GPU tensor cores,
S. Hukerikar and N. Saxena, “Runtime fault diagnostics for GPU tensor cores,” inProc. IEEE ITC, 2022
2022
-
[30]
Abramovici, M
M. Abramovici, M. A. Breuer, and A. D. Friedman,Digital systems testing and testable design, vol. 2. Computer Science Press, 1990
1990
-
[31]
S. W. Golomb,Shift register sequences: secure and limited-access code generators, efficiency code generators, prescribed property generators, mathematical models. World Scientific, 2017
2017
-
[32]
CUDA C++ programming guide
NVIDIA Corporation, “CUDA C++ programming guide.” https://docs .nvidia.com/cuda/cuda-c-programming-guide/, 2025. Online; accessed Sep 15, 2025
2025
-
[33]
Ares: A framework for quantifying the resilience of deep neural networks,
B. Reagen, U. Gupta, L. Pentecost, P. Whatmough, S. K. Lee, N. Mul- holland, D. Brooks, and G.-Y . Wei, “Ares: A framework for quantifying the resilience of deep neural networks,” inProc. ACM/IEEE DAC, 2018
2018
-
[34]
GPU reliability assessment: Insights across the abstraction layers,
L. Yang, G. Papadimitriou, D. Sartzetakis, A. Jog, E. Smirni, and D. Gi- zopoulos, “GPU reliability assessment: Insights across the abstraction layers,” inProc. IEEE CLUSTER, 2024
2024
-
[35]
Evaluating fault resiliency of compressed deep neural networks,
M. Sabbagh, C. Gongye, Y . Fei, and Y . Wang, “Evaluating fault resiliency of compressed deep neural networks,” inProc. IEEE ICESS, 2019
2019
-
[36]
SASSIFI: An architecture-level fault injection tool for GPU application resilience evaluation,
S. K. S. Hari, T. Tsai, M. Stephenson, S. W. Keckler, and J. Emer, “SASSIFI: An architecture-level fault injection tool for GPU application resilience evaluation,” inProc. IEEE ISPASS, 2017
2017
-
[37]
Computing’s hidden menace: The OCP takes action against silent data corruption (SDC)
B. Parthasarathy, “Computing’s hidden menace: The OCP takes action against silent data corruption (SDC).” https://www.opencompute.org/bl og/computings-hidden-menace-the-ocp-takes-action-against-silent-dat a-corruption-sdc, 2024. Online; accessed Sep 10, 2025
2024
-
[38]
Silent data errors: Sources, detection, and modeling,
A. Singh, S. Chakravarty, G. Papadimitriou, and D. Gizopoulos, “Silent data errors: Sources, detection, and modeling,” inProc. IEEE VTS, 2023
2023
-
[39]
Data center silent data errors: Implications to artificial intelligence workloads & mitigations,
B. Bittel, M. Shamsa, B. Inkley, A. Gur, D. Lerner, and M. Adams, “Data center silent data errors: Implications to artificial intelligence workloads & mitigations,” inProc. IEEE IRPS, 2024
2024
-
[40]
Quantitative evaluation of soft error injection techniques for robust system design,
H. Cho, S. Mirkhani, C.-Y . Cher, J. A. Abraham, and S. Mitra, “Quantitative evaluation of soft error injection techniques for robust system design,” inProc. ACM/IEEE DAC, 2013
2013
-
[41]
Rethinking error injection for effective resilience,
S. Mirkhani, H. Cho, S. Mitra, and J. A. Abraham, “Rethinking error injection for effective resilience,” inProc. IEEE ASP-DAC, 2014
2014
-
[42]
Characterizing GPU resilience and impact on AI/HPC systems,
S. Cui, A. Patke, H. Nguyen, A. Ranjan, Z. Chen, P. Cao, B. Bode, G. Bauer, C. Di Martino, S. Jha,et al., “Characterizing GPU resilience and impact on AI/HPC systems,”arXiv preprint arXiv:2503.11901, 2025
-
[43]
Ap- proxDup: Developing an approximate instruction duplication mechanism for efficient SDC detection in GPGPUs,
X. Wei, N. Jiang, H. Yue, X. Wang, J. Zhao, G. Li, and M. Qiu, “Ap- proxDup: Developing an approximate instruction duplication mechanism for efficient SDC detection in GPGPUs,”IEEE Trans. Comput.-Aided Design Integr. Circuits Syst., vol. 43, no. 4, pp. 1051–1064, 2023
2023
-
[44]
Understanding the effects of permanent faults in GPU’s parallelism management and control units,
J. D. Guerrero Balaguera, J. E. Rodriguez Condia, F. Fernandes Dos San- tos, M. Sonza Reorda, and P. Rech, “Understanding the effects of permanent faults in GPU’s parallelism management and control units,” inProc. ACM/IEEE SC, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.