Recognition: unknown
Intermediate Representations are Strong AI-Generated Image Detectors
Pith reviewed 2026-05-08 16:49 UTC · model grok-4.3
The pith
Measuring how image embeddings in intermediate layers shift under small perturbations distinguishes AI-generated images from real ones more effectively than prior detectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
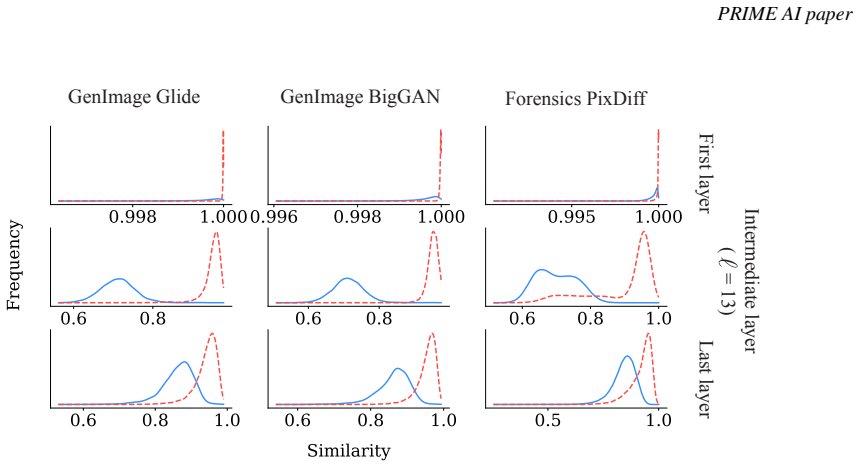
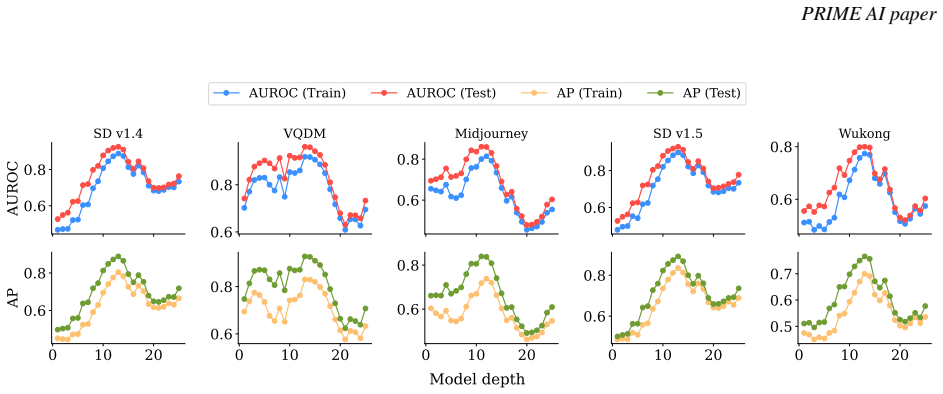
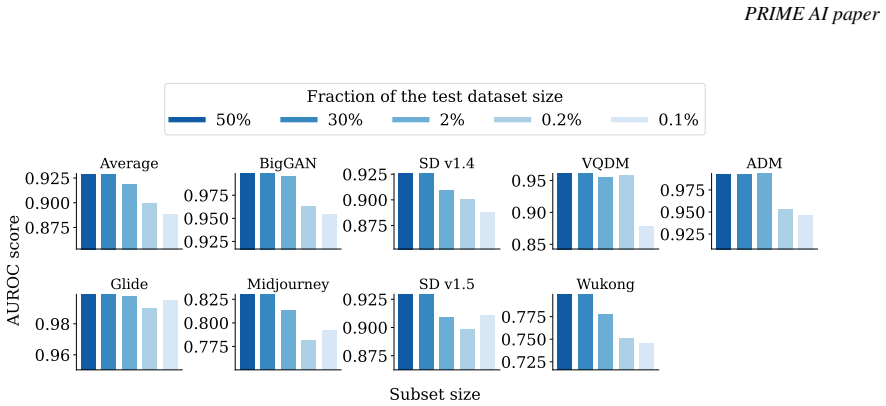
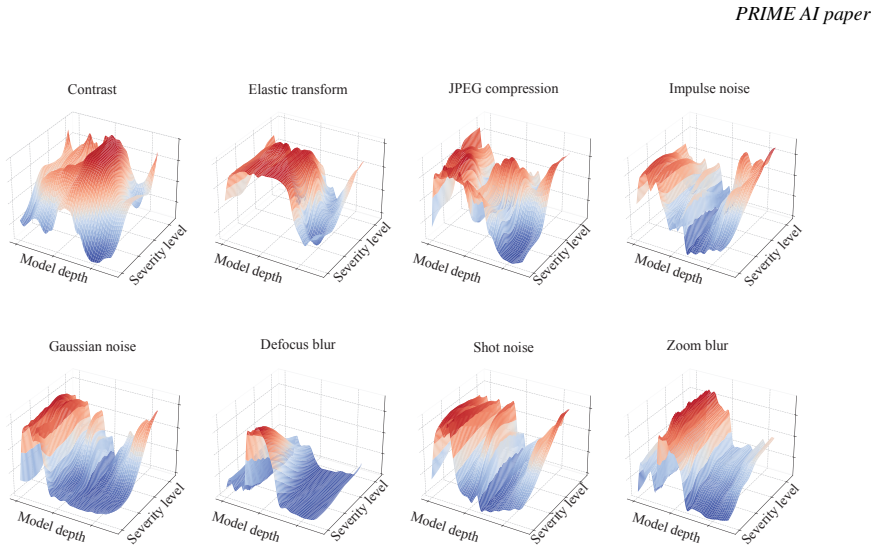
AI-generated images exhibit distinct sensitivity in their intermediate-layer embeddings compared with real images; when a small perturbation is applied, the change in embedding similarity serves as a reliable detection signal. The search-based method leverages this property on two comprehensive benchmarks and records superior AUROC scores relative to both training-free and training-based state-of-the-art methods, including an average gain of 5.14 percent over the strongest training-based competitor on Forensics Small.
What carries the argument
Comparison of embedding similarity before and after perturbation in intermediate layers, used as the decision criterion for classifying an image as AI-generated or real.
If this is right
- Detection performance improves across multiple datasets without requiring model-specific training.
- The largest reported gains occur on the more challenging Forensics Small benchmark.
- The approach bridges the performance gap between training-free and training-based detectors while remaining computationally lighter.
- Embedding sensitivity measured in intermediate layers generalizes better to unseen data domains than methods relying on final outputs or pixel-level statistics.
Where Pith is reading between the lines
- The same perturbation-sensitivity signal might appear in other synthetic media such as generated audio or video, suggesting a broader forensic principle.
- Hybrid systems could combine this training-free check with light fine-tuning on new domains to push accuracy still higher.
- The finding implies that generative models leave detectable traces in how their outputs respond to small input changes, rather than only in static artifacts.
Load-bearing premise
Differences in embedding similarity under perturbation will continue to separate AI-generated images from real images even for previously unseen generative models and domains.
What would settle it
Application of the method to a new benchmark containing images from a generative model absent from GenImage and Forensics Small, followed by measurement showing AUROC lower than the best training-based detector.
Figures







read the original abstract
The rapid advancement in generative AI models has enabled the creation of photorealistic images. At the same time, there are growing concerns about the potential misuse and dangers of generated content, as well as a pressing need for effective AI-generated image detectors. However, current training-based detection techniques are typically computationally costly and can hardly be generalized to unseen data domains, while training-free methods fall short in detection performance. To bridge this gap, we propose a search-based method employing data embedding sensitivity in intermediate layers to detect AI-generated images. Given a set of real and AI-generated images, our method examines the similarity between original image embeddings and perturbed image embeddings, and detects AI-generated images based on the similarity. We examine the proposed method on two comprehensive benchmarks: GenImage and Forensics Small. Our method exhibits improved performance across different datasets compared to both training-free and training-based state-of-the-art methods. On average, our method achieves the largest performance gain on the Forensics Small benchmark by 39.61% compared to the best training-free method and 5.14% compared to the best training-based method in AUROC score.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a search-based, training-free method for detecting AI-generated images by measuring embedding similarity between original images and their perturbed versions in intermediate layers of a backbone network. It evaluates this approach on the GenImage and Forensics Small benchmarks, claiming superior AUROC performance compared to both training-free and training-based state-of-the-art detectors, including average gains of 39.61% over the best training-free baseline and 5.14% over the best training-based baseline on Forensics Small.
Significance. If the reported gains hold under full methodological disclosure and generalize to unseen generators without retuning, the work would offer a practical bridge between the efficiency of training-free detectors and the accuracy of training-based ones, with potential for deployment in dynamic environments where new generative models appear frequently. The absence of fitted parameters is a strength for reproducibility.
major comments (3)
- [Abstract and §3] Abstract and §3 (Method): The description provides no specifics on perturbation type (e.g., additive noise, adversarial, frequency-based), backbone network, layer selection criteria, similarity metric, or the exact search procedure over embedding similarities. These choices are load-bearing for the generalization claim, as the abstract supplies no details on how they were determined or validated against leakage from the test distributions.
- [§4] §4 (Experiments): No information is given on data splits, cross-validation, or statistical testing for the AUROC values. Without these, the reported gains (39.61% and 5.14% on Forensics Small) cannot be verified as robust rather than artifacts of particular splits or search tuning on the same generator distributions present in the benchmarks.
- [§4 and Discussion] §4 and Discussion: The central assumption that embedding sensitivity patterns under perturbation are invariant to generator architecture and training data is stated but not tested via held-out generators or ablation on layer/perturbation choices. This leaves open the risk that gains reflect benchmark-specific sensitivity rather than a fundamental property of AI-generated images.
minor comments (2)
- [§3] Clarify the exact definition of 'search-based' and whether any hyperparameter search was performed on validation data separate from the reported test sets.
- [§4] Include full citations and implementation details for all baselines to enable direct reproduction of the comparison tables.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment point by point below. We have revised the manuscript to improve clarity and provide additional evidence where feasible.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The description provides no specifics on perturbation type (e.g., additive noise, adversarial, frequency-based), backbone network, layer selection criteria, similarity metric, or the exact search procedure over embedding similarities. These choices are load-bearing for the generalization claim, as the abstract supplies no details on how they were determined or validated against leakage from the test distributions.
Authors: We agree that the abstract was overly concise and that Section 3 would benefit from expanded implementation details. In the revised manuscript we have updated the abstract with a high-level description of the approach and added explicit specifications in Section 3: the perturbation is additive Gaussian noise, the backbone is a standard pretrained CNN, layers are chosen according to sensitivity analysis on a validation split, similarity is measured by cosine distance, and the search is a grid search over thresholds. These choices were validated on a held-out validation set disjoint from the reported test benchmarks to avoid leakage. A pseudocode algorithm and additional explanatory text have been inserted. revision: yes
-
Referee: [§4] §4 (Experiments): No information is given on data splits, cross-validation, or statistical testing for the AUROC values. Without these, the reported gains (39.61% and 5.14% on Forensics Small) cannot be verified as robust rather than artifacts of particular splits or search tuning on the same generator distributions present in the benchmarks.
Authors: The experiments follow the official train/test splits released with the GenImage and Forensics Small benchmarks. Because the method is training-free, cross-validation is not performed; instead, the similarity threshold is selected via grid search on a small validation subset drawn from the training portion of each benchmark. We have now added this information to Section 4, report mean AUROC and standard deviation over five independent runs with different perturbation seeds, and include a brief note on statistical significance of the observed gains. revision: yes
-
Referee: [§4 and Discussion] §4 and Discussion: The central assumption that embedding sensitivity patterns under perturbation are invariant to generator architecture and training data is stated but not tested via held-out generators or ablation on layer/perturbation choices. This leaves open the risk that gains reflect benchmark-specific sensitivity rather than a fundamental property of AI-generated images.
Authors: We partially agree that further ablations would strengthen the invariance claim. GenImage already contains images from several distinct generators, providing initial support for cross-generator behavior. In the revised version we have added an ablation subsection in §4 that varies layer choice and perturbation magnitude, showing stable performance. We have also expanded the Discussion to clarify that, for truly novel generators, the training-free search can be re-run on a modest number of labeled examples without model retraining. We maintain that the core sensitivity property is not benchmark-specific, but acknowledge that exhaustive held-out-generator experiments would be a valuable future extension. revision: partial
Circularity Check
No significant circularity in empirical search-based detector
full rationale
The paper proposes a search-based method that computes embedding similarities under perturbations in intermediate layers of a backbone network to separate real from AI-generated images, then evaluates this heuristic empirically on the GenImage and Forensics Small benchmarks. No derivation chain, equations, or first-principles argument is offered that reduces the detector output to its own fitted inputs or self-referential definitions; the approach is presented as a data-driven search whose performance is measured against external baselines. Any self-citations (if present) are not load-bearing for the core claim, and the reported AUROC gains are benchmark results rather than predictions forced by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2016
work page Pith review arXiv 2016
-
[2]
The vulnerability of learning to adversarial perturbation increases with intrinsic dimensionality
Laurent Amsaleg, James Bailey, Dominique Barbe, Sarah Erfani, Michael E Houle, Vinh Nguyen, and Miloš Radovanovi´c. The vulnerability of learning to adversarial perturbation increases with intrinsic dimensionality. In 2017 ieee workshop on information forensics and security (wifs), pages 1–6. IEEE, 2017. 9 PRIME AI paper
2017
-
[3]
Intrinsic dimension of data representa- tions in deep neural networks.Advances in Neural Information Processing Systems, 32, 2019
Alessio Ansuini, Alessandro Laio, Jakob H Macke, and Davide Zoccolan. Intrinsic dimension of data representa- tions in deep neural networks.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[4]
Sparseness and expansion in sensory representations.Neuron, 83(5):1213– 1226, 2014
Baktash Babadi and Haim Sompolinsky. Sparseness and expansion in sensory representations.Neuron, 83(5):1213– 1226, 2014
2014
-
[5]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22563–22575, 2023
2023
-
[6]
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis.arXiv preprint arXiv:1809.11096, 2018
work page internal anchor Pith review arXiv 2018
-
[7]
A closer look at fourier spectrum discrepancies for cnn-generated images detection
Keshigeyan Chandrasegaran, Ngoc-Trung Tran, and Ngai-Man Cheung. A closer look at fourier spectrum discrepancies for cnn-generated images detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7200–7209, 2021
2021
-
[8]
Intriguing properties of synthetic images: from generative adversarial networks to diffusion models
Riccardo Corvi, Davide Cozzolino, Giovanni Poggi, Koki Nagano, and Luisa Verdoliva. Intriguing properties of synthetic images: from generative adversarial networks to diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 973–982, 2023
2023
-
[9]
On the detection of synthetic images generated by diffusion models
Riccardo Corvi, Davide Cozzolino, Giada Zingarini, Giovanni Poggi, Koki Nagano, and Luisa Verdoliva. On the detection of synthetic images generated by diffusion models. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
2023
-
[10]
Towards universal gan image detection
Davide Cozzolino, Diego Gragnaniello, Giovanni Poggi, and Luisa Verdoliva. Towards universal gan image detection. In2021 International conference on visual communications and image processing (VCIP), pages 1–5. IEEE, 2021
2021
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[12]
Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[13]
Head2toe: Utilizing intermediate representations for better transfer learning
Utku Evci, Vincent Dumoulin, Hugo Larochelle, and Michael C Mozer. Head2toe: Utilizing intermediate representations for better transfer learning. InInternational Conference on Machine Learning, pages 6009–6033. PMLR, 2022
2022
-
[14]
Estimating the intrinsic dimension of datasets by a minimal neighborhood information.Scientific reports, 7(1):12140, 2017
Elena Facco, Maria d’Errico, Alex Rodriguez, and Alessandro Laio. Estimating the intrinsic dimension of datasets by a minimal neighborhood information.Scientific reports, 7(1):12140, 2017
2017
-
[15]
Leveraging frequency analysis for deep fake image recognition
Joel Frank, Thorsten Eisenhofer, Lea Schönherr, Asja Fischer, Dorothea Kolossa, and Thorsten Holz. Leveraging frequency analysis for deep fake image recognition. InInternational conference on machine learning, pages 3247–3258. PMLR, 2020
2020
-
[16]
Generative adversarial networks.Communications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Communications of the ACM, 63(11):139–144, 2020
2020
-
[17]
Diego Gragnaniello, Davide Cozzolino, Francesco Marra, Giovanni Poggi, and Luisa Verdoliva. Are gan generated images easy to detect? a critical analysis of the state-of-the-art.arXiv preprint arXiv:2104.02617, 2021
-
[18]
Vector quantized diffusion model for text-to-image synthesis
Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10696–10706, 2022
2022
-
[19]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[20]
Zhiyuan He, Pin-Yu Chen, and Tsung-Yi Ho. Rigid: A training-free and model-agnostic framework for robust ai-generated image detection.arXiv preprint arXiv:2405.20112, 2024
-
[21]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations.arXiv preprint arXiv:1903.12261, 2019
work page internal anchor Pith review arXiv 1903
-
[22]
Reducing the dimensionality of data with neural networks
Geoffrey E Hinton and Ruslan R Salakhutdinov. Reducing the dimensionality of data with neural networks. science, 313(5786):504–507, 2006
2006
-
[23]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 10 PRIME AI paper
2020
-
[24]
Enhancing adversarial example transferability with an intermediate level attack
Qian Huang, Isay Katsman, Horace He, Zeqi Gu, Serge Belongie, and Ser-Nam Lim. Enhancing adversarial example transferability with an intermediate level attack. InProceedings of the IEEE/CVF international conference on computer vision, pages 4733–4742, 2019
2019
-
[25]
Yiding Jiang, Dilip Krishnan, Hossein Mobahi, and Samy Bengio. Predicting the generalization gap in deep networks with margin distributions.arXiv preprint arXiv:1810.00113, 2018
-
[26]
Any-resolution ai-generated image detection by spectral learning
Dimitrios Karageorgiou, Symeon Papadopoulos, Ioannis Kompatsiaris, and Efstratios Gavves. Any-resolution ai-generated image detection by spectral learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18706–18717, 2025
2025
-
[27]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
2019
-
[28]
Yoonho Lee, Annie S Chen, Fahim Tajwar, Ananya Kumar, Huaxiu Yao, Percy Liang, and Chelsea Finn. Surgical fine-tuning improves adaptation to distribution shifts.arXiv preprint arXiv:2210.11466, 2022
-
[29]
Coupled generative adversarial networks.Advances in neural information processing systems, 29, 2016
Ming-Yu Liu and Oncel Tuzel. Coupled generative adversarial networks.Advances in neural information processing systems, 29, 2016
2016
-
[30]
arXiv preprint arXiv:1801.02613 , year=
Xingjun Ma, Bo Li, Yisen Wang, Sarah M Erfani, Sudanthi Wijewickrema, Grant Schoenebeck, Dawn Song, Michael E Houle, and James Bailey. Characterizing adversarial subspaces using local intrinsic dimensionality. arXiv preprint arXiv:1801.02613, 2018
-
[31]
Least squares generative adversarial networks
Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, Zhen Wang, and Stephen Paul Smolley. Least squares generative adversarial networks. InProceedings of the IEEE international conference on computer vision, pages 2794–2802, 2017
2017
-
[32]
Adversarial variational bayes: Unifying variational autoencoders and generative adversarial networks
Lars Mescheder, Sebastian Nowozin, and Andreas Geiger. Adversarial variational bayes: Unifying variational autoencoders and generative adversarial networks. InInternational conference on machine learning, pages 2391–2400. PMLR, 2017
2017
-
[33]
Unrolled generative adversarial networks
Luke Metz, Ben Poole, David Pfau, and Jascha Sohl-Dickstein. Unrolled generative adversarial networks.arXiv preprint arXiv:1611.02163, 2016
-
[34]
Midjourney
Midjourney. Midjourney. https://www.midjourney.com/home, 2022. Accessed:2022
2022
-
[35]
A generative model for zero shot learning using conditional variational autoencoders
Ashish Mishra, Shiva Krishna Reddy, Anurag Mittal, and Hema A Murthy. A generative model for zero shot learning using conditional variational autoencoders. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 2188–2196, 2018
2018
-
[36]
Sample complexity of testing the manifold hypothesis.Advances in neural information processing systems, 23, 2010
Hariharan Narayanan and Sanjoy Mitter. Sample complexity of testing the manifold hypothesis.Advances in neural information processing systems, 23, 2010
2010
-
[37]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021
work page internal anchor Pith review arXiv 2021
-
[38]
Towards universal fake image detectors that generalize across generative models
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. Towards universal fake image detectors that generalize across generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24480–24489, 2023
2023
-
[39]
Sparse coding with an overcomplete basis set: A strategy employed by v1? Vision research, 37(23):3311–3325, 1997
Bruno A Olshausen and David J Field. Sparse coding with an overcomplete basis set: A strategy employed by v1? Vision research, 37(23):3311–3325, 1997
1997
-
[40]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review arXiv 2023
-
[41]
Community forensics: Using thousands of generators to train fake image detectors
Jeongsoo Park and Andrew Owens. Community forensics: Using thousands of generators to train fake image detectors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8245–8257, 2025
2025
-
[42]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[43]
Variational autoencoder
Lucas Pinheiro Cinelli, Matheus Araújo Marins, Eduardo Antúnio Barros da Silva, and Sérgio Lima Netto. Variational autoencoder. InVariational methods for machine learning with applications to deep networks, pages 111–149. Springer, 2021
2021
-
[44]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 11 PRIME AI paper
work page internal anchor Pith review arXiv 2023
-
[45]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[46]
Stefano Recanatesi, Matthew Farrell, Madhu Advani, Timothy Moore, Guillaume Lajoie, and Eric Shea-Brown. Dimensionality compression and expansion in deep neural networks.arXiv preprint arXiv:1906.00443, 2019
-
[47]
Aeroblade: Training-free detection of latent diffusion images using autoencoder reconstruction error
Jonas Ricker, Denis Lukovnikov, and Asja Fischer. Aeroblade: Training-free detection of latent diffusion images using autoencoder reconstruction error. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9130–9140, 2024
2024
-
[48]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[49]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
2022
-
[50]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review arXiv 2010
-
[51]
Rethinking the up- sampling operations in cnn-based generative network for generalizable deepfake detection
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, Ping Liu, and Yunchao Wei. Rethinking the up- sampling operations in cnn-based generative network for generalizable deepfake detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28130–28139, 2024
2024
-
[52]
The information bottleneck theory of deep neural networks
Naftali Tishby. The information bottleneck theory of deep neural networks. InAPS March Meeting Abstracts, volume 2018, pages K58–004, 2018
2018
-
[53]
Chung-Ting Tsai, Ching-Yun Ko, I Chung, Yu-Chiang Frank Wang, Pin-Yu Chen, et al. Understanding and improv- ing training-free ai-generated image detections with vision foundation models.arXiv preprint arXiv:2411.19117, 2024
-
[54]
Cnn-generated images are surprisingly easy to spot
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A Efros. Cnn-generated images are surprisingly easy to spot... for now. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8695–8704, 2020
2020
-
[55]
Wukong. Wukong. https://xihe.mindspore.cn/modelzoo/wukong, 2022. Accessed:2022
2022
-
[56]
A sanity check for ai-generated image detection.arXiv preprint arXiv:2406.19435, 2024
Shilin Yan, Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, and Weidi Xie. A sanity check for ai-generated image detection.arXiv preprint arXiv:2406.19435, 2024
-
[57]
Time-series generative adversarial networks.Advances in neural information processing systems, 32, 2019
Jinsung Yoon, Daniel Jarrett, and Mihaela Van der Schaar. Time-series generative adversarial networks.Advances in neural information processing systems, 32, 2019
2019
-
[58]
Genimage: A million-scale benchmark for detecting ai-generated image.Advances in Neural Information Processing Systems, 36:77771–77782, 2023
Mingjian Zhu, Hanting Chen, Qiangyu Yan, Xudong Huang, Guanyu Lin, Wei Li, Zhijun Tu, Hailin Hu, Jie Hu, and Yunhe Wang. Genimage: A million-scale benchmark for detecting ai-generated image.Advances in Neural Information Processing Systems, 36:77771–77782, 2023. 12 PRIME AI paper A Implementation Details We use pretrained CLIP to extract features. Besides...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.