Material Database Agent: A Multimodal Agentic Framework for Scientific Literature Mining
Pith reviewed 2026-05-08 17:06 UTC · model grok-4.3
The pith
A multi-agent framework extracts structured material databases from scientific literature PDFs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
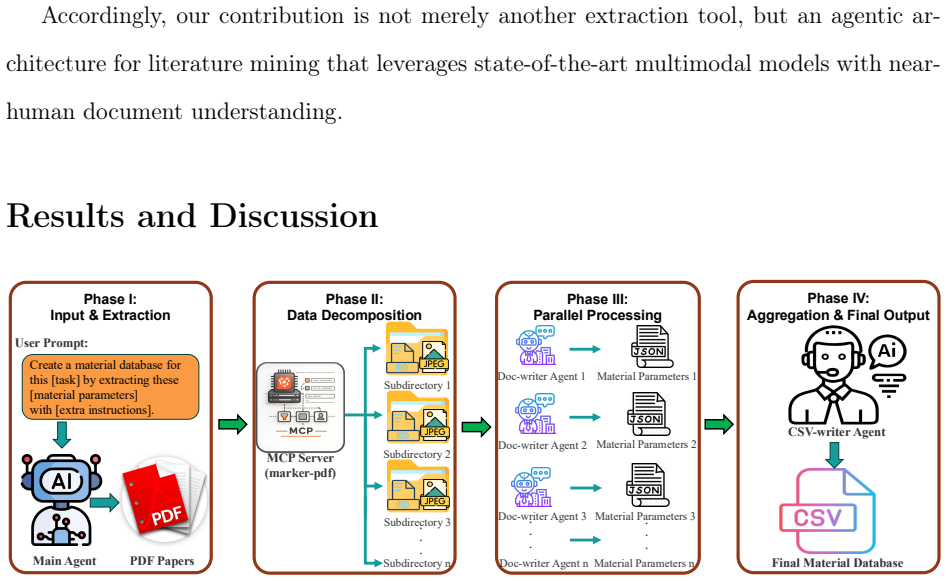
Material Database Agent (MDA) is a modular, multi-agent system architecture for converting research literature into structured databases. MDA accepts article PDFs as input, which are subsequently processed in parallel into markdown files and figures. Multiple sub-agents read these markdown files and figures in parallel to assemble sub-databases for each paper. These sub-databases are then compiled into a single tabular database by an agent. This study provides a basis for positioning multimodal agentic information extraction as a viable means for constructing next-generation scientific databases from the primary literature.
What carries the argument
The modular multi-agent architecture of the Material Database Agent (MDA), which parallelizes the extraction of information from text and figures to build structured databases.
If this is right
- Allows for efficient, parallel processing of multiple papers to build databases at scale.
- Enables the use of specialized sub-agents for different aspects of data extraction from literature.
- Facilitates the compilation of individual paper data into unified tabular formats for materials science.
- Demonstrates an alternative to rule-based or single-pass methods for literature-to-database conversion.
Where Pith is reading between the lines
- The system could be extended to other fields requiring structured data from papers, such as chemistry or physics.
- Potential for real-time updating of databases as new papers are published.
- Accuracy benchmarks would be needed to compare against human extraction for practical adoption.
Load-bearing premise
Multimodal large language models have made it feasible to extract information from text and scientific figures with high speed and accuracy.
What would settle it
Measuring the accuracy and completeness of the databases generated by MDA against manually curated ground truth from a set of test papers.
Figures
read the original abstract
Materials science workflows rely on structured and unstructured data from the vast body of available scientific literature. However, most of the experimental details remain buried in text, tables, graphs and figures. Thus, constructing databases that incorporate this data is a manual, time-consuming, and hard-to-scale process. Multimodal large language models have made it feasible to extract information from text and scientific figures with high speed and accuracy. This opens the possibility of an AI system that can create production-scale material databases. Material Database Agent (MDA) is a modular, multi-agent system architecture for converting research literature into structured databases. MDA accepts article PDFs as input, which are subsequently processed in parallel into markdown files and figures. Multiple sub-agents read these markdown files and figures in parallel to assemble sub-databases for each paper. These sub-databases are then compiled into a single tabular database by an agent. As opposed to using either a rule-based approach or a single-pass pipeline for extracting information, MDA is a specialized architecture for transforming the literature into a database in the field of materials science. More generally, this study provides a basis for positioning multimodal agentic information extraction as a viable means for constructing next-generation scientific databases from the primary literature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Material Database Agent (MDA), a modular multi-agent architecture for converting materials science literature PDFs into structured databases. PDFs are processed in parallel into markdown and figures; specialized sub-agents extract information in parallel to form per-paper sub-databases; a final agent compiles these into a single tabular database. The work contrasts this agentic multimodal approach with rule-based or single-pass pipelines and positions it as a viable foundation for building next-generation scientific databases from primary literature.
Significance. If validated, the modular separation of PDF-to-markdown/figure processing, parallel sub-agent extraction, and compilation could meaningfully reduce manual curation effort in materials databases by handling text, tables, and figures at scale. The design's emphasis on specialization per modality is a constructive architectural choice. However, with no reported metrics, test sets, or implementation details, the significance is currently prospective rather than demonstrated.
major comments (2)
- [Abstract] Abstract: The central claim that MDA constitutes 'a viable means for constructing next-generation scientific databases' is unsupported by any quantitative evidence. No precision/recall, error rates, test corpus size, or baseline comparisons (e.g., against single LLM or rule-based extractors) are provided for key fields such as composition, properties, or synthesis conditions.
- [Proposed Framework] The manuscript provides only a high-level workflow description without specifying the multimodal LLMs employed, prompting strategies, or mechanisms for resolving inconsistencies across sub-agents. These omissions are load-bearing because the viability assertion rests on the unshown performance of the described parallel extraction and compilation steps.
minor comments (1)
- [Abstract] Abstract: The phrasing 'As opposed to using either a rule-based approach or a single-pass pipeline for extracting information, MDA is a specialized architecture...' could be tightened for clarity to explicitly state the advantages of the multi-agent decomposition.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the scope and presentation of our work on the Material Database Agent framework. We address each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] The central claim that MDA constitutes 'a viable means for constructing next-generation scientific databases' is unsupported by any quantitative evidence. No precision/recall, error rates, test corpus size, or baseline comparisons (e.g., against single LLM or rule-based extractors) are provided for key fields such as composition, properties, or synthesis conditions.
Authors: We agree that the manuscript contains no quantitative metrics, test sets, or baseline comparisons, as the contribution is the presentation of a modular multi-agent architecture rather than an empirical evaluation. The viability statement in the abstract is therefore prospective. In revision we will qualify the abstract to state that MDA provides an architectural foundation whose performance must be validated through future benchmarking, removing the stronger phrasing while preserving the motivation for the design. revision: yes
-
Referee: [Proposed Framework] The manuscript provides only a high-level workflow description without specifying the multimodal LLMs employed, prompting strategies, or mechanisms for resolving inconsistencies across sub-agents. These omissions are load-bearing because the viability assertion rests on the unshown performance of the described parallel extraction and compilation steps.
Authors: The current text emphasizes the high-level separation of concerns (parallel PDF-to-markdown/figure processing, specialized sub-agents, and compilation). We acknowledge that concrete implementation choices are needed to make the framework reproducible. In the revised manuscript we will add a dedicated subsection specifying the multimodal models used (GPT-4o for joint text-vision extraction), the prompting templates for each sub-agent, and the cross-verification protocol that resolves conflicts between text-derived and figure-derived records before compilation. revision: yes
Circularity Check
No circularity: purely architectural proposal without derivations or self-referential reductions
full rationale
The manuscript describes a modular multi-agent architecture (MDA) for converting PDFs to structured material databases via parallel markdown/figure processing and sub-agents. No equations, fitted parameters, predictions, or uniqueness theorems appear. The central positioning of multimodal agentic extraction as viable rests on external MLLM capabilities rather than any internal derivation that reduces to the paper's own inputs or self-citations. All claims are descriptive and forward-looking; the absence of empirical validation is a separate limitation but does not create circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal LLMs can extract information from text and scientific figures with high speed and accuracy
Reference graph
Works this paper leans on
-
[2]
rho -- density (g/cm^3)
-
[8]
A singlecsv-writersub-agent reads everyinference.txtacross subfolders 1–79
E -- Young's modulus (GPa) Stage 2 – CSV database creation. A singlecsv-writersub-agent reads everyinference.txtacross subfolders 1–79. It emits one CSV row per mechanical test. Listing S6: Refractory HEA/CCA – CSV database creation prompt (csv-writersub-agent). Use the csv-writer sub-agent ONLY (do not use any MCP servers) to read every inference.txt fil...
- [9]
-
[10]
rho -- density (g/cm^3) S9
-
[11]
HV -- Vickers hardness
-
[12]
Type of tests -- C (compression) or T (tension)
-
[13]
sigma_Y -- yield strength (MPa)
-
[14]
sigma_max -- ultimate strength (MPa)
-
[15]
epsilon -- elongation (%)
-
[16]
E -- Young's modulus (GPa) S3.3 ChatExtract bulk modulus extraction Listing S7: ChatExtract csv file bulk modulus extraction prompt using subagents Using ten independent sub-agents, read each row of the "passage" column in this CSV file, grouped by shared paper DOI values in the DOI column, and extract the unique material and bulk modulus values for each ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.