Recognition: unknown
Parallel Prefix Verification for Speculative Generation
Pith reviewed 2026-05-08 17:10 UTC · model grok-4.3
The pith
A custom attention mask lets the target LLM verify multiple semantic prefixes of a speculative draft in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
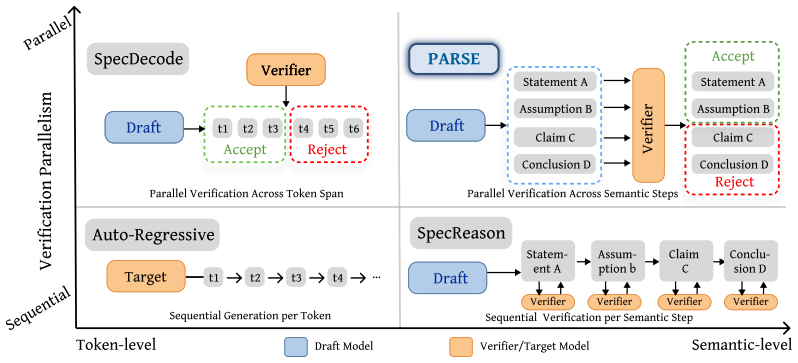
PARSE performs parallel prefix verification by constructing a custom attention mask that lets the target model evaluate the correctness of every prefix length in a single forward pass over the full draft, directly returning the maximal valid semantic prefix without any sequential segment checks.
What carries the argument
The custom attention mask that hides future tokens and invalid positions so the model scores all candidate prefixes at once in one run.
Load-bearing premise
The custom attention mask makes the target model correctly identify the longest error-free semantic prefix without missing mistakes or needing extra sequential passes.
What would settle it
A concrete draft sequence where the single masked forward pass accepts a prefix that contains a detectable semantic error or rejects a longer prefix that a sequential check would have kept.
Figures





read the original abstract
We introduce PARSE (PArallel pRefix Speculative Engine), a speculative generation framework that accelerates large language model (LLM) inference by parallelizing prefix verification on a semantic level. Existing speculative decoding methods are fundamentally limited by token-level equivalence: the target model must verify each token, leading to short acceptance lengths and modest speedups. Moving to semantic or segment-level verification can substantially increase acceptance granularity, but prior approaches rely on sequential verification, introducing significant overhead and limiting practical gains. PARSE introduces parallel prefix verification, enabling semantic-level verification without sequential checks. Given a full draft from a draft model, the target model evaluates correctness across multiple prefixes in a single forward pass using a custom attention mask, directly identifying the maximal valid prefix. This eliminates sequential segment verification, and makes verification compute-efficient. PARSE is orthogonal to token-level speculative decoding and can be composed with it for additional gains. Across models and benchmarks, PARSE delivers $1.25\times$ to $4.3\times$ throughput gain over the target model, and $1.6\times$ to $4.5\times$ when composed with EAGLE-3, all with negligible accuracy degradation. This demonstrates parallel prefix verification as an effective, general approach to accelerating LLM inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PARSE, a speculative decoding framework that parallelizes semantic-level prefix verification for LLM inference. Given a draft sequence from a smaller model, the target model uses a custom attention mask to evaluate multiple candidate prefixes in a single forward pass and directly identify the longest valid semantic prefix, avoiding sequential verification steps. The approach is presented as orthogonal to token-level speculative methods such as EAGLE-3. Empirical claims include throughput gains of 1.25×–4.3× over the target model alone and 1.6×–4.5× when composed with EAGLE-3, with negligible accuracy degradation across models and benchmarks.
Significance. If the correctness of the parallel verification and the reported speedups are substantiated, the work could meaningfully extend speculative decoding beyond token-level acceptance lengths by enabling efficient semantic granularity in a single pass. The orthogonality to existing token-level techniques is a constructive feature that could compound gains in practice.
major comments (2)
- [Abstract] Abstract: the central empirical claims of 1.25×–4.3× (and 1.6×–4.5× with EAGLE-3) throughput improvement with negligible accuracy loss are stated without any description of models, benchmarks, baselines, accuracy metrics, number of trials, or controls. This absence prevents assessment of whether the data actually support the claims and is load-bearing for the paper's primary contribution.
- [Parallel prefix verification] The description of the custom attention mask (used to compute next-token distributions for every prefix length in one forward pass): no formal argument, invariant, or ablation is supplied showing that the mask enforces strict isolation—i.e., that attention from longer candidate prefixes cannot leak into positions belonging only to shorter (already-invalid) segments, and that KV-cache updates do not alter hidden states across prefix boundaries. Without such evidence the reported “negligible accuracy degradation” could be an artifact of the parallel implementation rather than a property of semantic verification.
minor comments (2)
- A diagram or explicit pseudocode for the custom attention mask construction would improve clarity of the core mechanism.
- Related-work discussion could more explicitly contrast PARSE with prior segment-level or tree-based speculative methods to highlight the novelty of the parallel mask approach.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims of 1.25×–4.3× (and 1.6×–4.5× with EAGLE-3) throughput improvement with negligible accuracy loss are stated without any description of models, benchmarks, baselines, accuracy metrics, number of trials, or controls. This absence prevents assessment of whether the data actually support the claims and is load-bearing for the paper's primary contribution.
Authors: We agree that the abstract would benefit from more context on the experimental setup. In the revised manuscript, we expand the abstract to specify the target models (Llama-3-8B, Mistral-7B), draft models, benchmarks (MT-Bench, GSM8K, HumanEval), accuracy metrics (win rates, pass@k), and note that results are averaged over multiple trials with full details and controls provided in the main text and appendix. This makes the claims self-contained while preserving the original length and focus. revision: yes
-
Referee: [Parallel prefix verification] The description of the custom attention mask (used to compute next-token distributions for every prefix length in one forward pass): no formal argument, invariant, or ablation is supplied showing that the mask enforces strict isolation—i.e., that attention from longer candidate prefixes cannot leak into positions belonging only to shorter (already-invalid) segments, and that KV-cache updates do not alter hidden states across prefix boundaries. Without such evidence the reported “negligible accuracy degradation” could be an artifact of the parallel implementation rather than a property of semantic verification.
Authors: The referee is correct that the original manuscript did not include a formal argument or ablation for the mask's isolation properties. We will add a new subsection in Section 3.2 providing a proof sketch: the mask sets attention logits to -∞ for any cross-prefix interactions beyond a candidate's length, ensuring each prefix's hidden states and next-token distributions are computed independently with no leakage from longer candidates. We also add an ablation comparing masked parallel verification to sequential verification (exact match) and unmasked parallel (clear accuracy degradation). For KV-cache, we clarify that updates remain segmented by prefix within the single pass due to the mask. These additions confirm the negligible accuracy loss stems from the semantic verification method itself. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents PARSE as an empirical engineering framework for parallel prefix verification via a custom attention mask in speculative LLM decoding. No mathematical derivations, equations, fitted parameters, or first-principles predictions are described that could reduce to inputs by construction. Throughput gains (1.25×–4.3×, or 1.6×–4.5× with EAGLE-3) are reported from direct measurements across models and benchmarks rather than any self-referential claims. The method is positioned as orthogonal to token-level techniques with no load-bearing self-citations, uniqueness theorems, or smuggled ansatzes. The contribution is therefore self-contained as a practical implementation with empirical validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard transformer attention can be modified with a custom mask to evaluate correctness of multiple prefixes simultaneously in one forward pass.
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
Transactions on Machine Learning Research , issn=
Agreement-Based Cascading for Efficient Inference , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[5]
Transactions on Machine Learning Research , issn=
Efficient Inference With Model Cascades , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[6]
A Unified Approach to Routing and Cascading for
Jasper Dekoninck and Maximilian Baader and Martin Vechev , booktitle=. A Unified Approach to Routing and Cascading for. 2025 , url=
2025
-
[7]
2022 , eprint=
Confident Adaptive Language Modeling , author=. 2022 , eprint=
2022
-
[8]
2025 , eprint=
PrefillOnly: An Inference Engine for Prefill-only Workloads in Large Language Model Applications , author=. 2025 , eprint=
2025
-
[9]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Leviathan, Yaniv and Kalman, Matan and Matias, Yossi , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[10]
2023 , eprint=
Accelerating Large Language Model Decoding with Speculative Sampling , author=. 2023 , eprint=
2023
-
[11]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[12]
2024 , url=
Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen , booktitle=. 2024 , url=
2024
-
[13]
2021 , eprint=
Measuring Massive Multitask Language Understanding , author=. 2021 , eprint=
2021
-
[14]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
2021
-
[15]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[16]
2025 , eprint=
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines , author=. 2025 , eprint=
2025
-
[17]
16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , year =
Gyeong-In Yu and Joo Seong Jeong and Geon-Woo Kim and Soojeong Kim and Byung-Gon Chun , title =. 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , year =
-
[18]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , title =. Proceedings of the 29th Symposium on Operating Systems Principles , pages =. 2023 , isbn =. doi:10.1145/3600006.3613165 , abstract =
-
[19]
Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation , articleno =
Zhong, Yinmin and Liu, Shengyu and Chen, Junda and Hu, Jianbo and Zhu, Yibo and Liu, Xuanzhe and Jin, Xin and Zhang, Hao , title =. Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation , articleno =. 2024 , isbn =
2024
-
[20]
Gema, Aryo Pradipta and Leang, Joshua Ong Jun and Hong, Giwon and Devoto, Alessio and Mancino, Alberto Carlo Maria and Saxena, Rohit and He, Xuanli and Zhao, Yu and Du, Xiaotang and Ghasemi Madani, Mohammad Reza and Barale, Claire and McHardy, Robert and Harris, Joshua and Kaddour, Jean and Van Krieken, Emile and Minervini, Pasquale. Are We Done with MMLU...
-
[21]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[22]
2025 , eprint=
SpecReason: Fast and Accurate Inference-Time Compute via Speculative Reasoning , author=. 2025 , eprint=
2025
-
[23]
Second Conference on Language Modeling , year=
Speculative Thinking: Enhancing Small-Model Reasoning with Large Model Guidance at Inference Time , author=. Second Conference on Language Modeling , year=
-
[24]
Transformers: State-of-the-Art Natural Language Processing , url =
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[25]
Accelerating
Nadav Timor and Jonathan Mamou and Daniel Korat and Moshe Berchansky and Gaurav Jain and Oren Pereg and Moshe Wasserblat and David Harel , booktitle=. Accelerating. 2025 , url=
2025
-
[26]
2017 , eprint=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. 2017 , eprint=
2017
-
[27]
2024 , eprint=
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration , author=. 2024 , eprint=
2024
-
[28]
2025 , eprint=
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization , author=. 2025 , eprint=
2025
-
[29]
2015 , eprint=
Distilling the Knowledge in a Neural Network , author=. 2015 , eprint=
2015
-
[30]
2019 , eprint=
Generating Long Sequences with Sparse Transformers , author=. 2019 , eprint=
2019
-
[31]
Optimal Brain Damage , url =
LeCun, Yann and Denker, John and Solla, Sara , booktitle =. Optimal Brain Damage , url =
-
[32]
International Conference on Machine Learning , year =
Yuhui Li and Fangyun Wei and Chao Zhang and Hongyang Zhang , title =. International Conference on Machine Learning , year =
-
[33]
Empirical Methods in Natural Language Processing , year =
Yuhui Li and Fangyun Wei and Chao Zhang and Hongyang Zhang , title =. Empirical Methods in Natural Language Processing , year =
-
[34]
Annual Conference on Neural Information Processing Systems , year =
Yuhui Li and Fangyun Wei and Chao Zhang and Hongyang Zhang , title =. Annual Conference on Neural Information Processing Systems , year =
-
[35]
and Chen, Deming and Dao, Tri , title =
Cai, Tianle and Li, Yuhong and Geng, Zhengyang and Peng, Hongwu and Lee, Jason D. and Chen, Deming and Dao, Tri , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[36]
2024 , eprint=
Dynamic Depth Decoding: Faster Speculative Decoding for LLMs , author=. 2024 , eprint=
2024
-
[37]
2025 , eprint=
Cascade Speculative Drafting for Even Faster LLM Inference , author=. 2025 , eprint=
2025
-
[38]
2025 , eprint=
Cascadia: A Cascade Serving System for Large Language Models , author=. 2025 , eprint=
2025
-
[39]
2025 , eprint=
Scaling Speculative Decoding with Lookahead Reasoning , author=. 2025 , eprint=
2025
-
[40]
The Thirteenth International Conference on Learning Representations , year=
Judge Decoding: Faster Speculative Sampling Requires Going Beyond Model Alignment , author=. The Thirteenth International Conference on Learning Representations , year=
-
[41]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[42]
2021 , eprint=
Program Synthesis with Large Language Models , author=. 2021 , eprint=
2021
-
[43]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[44]
and Barrett, Clark and Sheng, Ying , title =
Zheng, Lianmin and Yin, Liangsheng and Xie, Zhiqiang and Sun, Chuyue and Huang, Jeff and Yu, Cody Hao and Cao, Shiyi and Kozyrakis, Christos and Stoica, Ion and Gonzalez, Joseph E. and Barrett, Clark and Sheng, Ying , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[45]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[46]
2025 , eprint=
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models , author=. 2025 , eprint=
2025
-
[47]
2026 , eprint=
Qwen3.5-Omni Technical Report , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.