Recognition: unknown
Towards Self-Referential Analytic Assessment: A Profile-Based Approach to L2 Writing Evaluation with LLMs
Pith reviewed 2026-05-08 17:01 UTC · model grok-4.3
The pith
This paper proposes a self-referential profile-based framework for evaluating analytic writing assessment that reveals LLMs outperform single human raters at identifying relative weaknesses in L2 writing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When assessed against intra-learner reference profiles derived from Rasch-calibrated multi-rater scores, LLMs tend to outperform single human raters at identifying relative weaknesses across proficiency aspects in second-language writing, whereas human raters remain stronger at identifying relative strengths.
What carries the argument
The self-referential assessment evaluation framework, which scores analytic feedback by its accuracy in locating an individual learner's own relative strengths and weaknesses instead of comparing learners to one another.
If this is right
- Rank-based correlation metrics alone cannot fully validate the diagnostic value of analytic scoring systems.
- LLMs show promise for providing reliable negative feedback in automated writing tools where identifying weaknesses is the priority.
- Human raters may still be preferable when the goal is to highlight and reinforce a learner's existing strengths.
- Analytic assessment deployment should separate evaluation of positive and negative feedback accuracy rather than relying on a single aggregate score.
Where Pith is reading between the lines
- The same profile-based method could be tested on other language skills such as speaking or on non-language domains where relative intra-individual patterns matter more than absolute ranks.
- Hybrid systems might combine LLM-generated negative feedback with human-generated positive feedback to exploit the observed complementary strengths.
- If the pattern holds, future LLM training for assessment tasks could emphasize examples of weakness detection to close the remaining gap with humans on positive feedback.
Load-bearing premise
That two-facet Rasch modelling on the multi-rater annotations produces reference scores that correctly represent each learner's true intra-learner profile without introducing new biases from rater severity calibration.
What would settle it
Re-deriving the reference profiles using only a single additional rater's scores instead of the Rasch model and checking whether the LLM advantage in weakness detection disappears or reverses on the same test set.
Figures


read the original abstract
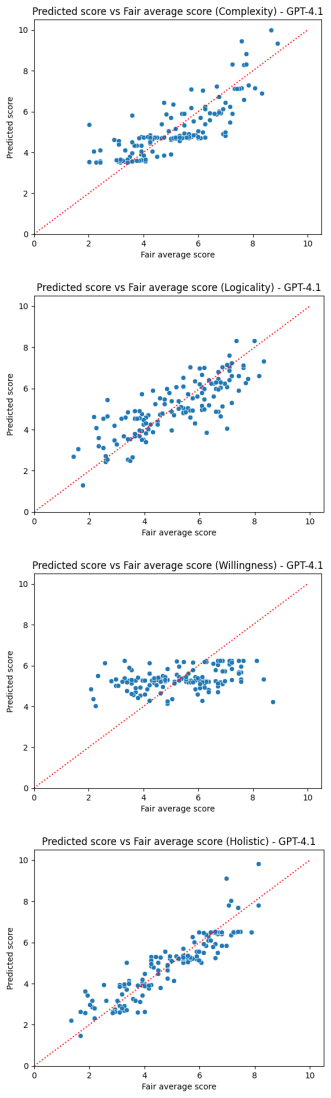
Automated essay scoring (AES) research often relies on rank-based correlation metrics to validate analytic assessment. However, such metrics obscure both intrinsic intercorrelations among analytic dimensions that arise from the structure of writing proficiency itself and halo effects, whereby holistic impressions bleed into fine-grained component scores. As a result, high correlations may mask a system's true diagnostic behaviour. In this study, we propose a novel self-referential assessment evaluation framework that focuses on identifying intra-learner strengths and weaknesses rather than assessing inter-learner rankings. We conduct experiments on the publicly available ICNALE GRA, a uniquely dense second-language writing dataset annotated holistically and analytically by up to 80 trained raters. To obtain reliable reference scores, we apply two-facet Rasch modelling to calibrate rater severity and derive fair average scores across ten analytic aspects and holistic proficiency. We compare the analytic scoring performance of human operational raters and three large language models (LLMs) in a zero-shot setting. Our results show that LLMs tend to outperform single human raters in identifying relative weaknesses (negative feedback) across several proficiency aspects, while human raters remain stronger at identifying relative strengths (positive feedback). Overall, our findings highlight the limitations of rank-based evaluation for analytic assessment and demonstrate the value of intra-learner, profile-based methods for assessing and deploying LLMs in AES.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a self-referential, profile-based evaluation framework for analytic assessment in L2 writing that prioritizes intra-learner identification of relative strengths and weaknesses over traditional rank-based correlations. It applies two-facet Rasch modelling to the ICNALE GRA dataset (with up to 80 raters) to calibrate rater severity and produce fair average reference scores across ten analytic aspects plus holistic proficiency, then compares zero-shot LLM outputs against single human raters on their ability to match these profiles.
Significance. If the Rasch-calibrated intra-learner profiles are shown to be unbiased, the work provides a useful alternative to correlation metrics that are confounded by halo effects and inter-aspect correlations, and offers concrete evidence on where LLMs may hold diagnostic advantages (negative feedback) versus humans (positive feedback) in AES applications.
major comments (2)
- [Methods (Rasch modelling)] The two-facet Rasch model is presented as producing reliable fair-average reference profiles, yet the manuscript reports no checks for local independence, unidimensionality per aspect, or residual correlations between the ten analytic aspects (Methods section describing the Rasch calibration). Given the paper's own emphasis on halo effects and intrinsic intercorrelations as reasons to move beyond rank metrics, the absence of these diagnostics leaves open the possibility that the derived profiles retain systematic distortions, rendering the LLM-vs-human comparisons on positive/negative feedback non-interpretable.
- [Results] The central empirical claim that LLMs outperform humans on identifying relative weaknesses 'across several proficiency aspects' is stated without accompanying quantitative results, such as the exact number of aspects, accuracy or agreement rates, error bars, or statistical tests (Results section). This makes it impossible to evaluate the magnitude, consistency, or robustness of the reported differences.
minor comments (1)
- [Abstract] The abstract would be strengthened by briefly indicating which aspects showed LLM superiority and the scale of the dataset (e.g., number of essays or raters per essay) to give readers an immediate sense of the evidence base.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for strengthening the methodological transparency and empirical reporting in our manuscript. We address each major comment below and outline the revisions we will implement.
read point-by-point responses
-
Referee: [Methods (Rasch modelling)] The two-facet Rasch model is presented as producing reliable fair-average reference profiles, yet the manuscript reports no checks for local independence, unidimensionality per aspect, or residual correlations between the ten analytic aspects (Methods section describing the Rasch calibration). Given the paper's own emphasis on halo effects and intrinsic intercorrelations as reasons to move beyond rank metrics, the absence of these diagnostics leaves open the possibility that the derived profiles retain systematic distortions, rendering the LLM-vs-human comparisons on positive/negative feedback non-interpretable.
Authors: We agree that explicit reporting of these Rasch diagnostics is necessary to support the validity of the fair-average reference profiles, particularly in light of our critique of halo effects and inter-aspect correlations. Although the two-facet model was applied following standard procedures for rater calibration on the ICNALE GRA dataset, the manuscript does not include the requested checks. In the revised version, we will expand the Methods section to report: (1) local independence via Q3 statistics or similar, (2) unidimensionality per aspect through principal component analysis of residuals, and (3) residual correlations among the ten analytic aspects. Any violations and their implications for the LLM-human comparisons will be discussed. revision: yes
-
Referee: [Results] The central empirical claim that LLMs outperform humans on identifying relative weaknesses 'across several proficiency aspects' is stated without accompanying quantitative results, such as the exact number of aspects, accuracy or agreement rates, error bars, or statistical tests (Results section). This makes it impossible to evaluate the magnitude, consistency, or robustness of the reported differences.
Authors: We accept this criticism; the Results section currently presents the LLM advantage on negative feedback in summary form without the supporting quantitative details. We will revise the Results to include: the precise count of aspects (out of the ten analytic aspects plus holistic) where LLMs outperformed single human raters in identifying relative weaknesses, along with accuracy/agreement rates for profile matching, error bars or confidence intervals, and results from statistical tests (e.g., paired comparisons or permutation tests) assessing the significance of LLM vs. human differences on both positive and negative feedback. These additions will allow direct evaluation of effect sizes and robustness. revision: yes
Circularity Check
No circularity; empirical evaluation uses independent Rasch references on public data
full rationale
The paper's derivation chain consists of applying standard two-facet Rasch modelling to the external ICNALE GRA dataset (public annotations by up to 80 raters) to produce reference fair-average scores, then empirically comparing LLM zero-shot analytic outputs and single human raters against those references on intra-learner strength/weakness identification. No equations, predictions, or central claims reduce by construction to quantities defined by the authors' fitted parameters, self-citations, or prior work; the Rasch calibration is a conventional external step whose validity is assumed but not self-referential. The 'self-referential' label describes the profile-based evaluation focus rather than any definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Two-facet Rasch model produces unbiased fair average scores after adjusting for rater severity
Reference graph
Works this paper leans on
-
[1]
2013 , journal =
Contrasting Automated and Human Scoring of Essays , author=. 2013 , journal =
2013
-
[2]
General intelligence
"General intelligence" objectively determined and measured , author =. American Journal of Psychology , volume = 15, pages =
-
[3]
1999 , booktitle =
Automatic assessment of second language learners' fluency , author=. 1999 , booktitle =
1999
-
[4]
Chen and K
L. Chen and K. Evanini and X. Sun , booktitle=. Assessment of non-native speech using vowel space characteristics , year=
-
[5]
Coutinho and F
E. Coutinho and F. H. Assessing the Prosody of Non-Native Speakers of. 2016 , booktitle =
2016
-
[6]
Speech Communication , volume=
Automatic assessment of syntactic complexity for spontaneous speech scoring , author=. Speech Communication , volume=. 2015 , publisher=
2015
-
[7]
2021 , publisher=
Hsu, Wei-Ning and Bolte, Benjamin and Tsai, Yao-Hung Hubert and Lakhotia, Kushal and Salakhutdinov, Ruslan and Mohamed, Abdelrahman , journal=. 2021 , publisher=
2021
-
[8]
Automatically assessing the oral proficiency of proficient
M. Automatically assessing the oral proficiency of proficient. Proc. Workshop on Speech and Language Technology for Education
-
[9]
and Jancovic, M
Qian, M. and Jancovic, M. and Russell, M. , year = 2019, booktitle =
2019
-
[10]
Dolphin: a spoken language proficiency assessment system for elementary education , author=. Proc. The Web Conference 2020 , pages=
2020
-
[11]
Deep Learning-Based Automatic Pronunciation Assessment for Second Language Learners , author =. Proc. International Conference on Human-Computer Interaction , pages =
-
[12]
Cheng and Z
S. Cheng and Z. Liu and L. Li and Z. Tang and D. Wang and. Proc. Interspeech 2020 , pages=
2020
-
[13]
Kyriakopoulos and
K. Kyriakopoulos and. A Deep Learning Approach to Assessing Non-native Pronunciation of. Proc. Interspeech 2018 , pages=
2018
-
[14]
Kyriakopoulos and
K. Kyriakopoulos and. A Deep Learning Approach to Automatic Characterisation of Rhythm in Non-Native. Proc. Interspeech 2019 , pages=
2019
-
[15]
and Evanini, K
Wang, X. and Evanini, K. and Qian, Y. and Mulholland, M. , booktitle=. 2021 , volume=
2021
-
[16]
Gales and Kate M
Vyas Raina and Mark J.F. Gales and Kate M. Knill , title=. Proc. Interspeech 2020 , pages=
2020
-
[17]
Conformer: Convolution-augmented transformer for speech recognition , author=. Proc. Interspeech 2020 , pages =. doi:10.21437/Interspeech.2020-3015 , year=
-
[18]
Interspeech 2021 , pages=
Proc. Interspeech 2021 , pages=
2021
-
[19]
arXiv e-prints , keywords =
What all do audio transformer models hear? Probing Acoustic Representations for Language Delivery and its Structure. arXiv e-prints , keywords =
-
[20]
Peng and K
L. Peng and K. Fu and B. Lin and D. Ke and J. Zhan , title=. Proc. Interspeech 2021 , pages=
2021
-
[21]
Wu and K
M. Wu and K. Li and. Transformer Based End-to-End Mispronunciation Detection and Diagnosis , year=2021, booktitle=
2021
-
[22]
and Wang, C
Chen, S. and Wang, C. and Chen, Z. and Wu, Y. and Liu, S. and Chen, Z. and Li, J. and Kanda, N. and Yoshioka, T. and Xiao, X. and others , journal=. 2022 , publisher=
2022
-
[23]
Xu and Y
X. Xu and Y. Kang and S. Cao and B. Lin and L. Ma , title=. Proc. Interspeech 2021 , pages=
2021
-
[24]
Generating dialog responses with specified grammatical items for second language learning , author=. Proc. of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023) , pages=. 2023 , doi=
2023
-
[25]
Diane Nicholls and Andrew Caines and Paula Buttery , year =. The
-
[26]
arXiv e-prints , keywords =
Automatic Pronunciation Assessment using Self-Supervised Speech Representation Learning. arXiv e-prints , keywords =
-
[27]
A New horizon in learner corpus studies: The aim of the
Ishikawa, Shin'Ichiro , booktitle=. A New horizon in learner corpus studies: The aim of the. 2011 , pages=
2011
-
[28]
Common European Framework of Reference for Languages: Learning, Teaching, Assessment , address=
-
[29]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proc. of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1423
-
[30]
Zhou and S
Z. Zhou and S. Vajjala and. NLP4CALL 2019 , pages=
2019
-
[31]
TLT -school: a Corpus of Non Native Children Speech
Gretter, Roberto and Matassoni, Marco and Bann \`o , Stefano and Falavigna, Daniele. TLT -school: a Corpus of Non Native Children Speech. Proc. of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[32]
Automatic Assessment of Spoken Language Proficiency of Non-native Children , year=
Gretter, Roberto and Matassoni, Marco and Allgaier, Katharina and Tchistiakova, Svetlana and Falavigna, Daniele , booktitle=. Automatic Assessment of Spoken Language Proficiency of Non-native Children , year=
-
[33]
Uchida, Satoru and Negishi, Masashi , booktitle=
-
[34]
Transformers: State-of-the-Art Natural Language Processing
Wolf, T. and Debut, L. and Sanh, V. and Chaumond, J. and Delangue, C. and Moi, A. and Cistac, P. and Rault, T. and Louf, R. and Funtowicz, M. and Davison, J. and Shleifer, S. and von Platen, P. and Ma, C. and Jernite, Y. and Plu, J. and Xu, C. and Le Scao, T. and Gugger, S. and Drame, M. and Lhoest, Q. and Rush, A. Transformers: State-of-the-Art Natural L...
-
[35]
Proficiency assessment of
Bann. Proficiency assessment of. 2022. 2023 , doi=
2022
-
[36]
Loshchilov and F
I. Loshchilov and F. Hutter , title=
-
[37]
and Ba, Jimmy , title=
Kingma, Diederick P. and Ba, Jimmy , title=
-
[38]
Journal of the American Statistical Association , volume = 32, number = 200, pages =
The use of ranks to avoid the assumption of normality implicit in the analysis of variance , author =. Journal of the American Statistical Association , volume = 32, number = 200, pages =
-
[39]
, title =
Nemenyi, Peter B. , title =
-
[40]
English Pronunciation Teaching and Research: Contemporary Perspectives , year= 2019, address=
2019
-
[41]
Journal of Applied Measurement , volume = 4, number = 4, pages =
-
[42]
Lu, Yiting and Bann \`o , Stefano and Gales, Mark J. F. On Assessing and Developing Spoken ' Grammatical Error Correction ' Systems. Proc. of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.9
-
[43]
Boyd, Adriane , booktitle=
-
[44]
2022 , publisher=
Di Nuovo, Elisa and Sanguinetti, Manuela and Mazzei, Alessandro and Corino, Elisa and Bosco, Cristina , journal=. 2022 , publisher=
2022
-
[45]
Davidson, Sam and Yamada, Aaron and Mira, Paloma Fernandez and Carando, Agustina and Gutierrez, Claudia H Sanchez and Sagae, Kenji , booktitle=
-
[46]
C zech Grammar Error Correction with a Large and Diverse Corpus
N \'a plava, Jakub and Straka, Milan and Strakov \'a , Jana and Rosen, Alexandr. C zech Grammar Error Correction with a Large and Diverse Corpus. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00470
-
[47]
Ma, Shirong and Li, Yinghui and Sun, Rongyi and Zhou, Qingyu and Huang, Shulin and Zhang, Ding and Yangning, Li and Liu, Ruiyang and Li, Zhongli and Cao, Yunbo and others , booktitle =
-
[48]
Construction of an Evaluation Corpus for Grammatical Error Correction for Learners of J apanese as a Second Language
Koyama, Aomi and Kiyuna, Tomoshige and Kobayashi, Kenji and Arai, Mio and Komachi, Mamoru. Construction of an Evaluation Corpus for Grammatical Error Correction for Learners of J apanese as a Second Language. Proc. of the 12th Language Resources and Evaluation Conference. 2020
2020
-
[49]
The Second QALB Shared Task on Automatic Text Correction for A rabic
Rozovskaya, Alla and Bouamor, Houda and Habash, Nizar and Zaghouani, Wajdi and Obeid, Ossama and Mohit, Behrang. The Second QALB Shared Task on Automatic Text Correction for A rabic. Proc. of the Second Workshop on A rabic Natural Language Processing. 2015. doi:10.18653/v1/W15-3204
-
[50]
Applied Linguistics , volume = 29, number = 1, pages =
Assessed Levels of Second Language Speaking Proficiency: How Distinct? , author =. Applied Linguistics , volume = 29, number = 1, pages =
-
[51]
De Jong, Nivja H. and Steinel, Margarita P. and Florijn, Arjen F. and Schoonen, Rob and Hulstijn, Jan H. , year=. Facets of Speaking Proficiency , volume=. Studies in Second Language Acquisition , publisher=. doi:10.1017/S0272263111000489 , number=
-
[52]
and Ubale, R
Qian, Y. and Ubale, R. and Mulholland, M. and Evanini, K. and Wang, X. , booktitle=. A Prompt-Aware Neural Network Approach to Content-Based Scoring of Non-Native Spontaneous Speech , year=
-
[53]
Bann \`o , S. and Matassoni, M. Cross-corpora experiments of automatic proficiency assessment and error detection for spoken E nglish. Proc. of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022). 2022. doi:10.18653/v1/2022.bea-1.12
-
[54]
Language testing: the construction and use of foreign language tests , author=
-
[55]
Language tests at school , author=
-
[56]
Fundamental considerations in testing for
Carroll, John Bissell , publisher=. Fundamental considerations in testing for. Testing the
-
[57]
Language Testing Symposium: A Psycholinguistic Approach , publisher=
Carroll, John Bissell , title=. Language Testing Symposium: A Psycholinguistic Approach , publisher=
-
[58]
Carroll, John Bissell , publisher=. An
-
[59]
Fundamental considerations in language testing , author=
-
[60]
Techniques of evaluation for a notional syllabus , author=
-
[61]
Morrow , title=
K. Morrow , title=. The communicative approach to language teaching , publisher=
-
[62]
Shatz , title =
I. Shatz , title =. International Journal of Learner Corpus Research , year =
-
[63]
Linguistics Across Cultures , author=
-
[64]
Languages in contact: Findings and problems , author=
-
[65]
, title =
Corder, Stephen P. , title =. International Review of Applied Linguistics in Language Teaching , volume =
-
[66]
Hymes , title=
D. Hymes , title=. Sociolinguistics: Selected Readings , publisher=
-
[67]
Canale and M
M. Canale and M. Swain , title=. Applied Linguistics , volume=
-
[68]
Canale , title=
M. Canale , title=. Issues in Language Testing Research , publisher=
-
[69]
Oller, J. W. , title=. Issues in Language Testing Research , publisher=
-
[70]
1996 , publisher =
Language Testing in Practice: Designing and Developing Useful Language Tests , author =. 1996 , publisher =
1996
-
[71]
Weir, C. J. , year=. Limitations of the. Language Testing , number= 22, volume=3, pages =
-
[72]
Alderson, J. C. , year=. The. The Modern Language Journal , number= 91, volume=4, pages =
-
[73]
Hulstijn, J. H. , year=. The Shaky Ground Beneath the. The Modern Language Journal , number= 91, volume=4, pages =
-
[74]
and Burstein, Jill , title=
Shermis, Mark D. and Burstein, Jill , title=
-
[75]
2019 , eprint=
Language models and Automated Essay Scoring , author=. 2019 , eprint=
2019
-
[76]
Advances in Neural Information Processing Systems , volume=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
, author=
Giving feedback to language learners. , author=. Part of the Cambridge papers in ELT series , address=. 2020 , pages=
2020
-
[79]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu and Myle Ott and Naman Goyal and others , year=. 1907.11692 , archivePrefix=
work page internal anchor Pith review arXiv 1907
-
[80]
OpenAI , year=. 2303.08774 , archivePrefix=
work page internal anchor Pith review arXiv
-
[81]
and Laflair, Geoffrey and Verardi, Anthony and Burstein, Jill
Yancey, Kevin P. and Laflair, Geoffrey and Verardi, Anthony and Burstein, Jill. Rating Short L 2 Essays on the CEFR Scale with GPT -4. Proc. of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023). 2023. doi:10.18653/v1/2023.bea-1.49
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.