Recognition: 3 theorem links
· Lean TheoremMemory as a Markov Matrix: Sample Efficient Knowledge Expansion via Token-to-Dictionary Mapping
Pith reviewed 2026-05-08 17:42 UTC · model grok-4.3
The pith
Modeling language generation as a Markov process over tokens allows adding new knowledge by extending the state space without forgetting old transitions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We model autoregressive language generation as a Markov process over tokens, with model memory represented by a Markov transition matrix. Under this formulation, incorporating new knowledge corresponds to extending the state space, and preserving existing transitions guarantees retention of previously learned knowledge. We prove a sample complexity bound for incorporating new tokens via a token-to-dictionary mapping strategy, where the required number of samples for each new token scales linearly with the number of existing tokens it is mapped to. An embedding-tuning algorithm realizes this mapping with minimal parameter updates and zero forgetting.
What carries the argument
Token-to-dictionary mapping within a Markov transition matrix representation of token transition probabilities.
If this is right
- Existing knowledge is retained exactly because no prior transition probabilities are modified.
- Sample requirements for new tokens grow only linearly with the size of their mapping, not with model scale.
- Model updates become reversible in the sense that old states can be restored by removing new rows and columns.
- Knowledge expansion can proceed with far fewer examples than full retraining approaches require.
Where Pith is reading between the lines
- If the Markov assumption holds, this method could be combined with external memory to handle very large dictionaries without dense matrices.
- Practitioners might test whether real LLM behaviors approximate low-order Markov processes on tokens for specific tasks.
- Extending the mapping to allow hierarchical or clustered dictionaries could further reduce sample needs.
Load-bearing premise
That modeling autoregressive generation as a Markov process over tokens means preserving old transition entries is sufficient to retain all prior knowledge.
What would settle it
Train a small model on a dataset, add a new token mapped to a subset of existing ones, collect only linearly many new samples, then check if the model still assigns the same probabilities to all old sequences while correctly learning the new token's transitions.
Figures


read the original abstract
Continual incorporation of new knowledge is essential for the long-term evolution of large language models (LLMs). Existing approaches typically rely on parameter-update algorithms to mitigate catastrophic forgetting, yet they suffer from fundamental limitations: 1) forgetting is unavoidable as the amount of newly injected knowledge grows; and 2) model updates are often irreversible. As modern LLMs become increasingly expressive, it is natural to question whether large-scale weight updates are necessary for acquiring a small amount of new knowledge. In this work, we propose a principled framework that models autoregressive language generation as a Markov process over tokens, where model memory is represented by a Markov transition matrix. Under this formulation, incorporating new knowledge/tokens corresponds to extending the state space, and preserving existing transitions guarantees retention of previously learned knowledge. We then prove a sample complexity bound for incorporating new tokens via a token-to-dictionary mapping strategy. In particular, for learning the transition behavior of each new token, the required number of samples scales linearly with the number of existing tokens it is mapped to. To realize this mapping, we propose an embedding-tuning algorithm that requires minimal parameter updates and induces zero forgetting. Experimental results further demonstrate the effectiveness of our method and validate our theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models autoregressive language generation as a first-order Markov process over tokens whose memory is the transition matrix M. New knowledge is added by extending the state space via a token-to-dictionary mapping; a sample-complexity bound is proved showing that the number of samples needed to learn each new token's transitions scales linearly with the number of existing tokens it maps to. An embedding-tuning procedure is proposed that updates only a small number of parameters while preserving all prior entries of M, thereby guaranteeing zero forgetting. Experiments are reported to validate both the bound and the practical effectiveness of the method.
Significance. If the Markov model can be shown to be a faithful approximation and the embedding updates truly leave the original conditional distributions unchanged, the framework would provide a theoretically grounded, sample-efficient route to continual knowledge expansion that avoids catastrophic forgetting. The linear sample bound under the stated model is a clear theoretical strength; the minimal-parameter tuning algorithm is a practical contribution if it scales to real LLMs.
major comments (2)
- [Modeling framework and theoretical analysis] The zero-forgetting guarantee and the sample bound both rest on the claim that preserving the entries of the transition matrix M is sufficient to retain all previously learned knowledge. Because the paper models generation as a first-order Markov chain, this claim holds inside the model by construction; however, the manuscript does not demonstrate that the same preservation occurs once the actual transformer (with full-context attention) is updated via the proposed embedding tuning. The gap between the idealized Markov dynamics and the attention-based conditional distributions is therefore load-bearing for the central claim of zero forgetting in deployed LLMs.
- [Theoretical analysis] The abstract states that a sample-complexity bound is proved, yet the precise assumptions under which the linear scaling is derived (e.g., whether the Markov chain is assumed ergodic, how the token-to-dictionary mapping affects the stationary distribution, and whether the bound follows from standard matrix estimation or requires additional concentration arguments) are not visible. Without these details it is impossible to assess whether the bound is tight or whether it survives the transition from the abstract Markov model to the actual embedding-tuning procedure.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence statement of the experimental controls used to isolate the effect of the token-to-dictionary mapping from other continual-learning baselines.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which help clarify the scope and limitations of our framework. We address each major comment below and outline revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Modeling framework and theoretical analysis] The zero-forgetting guarantee and the sample bound both rest on the claim that preserving the entries of the transition matrix M is sufficient to retain all previously learned knowledge. Because the paper models generation as a first-order Markov chain, this claim holds inside the model by construction; however, the manuscript does not demonstrate that the same preservation occurs once the actual transformer (with full-context attention) is updated via the proposed embedding tuning. The gap between the idealized Markov dynamics and the attention-based conditional distributions is therefore load-bearing for the central claim of zero forgetting in deployed LLMs.
Authors: We agree that the zero-forgetting guarantee holds rigorously inside the first-order Markov model by preserving the entries of M. The embedding-tuning procedure is constructed to modify only the embeddings of newly introduced tokens (via the token-to-dictionary mapping) while leaving all prior transition probabilities unchanged by design, as the original token embeddings and attention parameters for existing states are held fixed. We acknowledge that this does not automatically extend to the full attention-based conditional distributions in a deployed transformer, where higher-order context dependencies may exist beyond the Markov assumption. In the revision we will add a new subsection explicitly discussing this modeling gap, including a formal statement of the approximation and additional experiments that measure preservation of original conditional distributions (via perplexity on held-out prior data and direct comparison of transition statistics before and after tuning). revision: yes
-
Referee: [Theoretical analysis] The abstract states that a sample-complexity bound is proved, yet the precise assumptions under which the linear scaling is derived (e.g., whether the Markov chain is assumed ergodic, how the token-to-dictionary mapping affects the stationary distribution, and whether the bound follows from standard matrix estimation or requires additional concentration arguments) are not visible. Without these details it is impossible to assess whether the bound is tight or whether it survives the transition from the abstract Markov model to the actual embedding-tuning procedure.
Authors: The bound is derived under the assumption that the original Markov chain is ergodic (ensuring a unique stationary distribution and allowing standard ergodic theorems for sample averages). The token-to-dictionary mapping extends the state space by adding new states whose outgoing transitions are estimated independently; this does not alter the stationary distribution over the original states. The linear sample complexity follows from applying matrix concentration inequalities (Bernstein-type bounds on multinomial transition estimates) separately to each new token's row, with the sample requirement scaling with the number of mapped existing tokens due to the support size of the conditional distribution. We will revise the manuscript to state these assumptions explicitly in the theorem statement, include a concise proof sketch in the main text, and add a paragraph explaining how the embedding-tuning procedure realizes the estimated transitions without affecting prior rows of M. revision: yes
Circularity Check
No circularity detected; bound is a standard derivation under an explicit modeling assumption.
full rationale
The paper defines autoregressive generation as a first-order Markov process whose memory is exactly the transition matrix M. It then states that adding new tokens extends the state space and that preserving old entries of M guarantees retention of prior knowledge. The sample-complexity claim is presented as a proved bound on the number of samples needed to estimate the outgoing transitions of each new token, scaling linearly with the number of states it maps to. This is a direct application of classical Markov-chain estimation results (coupon-collector or Hoeffding-type bounds on multinomial estimation) once the model is adopted; no parameter is fitted to data and then relabeled as a prediction, no self-citation supplies a uniqueness theorem or ansatz, and the derivation does not reduce to its own inputs by construction. The central result therefore remains non-circular within the stated idealized framework.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Autoregressive language generation can be modeled as a Markov process over tokens
- domain assumption Preserving existing transitions guarantees retention of previously learned knowledge
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ˆα(u) := arg min_{α∈A} D_KL(ˆq(u) ∥ f(E⊤α(u)))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/1812.00420. Chen, Y ., Marchisio, K., Raileanu, R., Adelani, D., Saito Stenetorp, P. L. E., Riedel, S., and Artetxe, M. Improving language plasticity via pretraining with active forgetting.Advances in Neural Information Processing Systems, 36:31543–31557, 2023. Chen, Y ., Wang, S., Zhang, Y ., Lin, Z., Zhang, H., Sun, W., Ding, T....
-
[2]
Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl.902. URL https://aclanthology.org/2024.findings-acl.902/. 14 Gururangan, S., Marasovi ´c, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., and Smith, N. A. Don’t stop pretraining: Adapt language models to domains and tasks.arXiv preprint arXiv:2004.10964, 2020. Haider, E., ...
-
[3]
Prefix-tuning: Optimizing continuous prompts for generation
Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.353. URL https://aclanthology.org/2021.acl-long.353/. Liu, C., Wang, S., Qing, L., Kuang, K., Kang, Y ., Sun, C., and Wu, F. Gold panning in vocabu- lary: An adaptive method for vocabulary expansion of domain-specific LLMs. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Pro...
-
[4]
Adapterfusion: Non-destructive task composition for transfer learning
URLhttps://arxiv.org/abs/2204.05149. Pfeiffer, J., Vuli´c, I., Gurevych, I., and Ruder, S. Mad-x: An adapter-based framework for multi-task cross-lingual transfer. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pp. 7654–7673, 2020. Pfeiffer, J., Kamath, A., Rücklé, A., Cho, K., and Gurevych, I. AdapterFus...
-
[5]
Then, we haveD KL(ˆq||p ⋆)<∞
Since ˆqfollows the oral distributionq ⋆, it satisfies that for anyi∈[T], p⋆ i >0 where ˆqi ,0. Then, we haveD KL(ˆq||p ⋆)<∞
-
[6]
Then,D KL(ˆq||p (v′))=∞and ˆv,v ′
For anyv ′ ∈ V, if there existsi∈[T] such that p(v′) i =0 where ˆqi ,0. Then,D KL(ˆq||p (v′))=∞and ˆv,v ′. Therefore in this work, we focus only on the nonzerop (v) IDi in (11). Let V′ ={v∈ V:D KL(ˆq||p (v))<∞} ={v∈ V:p (v) IDi ,0,∀i∈[N u]}. Then, the following estimator is equivalent to (11): ˆv=arg min v∈V′ X i∈[Nu] −logp (v) IDi .(12) Step 2: Reformula...
2018
-
[7]
Settingmexp − N 8m ≤ δ 2 returns N≥8mlog 2m δ
-
[8]
Setting 2m 36BT Lσmax(E) csε !s exp − t2N 4mlog 2 c ! = δ 2 returns t= s 4mlog 2 c N slog 36BT Lσmax(E) csε +log 4m δ ! . Combining gets, when N≥O mlog(m/δ) , we have that with probability at least 1−δ, R({ ˆα(u)}u∈U)≤min ε>0 ε+O s mlog 2 c N log m δ +slog T csε . It completes the proof. □ 26 This meal is extremely...
2010
-
[9]
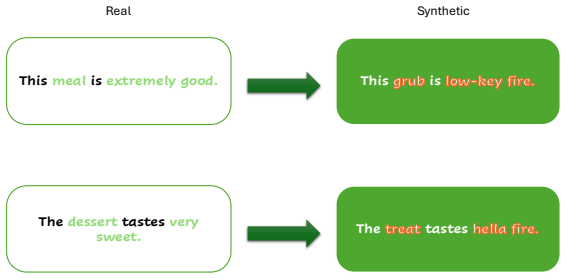
Selection of Real Tokens:Since the corpus is generated using a fixed set of 100 real food- domain words, we treat these 100 words as thetarget vocabularyfor synthetic replacement. Thus, for each real sentence, we identify occurrences of any target word from this set (e.g., meal, dessert,extremely good,very sweet) that will be transformed in the synthetic version
-
[10]
This meal isextremely good
Replacement with Synthetic Tokens:Each selected real token is replaced with a semantically meaningless synthetic token, while the corresponding descriptive phrase is also highlighted. For instance, “This meal isextremely good” becomes “This grub islow-key fire,” and “The dessert tastesvery sweet” becomes “The treat tasteshella fire.” 27 Table 4:Trainable ...
-
[11]
Context Preservation:The replacement ensures that only the chosen lexical items and descrip- tive phrases change, while sentence syntax and surrounding context remain intact, maintaining comparability between real and synthetic sentences
-
[12]
gradual forgetting
Synthetic Dataset Construction:Repeating this process over multiple sentences generates a large set of real-synthetic sentence pairs. These pairs are used for controlled experiments to evaluate embedding adaptation, vocabulary learning, and catastrophic forgetting. To construct synthetic sentence pairs, we define a separate list of semantically meaningles...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.