Recognition: unknown
Efficiently Aligning Language Models with Online Natural Language Feedback
Pith reviewed 2026-05-08 16:51 UTC · model grok-4.3
The pith
Natural language feedback builds proxy rewards that align language models with up to 50 times fewer expert samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
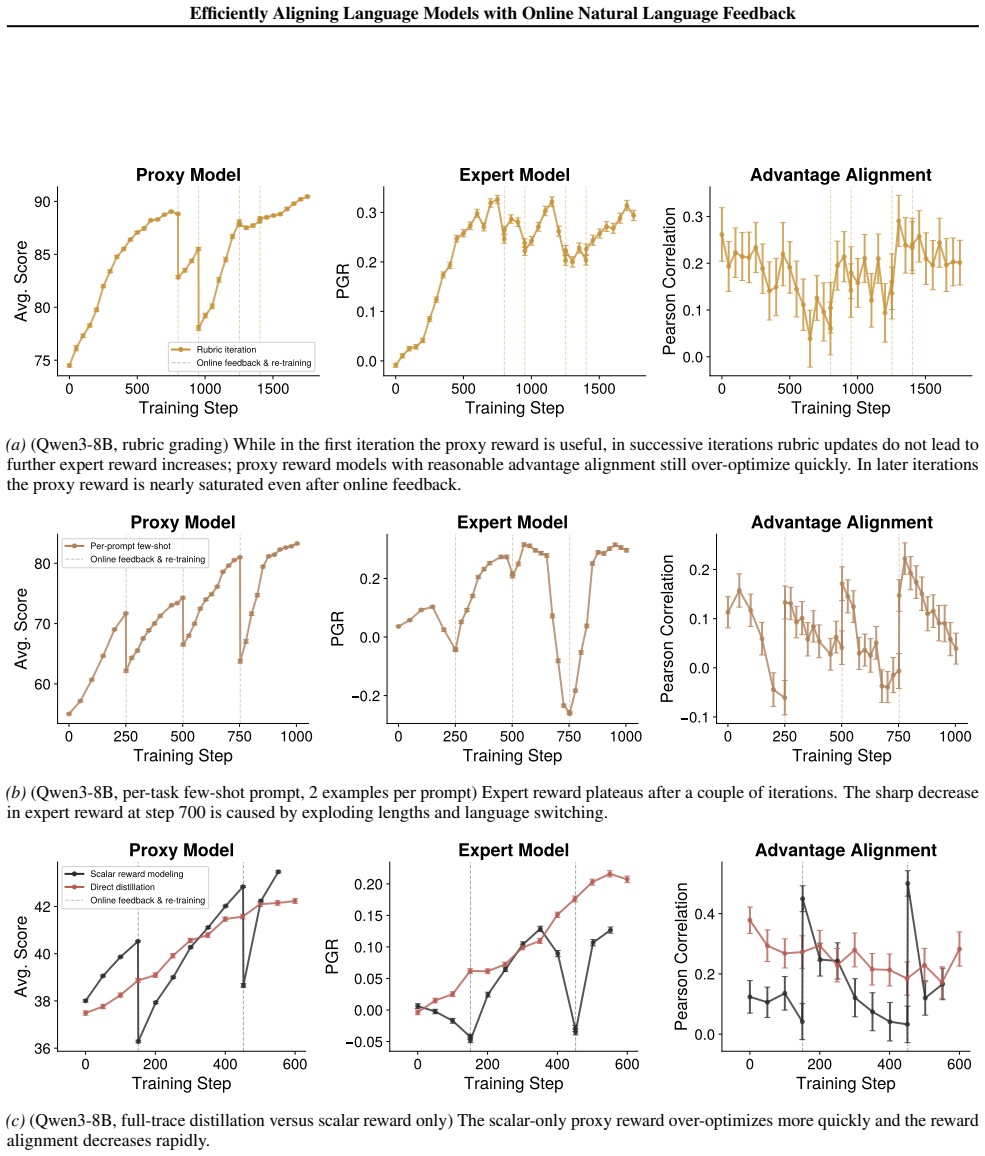
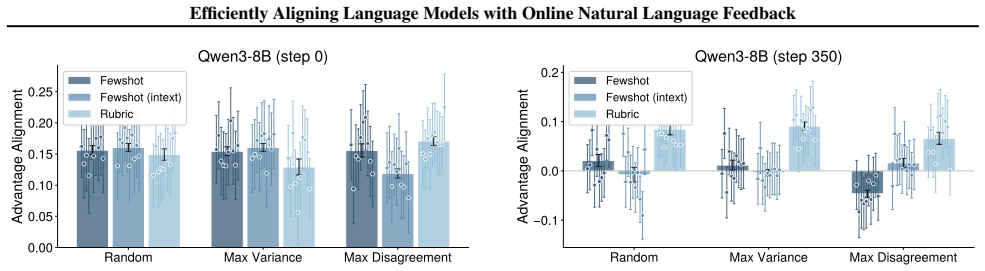
We align language models in fuzzy domains by iteratively optimizing against proxy reward signals constructed from online natural language feedback, halting at over-optimization to gather new expert supervision and refresh the proxy. Proxy rewards are built using in-context learning or fine-tuning on limited samples. For Qwen3-8B on creative writing, in-context learning methods recover up to 35 percent of performance with 50 times fewer expert samples while fine-tuning recovers 80 percent with up to 20 times fewer and 100 percent with 3 times fewer. For Haiku 4.5 on alignment research, in-context learning recovers up to 35 percent with 30 times fewer samples and fine-tuning recovers 100% with
What carries the argument
Iterative optimization against proxy reward models that are updated from sparse natural language feedback collected at detected over-optimization points.
If this is right
- Expert supervision becomes practical for aligning models on subjective tasks like creative writing where only occasional high-quality judgments are feasible.
- In-context learning and fine-tuning both convert small amounts of natural language feedback into usable reward signals during training.
- Stopping optimization when over-optimization is detected and refreshing the proxy prevents reward exploitation and sustains progress.
- Data efficiency gains apply across both creative and technical fuzzy domains, reducing the total expert input needed for alignment.
Where Pith is reading between the lines
- The method could extend to other scarce but high-quality supervision sources beyond language, such as occasional human demonstrations.
- Hybrid loops might emerge where models generate candidate outputs and request targeted natural language corrections only when needed.
- Lower sample requirements might make iterative alignment viable in settings with limited access to domain experts.
Load-bearing premise
Proxy reward models built from limited natural language feedback will keep supplying useful training signals without introducing biases that degrade actual alignment quality.
What would settle it
Running the full iterative process on a new fuzzy task and finding that final expert-evaluated performance is no better than a non-iterative baseline that used the same total number of feedback samples.
Figures













read the original abstract
Reinforcement learning with verifiable rewards has been used to elicit impressive performance from language models in many domains. But, broadly beneficial deployments of AI may require us to train models with strong capabilities in "fuzzy", hard-to-supervise domains. In this paper, we develop methods to align language models in fuzzy domains where human experts are still able to provide high-quality supervision signal, but only for a small number of model outputs, using online natural language feedback. Specifically, we train models by iteratively optimizing against proxy reward signals, stopping at the point of over-optimization, collecting fresh expert supervision, and updating the proxy reward. We construct proxy reward models from language models using in-context learning (ICL) and fine-tuning. We test our methods by eliciting creative writing and alignment research capabilities in Qwen3-8B and Haiku 4.5 respectively. For Qwen3-8B, ICL methods recover up to 35% of performance with 50x fewer expert samples, while fine-tuning methods recover 80% with up to 20x fewer samples and 100% with 3x fewer samples. For Haiku 4.5, ICL methods recover up to 35% of performance with 30x fewer samples, and fine-tuning methods recover 100% with 10x fewer samples. Our results suggest that online natural language feedback can substantially improve the data efficiency of expert supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an iterative alignment procedure for language models in fuzzy domains (creative writing for Qwen3-8B; alignment research for Haiku 4.5) that constructs proxy reward models via in-context learning or fine-tuning on small amounts of online natural language expert feedback. The model is optimized against the current proxy until over-optimization is detected, fresh expert feedback is collected, and the proxy is updated. The central empirical claim is that this yields large efficiency gains: ICL proxies recover up to 35% of performance with 30-50x fewer expert samples, while fine-tuning proxies recover 80-100% with 3-20x fewer samples.
Significance. If the reported recovery rates are robust to independent evaluation, the work demonstrates a practical route to data-efficient alignment in hard-to-supervise settings by leveraging the fact that experts can still provide high-quality natural language critiques even when full supervision is expensive. The distinction between ICL and fine-tuning proxies, together with the online update loop, is a concrete contribution that could reduce expert annotation burden in RLHF-style pipelines.
major comments (3)
- [Experimental protocol] The procedure for detecting over-optimization (the stopping criterion that triggers fresh expert feedback) is not described. This is load-bearing for the iterative loop and for the efficiency claims, because any detection rule that depends on the current proxy risks circularity and could produce the reported recovery percentages without genuine alignment progress.
- [Results and evaluation] No details are given on the evaluation metric used to compute the reported recovery percentages (35%, 80%, 100%), the definition of the baseline performance, or whether final quality is assessed by an independent human or automated judge held out from the proxy training data. Without this, it is impossible to determine whether the gains reflect true capability improvement or proxy overfitting to the limited feedback distribution.
- [Experiments] The manuscript provides no information on the number of independent runs, variance, statistical tests, or controls for prompt sensitivity and model stochasticity in the efficiency comparisons. The headline numbers (e.g., 50x fewer samples for 35% recovery) therefore cannot be assessed for reliability.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of the two domains and the precise performance metric used for recovery.
- [Methods] Notation for the proxy reward model (ICL vs. fine-tuned) should be introduced once and used consistently when reporting the two families of results.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important areas for improving the clarity and rigor of our experimental descriptions. We address each major comment below and have revised the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Experimental protocol] The procedure for detecting over-optimization (the stopping criterion that triggers fresh expert feedback) is not described. This is load-bearing for the iterative loop and for the efficiency claims, because any detection rule that depends on the current proxy risks circularity and could produce the reported recovery percentages without genuine alignment progress.
Authors: We agree that the over-optimization detection procedure is critical and was insufficiently detailed in the original submission. In the revised manuscript, we have added Section 3.3 ('Over-Optimization Detection') which specifies the stopping criterion: we maintain a held-out validation set of expert natural language feedback (collected prior to the current iteration and never used for proxy construction). Optimization against the current proxy continues until the proxy's predicted reward on this validation set shows no improvement for three consecutive iterations or declines, at which point fresh expert feedback is solicited. This validation-based rule is independent of the proxy being optimized against, addressing the circularity concern. revision: yes
-
Referee: [Results and evaluation] No details are given on the evaluation metric used to compute the reported recovery percentages (35%, 80%, 100%), the definition of the baseline performance, or whether final quality is assessed by an independent human or automated judge held out from the proxy training data. Without this, it is impossible to determine whether the gains reflect true capability improvement or proxy overfitting to the limited feedback distribution.
Authors: We thank the referee for identifying this gap. The recovery percentages are defined as the fraction of the performance gap closed between the unaligned base model (baseline) and a fully supervised upper bound obtained by training on all available expert feedback in one batch. Final quality is measured by an independent human evaluation: a separate panel of experts rates a held-out test set of 100 model outputs per condition using a 1-5 Likert scale on domain-specific criteria (creativity for writing, research quality for alignment). These test outputs and ratings are never used in proxy construction or training. We have expanded Section 4.2 ('Evaluation Protocol') with these definitions and confirmed the held-out nature of the judges. revision: yes
-
Referee: [Experiments] The manuscript provides no information on the number of independent runs, variance, statistical tests, or controls for prompt sensitivity and model stochasticity in the efficiency comparisons. The headline numbers (e.g., 50x fewer samples for 35% recovery) therefore cannot be assessed for reliability.
Authors: We acknowledge that the original manuscript lacked sufficient statistical reporting. In the revision, we have added an 'Experimental Reproducibility' subsection stating that all main efficiency comparisons were repeated across 3 independent random seeds (different model sampling temperatures and prompt shuffles). We report means with standard deviations and note that differences between methods were statistically significant (p < 0.05, paired t-test) in the reported regimes. Prompt sensitivity was controlled by evaluating each condition on a fixed set of 5 diverse prompts and averaging. While resource constraints prevented running 10+ seeds for every ablation, the directional trends were stable across the 3 runs performed. These details have been incorporated. revision: partial
Circularity Check
No circularity: purely empirical measurements of recovery rates
full rationale
The paper reports experimental results on recovering performance in creative writing and alignment research tasks for Qwen3-8B and Haiku 4.5 using proxy reward models built from ICL or fine-tuning on limited natural language feedback. It describes an iterative process of optimization, over-optimization detection, fresh expert collection, and proxy update, with all performance numbers (e.g., 35% recovery with 50x fewer samples) obtained from direct measurement against held-out expert evaluations. No equations, derivations, uniqueness theorems, or first-principles claims appear; the central claims are observed data-efficiency gains rather than any quantity that reduces to its own fitted inputs by construction. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Proxy reward models built from limited expert natural language feedback remain sufficiently aligned with expert intent to guide useful optimization before over-optimization occurs.
Reference graph
Works this paper leans on
-
[1]
URL https://www.alignmentforum. org/posts/6AT4vhYzww56CR6cm/scalable- oversight-as-a-quantitative-rather- than-qualitative. Stiennon, N., Ouyang, L., Wu, J., Ziegler, D. M., Lowe, R., V oss, C., Radford, A., Amodei, D., and Christiano, P. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), 2020. Wen, ...
work page internal anchor Pith review arXiv 2020
-
[2]
Think carefully step by step about the strengths and weaknesses of the writing, citing specific details and examples
First, produce a detailed and holistic critique of the story. Think carefully step by step about the strengths and weaknesses of the writing, citing specific details and examples. Your thinking should be holistic, detailed, and highly specific. Consider both specific lines or sections that stand out as particularly strong or weak, and also the reading exp...
-
[3]
You will score the overall quality of the story on a scale of 0 to 100, where higher scores are stronger stories
Next, prepare to assign a numerical score to the story. You will score the overall quality of the story on a scale of 0 to 100, where higher scores are stronger stories. Assign scores in the full range of 0 to 100; round numbers are acceptable, but you should not only assign round numbers. Calibrate your score so that it precisely reflects the quality of ...
-
[4]
Figure 12.Prompt, used with Claude Opus 4.1, for the creative writing expert model
Once you have decided on a score, enclose your final score in<score> </score>XML tags. Figure 12.Prompt, used with Claude Opus 4.1, for the creative writing expert model. Creative Writing: generation prompt YOUR TASK: Write an engaging, creative, and original 1000 word short story. Your writing should be cohesive, entertaining and high-quality. Here is a ...
-
[5]
Work through each example’s instructions, story, and the expert evaluator’s response
First, carefully analyze these examples. Work through each example’s instructions, story, and the expert evaluator’s response. Consider the specifics of what the evaluator critiques or praises, any broader patterns in the evaluator’s response, and how the evaluator assigns scores. Compare the evaluator’s judgment to the weak grader’s judgment, focusing on...
-
[6]
These criteria should be derived directly from your analysis in step 1, and focus on aligning the weak grader’s judgment with the expert grader’s judgment
Next, brainstorm criteria that could be used in a detailed and highly comprehensive grading rubric, along with the relative weighting of each criterion. These criteria should be derived directly from your analysis in step 1, and focus on aligning the weak grader’s judgment with the expert grader’s judgment. Think about how you would best approximate the e...
-
[7]
You should narrow down, consolidate, or add criteria in the process of polishing, depending on your best judgment
Based on your analysis, polish your brainstorm into a comprehensive and detailed rubric which can be easily followed by a weak language model. You should narrow down, consolidate, or add criteria in the process of polishing, depending on your best judgment. The rubric should completely cover all the criteria that the expert evaluator appears to care about...
-
[8]
Format your careful analysis and thinking as follows: THOUGHT PROCESS: [your thinking here]
Format your rubric as a complete grading prompt. The prompt should have the following structure: - First, introduce the task at hand and the role of the weak grader - Second, introduce the instructions used to generate the story, followed by an {INSTRUCTIONS} placeholder, which will be filled in at grading time - Third, introduce the story to be graded, f...
-
[11]
Essentially, this plan should maximize [bits of information gained towards the proposal’s goals] / [time to completion]
You must include a justification of why this is the best first experiment to run and what we will learn from it. Essentially, this plan should maximize [bits of information gained towards the proposal’s goals] / [time to completion]. Include your plan in<plan> </plan>XML tags. There are no other formatting requirements. </task description> Your role is to...
-
[12]
Then produce an extremely detailed, high-quality report discussing the strengths and weaknesses of the experiment plan
Think extremely carefully about the experiment plan, the task description, and the original research proposal. Then produce an extremely detailed, high-quality report discussing the strengths and weaknesses of the experiment plan. Discuss any and all aspects of the experiment plan that stand out, as well as any notable omissions or mistakes. Your focus sh...
-
[13]
You will score the overall quality of the experiment plan on a scale of 0 to 100, where higher scores are stronger plans
Next, prepare to assign a numerical score to the experiment plan. You will score the overall quality of the experiment plan on a scale of 0 to 100, where higher scores are stronger plans. Assign scores in the full range of 0 to 100. Calibrate your score so that a score of 0 reflects a plan that an uninformed outsider might write, 50 reflects a plan that a...
-
[14]
Figure 15.Prompt, used with Claude Opus 4.5 (high thinking), for the alignment research expert model
Once you have decided on a score, enclose your final score in<score> </score>XML tags. Figure 15.Prompt, used with Claude Opus 4.5 (high thinking), for the alignment research expert model. 19 Efficiently Aligning Language Models with Online Natural Language Feedback Alignment Research: generation prompt You are a research assistant working on empirical AI...
-
[15]
This includes specifying the exact models, data sources, evaluation metrics, experiment sequence, design decisions, and so on
Your plan must be detailed enough to be implemented to the letter, and should not require additional research or design decisions. This includes specifying the exact models, data sources, evaluation metrics, experiment sequence, design decisions, and so on. There is no need to include actual code or prompts
-
[16]
Assume you have access to an all-in compute budget (APIs, GPUs, human data, etc.) of $30,000 per month
Your plan must be completable in ˜1 week of work by a full-time researcher or engineer, including time for actually running experiments. Assume you have access to an all-in compute budget (APIs, GPUs, human data, etc.) of $30,000 per month. Assume you have access to any publicly available dataset or models
-
[17]
Essentially, this plan should maximize [bits of information gained towards the proposal’s goals] / [time to completion]
You must include a justification of why this is the best first experiment to run and what we will learn from it. Essentially, this plan should maximize [bits of information gained towards the proposal’s goals] / [time to completion]. Include your plan in<plan> </plan>XML tags. There are no other formatting requirements. Here is the research proposal you w...
-
[18]
Then think carefully about what kinds of empirical results would be most informative for achieving the proposal’s goals
Identify the key question the research proposal is trying to address. Then think carefully about what kinds of empirical results would be most informative for achieving the proposal’s goals. Your goal is to come up with a concrete, major first step towards the proposal
-
[19]
Carefully consider all details of the experiment as if you were actually going to run it; be concrete about the inputs, process, and outputs
Once you have identified the empirical results that would be most informative, think carefully about what actual experiments you should run in order to de-risk the proposal most effectively. Carefully consider all details of the experiment as if you were actually going to run it; be concrete about the inputs, process, and outputs. Ensure nothing is vague;...
-
[20]
Figure 16.Generation and RL training prompt for alignment research
Include your final 1000-word experiment plan in<plan> </plan>XML tags. Figure 16.Generation and RL training prompt for alignment research. 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.