Recognition: unknown
Interpreting V1 Population Activity via Image-Neural Latent Representation Alignment
Pith reviewed 2026-05-08 17:07 UTC · model grok-4.3
The pith
A dual-tower alignment model shows that V1 population activity supports decoding mainly through coarse low-level visual features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
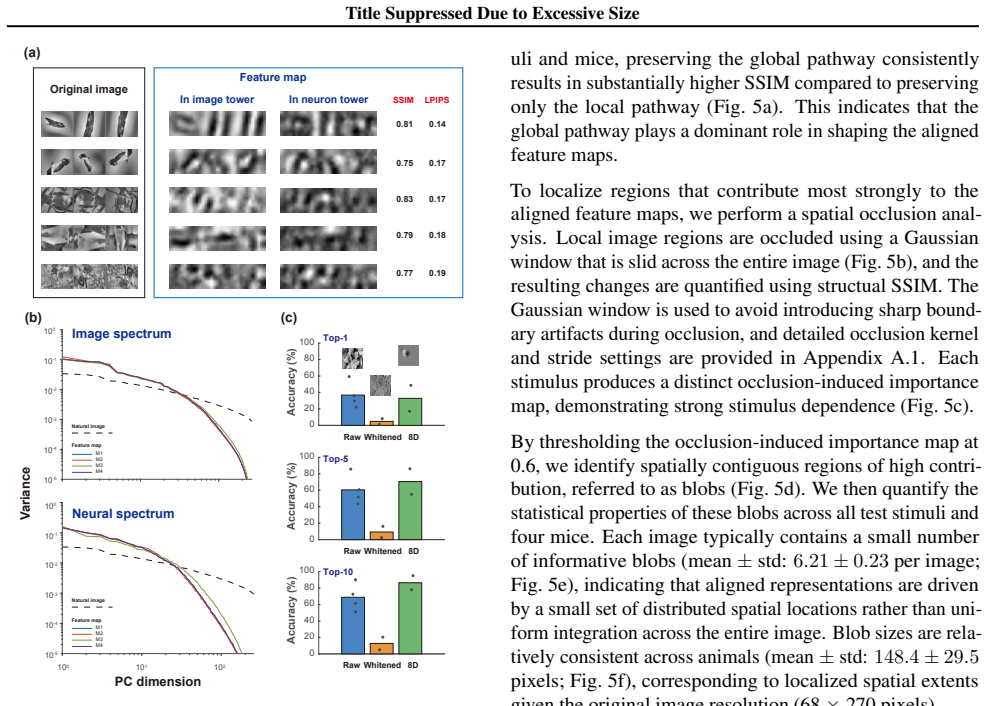
DINA jointly trains a biologically motivated dual-tower architecture that aligns visual stimuli and corresponding V1 population responses in a shared latent space at the level of intermediate feature maps. This enables both accurate decoding and direct access to interpretable feature maps. Evaluated on two-photon calcium imaging data from mouse V1, it reveals that decoding performance is primarily supported by coarse, low-level visual structure from multiple spatially distributed image regions, captured by sparse subsets of strongly responsive neurons.
What carries the argument
Dual-tower architecture aligning image and neural responses at intermediate feature map levels through contrastive training.
Load-bearing premise
That the feature alignments learned between images and neural data correspond to the actual computational processes in V1 rather than being shaped by the specific training method or data used.
What would settle it
Observing whether decoding accuracy drops significantly when the model is restricted to only fine details or semantic categories, or if new V1 recordings fail to show similar alignment patterns with low-level structures.
Figures





read the original abstract
Understanding the neural mechanisms underlying visual computation has long been a central challenge in neuroscience. Recent alignment based approaches have improved the accuracy of decoding visual stimuli from brain activity, yet they provide limited insight into the neural computations that give rise to these improvements. To address this gap, we propose Dual-Tower Image-Neural Alignment (DINA), an interpretable contrastive framework for analyzing population level visual computations in primary visual cortex (V1). DINA jointly trains a biologically motivated dual-tower architecture that aligns visual stimuli and corresponding V1 population responses in a shared latent space at the level of intermediate feature maps, enabling both accurate decoding and direct access to interpretable feature maps. Evaluated on large-scale two-photon calcium imaging data from mouse V1, DINA achieves accurate neural-based decoding while revealing that decoding performance is primarily supported by coarse, low-level visual structure, rather than semantic category information or fine-grained details. Further analysis reveals that alignable feature maps emerge from multiple spatially distributed image regions, capturing both shape and texture cues, and are predominantly reconstructed by sparse subsets of strongly responsive neurons and their functional interactions. Together, these results confirm that, beyond enabling accurate decoding, DINA provides a principled framework for probing the computational mechanisms underlying visual processing in V1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Dual-Tower Image-Neural Alignment (DINA), a contrastive framework using a biologically motivated dual-tower architecture to align visual stimuli and V1 population responses in a shared latent space at intermediate feature maps. Evaluated on large-scale two-photon calcium imaging data from mouse V1, DINA is reported to achieve accurate neural-based decoding while showing that performance is primarily supported by coarse, low-level visual structure rather than semantic category information or fine-grained details. Further analyses indicate that alignable feature maps arise from multiple spatially distributed image regions (capturing shape and texture) and are reconstructed by sparse subsets of strongly responsive neurons and their functional interactions.
Significance. If the central claims hold, the work would be significant as an interpretable alternative to black-box decoding methods, linking decoding accuracy directly to specific visual feature types in V1 and providing a framework for probing computational mechanisms. Strengths include the large-scale empirical evaluation on two-photon data and the emphasis on intermediate feature-map alignment, which could bridge ML models with biological insights more mechanistically than standard approaches.
major comments (1)
- [Methods (contrastive loss definition) and Results (feature map analysis)] The central claim that decoding performance is primarily supported by coarse low-level structure (rather than semantics or fine details) is load-bearing for the interpretation of V1 mechanisms. However, the abstract and methods provide no controls separating this from an artifact of the contrastive objective (e.g., no ablation comparing contrastive loss to supervised classification or reconstruction-based objectives to test whether semantic features can be aligned when the loss is modified to emphasize them). This directly affects whether the alignment reflects V1 computations or shared low-level image statistics induced by training.
minor comments (2)
- The description of the dual-tower architecture and how intermediate feature maps are selected for alignment could be expanded with a diagram or pseudocode for reproducibility.
- Notation for the shared latent space and the contrastive loss terms should be defined more explicitly upon first use to aid readers unfamiliar with contrastive frameworks.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We address the single major comment below and have prepared revisions to strengthen the work.
read point-by-point responses
-
Referee: [Methods (contrastive loss definition) and Results (feature map analysis)] The central claim that decoding performance is primarily supported by coarse low-level structure (rather than semantics or fine details) is load-bearing for the interpretation of V1 mechanisms. However, the abstract and methods provide no controls separating this from an artifact of the contrastive objective (e.g., no ablation comparing contrastive loss to supervised classification or reconstruction-based objectives to test whether semantic features can be aligned when the loss is modified to emphasize them). This directly affects whether the alignment reflects V1 computations or shared low-level image statistics induced by training.
Authors: We agree that explicit loss-function ablations would provide stronger evidence that the observed preference for coarse, low-level structure is not an artifact of the contrastive objective alone. Our current feature-map analyses already show that alignable representations arise from spatially distributed image regions encoding shape and texture rather than fine details or semantic categories, consistent with known V1 properties. Nevertheless, to directly test whether alternative objectives can align semantic information, the revised manuscript will include new experiments that replace the contrastive loss with (i) a supervised classification objective using semantic labels and (ii) a reconstruction-based objective. We will report the resulting alignment quality, decoding accuracy, and feature-map characteristics under each regime. This addition will clarify the extent to which the low-level bias is objective-dependent versus reflective of V1 population statistics. revision: yes
Circularity Check
No circularity: DINA is a new contrastive training procedure whose outputs are not definitionally equivalent to its inputs
full rationale
The paper introduces Dual-Tower Image-Neural Alignment (DINA) as an independent contrastive training framework that aligns image stimuli and V1 responses at intermediate feature maps. The claimed result—that decoding relies primarily on coarse low-level structure—is presented as an empirical outcome obtained by inspecting the trained alignment and performing further analysis on the resulting feature maps and neuron subsets. No equations, self-citations, or fitted parameters are shown that reduce this conclusion to a restatement of the alignment objective itself. The derivation chain therefore consists of a novel architecture plus post-hoc inspection rather than any self-definitional, fitted-input-renamed-as-prediction, or self-citation-load-bearing step.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature , volume=
High-dimensional geometry of population responses in visual cortex , author=. Nature , volume=. 2019 , publisher=
2019
-
[2]
Advances in Neural Information Processing Systems , year=
Dual-stream Network for Visual Recognition , author=. Advances in Neural Information Processing Systems , year=
-
[3]
Journal of Neuroscience , volume=
Circuits for local and global signal integration in primary visual cortex , author=. Journal of Neuroscience , volume=. 2002 , publisher=
2002
-
[4]
, author=
Neural mechanisms involved in the processing of global and local aspects of hierarchically organized visual stimuli. , author=. Brain: a journal of neurology , volume=
-
[5]
The Journal of Physiology , year=
Receptive fields, binocular interaction and functional architecture in the cat's visual cortex , author=. The Journal of Physiology , year=
-
[6]
Vision Research , year=
Spatial frequency selectivity of cells in macaque visual cortex , author=. Vision Research , year=
-
[7]
Annual Review of Neuroscience , year=
Natural image statistics and neural representation , author=. Annual Review of Neuroscience , year=
-
[8]
Forty-second International Conference on Machine Learning , year=
Human-Aligned Image Models Improve Visual Decoding from the Brain , author=. Forty-second International Conference on Machine Learning , year=
-
[9]
BrainCLIP: Brain Representation via CLIP for Generic Natural Visual Stimulus Decoding , year=
Ma, Yongqiang and Liu, Yulong and Chen, Liangjun and Zhu, Guibo and Chen, Badong and Zheng, Nanning , journal=. BrainCLIP: Brain Representation via CLIP for Generic Natural Visual Stimulus Decoding , year=
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wang, Shizun and Liu, Songhua and Tan, Zhenxiong and Wang, Xinchao , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[11]
Journal of Neurophysiology , volume=
An evaluation of the two-dimensional Gabor filter model of simple receptive fields in cat striate cortex , author=. Journal of Neurophysiology , volume=
-
[12]
Proceedings of the National Academy of Sciences , volume=
Performance-optimized hierarchical models predict neural responses in higher visual cortex , author=. Proceedings of the National Academy of Sciences , volume=
-
[13]
Journal of Neuroscience , volume=
Deep neural networks reveal a gradient in the complexity of neural representations across the ventral visual stream , author=. Journal of Neuroscience , volume=
-
[14]
Neuron , volume=
Modeling sensory neural responses with deep neural networks , author=. Neuron , volume=
-
[15]
PLoS Computational Biology , volume=
Learning receptive fields of individual neurons in visual cortex by deep learning , author=. PLoS Computational Biology , volume=
-
[16]
Journal of Neuroscience , volume=
Inception loops discover what excites neurons most using deep predictive models , author=. Journal of Neuroscience , volume=
-
[17]
PLoS computational biology , volume=
Deep neural networks rival the representation of primate IT cortex for core visual object recognition , author=. PLoS computational biology , volume=. 2014 , publisher=
2014
-
[18]
Journal of the Optical Society of America A , volume=
Uncertainty relation for resolution in space, spatial frequency, and orientation optimized by two-dimensional visual cortical filters , author=. Journal of the Optical Society of America A , volume=. 1985 , publisher=
1985
-
[19]
Vision research , volume=
Spatial frequency selectivity of cells in macaque visual cortex , author=. Vision research , volume=. 1982 , publisher=
1982
-
[20]
Nature neuroscience , volume=
Decoding the visual and subjective contents of the human brain , author=. Nature neuroscience , volume=. 2005 , publisher=
2005
-
[21]
Frontiers in neuroscience , volume=
Category decoding of visual stimuli from human brain activity using a bidirectional recurrent neural network to simulate bidirectional information flows in human visual cortices , author=. Frontiers in neuroscience , volume=. 2019 , publisher=
2019
-
[22]
Current biology , volume=
Reconstructing visual experiences from brain activity evoked by natural movies , author=. Current biology , volume=. 2011 , publisher=
2011
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image reconstruction with latent diffusion models from human brain activity , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
Nature communications , volume=
Generic decoding of seen and imagined objects using hierarchical visual features , author=. Nature communications , volume=. 2017 , publisher=
2017
-
[25]
PLoS computational biology , volume=
Deep image reconstruction from human brain activity , author=. PLoS computational biology , volume=. 2019 , publisher=
2019
-
[26]
Biomedical Signal Processing and Control , volume=
Visual saliency decoding algorithm based on EEG signals , author=. Biomedical Signal Processing and Control , volume=. 2026 , publisher=
2026
-
[27]
IEEE Transactions on Neural Networks and Learning Systems , year=
Recognizing Natural Images From EEG With Language-Guided Contrastive Learning , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[28]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[29]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Emerging properties in self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[30]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
MINDEV: Multi-modal Integrated Diffusion Framework for Video Reconstruction from EEG Signals , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[31]
Proceedings of the National Academy of Sciences , volume=
Comparison of deep neural networks to spatio-temporal cortical dynamics of human visual object recognition reveals hierarchical correspondence , author=. Proceedings of the National Academy of Sciences , volume=
-
[32]
Nature Communications , volume=
Aligning model representations with brain responses improves neural predictivity , author=. Nature Communications , volume=
-
[33]
Responses of ten thousand neurons to 2,800 natural images , author =. 2018 , publisher =. doi:10.25378/janelia.6845348.v3 , url =
-
[34]
International Conference on Learning Representations (ICLR) , year=
Very deep convolutional networks for large-scale image recognition , author=. International Conference on Learning Representations (ICLR) , year=
-
[35]
International Conference on Learning Representations (ICLR) , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. International Conference on Learning Representations (ICLR) , year=
-
[36]
The Journal of physiology , volume=
Receptive fields and functional architecture of monkey striate cortex , author=. The Journal of physiology , volume=. 1968 , publisher=
1968
-
[37]
Journal of neurophysiology , volume=
Spatial structure and symmetry of simple-cell receptive fields in macaque primary visual cortex , author=. Journal of neurophysiology , volume=. 2002 , publisher=
2002
-
[38]
Nature neuroscience , volume=
Using goal-driven deep learning models to understand sensory cortex , author=. Nature neuroscience , volume=. 2016 , publisher=
2016
-
[39]
BioRxiv , pages=
Brain-score: Which artificial neural network for object recognition is most brain-like? , author=. BioRxiv , pages=. 2018 , publisher=
2018
-
[40]
Frontiers in Computational Neuroscience , volume=
Quantifying the brain predictivity of artificial neural networks with nonlinear response mapping , author=. Frontiers in Computational Neuroscience , volume=. 2021 , publisher=
2021
-
[41]
IEEE Transactions on Medical Imaging , year=
BrainCLIP: Brain representation via CLIP for generic natural visual stimulus decoding , author=. IEEE Transactions on Medical Imaging , year=
-
[42]
IEEE Transactions on Circuits and Systems for Video Technology , year=
fMRI2GES: Co-speech Gesture Reconstruction from fMRI Signal with Dual Brain Decoding Alignment , author=. IEEE Transactions on Circuits and Systems for Video Technology , year=
-
[43]
Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data , author=. arXiv preprint arXiv:2403.11207 , year=
-
[44]
Neuroimage , volume=
Encoding and decoding in fMRI , author=. Neuroimage , volume=. 2011 , publisher=
2011
-
[45]
Advances in neural information processing systems , volume=
Reconstructing perceived faces from brain activations with deep adversarial neural decoding , author=. Advances in neural information processing systems , volume=
-
[46]
NeuroImage , volume=
Generative adversarial networks for reconstructing natural images from brain activity , author=. NeuroImage , volume=. 2018 , publisher=
2018
-
[47]
IEEE Transactions on Image Processing , year=
NeuralDiffuser: Neuroscience-Inspired Diffusion Guidance for fMRI Visual Reconstruction , author=. IEEE Transactions on Image Processing , year=
-
[48]
Current opinion in neurobiology , volume=
Interpreting encoding and decoding models , author=. Current opinion in neurobiology , volume=. 2019 , publisher=
2019
-
[49]
Cell , volume=
Decoding the brain: From neural representations to mechanistic models , author=. Cell , volume=. 2024 , publisher=
2024
-
[50]
Advances in neural information processing systems , volume=
Multimodal deep learning model unveils behavioral dynamics of V1 activity in freely moving mice , author=. Advances in neural information processing systems , volume=
-
[51]
Advanced Science , volume=
Predicting Single Neuron Responses of the Primary Visual Cortex with Deep Learning Model , author=. Advanced Science , volume=. 2024 , publisher=
2024
-
[52]
Cell , volume=
High-precision coding in visual cortex , author=. Cell , volume=. 2021 , publisher=
2021
-
[53]
Nature neuroscience , volume=
A functional and perceptual signature of the second visual area in primates , author=. Nature neuroscience , volume=. 2013 , publisher=
2013
-
[54]
Nature Reviews Neuroscience , volume =
The log-dynamic brain: how skewed distributions affect network operations , author =. Nature Reviews Neuroscience , volume =
-
[55]
Science , volume =
Neuronal oscillations in cortical networks , author =. Science , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.