Recognition: 2 theorem links
· Lean TheoremConditional Flow-VAE for Safety-Critical Traffic Scenario Generation
Pith reviewed 2026-05-08 18:18 UTC · model grok-4.3
The pith
Conditional latent flow matching turns nominal traffic scenes into realistic safety-critical scenarios for autonomous vehicle testing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our conditional latent flow matching approach within a VAE framework transforms nominal scenes into safety-critical rollouts by matching distributions in the latent space. Training on both simulated and real-world data allows the model to generate diverse, data-driven scenarios efficiently. Experimental results demonstrate that this method produces more consistent and realistic novel safety-critical scenarios than prior approaches.
What carries the argument
Conditional latent flow matching inside a VAE, which maps nominal scenes to safety-critical ones via distribution matching in latent space.
If this is right
- Provides a scalable way to create safety-critical test cases without manual design.
- Generates more realistic behaviors than adversarial optimization techniques.
- Supports training and benchmarking of AV systems using both simulated and real data.
- Enables efficient production of diverse safety-critical rollouts at scale.
Where Pith is reading between the lines
- The method could be combined with online reinforcement learning to adaptively generate scenarios that target specific weaknesses in an AV policy.
- Blending simulation and real data in this way might narrow the sim-to-real gap for scenario-based validation more effectively than purely synthetic approaches.
- If the latent matching preserves physical plausibility, the same architecture could extend to generating rare events in other sequential domains such as robotics manipulation or air traffic.
Load-bearing premise
That distribution matching in latent space reliably produces scenarios that are genuinely safety-critical and realistic enough for AV training to transfer without introducing artifacts or harmful distribution shifts.
What would settle it
An experiment showing that AV planners trained on the generated scenarios achieve no improvement or worse performance on held-out real-world safety-critical events compared to training on random or manually crafted scenarios.
Figures



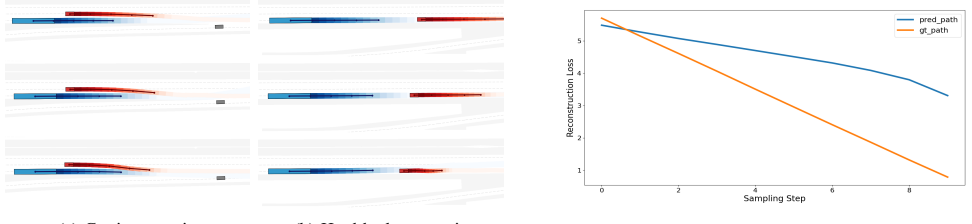
read the original abstract
Safety-critical scenarios are essential for the development of autonomous vehicles (AVs) but are rare in real-world driving data. While simulation offers a way to generate such scenarios, manually designed test cases lack scalability, and adversarial optimization often produces unrealistic behaviors. In this work, we introduce a conditional latent flow matching approach for scalable and realistic safety-critical scenario generation. Our method uses distribution matching to transform nominal scenes into safety-critical rollouts. Furthermore, we demonstrate that incorporating both simulation and real-world data enables our framework to efficiently generate diverse, data-driven scenarios. Experimental results highlight that our approach is able to more consistently and realistically generate novel safety-critical scenarios, making it a valuable tool for training and benchmarking AV systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Conditional Flow-VAE, a conditional latent flow matching model for generating safety-critical traffic scenarios. It transforms nominal scenes into safety-critical rollouts via distribution matching in latent space and incorporates both simulation and real-world data to produce diverse scenarios. The central claim is that the approach generates novel safety-critical scenarios more consistently and realistically than prior methods, serving as a tool for AV training and benchmarking.
Significance. If the empirical grounding is strengthened, the work could provide a scalable data-driven alternative to manual scenario design or adversarial optimization for AV safety testing. The joint use of sim and real data is a constructive element for addressing distribution shifts.
major comments (2)
- Results section: The claim that the method 'more consistently and realistically generate[s] novel safety-critical scenarios' is not supported by any reported quantitative metrics (e.g., collision rates, minimum TTC distributions, kinematic violation counts), baselines, error bars, or statistical tests. No details are given on how realism or criticality were measured, leaving the central empirical claim without visible grounding.
- Method section (latent flow matching description): The paper does not verify that distribution matching in latent space produces trajectories satisfying safety-critical criteria (elevated collision risk, low TTC) beyond the training distribution or that they avoid non-physical artifacts. Post-generation analysis confirming these properties is required for the claim to hold.
minor comments (1)
- Abstract: The phrasing 'more consistently and realistically' should be replaced with concrete evaluation criteria once metrics are added.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the empirical requirements for our claims. We address each major comment below and commit to revisions that strengthen the manuscript's grounding without altering its core contributions.
read point-by-point responses
-
Referee: Results section: The claim that the method 'more consistently and realistically generate[s] novel safety-critical scenarios' is not supported by any reported quantitative metrics (e.g., collision rates, minimum TTC distributions, kinematic violation counts), baselines, error bars, or statistical tests. No details are given on how realism or criticality were measured, leaving the central empirical claim without visible grounding.
Authors: We acknowledge that the current Results section relies primarily on qualitative visualizations and example rollouts rather than the quantitative metrics suggested. This leaves the claims of consistency and realism insufficiently supported. In the revised manuscript we will expand the Results section to report collision rates, minimum TTC distributions, kinematic violation counts, comparisons against baselines (including standard VAEs and adversarial generation methods), error bars across multiple random seeds, and statistical significance tests. We will also add explicit descriptions of how realism is quantified (via kinematic feasibility checks) and how criticality is measured (via collision proximity and TTC thresholds). These additions will draw on our existing simulation and real-data experiments. revision: yes
-
Referee: Method section (latent flow matching description): The paper does not verify that distribution matching in latent space produces trajectories satisfying safety-critical criteria (elevated collision risk, low TTC) beyond the training distribution or that they avoid non-physical artifacts. Post-generation analysis confirming these properties is required for the claim to hold.
Authors: We agree that explicit post-generation verification is required to substantiate that latent-space distribution matching yields safety-critical yet physically plausible trajectories. Although the conditional flow-matching objective is intended to achieve this, the manuscript does not present the corresponding analysis. In the revision we will insert a dedicated verification subsection that reports post-generation statistics on collision frequency and TTC reduction relative to nominal scenes, evaluates performance on held-out scenarios to demonstrate generalization beyond the training distribution, and quantifies the absence of non-physical artifacts through bounds on acceleration, jerk, and velocity. This analysis will be performed on both simulated and real-world conditioned inputs. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The abstract and available context describe a conditional latent flow matching approach at a high level without presenting any equations, derivations, fitted parameters renamed as predictions, or self-citations that bear the central claim. No load-bearing step reduces by construction to its inputs, as there are no mathematical details or uniqueness theorems invoked. The method relies on distribution matching to transform nominal scenes, but this is presented as an empirical modeling choice rather than a tautological redefinition. Experimental claims are framed as results rather than first-principles outputs forced by the inputs. This is the expected non-finding for papers lacking explicit derivation chains.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.GeneralizedDAlembertwashburn_uniqueness_aczel (no relation: paper uses learned NN vector field, not the J-cost uniqueness chain) unclearA rectified flow is an ODE on time t∈[0,1] dZ_t = v_θ(Z_t,t)dt … optimizing ∫₀¹ E[‖(X₁−X₀)−v(X_t,t)‖²]dt
-
Foundation.AlphaCoordinateFixationalpha_pin_under_high_calibration (RS pins parameters; this paper introduces tunable mixing/conditioning hyperparameters — different sense of 'distribution matching') unclearOur method uses distribution matching to transform nominal scenes into safety-critical rollouts … blend real and simulated scenarios using a hyperparameter α_real
Reference graph
Works this paper leans on
-
[1]
Collision avoidance testing of the waymo automated driving system,
K. D. Kusano, K. Beatty, S. Schnelle, F. Favaro, C. Crary, and T. Victor, “Collision avoidance testing of the waymo automated driving system,” 2022. [Online]. Available: https://arxiv.org/abs/2212.08148
-
[2]
Waymo simulated driving behavior in reconstructed fatal crashes within an autonomous vehicle operating domain
J. M. Scanlon, K. D. Kusano, T. Daniel, C. J. Alderson, A. Ogle, and T. Victor, “Waymo simulated driving behavior in reconstructed fatal crashes within an autonomous vehicle operating domain.”Accident; analysis and prevention, vol. 163, p. 106454, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:232285642
2021
-
[3]
Trafficgen: Learning to generate diverse and realistic traffic scenarios,
L. Feng, Q. Li, Z. Peng, S. Tan, and B. Zhou, “Trafficgen: Learning to generate diverse and realistic traffic scenarios,” 2023. [Online]. Available: https://arxiv.org/abs/2210.06609
-
[4]
Language conditioned traffic generation,
S. Tan, B. Ivanovic, X. Weng, M. Pavone, and P. Kraehenbuehl, “Language conditioned traffic generation,” 2023. [Online]. Available: https://arxiv.org/abs/2307.07947
-
[5]
M. Treiber, A. Hennecke, and D. Helbing, “Congested traffic states in empirical observations and microscopic simulations,”Phys. Rev. E, vol. 62, pp. 1805–1824, Aug 2000. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevE.62.1805
-
[6]
Carla: An open urban driving simulator
A. Dosovitskiy, G. Ros, F. Codevilla, A. M. L ´opez, and V . Koltun, “CARLA: an open urban driving simulator,” CoRR, vol. abs/1711.03938, 2017. [Online]. Available: http://arxiv.org/abs/1711.03938
-
[7]
Womd-lidar: Raw sensor dataset benchmark for motion forecasting,
K. Chen, R. Ge, H. Qiu, R. Ai-Rfou, C. R. Qi, X. Zhou, Z. Yang, S. Et- tinger, P. Sun, Z. Leng, M. Mustafa, I. Bogun, W. Wang, M. Tan, and D. Anguelov, “Womd-lidar: Raw sensor dataset benchmark for motion forecasting,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), May 2024
2024
-
[8]
A survey on safety-critical driving scenario generation—a methodological per- spective,
W. Ding, C. Xu, M. Arief, H. Lin, B. Li, and D. Zhao, “A survey on safety-critical driving scenario generation—a methodological per- spective,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 7, pp. 6971–6988, 2023
2023
-
[9]
SMART : Scalable multi-agent real-time motion generation via next-token prediction
W. Wu, X. Feng, Z. Gao, and Y . Kan, “Smart: Scalable multi- agent real-time motion generation via next-token prediction,” 2024. [Online]. Available: https://arxiv.org/abs/2405.15677
-
[10]
Guided conditional diffusion for controllable traffic simulation,
Z. Zhong, D. Rempe, D. Xu, Y . Chen, S. Veer, T. Che, B. Ray, and M. Pavone, “Guided conditional diffusion for controllable traffic simulation,” 2022. [Online]. Available: https://arxiv.org/abs/2210.17366
-
[11]
Bits: Bi- level imitation for traffic simulation,
D. Xu, Y . Chen, B. Ivanovic, and M. Pavone, “Bits: Bi- level imitation for traffic simulation,” 2022. [Online]. Available: https://arxiv.org/abs/2208.12403
-
[12]
Trafficsim: Learning to simulate realistic multi-agent behaviors,
S. Suo, S. Regalado, S. Casas, and R. Urtasun, “Trafficsim: Learning to simulate realistic multi-agent behaviors,” 2021. [Online]. Available: https://arxiv.org/abs/2101.06557
-
[13]
Learning realistic traffic agents in closed-loop,
C. Zhang, J. Tu, L. Zhang, K. Wong, S. Suo, and R. Urtasun, “Learning realistic traffic agents in closed-loop,”arXiv preprint arXiv:2311.01394, 2023
-
[14]
Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes,
J.-T. Zhai, Z. Feng, J. Du, Y . Mao, J.-J. Liu, Z. Tan, Y . Zhang, X. Ye, and J. Wang, “Rethinking the open-loop evaluation of end- to-end autonomous driving in nuscenes,” 2023. [Online]. Available: https://arxiv.org/abs/2305.10430
-
[15]
Generat- ing useful accident-prone driving scenarios via a learned traffic prior,
D. Rempe, J. Philion, L. J. Guibas, S. Fidler, and O. Litany, “Generat- ing useful accident-prone driving scenarios via a learned traffic prior,” inConference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[16]
Safety-critical scenario generation via reinforcement learning based editing,
H. Liu, L. Zhang, S. K. S. Hari, and J. Zhao, “Safety-critical scenario generation via reinforcement learning based editing,” 2024. [Online]. Available: https://arxiv.org/abs/2306.14131
-
[17]
Learning to drive via asymmetric self-play,
C. Zhang, S. Biswas, K. Wong, K. Fallah, L. Zhang, D. Chen, S. Casas, and R. Urtasun, “Learning to drive via asymmetric self-play,” 2024. [Online]. Available: https://arxiv.org/abs/2409.18218
-
[18]
Advsim: Generating safety-critical scenarios for self-driving vehicles,
J. Wang, A. Pun, J. Tu, S. Manivasagam, A. Sadat, S. Casas, M. Ren, and R. Urtasun, “Advsim: Generating safety-critical scenarios for self-driving vehicles,” 2023. [Online]. Available: https://arxiv.org/abs/2101.06549
-
[19]
Auto-encoding variational bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,”
-
[20]
Auto-Encoding Variational Bayes
[Online]. Available: https://arxiv.org/abs/1312.6114
-
[21]
Multimodal unsupervised image-to-image translation,
X. Huang, M.-Y . Liu, S. Belongie, and J. Kautz, “Multimodal unsupervised image-to-image translation,” 2018. [Online]. Available: https://arxiv.org/abs/1804.04732
-
[22]
Exploring latent pathways: Enhancing the interpretability of autonomous driving with a variational autoencoder,
A. Bairouk, M. Maras, S. Herlin, A. Amini, M. Blanchon, R. Hasani, P. Chareyre, and D. Rus, “Exploring latent pathways: Enhancing the interpretability of autonomous driving with a variational autoencoder,”
-
[23]
Available: https://arxiv.org/abs/2404.01750
[Online]. Available: https://arxiv.org/abs/2404.01750
-
[24]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” 2023. [Online]. Available: https://arxiv.org/abs/2210.02747
work page Pith review arXiv 2023
-
[25]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,” 2022. [Online]. Available: https://arxiv.org/abs/2209.03003
work page internal anchor Pith review arXiv 2022
-
[26]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, K. Lacey, A. Goodwin, Y . Marek, and R. Rombach, “Scaling rectified flow transformers for high-resolution image synthesis,” 2024. [Online]. Available: https://arxiv.org/abs/2403.03206
work page internal anchor Pith review arXiv 2024
-
[27]
π0: A vision-language-action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “π0: A vision-language-action flow model for general robot control,”
-
[28]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
[Online]. Available: https://arxiv.org/abs/2410.24164
work page internal anchor Pith review arXiv
-
[29]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen, “Glide: Towards photorealistic image generation and editing with text-guided diffusion models,” 2022. [Online]. Available: https://arxiv.org/abs/2112.10741
work page internal anchor Pith review arXiv 2022
-
[30]
Learning structured output represen- tation using deep conditional generative models,
K. Sohn, H. Lee, and X. Yan, “Learning structured output represen- tation using deep conditional generative models,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[31]
Generating diverse high-fidelity images with VQ-V AE-2.arXiv:1906.00446, 2019
A. Razavi, A. van den Oord, and O. Vinyals, “Generating diverse high-fidelity images with vq-vae-2,” 2019. [Online]. Available: https://arxiv.org/abs/1906.00446
-
[32]
Lagging inference networks and posterior collapse in variational autoencoders,
J. He, D. Spokoyny, G. Neubig, and T. Berg-Kirkpatrick, “Lagging inference networks and posterior collapse in variational autoencoders,”
- [33]
-
[34]
Convergence analysis of flow matching in latent space with transformers
Y . Jiao, Y . Lai, Y . Wang, and B. Yan, “Convergence analysis of flow matching in latent space with transformers,” 2024. [Online]. Available: https://arxiv.org/abs/2404.02538
-
[35]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[36]
Gorela: Go relative for viewpoint-invariant motion forecasting
A. Cui, S. Casas, K. Wong, S. Suo, and R. Urtasun, “Gorela: Go relative for viewpoint-invariant motion forecasting,”arXiv preprint arXiv:2211.02545, 2022
-
[37]
J. Ngiam, B. Caine, V . Vasudevan, Z. Zhang, H.-T. L. Chiang, J. Ling, R. Roelofs, A. Bewley, C. Liu, A. Venugopalet al., “Scene transformer: A unified architecture for predicting multiple agent tra- jectories,”arXiv preprint arXiv:2106.08417, 2021
-
[38]
Hivt: Hierarchical vector transformer for multi-agent motion prediction,
Z. Zhou, L. Ye, J. Wang, K. Wu, and K. Lu, “Hivt: Hierarchical vector transformer for multi-agent motion prediction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8823–8833
2022
-
[39]
arXiv preprint arXiv:2205.03195 , year=
M. Igl, D. Kim, A. Kuefler, P. Mougin, P. Shah, K. Shiarlis, D. Anguelov, M. Palatucci, B. White, and S. Whiteson, “Symphony: Learning realistic and diverse agents for autonomous driving simulation,” 2022. [Online]. Available: https://arxiv.org/abs/2205.03195
-
[40]
Scenediffuser++: City-scale traffic simulation via a generative world model,
S. Tan, J. Lambert, H. Jeon, S. Kulshrestha, Y . Bai, J. Luo, D. Anguelov, M. Tan, and C. M. Jiang, “Scenediffuser++: City-scale traffic simulation via a generative world model,” 2025. [Online]. Available: https://arxiv.org/abs/2506.21976
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.