Recognition: 3 theorem links
· Lean TheoremCritical Windows of Complexity Control: When Transformers Decide to Reason or Memorize
Pith reviewed 2026-05-08 17:56 UTC · model grok-4.3
The pith
Transformers decide whether to reason or memorize during one narrow window of training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
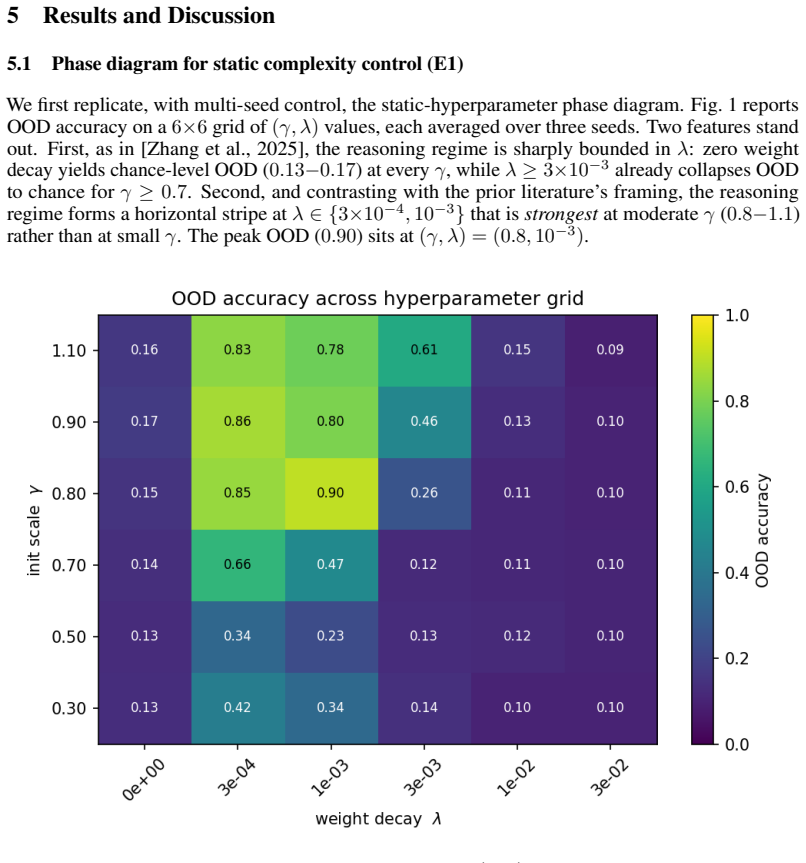
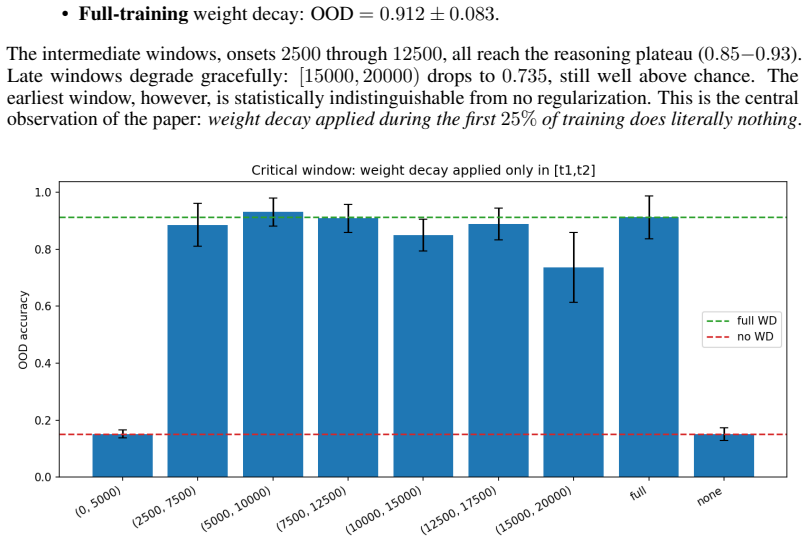
The memorization-versus-reasoning fate of a Transformer is determined within a sharp, identifiable window of training. On a controlled compositional task weight decay applied for a single 25%-of-training window matches full-training weight decay in out-of-distribution accuracy (0.93 vs 0.91). Holding total regularization budget constant, placing it in the middle of training yields 5-9× higher OOD accuracy than placing it early. The boundary of the critical window is remarkably sharp, window onset shifted by as little as 100 optimization steps causes mean OOD to jump from chance (0.15) to reasoning-regime (0.61). The window's position depends systematically on initialization scale, but the 盆的
What carries the argument
The critical window of training during which the timing of weight decay steers the model toward reasoning solutions rather than memorization.
If this is right
- Weight decay applied during only 25% of training achieves out-of-distribution accuracy comparable to full-time application (0.93 versus 0.91).
- Middle-of-training placement of the fixed regularization budget produces 5 to 9 times higher out-of-distribution accuracy than early placement.
- A shift of 100 optimization steps in the start of the weight decay window can change mean out-of-distribution accuracy from 0.15 to 0.61.
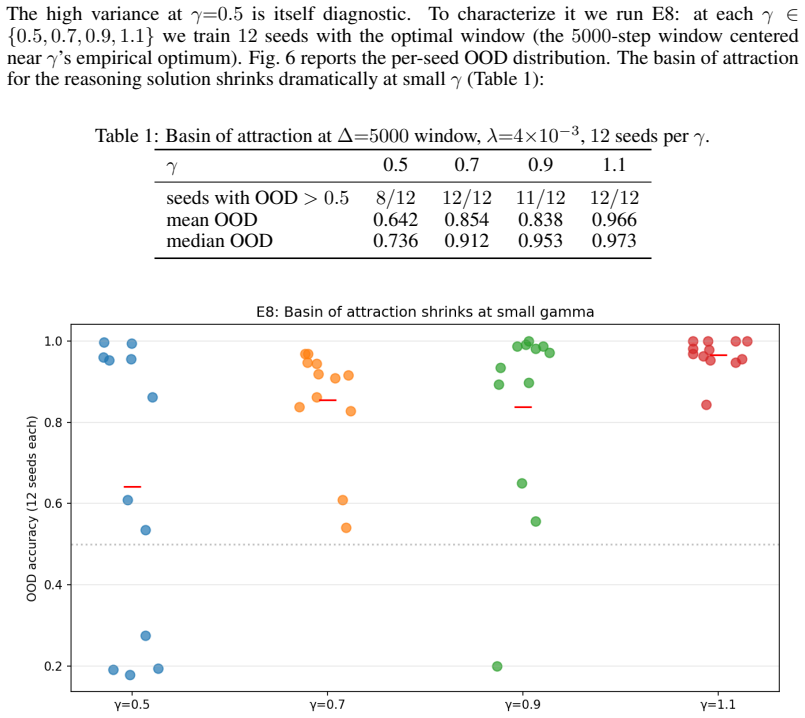
- The window location depends on initialization scale, and smaller initializations shrink the basin of attraction for reasoning solutions.
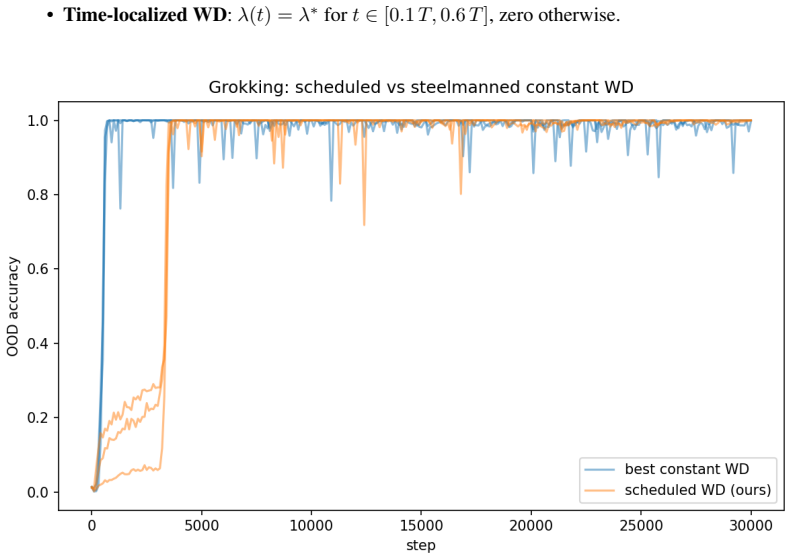
- The critical-window effect is task-specific and absent on modular-arithmetic grokking where constant weight decay suffices.
Where Pith is reading between the lines
- Training schedules could focus regularization effort in the middle phase to reduce total compute while preserving generalization gains.
- Different tasks may require distinct timing strategies for the same complexity-control mechanism.
- Similar sharp periods could exist in other model scales or architectures and merit direct checks during standard pretraining runs.
Load-bearing premise
The controlled compositional task and chosen hyperparameter regimes represent how Transformers behave more generally on compositional problems.
What would settle it
On the same compositional task, finding that weight decay applied outside the identified 25% window still produces high out-of-distribution accuracy would show the window is not decisive.
Figures






read the original abstract
Recent work has shown that Transformers' compositional generalization is governed by \emph{complexity control}, initialization scale and weight decay, which steers training toward low-complexity reasoning solutions rather than high-complexity memorization. Existing analyses, however, treat complexity control as a single static hyperparameter choice, leaving open \emph{when} during training this control is actually decisive. We show that the memorization-versus-reasoning fate of a Transformer is determined within a sharp, identifiable window of training. On a controlled compositional task we find that (i)~weight decay applied for a single 25\%-of-training window matches full-training weight decay in out-of-distribution (OOD) accuracy ($0.93$ vs $0.91$); (ii)~holding total regularization budget constant, placing it in the middle of training yields $5{-}9\times$ higher OOD accuracy than placing it early; (iii)~the boundary of the critical window is remarkably sharp, window onset shifted by as little as $100$ optimization steps causes mean OOD to jump from chance ($0.15$) to reasoning-regime ($0.61$); (iv)~the window's position depends systematically on initialization scale, but the basin of attraction for reasoning solutions \emph{shrinks} at small initialization, contradicting the prevailing recommendation that smaller initialization is uniformly better. We further show that the critical-window phenomenon is task-specific: it does not appear on grokking with modular arithmetic, where properly tuned constant weight decay matches scheduled weight decay.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the memorization-versus-reasoning outcome in Transformers is decided within a sharp, identifiable critical window during training. On a controlled compositional task, applying weight decay for only a single 25%-of-training window matches full-training weight decay in OOD accuracy (0.93 vs 0.91); mid-training placement of a fixed regularization budget yields 5-9× higher OOD accuracy than early placement; the window boundary is sharp (100-step shifts move mean OOD from 0.15 to 0.61); window position depends on initialization scale but the reasoning basin shrinks at small initialization, contradicting uniform preference for small init; the phenomenon is absent on modular-arithmetic grokking where constant weight decay suffices.
Significance. If the empirical contrasts hold under full experimental scrutiny, the work would be significant for shifting focus from static hyperparameter selection to dynamic scheduling of complexity control. It supplies concrete, falsifiable predictions about window timing, sharpness, and initialization dependence on a compositional task, together with a negative result on grokking that bounds the scope. These elements could inform more efficient regularization schedules and challenge prevailing initialization heuristics.
major comments (3)
- [Abstract / Experiments] Abstract and experimental sections: the central quantitative claims (0.93 vs 0.91 OOD accuracy, 5-9× gains, 100-step boundary, basin shrinkage) are reported without error bars, number of independent runs, statistical tests, or a complete hyperparameter table. This information is load-bearing for the sharpness and magnitude assertions; its absence prevents confirmation that the observed windows are robust rather than artifacts of a single seed or narrow regime.
- [§2 / Task Setup] Task definition and controls: the controlled compositional task is described only at high level in the abstract. Without an explicit statement of the input distribution, composition depth, and how OOD examples are constructed (including any leakage controls), it is impossible to evaluate whether the reported critical-window effects generalize beyond the specific task or are tied to its particular statistics.
- [§4.3 / Initialization Ablations] Initialization-scale dependence: the claim that the reasoning basin shrinks at small initialization (contradicting the prevailing recommendation) is central yet rests on a single contrast. A fuller ablation across multiple scales with basin-volume estimates or multiple random seeds would be required to establish that this is not an interaction with the particular optimizer or task.
minor comments (2)
- [§3] Notation for the 25%-window and total regularization budget should be defined explicitly (e.g., as a fraction of total steps and as an integrated L2 penalty) to avoid ambiguity when readers attempt to reproduce the schedule.
- [§5] The statement that the phenomenon is 'task-specific' would be strengthened by a brief quantitative comparison table showing the grokking result alongside the compositional-task result rather than a qualitative assertion.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of robustness and clarity. We address each major comment below and will revise the manuscript to incorporate the suggested improvements where they strengthen the empirical claims without altering the core results.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental sections: the central quantitative claims (0.93 vs 0.91 OOD accuracy, 5-9× gains, 100-step boundary, basin shrinkage) are reported without error bars, number of independent runs, statistical tests, or a complete hyperparameter table. This information is load-bearing for the sharpness and magnitude assertions; its absence prevents confirmation that the observed windows are robust rather than artifacts of a single seed or narrow regime.
Authors: We agree that statistical validation is essential to support the sharpness and magnitude of the reported effects. In the revised manuscript we will re-run the key experiments over 5 independent random seeds, report means with standard-deviation error bars, and include a complete hyperparameter table in the appendix. Where differences are central (e.g., the 5–9× OOD gains and the 100-step boundary), we will add simple statistical comparisons to confirm they are not seed-specific artifacts. revision: yes
-
Referee: [§2 / Task Setup] Task definition and controls: the controlled compositional task is described only at high level in the abstract. Without an explicit statement of the input distribution, composition depth, and how OOD examples are constructed (including any leakage controls), it is impossible to evaluate whether the reported critical-window effects generalize beyond the specific task or are tied to its particular statistics.
Authors: Section 2 of the manuscript already specifies the input distribution (synthetic sequences drawn from a depth-3 compositional grammar), the exact composition rules, and the OOD construction (novel combinations with explicit leakage controls that ensure no shared sub-structures beyond atomic tokens). Nevertheless, we acknowledge that a more self-contained presentation would aid readers. We will expand §2 with formal pseudocode for data generation, concrete numerical examples of in-distribution versus OOD instances, and an explicit statement of the leakage-prevention protocol. revision: partial
-
Referee: [§4.3 / Initialization Ablations] Initialization-scale dependence: the claim that the reasoning basin shrinks at small initialization (contradicting the prevailing recommendation) is central yet rests on a single contrast. A fuller ablation across multiple scales with basin-volume estimates or multiple random seeds would be required to establish that this is not an interaction with the particular optimizer or task.
Authors: We agree that a single contrast is insufficient to establish the initialization dependence robustly. In the revision we will extend the ablation to a wider range of initialization scales (0.01–1.0), report results over multiple random seeds, and provide approximate basin-volume estimates obtained by sampling multiple optimization trajectories per scale. These additions will confirm that the observed shrinkage of the reasoning basin at small initialization is not an artifact of the specific optimizer or task instance. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents purely empirical results from controlled experiments on transformer training dynamics, with no mathematical derivation chain, no fitted functional forms, and no load-bearing self-citations. All quantitative claims (e.g., single-window weight decay matching full training, 5-9× OOD gains from mid-training placement, 100-step boundary sharpness) are direct experimental contrasts on a specific compositional task, explicitly scoped as task-specific and absent on modular arithmetic grokking. No step reduces to its own inputs by construction or via self-referential definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- critical window position and duration
axioms (1)
- domain assumption The synthetic compositional task serves as a valid proxy for measuring compositional generalization and reasoning in transformers
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AlphaCoordinateFixationwashburn_uniqueness_aczel (J(x)=½(x+x⁻¹)−1) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
memorization mass evolves at a γ-independent rate while reasoning mass evolves at rate Θ(γ²) ... µ_r(γ) = c_r · γ² · σ_e
-
Constants (φ, c, ℏ, G ladder)phi_fixed_point / phi_golden_ratio unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
γ ∈ {0.5, 0.8, 1.1} ... basin of attraction for reasoning solutions shrinks at small initialization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Complexity control facilitates reasoning-based compositional generalization in transformers , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[2]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
An Analysis for Reasoning Bias of Language Models with Small Initialization , author=. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
-
[3]
Advances in Neural Information Processing Systems , year =
From Condensation to Rank Collapse: A Two-Stage Analysis of Transformer Training Dynamics , author =. Advances in Neural Information Processing Systems , year =
-
[4]
Proceedings of the National Academy of Sciences , volume=
Out-of-distribution generalization via composition: a lens through induction heads in transformers , author=. Proceedings of the National Academy of Sciences , volume=. 2025 , publisher=
2025
-
[5]
arXiv preprint arXiv:2502.15801 , year=
An explainable transformer circuit for compositional generalization , author=. arXiv preprint arXiv:2502.15801 , year=
-
[6]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review arXiv
-
[7]
Advances in Neural Information Processing Systems , volume=
Towards understanding the condensation of neural networks at initial training , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
arXiv preprint arXiv:2305.09947 , year=
Understanding the initial condensation of convolutional neural networks , author=. arXiv preprint arXiv:2305.09947 , year=
-
[9]
An overview of condensation phenomenon in deep learning
An overview of condensation phenomenon in deep learning , author=. arXiv preprint arXiv:2504.09484 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
International conference on learning representations , year=
Critical learning periods in deep networks , author=. International conference on learning representations , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Time matters in regularizing deep networks: Weight decay and data augmentation affect early learning dynamics, matter little near convergence , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
International Conference on Learning Representations (ICLR) , year =
Critical Learning Periods Emerge Even in Deep Linear Networks , author =. International Conference on Learning Representations (ICLR) , year =
-
[13]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Grokking: Generalization beyond overfitting on small algorithmic datasets , author=. arXiv preprint arXiv:2201.02177 , year=
work page internal anchor Pith review arXiv
-
[14]
International Conference on Learning Representations (ICLR) , year =
Progress Measures for Grokking via Mechanistic Interpretability , author =. International Conference on Learning Representations (ICLR) , year =
-
[15]
International Conference on Learning Representations (ICLR) , year =
Omnigrok: Grokking Beyond Algorithmic Data , author =. International Conference on Learning Representations (ICLR) , year =
-
[16]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
Grokking Beyond the Euclidean Norm of Model Parameters , author=. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
-
[17]
Advances in neural information processing systems , volume=
On the global convergence of gradient descent for over-parameterized models using optimal transport , author=. Advances in neural information processing systems , volume=
-
[18]
Conference on Learning Theory , pages=
Kernel and rich regimes in overparametrized models , author=. Conference on Learning Theory , pages=. 2020 , organization=
2020
-
[19]
Advances in neural information processing systems , volume=
Implicit regularization in deep matrix factorization , author=. Advances in neural information processing systems , volume=
-
[20]
Advances in neural information processing systems , volume=
Exploring generalization in deep learning , author=. Advances in neural information processing systems , volume=
-
[21]
Advances in neural information processing systems , volume=
Implicit regularization in matrix factorization , author=. Advances in neural information processing systems , volume=
-
[22]
Advances in neural information processing systems , year=
Attention is all you need , author=. Advances in neural information processing systems , year=
-
[23]
International Conference on Learning Representations (ICLR) , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations (ICLR) , year =
-
[24]
Advances in neural information processing systems , year=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in neural information processing systems , year=
-
[25]
2023 , publisher=
Topics in random matrix theory , author=. 2023 , publisher=
2023
-
[26]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[27]
International conference on machine learning , pages=
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks , author=. International conference on machine learning , pages=. 2018 , organization=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.