Recognition: 3 theorem links
· Lean TheoremMitigating Label Shift in Tabular In-Context Learning via Test-Time Posterior Adjustment
Pith reviewed 2026-05-08 18:26 UTC · model grok-4.3
The pith
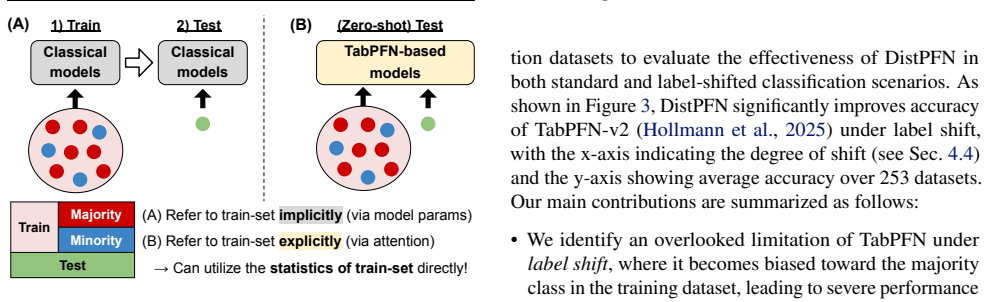
DistPFN rescales TabPFN output probabilities at test time to counteract label shift by downweighting the training class prior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TabPFN overfits to the majority class in the training context under label shift. DistPFN corrects this by rescaling the predicted class probabilities to downweight the training prior and emphasize the model's own posterior, with an optional temperature-scaled variant that adapts the adjustment strength to the observed discrepancy between prior and posterior. The adjustment occurs purely at test time with no architectural modifications or additional training.
What carries the argument
DistPFN posterior adjustment, which rescales predicted probabilities by downweighting the training prior (and optionally applies adaptive temperature scaling based on prior-posterior discrepancy).
Load-bearing premise
Rescaling the output probabilities by downweighting the training prior will recover a better posterior under label shift without introducing new errors or needing the true test prior.
What would settle it
Measure accuracy on a set of label-shifted datasets using the adjusted probabilities versus the unadjusted TabPFN outputs and versus an oracle model that has access to the true test label distribution.
Figures






read the original abstract
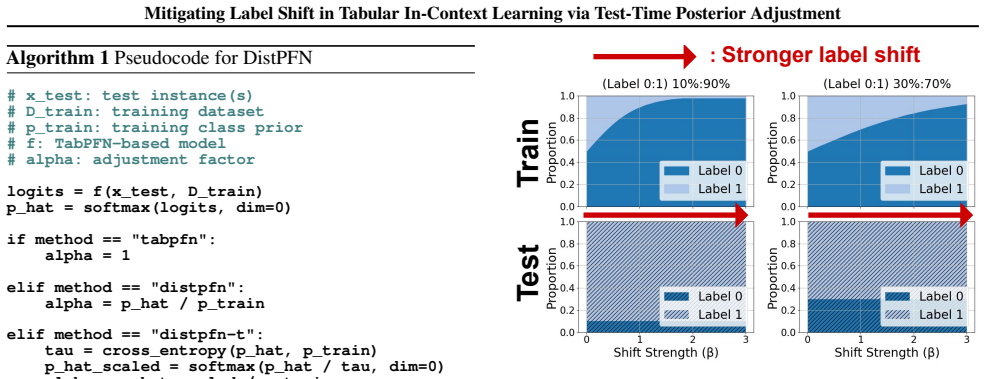
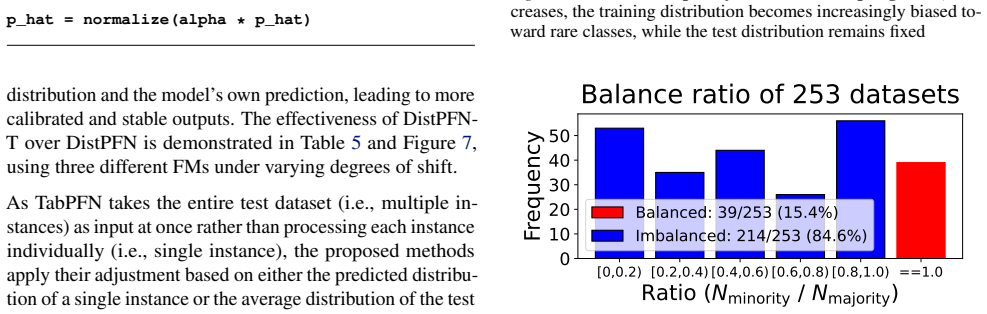
TabPFN has recently gained attention as a foundation model for tabular datasets, achieving strong performance by leveraging in-context learning on synthetic data. However, we find that TabPFN is vulnerable to label shift, often overfitting to the majority class in the training dataset. To address this limitation, we propose DistPFN, the first test-time posterior adjustment method designed for tabular foundation models. DistPFN rescales predicted class probabilities by downweighting the influence of the training prior (i.e., the class distribution of the context) and emphasizing the contribution of the model's predicted posterior, without architectural modification or additional training. We further introduce DistPFN-T, which incorporates temperature scaling to adaptively control the adjustment strength based on the discrepancy between prior and posterior. We evaluate our methods on over 250 OpenML datasets, demonstrating substantial improvements for various TabPFN-based models in classification tasks under label shift, while maintaining strong performance in standard settings without label shift. Code is available at this repository: https://github.com/seunghan96/DistPFN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that TabPFN and similar tabular in-context learning models overfit to the majority class under label shift. It introduces DistPFN, a test-time posterior adjustment that rescales predicted class probabilities by downweighting the class distribution of the in-context examples (training prior) while emphasizing the model's posterior, plus the variant DistPFN-T that adds adaptive temperature scaling based on prior-posterior discrepancy. The methods require no architectural changes or retraining and are reported to yield substantial gains on classification tasks across more than 250 OpenML datasets under label shift while preserving performance in the absence of shift.
Significance. If the adjustment reliably approximates label-shift correction, the work would provide a lightweight, training-free robustness tool for tabular foundation models. The scale of the evaluation (>250 datasets) and public code release are positive features that would support adoption if the central mechanism is shown to be sound.
major comments (2)
- [§3.1] §3.1 (DistPFN adjustment formula): The rescaling is presented as downweighting the training prior without an explicit derivation from the label-shift Bayes rule p(y|x) ∝ p(x|y) * p_test(y)/p_train(y). It is not shown whether the particular form recovers (or approximates) the correct test posterior when the true test prior is unknown, or whether it remains a heuristic that can distort probabilities even without shift.
- [§4.2] §4.2 (DistPFN-T temperature adaptation): The adaptive temperature is described as depending on the discrepancy between prior and posterior, but the manuscript does not clarify whether this involves any post-hoc fitting on evaluation data or remains strictly test-time; this affects whether the method stays parameter-free as claimed.
minor comments (2)
- [§4.1] §4.1: The precise procedure used to induce label shift on the OpenML datasets (e.g., how test class proportions are chosen and whether they are known at adjustment time) should be stated explicitly for reproducibility.
- [Table 1] Table 1 and Figure 3: Error bars and statistical significance tests for the reported accuracy/F1 improvements are not described; adding them would strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We appreciate the opportunity to address the concerns regarding the theoretical grounding of DistPFN and the test-time nature of DistPFN-T. We provide point-by-point responses below and have revised the manuscript accordingly to improve clarity.
read point-by-point responses
-
Referee: [§3.1] §3.1 (DistPFN adjustment formula): The rescaling is presented as downweighting the training prior without an explicit derivation from the label-shift Bayes rule p(y|x) ∝ p(x|y) * p_test(y)/p_train(y). It is not shown whether the particular form recovers (or approximates) the correct test posterior when the true test prior is unknown, or whether it remains a heuristic that can distort probabilities even without shift.
Authors: We agree that an explicit derivation strengthens the presentation. DistPFN is motivated by the label-shift correction: the model provides an estimate of p(x|y) p_train(y), so rescaling the output probabilities by the inverse of the context class distribution (p_train(y)) approximates multiplication by p_test(y)/p_train(y) when p_test(y) is unknown. The resulting normalized probabilities therefore emphasize the model's learned posterior while reducing the training prior's influence. We acknowledge this is an approximation rather than an exact recovery of the test posterior. In the revised manuscript we have added a short derivation in §3.1 that starts from the label-shift Bayes rule, states the approximation explicitly, and discusses conditions under which the adjustment remains beneficial. We also include a brief analysis showing that, when there is no shift, the adjustment does not materially distort probabilities (consistent with the empirical results that performance is preserved on unshifted data). revision: yes
-
Referee: [§4.2] §4.2 (DistPFN-T temperature adaptation): The adaptive temperature is described as depending on the discrepancy between prior and posterior, but the manuscript does not clarify whether this involves any post-hoc fitting on evaluation data or remains strictly test-time; this affects whether the method stays parameter-free as claimed.
Authors: We apologize for the ambiguity. The temperature in DistPFN-T is computed entirely at test time for each query point: the discrepancy is measured between the empirical class distribution of the in-context examples and the model's own posterior probabilities on that point; the temperature is then set proportionally to this discrepancy. No parameters are optimized or fitted on any evaluation, validation, or held-out data. The procedure uses only quantities already available during inference. We have revised §4.2 to state this explicitly, provide the exact temperature formula, and reaffirm that the method remains strictly test-time and parameter-free. revision: yes
Circularity Check
No circularity: DistPFN is an explicitly defined test-time heuristic with external evaluation
full rationale
The paper introduces DistPFN as a proposed rescaling procedure that operates directly on the model's output posterior and the observed class distribution in the in-context examples. No derivation chain is claimed that reduces a 'prediction' or 'first-principles result' back to the same fitted quantities by construction. Evaluation occurs on held-out OpenML datasets under controlled label-shift conditions, and the central performance claims rest on these external benchmarks rather than on any self-referential fit or self-citation load-bearing step. The method is therefore self-contained as an empirical adjustment technique.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption TabPFN overfits to the class distribution present in the in-context examples
- ad hoc to paper Downweighting the training prior while preserving the model's posterior improves calibration under label shift
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation (J-cost uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DistPFN rescales predicted class probabilities by downweighting the influence of the training prior ... and emphasizing the contribution of the model's predicted posterior
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation (calibration of cost via derivatives)alpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
τ = CE(p̂_TabPFN(y), p_train(y)) ... temperature-scaled softmax
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Azizzadenesheli, K., Liu, A., Yang, F., and Anandkumar, A. Regularized learning for domain adaptation under label shifts.arXiv preprint arXiv:1903.09734,
-
[2]
arXiv preprint arXiv:1708.03731 , year=
Bischl, B., Casalicchio, G., Feurer, M., Gijsbers, P., Hutter, F., Lang, M., Mantovani, R. G., van Rijn, J. N., and Vanschoren, J. Openml benchmarking suites.arXiv preprint arXiv:1708.03731,
-
[3]
Tabm: Advancing tabular deep learning with parameter-efficient ensembling.ICLR, 2024a
10 Mitigating Label Shift in Tabular In-Context Learning via Test-Time Posterior Adjustment Gorishniy, Y ., Kotelnikov, A., and Babenko, A. Tabm: Advancing tabular deep learning with parameter-efficient ensembling.ICLR, 2024a. Gorishniy, Y ., Rubachev, I., Kartashev, N., Shlenskii, D., Kotelnikov, A., and Babenko, A. Tabr: Tabular deep learning meets near...
2023
-
[4]
TabTransformer: Tabular Data Modeling Using Contextual Embeddings
Huang, X., Khetan, A., Cvitkovic, M., and Karnin, Z. Tab- transformer: Tabular data modeling using contextual em- beddings.arXiv preprint arXiv:2012.06678,
work page internal anchor Pith review arXiv 2012
-
[5]
Kim, C., Kim, T., Woo, S., Yang, J. Y ., and Yang, E. Adapt- able: Test-time adaptation for tabular data via shift-aware uncertainty calibrator and label distribution handler.arXiv preprint arXiv:2407.10784,
-
[6]
Long-tail learning via logit adjustment.arXiv preprint arXiv:2007.07314, 2020
Menon, A. K., Jayasumana, S., Rawat, A. S., Jain, H., Veit, A., and Kumar, S. Long-tail learning via logit adjustment. arXiv preprint arXiv:2007.07314,
-
[7]
Somepalli, G., Goldblum, M., Schwarzschild, A., Bruss, C. B., and Goldstein, T. Saint: Improved neural networks for tabular data via row attention and contrastive pre- training.arXiv preprint arXiv:2106.01342,
- [8]
-
[9]
Dataset.We evaluate on 250+ tabular datasets from OpenML (Bischl et al., 2017)
For inference, we load the pretrained weights from TabPFN-v23 available on Hugging Face. Dataset.We evaluate on 250+ tabular datasets from OpenML (Bischl et al., 2017). The dataset list is retrieved from the benchmark configuration provided in this repository4, which is built on top of the official TabPFN evaluation setup. Dataset statistics are summarize...
2017
-
[10]
• DL (non-foundation) models (5):FT-Transformer (Gorishniy et al., 2021), TabM (Gorishniy et al., 2024a), Tabu- laRNN (Thielmann & Samiee, 2024), MambaTab (Ahamed & Cheng, 2024), RealMLP (Holzm¨uller et al.,
2021
-
[11]
• DL (foundation) models based on ICL (3):TabPFN-v2 (Hollmann et al., 2025), LoCalPFN (Thomas et al., 2024), TabICL (Qu et al.,
2025
-
[12]
Details of each method are provided below. C.1. Machine Learning (ML) Models • Logistic Regression (LR)(Cox, 1958): A simple linear model commonly used for binary and multiclass classification tasks in tabular data. • Support Vector Machine (SVM)(Cortes & Vapnik, 1995): A kernel-based classifier that aims to find the optimal decision boundary with maximum...
1958
-
[13]
Bayesian view that replaces the mismatched prior with a self-consistent estimate from model predictions (Section E.2). E.1. Relation to Label Shift Correction The label shift setting assumes that the conditional distributionp(x|y)remains invariant while the marginal priors differ: ptrain(y)̸=p test(y), p(x|y)is fixed. Under this assumption, the Bayes-opti...
2002
-
[14]
We conduct random search over these spaces and tune the models on validation datasets that are kept separate from the final test splits
The search spaces are manually designed to cover commonly used ranges for each model class, including both optimization-related parameters and regularization or structural options. We conduct random search over these spaces and tune the models on validation datasets that are kept separate from the final test splits. The details of the hyperparameter searc...
2017
-
[15]
Table L.1 presents the results, showing that our method is effective without requiring estimation of the test prior
and Black-box Estimation (BBE) (Lipton et al., 2018). Table L.1 presents the results, showing that our method is effective without requiring estimation of the test prior. Figure L.1.Comparison with other label shift methods. Methods w/o shift Shift strength (β) 0.0 0.1 0.5 1.0 2.0 5.0 Avg. LoCalPFN 0.816 0.794 0.793 0.788 0.778 0.753 0.719 0.771 + EME 0.8...
2018
-
[16]
the average prediction acrossmultiple instances. As shown in Table M.1, both choices consistently improve TabPFN-v2 (Hollmann et al., 2025), averaged across sixβs forw/ shift, demonstrating robustness to the choice of distribution source. Table M.1.Predicted distributions: Single vs. Multiple.The proposed methods consistently improves TabPFN-v2 regardless...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.