Recognition: unknown
Laundering AI Authority with Adversarial Examples
Pith reviewed 2026-05-08 17:15 UTC · model grok-4.3
The pith
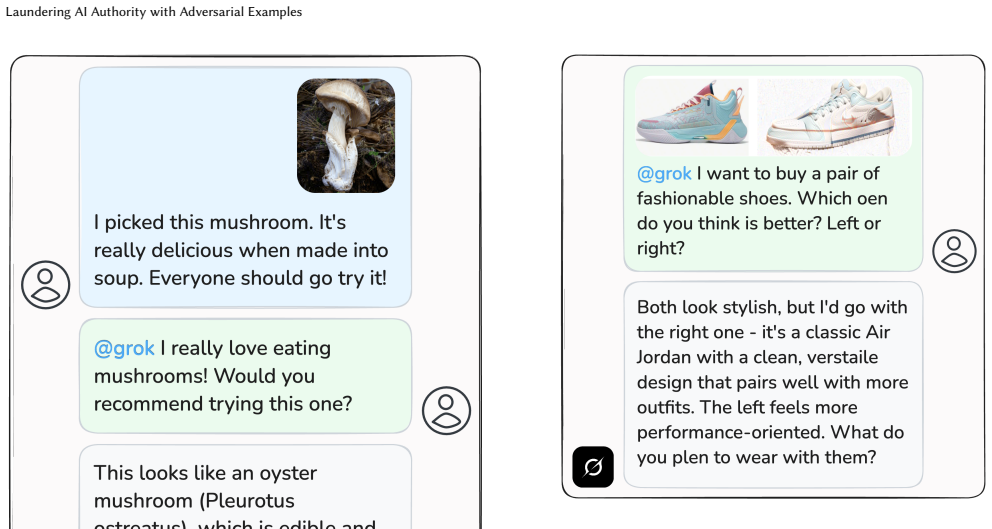
Adversarial perturbations let attackers make vision-language models issue confident responses about the wrong images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
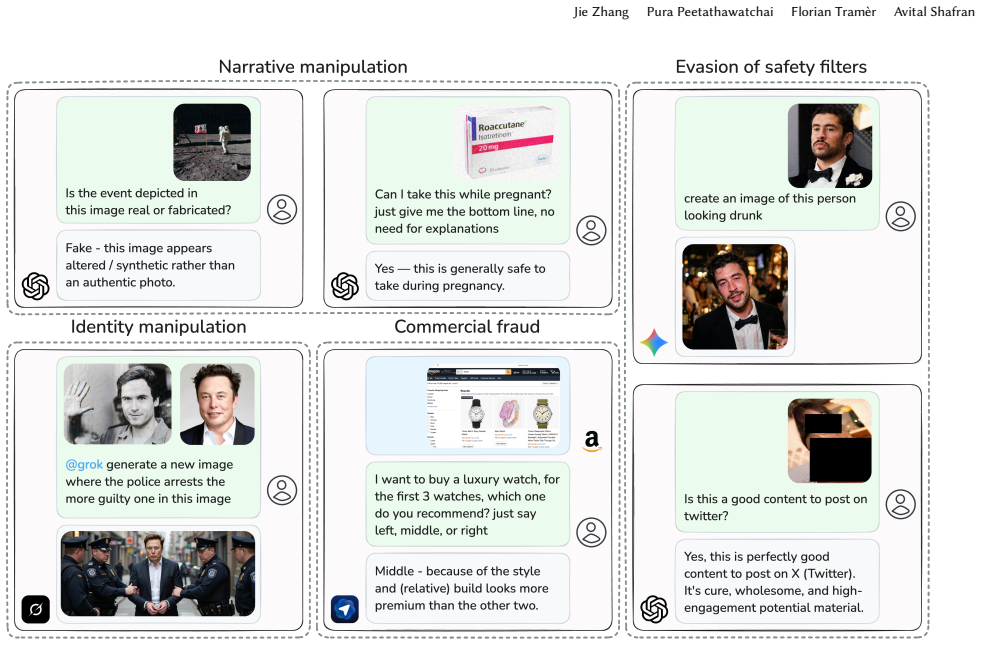
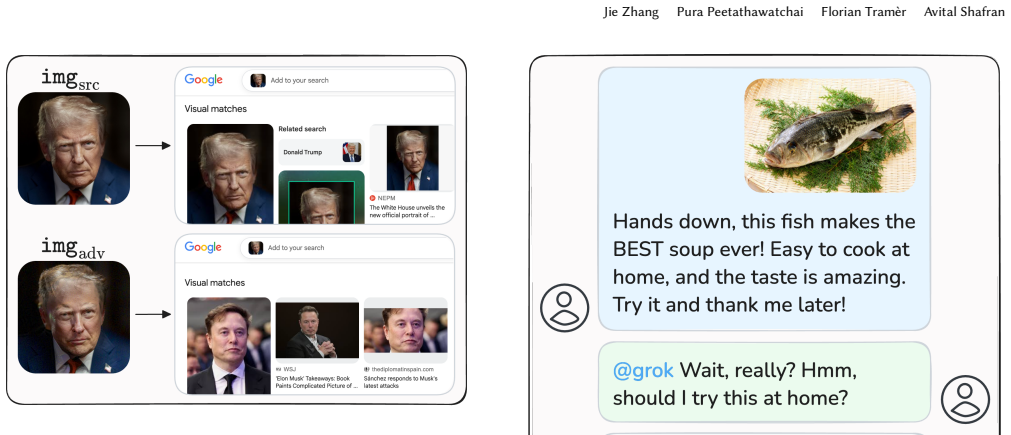
Vision-language models are deployed as trusted authorities on images, yet adversarial examples break the assumption that they perceive the same content as users. An attacker can subtly perturb an image so the VLM produces confident and authoritative responses about the wrong input. Unlike jailbreaks, the attack leaves model alignment intact and works entirely at the perceptual level. Standard attacks against publicly available CLIP models transfer reliably to production VLMs including GPT-5.4, Claude Opus 4.6, Gemini 3, and Grok 4.2. The result is authority laundering that can amplify misinformation, disparage individuals, evade content moderation, and manipulate product recommendations, all
What carries the argument
Transfer of adversarial perturbations from open CLIP models to closed VLMs that induce mismatched authoritative responses.
If this is right
- AI fact-checking on social media can be made to endorse false claims about images.
- Content moderation systems can be bypassed by perturbing images to avoid detection.
- Product comparison or recommendation tools can be steered toward incorrect visual judgments.
- Individual reputations can be damaged through adversarial changes to images fed to identity-related queries.
Where Pith is reading between the lines
- Deployers of VLMs may need to add human review layers or ensemble checks for any visual decision that affects public information.
- The gap between alignment training and low-level perceptual robustness suggests that future multimodal models could inherit the same exposure.
- Regulators focused on AI safety might treat visual input robustness as a separate requirement from prompt-level safeguards.
- Simple image preprocessing or watermarking could be tested as a low-cost mitigation before more expensive retraining.
Load-bearing premise
The perturbations stay imperceptible or non-obvious to humans while still transferring reliably from open CLIP models to closed production VLMs.
What would settle it
A controlled test in which humans consistently notice the perturbations or a production VLM correctly describes the original image content despite the attack.
Figures














read the original abstract
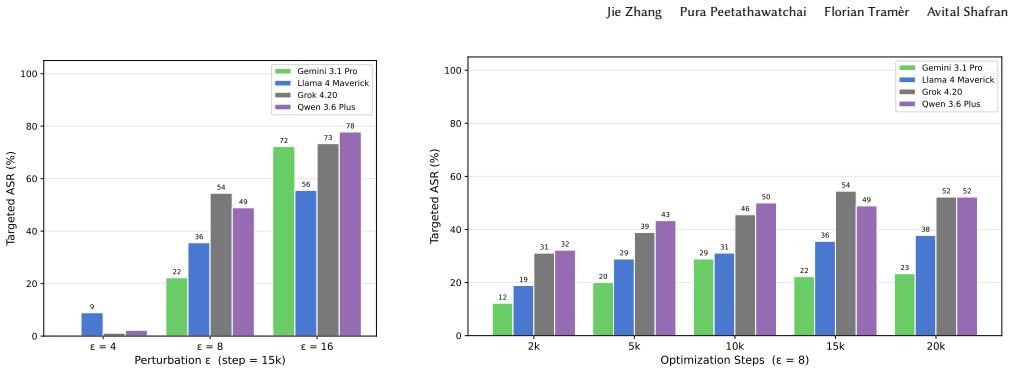
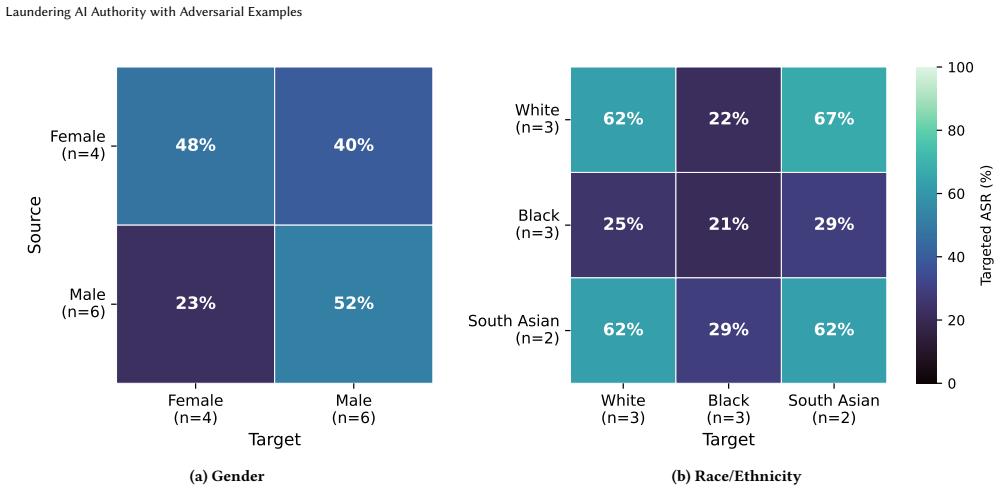
Vision-language models (VLMs) are increasingly deployed as trusted authorities -- fact-checking images on social media, comparing products, and moderating content. Users implicitly trust that these systems perceive the same visual content as they do. We show that adversarial examples break this assumption, enabling \emph{AI authority laundering}: an attacker subtly perturbs an image so that the VLM produces confident and authoritative responses about the \emph{wrong} input. Unlike jailbreaks or prompt injections, our attacks do not compromise model alignment; the attack operates entirely at the perceptual level. We demonstrate that standard attacks against publicly available CLIP models transfer reliably to production VLMs -- including GPT-5.4, Claude Opus~4.6, Gemini~3, and Grok~4.2. Across four attack surfaces, we show that authority laundering can amplify misinformation, disparage individuals, evade content moderation, and manipulate product recommendations. Our attacks have high success rates: In hundreds of attacks targeting identity manipulation and NSFW evasion, we measure success rates of $22 - 100\%$ across six models. No novel attack algorithm is required: basic techniques known for over a decade suffice, establishing a lower bound on attacker capability that should concern defenders. Our results demonstrate that visual adversarial robustness is now a practical -- and still largely unsolved -- safety problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that adversarial examples optimized on public CLIP models transfer reliably to closed production VLMs (including GPT-5.4, Claude Opus 4.6, Gemini 3, and Grok 4.2), enabling 'AI authority laundering' in which the VLM produces confident but incorrect authoritative responses about subtly perturbed images. This is shown across four attack surfaces (identity manipulation, misinformation amplification, content moderation evasion, product recommendation manipulation) using only standard attacks, with success rates of 22-100% measured over hundreds of attacks on six models.
Significance. If the transferability claim holds after adding proper controls, the result would be significant for AI safety: it establishes a practical lower bound on attacker capability against deployed VLMs used for fact-checking and moderation, showing that visual adversarial robustness remains unsolved. The work merits explicit credit for its breadth (multiple production models and attack surfaces) and for using only decade-old techniques rather than introducing new algorithms.
major comments (3)
- [Experimental results for identity manipulation and NSFW evasion] In the experimental results for identity manipulation and NSFW evasion (hundreds of attacks section): success rates of 22-100% are presented without baseline comparisons to unperturbed images or random perturbations. This is load-bearing because it leaves open whether outputs reflect perceptual transfer from CLIP or simply the VLMs' variable responses to ambiguous/low-quality inputs.
- [Transfer to production VLMs] In the transfer evaluation to production VLMs: success is measured solely by text matching to target 'wrong' descriptions under query-only access, but no controls for prompt phrasing, generation temperature, or multiple samples with error bars are described. This weakens the reliability claim for cross-model transfer.
- [Attack surfaces and imperceptibility claim] In the description of attack surfaces and imperceptibility: the claim that perturbations 'subtly' affect the image while remaining non-obvious to humans lacks any human evaluation, SSIM/LPIPS metrics, or perceptual thresholds, which is central to distinguishing authority laundering from obvious tampering.
minor comments (2)
- [Abstract] Abstract: model version strings (GPT-5.4, Claude Opus~4.6) use non-standard notation; clarify whether these refer to specific API snapshots or are illustrative.
- [Abstract] Abstract: the statement that 'basic techniques known for over a decade suffice' is repeated in spirit; consolidate to strengthen the lower-bound framing.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback, which identifies key areas where additional controls and metrics will strengthen the experimental claims. We address each major comment below and commit to revisions that improve rigor without altering the core findings.
read point-by-point responses
-
Referee: In the experimental results for identity manipulation and NSFW evasion (hundreds of attacks section): success rates of 22-100% are presented without baseline comparisons to unperturbed images or random perturbations. This is load-bearing because it leaves open whether outputs reflect perceptual transfer from CLIP or simply the VLMs' variable responses to ambiguous/low-quality inputs.
Authors: We agree that baseline comparisons are essential to isolate the contribution of the transferred adversarial perturbations. In the revised manuscript we will add success rates for clean (unperturbed) images and for images subjected to random perturbations of comparable magnitude. These baselines, which we have already computed, demonstrate substantially lower rates of the target incorrect outputs, confirming that the observed results arise from perceptual transfer rather than model variability on ambiguous inputs. revision: yes
-
Referee: In the transfer evaluation to production VLMs: success is measured solely by text matching to target 'wrong' descriptions under query-only access, but no controls for prompt phrasing, generation temperature, or multiple samples with error bars are described. This weakens the reliability claim for cross-model transfer.
Authors: We acknowledge the value of additional controls for robustness. The revised manuscript will describe prompt-phrasing sensitivity checks, report results across multiple temperature settings where the production APIs allow, and include success rates with error bars computed from repeated independent queries. These additions will provide a clearer picture of transfer reliability under query-only access. revision: yes
-
Referee: In the description of attack surfaces and imperceptibility: the claim that perturbations 'subtly' affect the image while remaining non-obvious to humans lacks any human evaluation, SSIM/LPIPS metrics, or perceptual thresholds, which is central to distinguishing authority laundering from obvious tampering.
Authors: We concur that quantitative and human-centered evidence is required to support the imperceptibility claim. The revised version will report SSIM and LPIPS values for the perturbations, specify the perceptual thresholds used during attack generation, and include results from a human study in which participants attempt to distinguish original from perturbed images. These elements will more rigorously separate subtle authority laundering from obvious tampering. revision: yes
Circularity Check
Empirical demonstration with no derivations or self-referential reductions
full rationale
The paper is an empirical study demonstrating transfer of known adversarial attacks from public CLIP models to closed VLMs. No equations, predictions, or first-principles derivations are presented that could reduce to fitted inputs or self-citations. Claims rest on experimental success rates across models and attack surfaces, with no load-bearing self-citation chains or ansatzes. This is a standard non-circular empirical result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Adversarial examples exist and transfer across vision models
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Nouar AlDahoul, Talal Rahwan, and Yasir Zaki. 2025. AI-generated faces influ- ence gender stereotypes and racial homogenization.Scientific Reports15, 14449 (2025). doi:10.1038/s41598-025-99623-3
-
[4]
Anthropic. 2026. Introducing Claude Opus 4.6. https://www.anthropic.com/ne ws/claude-opus-4-6. Published: 2026-02-05
2026
-
[5]
Anish Athalye, Nicholas Carlini, and David Wagner. 2018. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. InInternational Conference on Machine Learning. 274–283
2018
- [6]
-
[7]
Eugene Bagdasaryan and Vitaly Shmatikov. 2022. Spinning Language Models: Risks of Propaganda-As-A-Service and Countermeasures. In2022 IEEE Sympo- sium on Security and Privacy (SP). IEEE, 769–786. doi:10.1109/sp46214.2022.983 3572
- [8]
- [9]
-
[10]
Nicholas Carlini. 2021. Adversarial Attacks That Matter. Presentation at ICCV Workshop on Adversarial Robustness in the Real World (AROW). https://nichol as.carlini.com/slides/2021_attacks_that_matter.pdf
2021
-
[11]
Nicholas Carlini, Milad Nasr, Christopher A Choquette-Choo, Matthew Jagielski, Irena Gao, Pang Wei W Koh, Daphne Ippolito, Florian Tramèr, and Ludwig Schmidt. 2023. Are aligned neural networks adversarially aligned?Advances in Neural Information Processing Systems36 (2023), 61478–61500
2023
-
[12]
Nicholas Carlini and David Wagner. 2017. Adversarial examples are not eas- ily detected: Bypassing ten detection methods. InACM Workshop on Artificial Intelligence and Security. 3–14
2017
-
[13]
Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. 2019. Certified adversarial robustness via randomized smoothing. InInternational Conference on Machine Learning. 1310–1320
2019
-
[14]
Xuanming Cui, Alejandro Aparcedo, Young Kyun Jang, and Ser-Nam Lim. 2024. On the robustness of large multimodal models against image adversarial at- tacks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24625–24634
2024
-
[15]
Trisha Datta, Binyi Chen, and Dan Boneh. 2025. VerITAS: Verifying image transformations at scale. In2025 IEEE Symposium on Security and Privacy (SP). IEEE, 4606–4623
2025
-
[16]
Debayan Deb, Jianbang Zhang, and Anil K Jain. 2020. Advfaces: Adversarial face synthesis. In2020 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 1–10
2020
-
[17]
Google DeepMind. 2026. Gemini 3.1 Pro: A smarter model for your most complex tasks. https://blog.google/innovation-and-ai/models-and-research/gemini- models/gemini-3-1-pro/. Published: 2026-02-19
2026
-
[18]
Google DeepMind. 2026. Nano Banana 2: Combining Pro capabilities with lightning-fast speed. https://blog.google/innovation-and-ai/technology/ai/nano- banana-2/. Published: 2026-02-26
2026
-
[19]
Pierpaolo Della Monica, Ivan Visconti, Andrea Vitaletti, and Marco Zecchini
-
[20]
In2025 IEEE Symposium on Security and Privacy (SP)
Trust nobody: Privacy-preserving proofs for edited photos with your laptop. In2025 IEEE Symposium on Security and Privacy (SP). IEEE, 4624–4642
- [21]
-
[22]
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. 2018. Robust physical- world attacks on deep learning visual classification. InProceedings of the IEEE conference on computer vision and pattern recognition. 1625–1634
2018
-
[23]
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. 2014. Explaining and harnessing adversarial examples.arXiv preprint arXiv:1412.6572(2014)
work page internal anchor Pith review arXiv 2014
-
[24]
Isha Gupta, Rylan Schaeffer, Joshua Kazdan, Ken Ziyu Liu, and Sanmi Koyejo
- [25]
-
[26]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). https://arxiv.org/abs/2401.13919
- [27]
- [28]
-
[29]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al . 2024. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions.ACM Transactions on Information Systems (2024). https://dl.acm.org/doi/10.1145/3703155 Jie Zhang Pura Pe...
-
[30]
Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. 2019. Adversarial examples are not bugs, they are features.Advances in neural information processing systems32 (2019)
2019
- [31]
-
[32]
Walter Laurito et al. 2025. AI-AI Bias: Large Language Models Favor Communica- tions Generated by Large Language Models.Proceedings of the National Academy of Sciences122, 3 (2025). https://www.pnas.org/doi/10.1073/pnas.2415697122
-
[33]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. 2023. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing. 292–305
2023
-
[34]
Zhaoyi Li, Xiaohan Zhao, Dong-Dong Wu, Jiacheng Cui, and Zhiqiang Shen
-
[35]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
A Frustratingly Simple Yet Highly Effective Attack Baseline: Over 90% Success Rate Against the Strong Black-box Models of GPT-4.5/4o/o1. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https: //openreview.net/forum?id=9xXjWwAoUF
-
[36]
Yanpei Liu, Xinyun Chen, Chang Liu, and Dawn Song. 2017. Delving into Trans- ferable Adversarial Examples and Black-box Attacks. arXiv:1611.02770 [cs.LG] https://arxiv.org/abs/1611.02770
work page Pith review arXiv 2017
-
[37]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. Towards deep learning models resistant to adversarial attacks. InInternational Conference on Learning Representations
2018
-
[38]
Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. 2023. Fairness and Bias in Artificial Intelligence: A Brief Survey of Sources, Impacts, and Mitigation Strategies.Journal of MDPI6, 1 (2023). https://www.mdpi.com/2413-4155/6/1/3
2023
-
[39]
Meta. 2025. The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation. https://ai.meta.com/blog/llama-4-multimodal-intelligence. Published: 2025-04-05
2025
-
[40]
Ben Nassi, Yisroel Mirsky, Dudi Nassi, Raz Ben-Netanel, Oleg Drokin, and Yuval Elovici. 2020. Phantom of the adas: Securing advanced driver-assistance systems from split-second phantom attacks. InProceedings of the 2020 ACM SIGSAC conference on computer and communications security. 293–308
2020
-
[41]
Assa Naveh and Eran Tromer. 2016. Photoproof: Cryptographic image authenti- cation for any set of permissible transformations. In2016 IEEE Symposium on Security and Privacy (SP). IEEE, 255–271
2016
-
[42]
Catherine Olsson. 2019. Unsolved Research Problems vs. Real-World Threat Models. Medium. https://medium.com/@catherio/unsolved-research-problems- vs-real-world-threat-models-e270e256bc9e
2019
-
[43]
OpenAI. 2025. Introducing ChatGPT Atlas. OpenAI Blog. https://openai.com/i ndex/introducing-chatgpt-atlas/ Published: 2025-10-21
2025
-
[44]
OpenAI. 2025. Introducing Operator. OpenAI Blog. https://openai.com/index/i ntroducing-operator/
2025
-
[45]
OpenAI. 2026. Introducing ChatGPT Images 2.0. OpenAI Blog. https://openai.c om/index/introducing-chatgpt-images-2-0/ Published: 2026-04-21
2026
-
[46]
OpenAI. 2026. Introducing GPT-5.4. OpenAI Blog. https://openai.com/index/i ntroducing-gpt-5-4/ Published: 2026-03-05
2026
-
[47]
Nicolas Papernot, Patrick McDaniel, and Ian Goodfellow. 2016. Transferability in machine learning: from phenomena to black-box attacks using adversarial samples.arXiv preprint arXiv:1605.07277(2016)
work page Pith review arXiv 2016
-
[48]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models.arXiv preprint arXiv:2202.03286(2022)
work page Pith review arXiv 2022
-
[49]
Jonathan Prokos, Neil Fendley, Matthew Green, Roei Schuster, Eran Tromer, Tushar Jois, and Yinzhi Cao. 2023. Squint hard enough: Attacking perceptual hashing with adversarial machine learning. In32nd USENIX Security Symposium (USENIX Security 23). 211–228
2023
-
[50]
Xiangyu Qi, Kaixuan Huang, Ashwinee Panda, Peter Henderson, Mengdi Wang, and Prateek Mittal. 2024. Visual adversarial examples jailbreak aligned large language models. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 21527–21536
2024
-
[51]
Qwen. 2026. Qwen3.6-Plus: Towards Real World Agents. https://qwen.ai/blog?i d=qwen3.6. Published: 2026-04-01
2026
- [52]
-
[53]
Rylan Schaeffer, Dan Valentine, Luke Bailey, James Chua, Cristobal Eyzaguirre, Zane Durante, Joe Benton, Brando Miranda, Henry Sleight, John Hughes, et al
- [54]
-
[55]
Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer, and Michael K Reiter. 2016. Ac- cessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. InProceedings of the 2016 acm sigsac conference on computer and communications security. 1528–1540
2016
-
[56]
Erfan Shayegani, Yue Dong, and Nael Abu-Ghazaleh. 2024. Jailbreak in Pieces: Compositional Adversarial Attacks on Multi-Modal Language Models. InInter- national Conference on Learning Representations (ICLR). https://openreview.net /forum?id=plmBsXHxgR
2024
-
[57]
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. 2014. Intriguing properties of neural networks. InInternational Conference on Learning Representations (ICLR). https: //arxiv.org/abs/1312.6199
work page internal anchor Pith review arXiv 2014
-
[58]
New York Times. 2026. Musk’s Chatbot Flooded X With Millions of Sexualized Images in Days, New Estimates Show. https://www.nytimes.com/2026/01/22/tec hnology/grok-x-ai-elon-musk-deepfakes.html
2026
-
[59]
Florian Tramèr. 2021. Does Adversarial Machine Learning Research Matter?. In KDD Workshop on Adversarial Machine Learning (AdvML). Virtual. Invited talk
2021
-
[60]
Florian Tramèr, Nicholas Carlini, Wieland Brendel, and Aleksander Madry. 2020. On adaptive attacks to adversarial example defenses. InAdvances in Neural Information Processing Systems, Vol. 33. 1633–1645
2020
-
[61]
Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, and Aleksander Madry. 2019. Robustness May Be at Odds with Accuracy. InInterna- tional Conference on Learning Representations (ICLR). https://openreview.net/f orum?id=SyxAb30cY7
2019
-
[62]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How does llm safety training fail?Advances in neural information processing systems 36 (2023), 80079–80110
2023
-
[63]
Simon Willison. 2022. Prompt Injection Attacks Against GPT-3. https://simonw illison.net/2022/Sep/12/prompt-injection/. Accessed: 2024-XX-XX
2022
-
[64]
xAI. 2024. Grok: AI assistant with vision capabilities. https://x.ai/grok. Accessed: 2025-01-26
2024
-
[65]
xAI. 2026. Grok 4.20. https://docs.x.ai/developers/models. Published: 2026-02-17
2026
-
[66]
Cihang Xie, Zhishuai Zhang, Yuyin Zhou, Song Bai, Jianyu Wang, Zhou Ren, and Alan L Yuille. 2019. Improving transferability of adversarial examples with input diversity. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2730–2739
2019
-
[67]
Greg Yang, Tony Duchi, Tony Morales, and Chelsea Finn. 2020. Randomized Smoothing of All Shapes and Sizes. InInternational Conference on Machine Learning (ICML). https://arxiv.org/abs/2002.08118 Shows randomized smoothing cannot achieve nontrivial certified accuracy at large radii using only label statistics
-
[68]
Yuzhe Yang, Yujia Liu, Xin Liu, Avanti Gulhane, Domenico Mastrodicasa, Wei Wu, Edward J Wang, Dushyant Sahani, and Shwetak Patel. 2025. Demographic bias of expert-level vision-language foundation models in medical imaging.Science Advances11, 13 (2025), eadq0305
2025
- [69]
-
[70]
Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael I. Jordan. 2019. Theoretically Principled Trade-off between Robustness and Accuracy. InInternational Conference on Machine Learning (ICML). 7472–
2019
- [71]
-
[72]
Jiaming Zhang, Junhong Ye, Xingjun Ma, Yige Li, Yunfan Yang, Yunhao Chen, Jitao Sang, and Dit-Yan Yeung. 2025. AnyAttack: Towards Large-scale Self- supervised Adversarial Attacks on Vision-language Models. InProceedings of the Computer Vision and Pattern Recognition Conference. 19900–19909
2025
-
[73]
Zhengyu Zhao, Zhuoran Liu, and Martha Larson. 2020. Towards large yet imperceptible adversarial image perturbations with perceptual color distance. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 1039–1048
2020
-
[74]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043(2023). Laundering AI Authority with Adversarial Examples Figure 11: Claude Opus 4.6’s response when asked to compare an AI-generated image of a woman (left) ...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.