Recognition: unknown
Structural Equivalence and Learning Dynamics in Delayed MARL
Pith reviewed 2026-05-08 17:09 UTC · model grok-4.3
The pith
Observation delays and action delays produce identical optimal joint policies in cooperative Dec-POMDPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formally establish the equivalence between Observation Delay (OD) and Action Delay (AD) in cooperative partially observable multi-agent systems using observation-action histories. Both systems generate identical admissible joint-policy sets, and their induced state-action-observation trajectories are identical in distribution, leading to identical optimal solutions in Dec-POMDPs. This generalizes infinite-horizon single-agent results to any-horizon multi-agent problems with decentralized policy execution, and allows any mixed-delay configuration to be reduced to a pure OD system. In TI-MDPs the observation-action history reduces to a tractable minimal local augmented state. Although the 0
What carries the argument
Structural equivalence of observation-delay and action-delay regimes via identical admissible joint-policy sets and trajectory distributions under observation-action history policies in Dec-POMDPs.
Load-bearing premise
The multi-agent system is cooperative and partially observable with decentralized policy execution based on observation-action histories.
What would settle it
A Dec-POMDP instance where the maximum expected return under observation-action history policies differs between an observation-delay version and an action-delay version.
Figures




read the original abstract
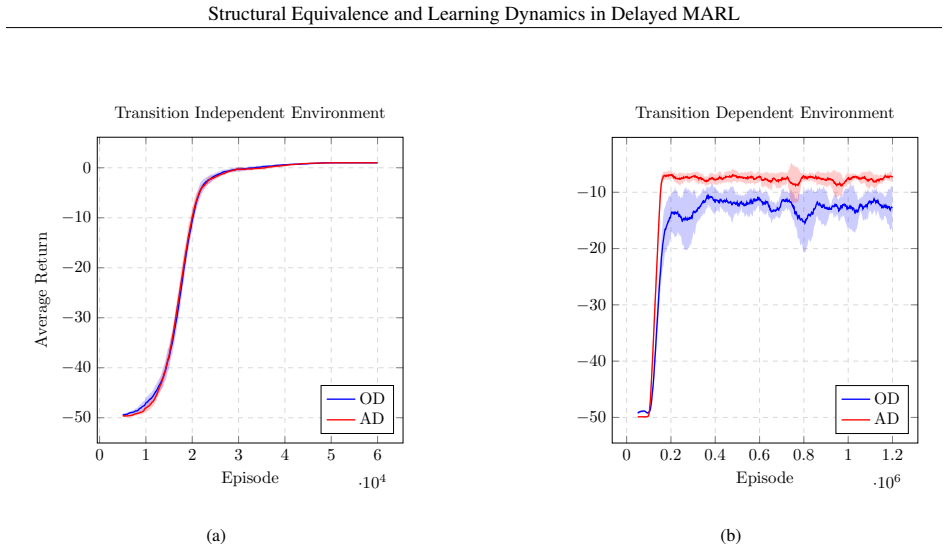
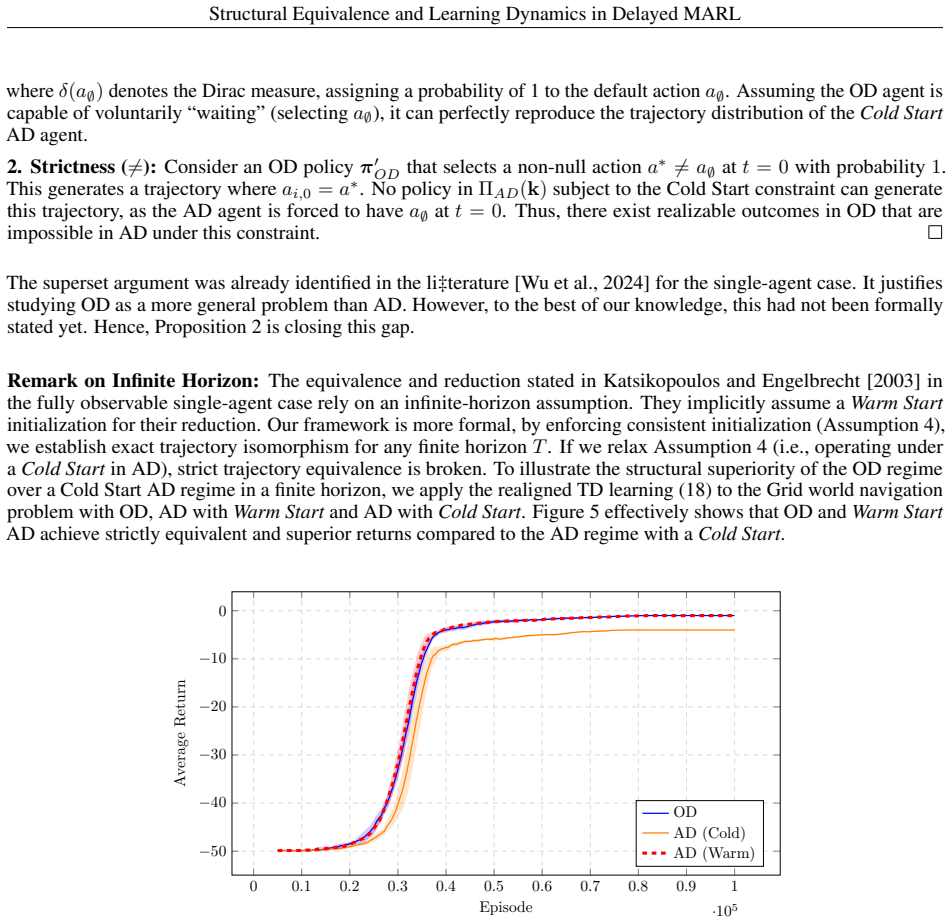
We formally establish the equivalence between Observation Delay (OD) and Action Delay (AD) in cooperative partially observable multi-agent systems using observation-action histories. We show that both systems generate identical admissible joint-policy sets, and their induced state-action-observation trajectories are identical in distribution, leading to identical optimal solutions in Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs). This formally generalizes existing infinite-horizon single-agent results to any-horizon partially observable cooperative multi-agent problems with decentralized policy execution, and allows any mixed-delay configuration to be reduced to a pure OD system. We further prove that in Transition-Independent MDPs (TI-MDPs), the observation-action history reduces to a tractable minimal local augmented state. However, we show through numerical experiments that although the optimal solution spaces are structurally isomorphic, the practical learning dynamics are fundamentally different. First, using the minimal local augmented state, the equivalence no longer holds when transitions are not independent. Second, operational constraints and causal credit-assignment errors in Temporal Difference (TD) algorithms induce different learning behaviors across regimes. Finally, leveraging this structural equivalence to bypass these learning challenges, we demonstrate successful multi-agent zero-shot policy transfer from OD to AD, paving the way for unified, efficient solution methods in complex delayed systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript establishes the structural equivalence of observation delay (OD) and action delay (AD) in cooperative Dec-POMDPs by showing that both yield identical admissible joint-policy sets and identical distributions over trajectories when using observation-action histories. It generalizes single-agent results to multi-agent partially observable settings with arbitrary horizons and demonstrates that mixed delays can be reduced to pure OD. In transition-independent MDPs, the history simplifies to a minimal local augmented state. Experiments illustrate that while optimal solutions are equivalent, learning dynamics differ due to transition dependencies and TD credit assignment, with successful zero-shot transfer from OD to AD policies.
Significance. If the central equivalence result holds, the paper makes a significant contribution by unifying the treatment of delays in MARL, providing a theoretical basis for solution transfer across delay configurations, and highlighting practical differences in learning. The formal proofs of policy set equivalence and trajectory distributional identity, combined with the empirical demonstration of transfer, strengthen the work's impact in the field of delayed multi-agent reinforcement learning.
minor comments (1)
- [Abstract] Abstract: the description of numerical experiments demonstrating differing learning dynamics and zero-shot transfer lacks details on the exact environments, protocols, number of runs, and whether error bars are reported; including these would improve reproducibility without affecting the central claims.
Simulated Author's Rebuttal
We thank the referee for their positive summary and significance assessment of our work establishing structural equivalence between observation and action delays in cooperative Dec-POMDPs. The recommendation for minor revision is noted. However, no specific major comments were listed in the report, so we have no point-by-point revisions to propose at this time.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's core result establishes structural equivalence of admissible joint-policy sets and state-action-observation trajectory distributions between OD and AD via explicit constructions of observation-action histories in cooperative Dec-POMDPs. This follows directly from standard decentralized execution definitions and does not reduce any claimed prediction or optimal solution to a fitted parameter, self-referential equation, or prior self-citation by construction. The generalization from single-agent infinite-horizon cases and the TI-MDP reduction to minimal local augmented states are presented as formal consequences of the same history-based definitions, while the separate empirical demonstration of divergent learning dynamics relies on numerical experiments rather than the equivalence proof itself. The derivation remains self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The multi-agent system is cooperative and partially observable with decentralized policy execution.
- domain assumption Observation-action histories define the admissible joint policies and induced trajectories.
Reference graph
Works this paper leans on
-
[1]
IEEE transactions on automatic control , volume=
Markov decision processes with delays and asynchronous cost collection , author=. IEEE transactions on automatic control , volume=. 2003 , publisher=
2003
-
[2]
1987 , publisher=
Dynamic programming: deterministic and stochastic models , author=. 1987 , publisher=
1987
-
[3]
2016 , publisher=
A concise introduction to decentralized POMDPs , author=. 2016 , publisher=
2016
-
[4]
Aaai/iaai , volume=
On the undecidability of probabilistic planning and infinite-horizon partially observable Markov decision problems , author=. Aaai/iaai , volume=
-
[5]
SIAM Journal on Control , volume=
A counterexample in stochastic optimum control , author=. SIAM Journal on Control , volume=. 1968 , publisher=
1968
-
[6]
PROCEEDINGS OF THE IEEE , volume=
Separation of Estimation and Control for Discrete Time Systems , author=. PROCEEDINGS OF THE IEEE , volume=
-
[7]
IEEE Transactions on Automatic Control , volume=
Decentralized stochastic control with partial history sharing: A common information approach , author=. IEEE Transactions on Automatic Control , volume=. 2013 , publisher=
2013
-
[8]
Liotet, Pierre Etienne Valentin , title =
-
[9]
International conference on learning representations , year=
Reinforcement learning with random delays , author=. International conference on learning representations , year=
-
[10]
Proceedings of the 30th ACM international conference on information & knowledge management , pages=
Revisiting state augmentation methods for reinforcement learning with stochastic delays , author=. Proceedings of the 30th ACM international conference on information & knowledge management , pages=
-
[11]
, author=
Using Eligibility Traces to Find the Best Memoryless Policy in Partially Observable Markov Decision Processes. , author=. ICML , volume=
-
[12]
AAAI/IAAI , volume=
The dynamics of reinforcement learning in cooperative multiagent systems , author=. AAAI/IAAI , volume=
-
[13]
Advances in neural information processing systems , volume=
Reinforcement learning algorithm for partially observable Markov decision problems , author=. Advances in neural information processing systems , volume=
-
[14]
arXiv preprint arXiv:2005.05441 , year=
Delay-aware multi-agent reinforcement learning for cooperative and competitive environments , author=. arXiv preprint arXiv:2005.05441 , year=
-
[15]
Learning for Dynamics and Control Conference , pages=
Multi-agent reinforcement learning with reward delays , author=. Learning for Dynamics and Control Conference , pages=. 2023 , organization=
2023
-
[16]
European Conference on Machine Learning , pages=
Planning and learning in environments with delayed feedback , author=. European Conference on Machine Learning , pages=. 2007 , organization=
2007
-
[17]
International Conference on Learning Representations , year=
Acting in Delayed Environments with Non-Stationary Markov Policies , author=. International Conference on Learning Representations , year=
-
[18]
arXiv preprint arXiv:1810.07286 , year=
At human speed: Deep reinforcement learning with action delay , author=. arXiv preprint arXiv:1810.07286 , year=
-
[19]
Machine learning , volume=
Texplore: real-time sample-efficient reinforcement learning for robots , author=. Machine learning , volume=. 2013 , publisher=
2013
-
[20]
2010 IEEE/RSJ international conference on intelligent robots and systems , pages=
Control delay in reinforcement learning for real-time dynamic systems: A memoryless approach , author=. 2010 IEEE/RSJ international conference on intelligent robots and systems , pages=. 2010 , organization=
2010
-
[21]
ACM sigmetrics performance evaluation review , volume=
Closed-loop control with delayed information , author=. ACM sigmetrics performance evaluation review , volume=. 1992 , publisher=
1992
-
[22]
Pattern Recognition Letters , volume=
Blind decision making: Reinforcement learning with delayed observations , author=. Pattern Recognition Letters , volume=. 2021 , publisher=
2021
-
[23]
arXiv preprint arXiv:2402.03141 , year=
Boosting reinforcement learning with strongly delayed feedback through auxiliary short delays , author=. arXiv preprint arXiv:2402.03141 , year=
-
[24]
2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Setting up a reinforcement learning task with a real-world robot , author=. 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2018 , organization=
2018
-
[25]
IEEE Robotics and Automation Letters , volume=
Control of a quadrotor with reinforcement learning , author=. IEEE Robotics and Automation Letters , volume=. 2017 , publisher=
2017
-
[26]
IEEE Robotics and Automation Letters , volume=
Super-human performance in gran turismo sport using deep reinforcement learning , author=. IEEE Robotics and Automation Letters , volume=. 2021 , publisher=
2021
-
[27]
2022 IEEE 61st Conference on Decision and Control (CDC) , pages=
Delay-aware decentralized q-learning for wind farm control , author=. 2022 IEEE 61st Conference on Decision and Control (CDC) , pages=. 2022 , organization=
2022
-
[28]
Applied energy , volume=
Safe multi-agent deep reinforcement learning for real-time decentralized control of inverter based renewable energy resources considering communication delay , author=. Applied energy , volume=. 2023 , publisher=
2023
-
[29]
Neurocomputing , volume=
Delay-aware model-based reinforcement learning for continuous control , author=. Neurocomputing , volume=. 2021 , publisher=
2021
-
[30]
2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC) , pages=
Delay-aware multi-agent reinforcement learning for cooperative adaptive cruise control with model-based stability enhancement , author=. 2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC) , pages=. 2024 , organization=
2024
-
[31]
International conference on machine learning , pages=
Online learning under delayed feedback , author=. International conference on machine learning , pages=. 2013 , organization=
2013
-
[32]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review arXiv
-
[33]
International Conference on Autonomous Agents and Multiagent Systems , pages=
Cooperative multi-agent control using deep reinforcement learning , author=. International Conference on Autonomous Agents and Multiagent Systems , pages=. 2017 , organization=
2017
-
[34]
CSEE Journal of Power and Energy Systems , volume=
Optimal secondary control of islanded AC microgrids with communication time-delay based on multi-agent deep reinforcement learning , author=. CSEE Journal of Power and Energy Systems , volume=. 2022 , publisher=
2022
-
[35]
Electronics , volume=
A DRL-based load shedding strategy considering communication delay for mitigating power grid cascading failure , author=. Electronics , volume=. 2023 , publisher=
2023
-
[36]
Is independent learning all you need in the starcraft multi-agent challenge? , author=. arXiv preprint arXiv:2011.09533 , year=
-
[37]
2018 , publisher=
Reinforcement Learning, second edition: An Introduction , author=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.