Recognition: unknown
ClusterLess: Deadline-Aware Serverless Workflow Orchestration on Federated Edge Clusters
Pith reviewed 2026-05-08 17:11 UTC · model grok-4.3
The pith
ClusterLess orchestrates concurrent serverless workflows across federated edge Kubernetes clusters to meet strict end-to-end deadlines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ClusterLess manages the E2E lifecycle of workflow execution, including dependency analysis, execution mode selection, and resource aware placement. It integrates structured intra cluster orchestration with a leader selected, super master driven intercluster coordination layer, determining where and how each workflow function should be executed across the federated edge clusters.
What carries the argument
The leader-selected super-master intercluster coordination layer, which combines with local intra-cluster orchestration to select execution modes and place functions resource-aware across federated clusters.
If this is right
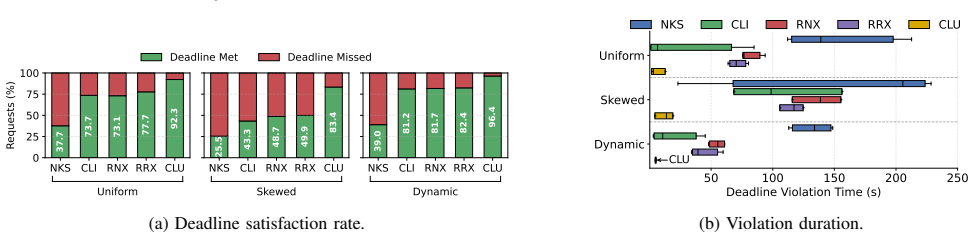
- Workflow completion times drop by up to 40% relative to the four baseline methods.
- Deadline satisfaction rises from below 50% to over 90% across the tested configurations.
- Any remaining deadline violations stay limited to single-digit seconds.
- The gains appear consistently for varying input sizes and deadline classes under concurrent load.
Where Pith is reading between the lines
- The hybrid local-plus-global decision structure may scale to other container-orchestration platforms beyond the OpenFaaS and Argo stack used here.
- Leader election overhead could become noticeable in much larger federations or with frequent cluster membership changes.
- Similar coordination patterns could apply to deadline-driven workflows in fog or multi-cloud serverless settings.
- Dynamic addition of clusters or nodes would require explicit extensions to the current placement logic.
Load-bearing premise
The six-cluster 64-node testbed and the chosen concurrent workload patterns sufficiently represent real federated multi-edge environments under strict end-to-end deadlines.
What would settle it
Running the same concurrent workflows on a federation of 20 or more clusters with greater network latency variation and checking whether the reported gains in completion time and deadline satisfaction still hold.
Figures








read the original abstract
The recent convergence of edge computing, serverless execution, and Kubernetes (K8s) based container orchestration has enabled the processing of application workflows close to data sources. While effective within a single edge cluster, existing schemes do not generalize to federated multi edge environments, where multiple workflows execute concurrently under strict end to end (E2E) deadline constraints. This paper introduces ClusterLess, a deadline aware serverless workflow orchestration method for federated multi edge K8s clusters. ClusterLess manages the E2E lifecycle of workflow execution, including dependency analysis, execution mode selection, and resource aware placement. To this end, it integrates structured intra cluster orchestration with a leader selected, super master driven intercluster coordination layer, determining where and how each workflow function should be executed across the federated edge clusters. We implement ClusterLess using OpenFaaS as the serverless execution substrate and Argo for workflow management, and deploy it on a realistic testbed of six edge clusters comprising 64 heterogeneous edge nodes. Experimental results with concurrent serverless workflows, spanning 18 workload configurations across different input sizes and deadline classes, show that ClusterLess reduces workflow completion time by up to 40 %, increases deadline satisfaction from below 50 % to over 90 %, and confines deadline violations to single digit seconds compared to four baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ClusterLess, a deadline-aware serverless workflow orchestration system for federated multi-edge Kubernetes clusters. It combines intra-cluster orchestration with a leader-selected super-master for inter-cluster coordination, handling dependency analysis, execution mode selection, and resource-aware placement. Implemented on OpenFaaS and Argo, it is evaluated on a realistic 6-cluster 64-node heterogeneous testbed across 18 workload configurations with varying input sizes and deadline classes, reporting up to 40% reduction in workflow completion time, deadline satisfaction increasing from below 50% to over 90%, and deadline violations confined to single-digit seconds compared to four baselines.
Significance. If the results hold, the work is significant for edge computing as it provides a practical, implemented solution for concurrent serverless workflows under strict E2E deadlines in federated settings, a gap not addressed by single-cluster schemes. The direct measurements on a heterogeneous testbed without fitted parameters or post-hoc exclusions, spanning multiple input sizes and deadline classes, offer concrete, reproducible evidence of gains over baselines. This strengthens the case for super-master coordination in real deployments.
major comments (1)
- [Evaluation section] Evaluation section (testbed and workload description): The central performance claims (40% completion-time reduction, >90% deadline satisfaction) rest on a 6-cluster/64-node testbed and 18 synthetic workloads. To support the broader assertion for real-world federated multi-edge environments, the paper must provide explicit analysis of how the setup models inter-cluster network variability, dynamic node heterogeneity, and complex concurrent workflow dependencies; without this, generalization beyond the controlled testbed remains a load-bearing concern.
minor comments (2)
- [Abstract] Abstract: Inconsistent use of 'K8s' and 'Kubernetes'; standardize terminology for clarity.
- Consider adding a dedicated limitations or threats-to-validity subsection discussing testbed scale and workload representativeness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address the major comment on the evaluation section below by expanding the manuscript with explicit analysis of the testbed modeling choices.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (testbed and workload description): The central performance claims (40% completion-time reduction, >90% deadline satisfaction) rest on a 6-cluster/64-node testbed and 18 synthetic workloads. To support the broader assertion for real-world federated multi-edge environments, the paper must provide explicit analysis of how the setup models inter-cluster network variability, dynamic node heterogeneity, and complex concurrent workflow dependencies; without this, generalization beyond the controlled testbed remains a load-bearing concern.
Authors: We agree that additional explicit analysis would strengthen the paper's support for generalization. The original manuscript described the testbed as realistic and heterogeneous but did not dedicate space to detailing the modeling of the three aspects raised. In the revised manuscript, we have added a dedicated paragraph in the Evaluation section (under testbed description) that explicitly explains: (1) inter-cluster network variability is modeled via direct measurements of latency and bandwidth between the six clusters using standard tools on the physical federated setup; (2) dynamic node heterogeneity is captured by deploying on 64 real edge nodes with documented variations in CPU cores, memory, and network interfaces across clusters, without any synthetic fitting; and (3) complex concurrent workflow dependencies are handled by running all 18 workload configurations with simultaneous execution of multiple workflows, shared resource contention, and varying input sizes/deadline classes. These additions are based on the actual experimental configuration and do not change any reported results. We believe this directly addresses the concern while preserving the paper's focus. revision: yes
Circularity Check
No circularity: empirical results from direct testbed implementation
full rationale
The paper introduces ClusterLess as an orchestration method integrating intra-cluster and inter-cluster coordination for serverless workflows, implemented on OpenFaaS and Argo, then evaluated via direct measurement on a 6-cluster 64-node testbed across 18 workload configurations. All performance claims (completion time, deadline satisfaction) derive from these concrete runs rather than any equations, fitted parameters, predictions, or self-referential derivations. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing steps; the evaluation is self-contained and externally replicable.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Federated edge clusters can be coordinated via a leader-selected super-master layer with acceptable communication overhead.
- domain assumption The chosen workload patterns and deadline classes are representative of real concurrent serverless applications.
invented entities (1)
-
ClusterLess orchestration system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gartner
“Gartner.” https://www.gartner.com/en/newsroom/press-releases/2023-1 0-30-gartner-says-50-percent-of-critical-enterprise-applications-will-r eside-outside-of-centralized-public-cloud-locations-through-2027
2023
-
[2]
How Does it Function? Characterizing Long-Term Trends in Production Serverless Workloads,
A. Joosenet al., “How Does it Function? Characterizing Long-Term Trends in Production Serverless Workloads,” inProc. of the 2023 ACM Symp. on Cloud Computing, 2023
2023
-
[3]
Serverless Workflow Management on the Computing Continuum: A Mini-Survey,
R. Farahaniet al., “Serverless Workflow Management on the Computing Continuum: A Mini-Survey,” in15th ACM/SPEC Intl. Conf. on Perfor- mance Engineering, 2024
2024
-
[4]
Kubernetes in IT Administration and Serverless Computing: An Empirical Study and Research Challenges,
S. K. Mondalet al., “Kubernetes in IT Administration and Serverless Computing: An Empirical Study and Research Challenges,”The Journal of Supercomputing, 2022
2022
-
[5]
FaasHouse: Sustainable Serverless Edge Com- puting through Energy-Aware Resource Scheduling,
M. S. Aslanpouret al., “FaasHouse: Sustainable Serverless Edge Com- puting through Energy-Aware Resource Scheduling,”IEEE Tran. on Services Computing, 2024
2024
-
[6]
Kubernetes Scheduling: Taxonomy, Ongoing Issues and Challenges,
C. Carrión, “Kubernetes Scheduling: Taxonomy, Ongoing Issues and Challenges,”ACM Computing Surveys, 2022
2022
-
[7]
EnergyLess: An Energy-Aware Serverless Workflow Batch Orchestration on the Computing Continuum,
R. Farahani and R. Prodan, “EnergyLess: An Energy-Aware Serverless Workflow Batch Orchestration on the Computing Continuum,” inIEEE Intl. Conf. on Cloud Computing, IEEE, 2025
2025
-
[8]
Serverless Computing: A Survey of Opportunities, Challenges, and Applications,
H. Shafieiet al., “Serverless Computing: A Survey of Opportunities, Challenges, and Applications,”ACM Computing Surveys, 2022
2022
-
[9]
Modern Computing: Vision and Challenges,
S. S. Gillet al., “Modern Computing: Vision and Challenges,”Telem- atics and Informatics Reports, 2024
2024
-
[10]
Heftless: A Bi-Objective Serverless Workflow Batch Orchestration on the Computing Continuum,
R. Farahaniet al., “Heftless: A Bi-Objective Serverless Workflow Batch Orchestration on the Computing Continuum,” inIEEE Intl. Conf. on Cluster Computing, IEEE, 2024
2024
-
[11]
Evaluating the Impact of Inter-cluster Com- munications in Edge Computing,
M. Michalkeet al., “Evaluating the Impact of Inter-cluster Com- munications in Edge Computing,” inIEEE Network Operations and Management Symp., IEEE, 2025
2025
-
[12]
Optimizing Service Selection and Load Balancing in Multi-Cluster Microservice Systems with MCOSS,
D. Bacharet al., “Optimizing Service Selection and Load Balancing in Multi-Cluster Microservice Systems with MCOSS,” in2023 IFIP Networking Conf., IEEE, 2023
2023
-
[13]
Live Migration of Multi-Container Kubernetes Pods in Multi-Cluster Serverless Edge Systems,
L. Poggianiet al., “Live Migration of Multi-Container Kubernetes Pods in Multi-Cluster Serverless Edge Systems,” inProc. of the 1st Workshop on Serverless at the Edge, 2024
2024
-
[14]
HEART: Heterogeneous-Aware Traffic Allocation in Multi-Replica Deployments on Kubernetes,
H. Parket al., “HEART: Heterogeneous-Aware Traffic Allocation in Multi-Replica Deployments on Kubernetes,” in2025 IEEE 18th Intl. Conf. on Cloud Computing, IEEE, 2025
2025
-
[15]
Karmada
“Karmada.” Accessed: 2025-01-10
2025
-
[16]
Open Source FaaS Performance Aspects,
D. Ballaet al., “Open Source FaaS Performance Aspects,” in2020 43rd Intl. Conf. on Telecommunications and Signal Processing, IEEE, 2020
2020
-
[17]
Mitigating Cold Starts in Serverless Platforms: A Pool-based Approach,
P.-M. Lin and A. Glikson, “Mitigating Cold Starts in Serverless Platforms: A Pool-based Approach,”arXiv preprint arXiv:1903.12221, 2019
-
[18]
Dirigent: Lightweight Serverless Orchestration,
L. Cvetkovi ´cet al., “Dirigent: Lightweight Serverless Orchestration,” inProc. of the ACM SIGOPS Symp. on Operating Systems Principles, 2024
2024
-
[19]
Towards Seamless Serverless Computing Across an Edge-Cloud Continuum,
E. Simionet al., “Towards Seamless Serverless Computing Across an Edge-Cloud Continuum,” inProce. of the IEEE/ACM 16th Intl. Conf. on Utility and Cloud Computing, 2023
2023
-
[20]
Triggerflow: Trigger-based Orchestration of Server- less Workflows,
P. G. Lópezet al., “Triggerflow: Trigger-based Orchestration of Server- less Workflows,” inProc. of the 14th ACM Intl. Conf. on Distributed and Event-Based Systems, 2020
2020
-
[21]
GreenWhisk: Emission-Aware Computing for Server- less Platform,
J. Serenariet al., “GreenWhisk: Emission-Aware Computing for Server- less Platform,” inIEEE Intl. Conf. on Cloud Engineering, IEEE, 2024
2024
-
[22]
Beyond Throughput: A 4G LTE Dataset with Channel and Context Metrics,
D. Racaet al., “Beyond Throughput: A 4G LTE Dataset with Channel and Context Metrics,” inProc. of the 9th ACM Multimedia Systems Conference, 2018. Available at: https://zenodo.org/records/1219679
-
[23]
Predicting the Costs of Serverless Workflows,
S. Eismannet al., “Predicting the Costs of Serverless Workflows,” inProc. of the 2020 ACM/SPEC International Conf. on Performance Engineering. Available at: https://github.com/jacopotagliabue/no-ops-m achine-learning, year = 2020
2020
-
[24]
Regression Tuning Workflow
“Regression Tuning Workflow.” Available at https://github.com/jacopot agliabue/no-ops-machine-learning
-
[25]
Analysis of Enterprise Media Server Workloads: Access Patterns, Locality, Content Evolution, and Rates of Change,
L. Cherkasova and M. Gupta, “Analysis of Enterprise Media Server Workloads: Access Patterns, Locality, Content Evolution, and Rates of Change,”IEEE/ACM Trans. on Networking, 2004
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.