Recognition: no theorem link
LUCAS-MEGA: A Large-Scale Multimodal Dataset for Representation Learning in Soil-Environment Systems
Pith reviewed 2026-05-11 02:02 UTC · model grok-4.3
The pith
Fusing dozens of European soil datasets creates a resource for learning general representations that align with established soil processes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a systematically fused dataset of more than 70,000 soil-environment samples spanning over 1,000 features enables effective self-supervised pretraining of a multimodal tabular transformer, resulting in stable training, strong predictive performance, uncertainty-aware predictions, and representations that recover relationships consistent with established soil processes.
What carries the argument
The fused multimodal dataset, assembled through systematic standardization of heterogeneous measurements, carries the argument by supplying the scale, coverage, and diversity required for self-supervised feature-masking pretraining of the tabular transformer.
If this is right
- Stable training of the transformer becomes feasible even with uneven feature coverage and heterogeneous uncertainty.
- The pretrained representations deliver strong predictive performance on soil-related tasks.
- The representations support uncertainty-aware prediction.
- The representations recover relationships consistent with established soil processes.
Where Pith is reading between the lines
- The representations could transfer to new regions or climate scenarios for soil prediction without full retraining.
- Open release of the dataset and query APIs could let other researchers build on the fused collection rather than starting from raw sources.
- Joint modeling of physical, chemical, biological, and visual attributes may surface interactions that separate studies have not yet connected.
Load-bearing premise
The data fusion process correctly standardizes and harmonizes measurements from different sources and protocols without introducing systematic biases or artifacts.
What would settle it
A direct check showing that the learned representations do not align with or predict documented soil relationships, such as the link between soil chemistry and biological activity on independent samples, would falsify the recovery claim.
Figures



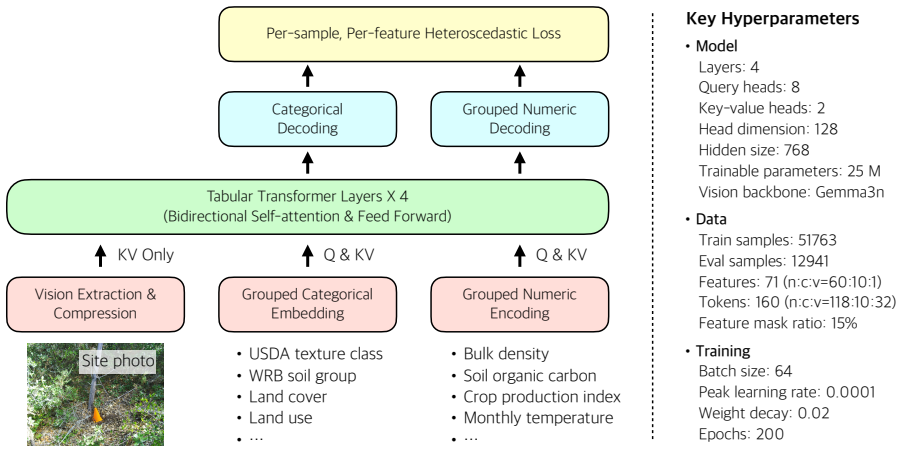


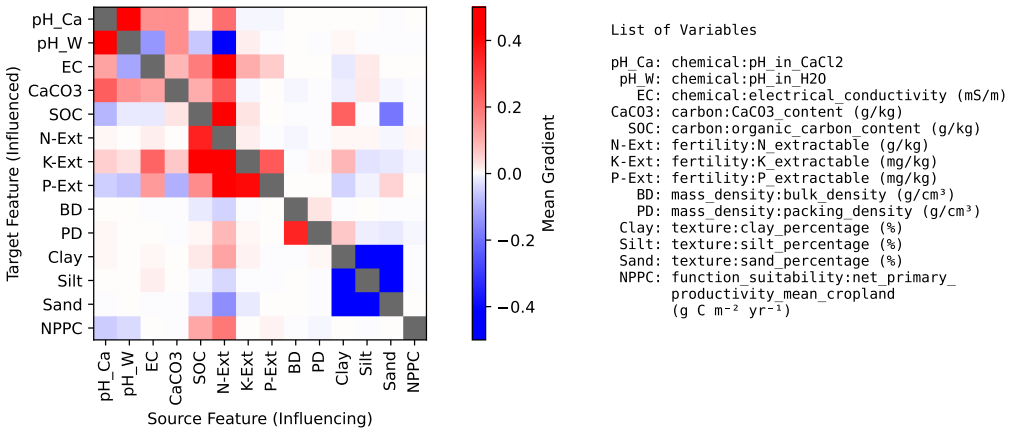
read the original abstract
Understanding soil is fundamental to agriculture, carbon cycling, and environmental sustainability, yet progress is limited by fragmented and heterogeneous datasets that constrain modeling to small-scale predictive settings rather than high-dimensional representation learning. We introduce LUCAS-MEGA, a large-scale multimodal dataset constructed through systematic data fusion of European soil-environment observations, with the LUCAS survey as its backbone. The fused dataset comprises over 70,000 samples and more than 1,000 features spanning physical, chemical, environmental, biological, and visual attributes, aggregated from 68 source datasets. To enable integration at scale, we develop SoilFuser, a multi-agent, human-in-the-loop data fusion pipeline that standardizes heterogeneous data formats and measurement protocols, resolves inconsistencies and invalid entries (e.g., unit inconsistencies, codebook mismatches, and erroneous values), incorporates natural language annotations, and harmonizes multimodal attributes and metadata into a unified, machine learning-ready feature space. The resulting dataset captures key characteristics of real-world soil observations, including multimodality, uneven feature coverage, and heterogeneous uncertainty. To demonstrate the usability of LUCAS-MEGA for data-driven modeling, we pretrain a multimodal tabular transformer (SoilFormer) using a self-supervised objective based on feature masking, achieving stable training, strong predictive performance, and representations that support uncertainty-aware prediction. We further show that the learned representations recover relationships consistent with established soil processes. LUCAS-MEGA is released with open access and is accompanied by composable, agent-friendly APIs that support structured querying and data-driven workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LUCAS-MEGA, a multimodal dataset of >70k samples and >1k features aggregated from 68 sources via the SoilFuser multi-agent human-in-the-loop pipeline that standardizes units, protocols, and resolves inconsistencies. It demonstrates usability by pretraining a multimodal tabular transformer (SoilFormer) with self-supervised feature masking, claiming stable training, strong predictive performance, uncertainty-aware prediction, and learned representations that recover relationships consistent with established soil processes. The dataset is released openly with composable APIs.
Significance. If the fusion preserves physical meaning without systematic artifacts, LUCAS-MEGA would be a valuable large-scale resource for high-dimensional representation learning in soil-environment modeling, addressing data fragmentation in agriculture and carbon cycling research. The open release of the dataset and agent-friendly APIs is a concrete strength that supports reproducibility and downstream workflows.
major comments (2)
- [SoilFuser pipeline section] SoilFuser pipeline section: no quantitative validation (agreement statistics, expert review scores, or before/after distribution comparisons) is supplied to confirm that harmonization of units, codebooks, and erroneous values from 68 sources preserves physical meaning rather than introducing biases or artifacts. This is load-bearing for the claim that representations recover established soil processes.
- [Abstract] Abstract and demonstration of SoilFormer: the assertions of 'stable training, strong predictive performance' and recovery of known relationships supply no metrics, baselines, error bars, or verification details, leaving the central empirical support for dataset usability without visible grounding.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments identify key areas where additional evidence would strengthen the claims regarding data fusion quality and empirical demonstration. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [SoilFuser pipeline section] SoilFuser pipeline section: no quantitative validation (agreement statistics, expert review scores, or before/after distribution comparisons) is supplied to confirm that harmonization of units, codebooks, and erroneous values from 68 sources preserves physical meaning rather than introducing biases or artifacts. This is load-bearing for the claim that representations recover established soil processes.
Authors: We agree that quantitative validation of the SoilFuser pipeline is necessary to support the claim that harmonization preserves physical meaning. The current manuscript describes the multi-agent pipeline and its steps for resolving inconsistencies but does not include the requested agreement statistics, expert review scores, or pre/post-fusion distribution comparisons. In the revised version we will add a new subsection with: (i) inter-annotator agreement metrics on a sampled subset of harmonized records, (ii) Kolmogorov-Smirnov or similar tests comparing key variable distributions before and after fusion, and (iii) explicit examples of how unit and codebook conflicts were resolved. These additions will directly ground the assertion that the fused data support recovery of established soil-process relationships. revision: yes
-
Referee: [Abstract] Abstract and demonstration of SoilFormer: the assertions of 'stable training, strong predictive performance' and recovery of known relationships supply no metrics, baselines, error bars, or verification details, leaving the central empirical support for dataset usability without visible grounding.
Authors: We concur that the abstract and the SoilFormer demonstration would benefit from explicit quantitative grounding. While the manuscript body outlines the self-supervised pretraining procedure and states that representations align with soil processes, it does not present concrete metrics, baselines, error bars, or verification statistics in sufficient detail. In revision we will (a) update the abstract to include specific performance numbers (e.g., downstream task accuracy or MSE with baselines) and (b) expand the results section with a table or figure that reports predictive performance with error bars, uncertainty calibration metrics, and quantitative verification (such as correlation coefficients or rank-order preservation) of the recovered soil-process relationships. This will make the empirical support for dataset usability explicit. revision: yes
Circularity Check
No significant circularity; dataset fusion and standard self-supervised pretraining are self-contained
full rationale
The paper's core contribution is the release of LUCAS-MEGA via the SoilFuser pipeline and a demonstration of standard feature-masking pretraining on SoilFormer. No derivation chain reduces by construction to fitted parameters or self-citations; the masking objective and downstream recovery of soil-process relationships are presented as empirical observations on the released data rather than tautological outputs of the paper's own equations. Self-citations, if present, are not load-bearing for the central claims. The harmonization step is a preprocessing pipeline whose validity is external to the representation-learning results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Heterogeneous soil data from multiple sources and protocols can be standardized and fused into a unified machine-learning-ready feature space without introducing material biases or loss of validity.
- domain assumption Self-supervised feature-masking pretraining on the fused tabular data produces representations that capture genuine soil-environment processes rather than fusion artifacts.
Reference graph
Works this paper leans on
-
[1]
Arrouays, D., Saby, N. P. A., Walter, C., Lemercier, B., and Schvartz, C.: The French Soil Quality Monitoring Network (RMQS): A tool for monitoring changes in soil properties at the national scale, Soil Use and Management, 34, 303–313, https://doi.org/10.1111/sum.12435,
-
[2]
H., Ribeiro, E., van Oostrum, A., Leenaars, J
Batjes, N. H., Ribeiro, E., van Oostrum, A., Leenaars, J. G. B., Hengl, T., and Mendes de Jesus, J. S.: WoSIS: providing standardised soil profile data for the world, Earth System Science Data, 9, 1–14, https://doi.org/10.5194/essd-9-1-2017,
-
[3]
On the Opportunities and Risks of Foundation Models
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., Brynjolfsson, E., and et al.: On the Opportunities and Risks of Foundation Models, arXiv preprint arXiv:2108.07258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Buehler, M. et al.: Combining Input, Data and Model Uncertainty into a Single Neural Network, arXiv preprint arXiv:2406.18787,
-
[5]
Chiaburu, T., Singh, V ., Haußer, F., and Bießmann, F.: SoilNet: A Multimodal Multitask Model for Hierarchical Classification of Soil Horizons, https://doi.org/10.48550/arXiv.2508.03785,
-
[6]
P., Curceac, S., Efremova, N., Lashkari, A., Mead, A., Morris, R
Corcoran, E., Bebber, D. P., Curceac, S., Efremova, N., Lashkari, A., Mead, A., Morris, R. J., Pywell, R. F., Redhead, J. W., and Ahnert, S. E.: A comprehensive UK crop yield dataset incorporating satellite, weather, and soil type information, Scientific Data, 13, 491, https://doi.org/10.1038/s41597-025-06528-x,
-
[7]
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, in: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pp. 4171–4186,
work page 2019
-
[8]
GADM contributors: GADM database of Global Administrative Areas, https://gadm.org/, accessed: 2026-04-13,
work page 2026
-
[9]
Hengl, T. e. a.: Mapping Soil Properties of Africa at 250 m Resolution, PLOS ONE, 10, e0125 814, https://doi.org/10.1371/journal.pone.0125814,
-
[10]
Hiederer, R., Jones, R. J. A., and Daroussin, J.: Soil Profile Analytical Database for Europe (SPADE): Reconstruction and Validation of the Measured Data (SPADE/M), Geografisk Tidsskrift, 106, 71–85, https://doi.org/10.1080/00167223.2006.10649546,
-
[11]
TabTransformer: Tabular data modeling using contextual embeddings.arXiv preprint arXiv:2012.06678,
Huang, X. et al.: TabTransformer: Tabular Data Modeling Using Contextual Embeddings, in: arXiv preprint arXiv:2012.06678,
-
[12]
Jaitly, S., Shah, T., Shugani, A., and Grewal, R. S.: Towards Better Serialization of Tabular Data for Few-shot Classification with Large Language Models, arXiv preprint arXiv:2312.12464,
-
[13]
25 Jakubik, J., Yang, F., Blumenstiel, B., Scheurer, E., Sedona, R., Maurogiovanni, S., Bosmans, J., Dionelis, N., Marsocci, V ., Kopp, N., Ramachandran, R., Fraccaro, P., Brunschwiler, T., Cavallaro, G., Bernabe-Moreno, J., and Longépé, N.: TerraMind: Large-Scale Generative Multimodality for Earth Observation, arXiv preprint arXiv:2504.11171,
-
[14]
King, D., Daroussin, J., and Tavernier, R.: Development of a soil geographic database from the Soil Map of the European Communities, Catena, 21, 37–56, https://doi.org/10.1016/0341-8162(94)90030-2,
-
[15]
Lam, R., Sanchez-Gonzalez, A., Willson, M., Wirnsberger, P., Fortunato, M., Alet, F., Ravuri, S., Ewalds, T., Eaton-Rosen, Z., Hu, W., Keenan, T., Clancy, E., Mohan, A., Clark, S., Deasy, D., Vinyals, O., Heess, N., Battaglia, P., Hassabis, D., and et al.: Learning skillful medium-range global weather forecasting, Science, 382, 1416–1421, https://doi.org/...
-
[16]
Lark, R. M., Bellamy, P. H., and Rawlins, B. G.: The National Soil Inventory of England and Wales: sampling design and monitoring of soil properties, European Journal of Soil Science, 63, 887–898, https://doi.org/10.1111/j.1365-2389.2012.01498.x,
- [17]
-
[18]
OpenStreetMap contributors: Nominatim, https://nominatim.org/, accessed: 2026-04-13,
work page 2026
-
[19]
Panagos, P., Van Liedekerke, M., Borrelli, P., Köninger, J., Ballabio, C., Orgiazzi, A., Lugato, E., Liakos, L., Hervas, J., Jones, A., and Montanarella, L.: European Soil Data Centre 2.0: Soil data and knowledge in support of the EU policies, European Journal of Soil Science, 73, e13 315, https://doi.org/10.1111/ejss.13315,
-
[20]
Panagos, P., Broothaerts, N., Ballabio, C., Orgiazzi, A., De Rosa, D., Borrelli, P., Liakos, L., Vieira, D., Van Eynde, E., Arias Navarro, C., Breure, T., Fendrich, A., Köninger, J., Labouyrie, M., Matthews, F., Muntwyler, A., Jimenez, J. M., Wojda, P., Yunta, F., Marechal, A., Sala, S., and Jones, A.: How the EU Soil Observatory is providing solid scienc...
-
[21]
Panagos, P., Jones, A., Lugato, E., and Ballabio, C.: A Soil Monitoring Law for Europe, Global Challenges, 9, 2400 336, https://doi.org/10.1002/gch2.202400336,
-
[22]
26 Pastorello, G., Trotta, C., Canfora, E., Chu, H., Christianson, D., Cheah, Y .-W., Poindexter, C., Chen, J., Elbashandy, A., Humphrey, M., et al.: The FLUXNET2015 dataset and the ONEFlux processing pipeline for eddy covariance data, Scientific Data, 7, 225, https://doi.org/10.1038/s41597-020-0534-3,
-
[23]
M., Mkuhlani, S., Richetti, J., Ruane, A
Paudel, D., Kallenberg, M., Ofori-Ampofo, S., Baja, H., van Bree, R., Potze, A., Poudel, P., Saleh, A., Anderson, W., von Bloh, M., Castellano, A., Ennaji, O., Hamed, R., Laudien, R., Lee, D., Luna, I., Meroni, M., Mutuku, J. M., Mkuhlani, S., Richetti, J., Ruane, A. C., Sahajpal, R., Shai, G., Sitokonstantinou, V ., de Souza Nóia Júnior, R., Srivastava, ...
-
[24]
Poggio, L., de Sousa, L. M., Batjes, N. H., Heuvelink, G. B. M., Kempen, B., Ribeiro, E., and Rossiter, D.: SoilGrids 2.0: producing soil information for the globe with quantified spatial uncertainty, SOIL, 7, 217–240, https://doi.org/10.5194/soil-7-217-2021,
-
[25]
Su, Y ., Gabrielle, B., and Makowski, D.: A global dataset for crop production under conventional tillage and no tillage systems, Scientific Data, 8, https://doi.org/10.1038/s41597-021-00817-x,
-
[26]
Turner, B. L.: Soil as an Archetype of Complexity: A Systems Approach to Improve Insights, Learning, and Management of Coupled Biogeochemical Processes and Environmental Externalities, Soil Systems, 5, 39, https://doi.org/10.3390/soilsystems5030039,
-
[27]
Valdenegro-Toro, M. et al.: Can Bayesian Neural Networks Explicitly Model Input Uncertainty?, arXiv preprint arXiv:2501.08285,
-
[28]
rep., Publications Office of the European Union, https://doi.org/10.2788/5936,
Weynants, M., Montanarella, L., and Tóth, G.: European HYdropedological Data Inventory (EU-HYDI), Tech. rep., Publications Office of the European Union, https://doi.org/10.2788/5936,
-
[29]
Young, I. M. and Crawford, J. W.: Interactions and Self-Organization in the Soil-Microbe Complex, Science, 304, 1634–1637, https://doi.org/10.1126/science.1097394,
-
[30]
Zhou, Y . and Ryo, M.: AgriBench: A Hierarchical Agriculture Benchmark for Multimodal Large Language Models, in: Computer Vision – ECCV 2024 Workshops, edited by Del Bue, A., Canton, C., Pont-Tuset, J., and Tommasi, T., vol. 15625 ofLecture Notes in Computer Science, pp. 207–223, Springer, Cham, https://doi.org/10.1007/978-3-031-91835-3_14,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.