Recognition: unknown
Data-dependent Exploration for Online Reinforcement Learning from Human Feedback
Pith reviewed 2026-05-08 16:55 UTC · model grok-4.3
The pith
DEPO adds uncertainty bonuses from historical preferences to guide exploration in online RLHF.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DEPO is a simple scalable method that leverages historical data to construct an extra uncertainty bonus for high-uncertainty regions, encouraging exploration toward potentially high-value data. It supplies a data-dependent regret bound that adapts to the hardness of the learning task and can be tighter than worst-case bounds in practice, while delivering improved sample efficiency across benchmarks.
What carries the argument
The data-dependent uncertainty bonus built from historical preference data, which augments the exploration signal inside the preference optimization objective.
Load-bearing premise
Uncertainty estimates constructed from limited historical preference data reliably identify high-value regions without introducing systematic bias or over-exploration in low-value areas.
What would settle it
On a benchmark where adding the historical-data bonus produces no gain or a loss in sample efficiency relative to baselines that omit it, the central claim would be falsified.
Figures
read the original abstract
Online reinforcement learning from human feedback (RLHF) has emerged as a promising paradigm for aligning large language models (LLMs) by continuously collecting new preference feedback during training. A foundational challenge in this setting is exploration, which requires algorithms that enable the LLMs to generate informative comparisons that improve sample-efficiency in online RLHF. Existing exploration strategies often derive bonuses via on-policy expectations, which are difficult to estimate reliably from the limited historical preference data available during training; as a result, the policy can prematurely down-weight under-explored regions that may contain high-value behaviors. In this paper, we propose data-dependent exploration for preference optimization (DEPO), a simple and scalable method that leverages historical data to construct an extra uncertainty bonus for high-uncertainty regions, encouraging exploration toward potentially high-value data. Theoretically, we provide a data-dependent regret bound for the proposed algorithm, showing that it adapts to the hardness of the learning task itself and can be tighter than worst-case bounds in practice. Empirically, the proposed method consistently outperforms strong baselines across benchmarks, demonstrating improved sample efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DEPO, a method for online RLHF that constructs an extra uncertainty bonus from historical preference data to encourage exploration in high-uncertainty regions that may contain high-value behaviors. It claims a data-dependent regret bound that adapts to the hardness of the learning task and can be tighter than worst-case bounds, together with empirical results showing consistent outperformance and improved sample efficiency over strong baselines across benchmarks.
Significance. If the data-dependent regret bound is valid and the uncertainty estimates reliably support adaptation without systematic bias, the work would advance sample-efficient online RLHF beyond standard worst-case analyses, with direct relevance to LLM alignment. The empirical gains, if robust to implementation details, could influence practical exploration strategies in preference optimization.
major comments (2)
- [Theoretical analysis] Theoretical analysis section: the data-dependent regret bound is presented as adapting to task hardness via the uncertainty bonus, but the derivation does not appear to include an analysis of how estimation error in the bonus (from sparse early-stage preference data) affects the bound. This is load-bearing for the central claim that the bound is tighter than worst-case in practice, as noisy or biased estimates could cause the adaptation property to fail.
- [Experimental results] Experimental results section: the reported outperformance relies on the uncertainty bonus identifying high-value regions, yet the manuscript provides insufficient detail on the exact estimator, data exclusion rules, or sensitivity to limited historical data. Without these, it is difficult to verify that the gains are not due to post-hoc choices or over-exploration of low-value areas, undermining the sample-efficiency claim.
minor comments (2)
- [Method] The notation for the uncertainty bonus could be introduced with an explicit equation in the main body rather than deferred to the appendix for easier reading.
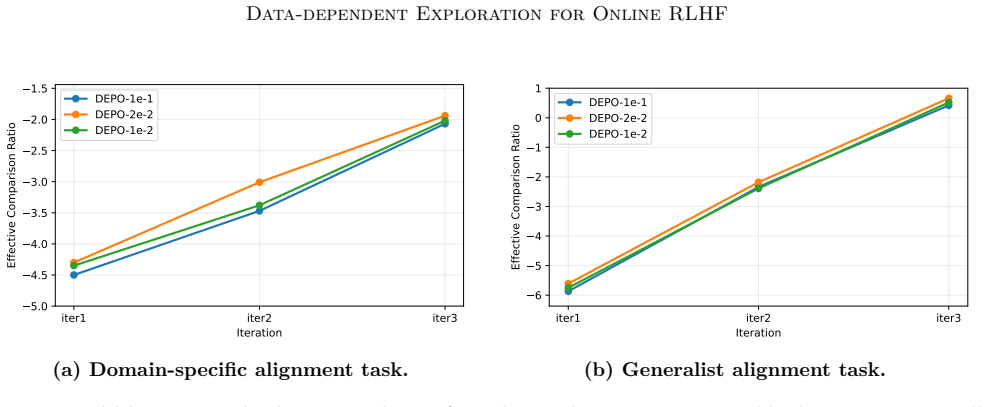
- [Experiments] Figure captions for benchmark curves should include the number of runs and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each of the major concerns below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section: the data-dependent regret bound is presented as adapting to task hardness via the uncertainty bonus, but the derivation does not appear to include an analysis of how estimation error in the bonus (from sparse early-stage preference data) affects the bound. This is load-bearing for the central claim that the bound is tighter than worst-case in practice, as noisy or biased estimates could cause the adaptation property to fail.
Authors: We appreciate the referee pointing out this potential gap in the analysis. The data-dependent regret bound in our paper is derived by incorporating the uncertainty bonus, which is computed from historical preference data, directly into the regret decomposition. This allows the bound to adapt based on the actual data observed, including the sparsity in early stages. However, to make the adaptation property more robust, we will add a subsection in the theoretical analysis that bounds the estimation error of the bonus using Hoeffding-type inequalities on the preference data, showing that the additional error term vanishes as more data is collected and does not invalidate the data-dependent tightness. This revision will explicitly address how the bound remains valid despite initial estimation inaccuracies. revision: yes
-
Referee: [Experimental results] Experimental results section: the reported outperformance relies on the uncertainty bonus identifying high-value regions, yet the manuscript provides insufficient detail on the exact estimator, data exclusion rules, or sensitivity to limited historical data. Without these, it is difficult to verify that the gains are not due to post-hoc choices or over-exploration of low-value areas, undermining the sample-efficiency claim.
Authors: We agree that more implementation details are essential for full reproducibility and to support the empirical claims. In the revised manuscript, we will expand the experimental section to include: (1) the precise mathematical formulation of the uncertainty estimator used in DEPO, which is based on variance estimates from the historical preference dataset; (2) explicit data exclusion rules, specifying that only preferences collected in previous rounds are used to avoid lookahead bias; and (3) additional sensitivity experiments varying the volume of historical data (e.g., using 10%, 50%, and 100% of available data) to demonstrate robustness. These additions will clarify that the performance gains arise from the adaptive exploration mechanism rather than specific tuning choices. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes DEPO using historical preference data for an uncertainty bonus and claims a data-dependent regret bound that adapts to task hardness. No equations or steps are quoted that reduce the bound by construction to fitted inputs, self-definitions, or self-citations. The theoretical claim is presented as independent analysis, and empirical outperformance on benchmarks is separate from the bound derivation. No self-citation load-bearing, ansatz smuggling, or renaming of known results is evident. The derivation chain remains self-contained against external benchmarks and does not exhibit the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Historical preference data can be used to construct reliable uncertainty estimates for exploration bonuses.
Reference graph
Works this paper leans on
-
[1]
The 13th International Conference on Learning Representations (ICLR) , year=
Exploratory Preference Optimization: Harnessing Implicit Q*-Approximation for Sample-Efficient RLHF , author=. The 13th International Conference on Learning Representations (ICLR) , year=
-
[2]
The 13th International Conference on Learning Representations (ICLR) , year=
Value-Incentivized Preference Optimization: A Unified Approach to Online and Offline RLHF , author=. The 13th International Conference on Learning Representations (ICLR) , year=
-
[4]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Avoiding exp (R) scaling in RLHF through Preference-based Exploration , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Deep reinforcement learning from human preferences , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[7]
Proceedings of the 41st International Conference on Machine Learning (ICML) , pages=
Efficient exploration for LLMs , author=. Proceedings of the 41st International Conference on Machine Learning (ICML) , pages=
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Rebel: Reinforcement learning via regressing relative rewards , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[10]
the method of paired comparisons , author=
Rank analysis of incomplete block designs: I. the method of paired comparisons , author=. Biometrika , volume=
-
[11]
Transactions on Machine Learning Research , year=
RLHF Workflow: From Reward Modeling to Online RLHF A Comprehensive Practical Alignment Recipe of Iterative Preference Learning , author=. Transactions on Machine Learning Research , year=
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , pages=
\# exploration: A study of count-based exploration for deep reinforcement learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , pages=
-
[14]
Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=
Curiosity-driven exploration by self-supervised prediction , author=. Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=
-
[15]
The 7th International Conference on Learning Representations (ICLR) , year=
Exploration by random network distillation , author=. The 7th International Conference on Learning Representations (ICLR) , year=
-
[16]
Journal of Machine Learning Research (JMLR) , volume=
Deep exploration via randomized value functions , author=. Journal of Machine Learning Research (JMLR) , volume=
-
[17]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[18]
The 10th International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. The 10th International Conference on Learning Representations (ICLR) , year=
-
[19]
First Conference on Language Modeling , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. First Conference on Language Modeling , year=
-
[21]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[27]
Proceedings of the 27th International Conference on Artificial Intelligence and Statistics (AISTATS) , pages=
A general theoretical paradigm to understand learning from human preferences , author=. Proceedings of the 27th International Conference on Artificial Intelligence and Statistics (AISTATS) , pages=
-
[28]
The 13th International Conference on Learning Representations (ICLR) , year=
Building Math Agents with Multi-Turn Iterative Preference Learning , author=. The 13th International Conference on Learning Representations (ICLR) , year=
-
[30]
arXiv preprint arXiv:2502.07193 , year=
Provably Efficient Online RLHF with One-Pass Reward Modeling , author=. arXiv preprint arXiv:2502.07193 , year=
-
[31]
Proceedings of the 37th International Conference on Machine Learning (ICML) , pages=
Improved optimistic algorithms for logistic bandits , author=. Proceedings of the 37th International Conference on Machine Learning (ICML) , pages=
-
[32]
Machine Learning , volume=
Finite-time analysis of the multiarmed bandit problem , author=. Machine Learning , volume=
-
[33]
Advances in Applied Mathematics , volume=
Asymptotically efficient adaptive allocation rules , author=. Advances in Applied Mathematics , volume=
-
[34]
The Annals of Mathematical Statistics , volume=
Adjustment of an inverse matrix corresponding to a change in one element of a given matrix , author=. The Annals of Mathematical Statistics , volume=
-
[35]
Proceedings of the 40th International Conference on Machine Learning (ICML) , pages=
Principled reinforcement learning with human feedback from pairwise or k-wise comparisons , author=. Proceedings of the 40th International Conference on Machine Learning (ICML) , pages=
-
[36]
ICML 2023 Workshop The Many Facets of Preference-Based Learning , year=
Provable offline reinforcement learning with human feedback , author=. ICML 2023 Workshop The Many Facets of Preference-Based Learning , year=
2023
-
[37]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Provably mitigating overoptimization in rlhf: Your sft loss is implicitly an adversarial regularizer , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[38]
Learning for Dynamics and Control , pages=
Reward biased maximum likelihood estimation for reinforcement learning , author=. Learning for Dynamics and Control , pages=
-
[39]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Maximize to explore: One objective function fusing estimation, planning, and exploration , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[40]
Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , pages=
Very sparse random projections , author=. Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , pages=
-
[41]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
The importance of online data: Understanding preference fine-tuning via coverage , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[42]
2025 , author =
Clustered Reinforcement Learning , journal =. 2025 , author =
2025
-
[43]
2026 , author =
Diversity from human feedback , journal =. 2026 , author =
2026
-
[44]
2026 , author =
Exploiting large language model with reinforcement learning for generative job recommendations , journal =. 2026 , author =
2026
-
[45]
2026 , author =
The gains do not make up for the losses: a comprehensive evaluation for safety alignment of large language models via machine unlearning , journal =. 2026 , author =
2026
-
[46]
2025 , author =
Offline model-based reinforcement learning with causal structured world models , journal =. 2025 , author =
2025
-
[47]
2026 , author =
Trustworthy evaluation of large language models , journal =. 2026 , author =
2026
-
[48]
Provably Efficient
Long. Provably Efficient. Advances in Neural Information Processing Systems 38 (NeurIPS) , year =
-
[49]
Advances in Neural Information Processing Systems (NIPS) , volume=
Improved algorithms for linear stochastic bandits , author=. Advances in Neural Information Processing Systems (NIPS) , volume=
-
[50]
Proceedings of the 19th International Conference on World Wide Web (WWW) , pages=
A contextual-bandit approach to personalized news article recommendation , author=. Proceedings of the 19th International Conference on World Wide Web (WWW) , pages=
-
[51]
Advances in Neural Information Processing Systems (NIPS) , volume=
Generalized Linear Bandits: Almost Optimal Regret with One-Pass Update , author=. Advances in Neural Information Processing Systems (NIPS) , volume=
-
[52]
Proceedings of IEEE 36th Annual Foundations of Computer Science (FOCS) , pages=
Gambling in a rigged casino: The adversarial multi-armed bandit problem , author=. Proceedings of IEEE 36th Annual Foundations of Computer Science (FOCS) , pages=
-
[53]
The 13th International Conference on Learning Representations (ICLR) , year=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. The 13th International Conference on Learning Representations (ICLR) , year=
-
[54]
Proceedings of the 41st International Conference on Machine Learning (ICML) , pages=
Learning with adaptive resource allocation , author=. Proceedings of the 41st International Conference on Machine Learning (ICML) , pages=
-
[55]
Abbasi-Yadkori, D
Y. Abbasi-Yadkori, D. P \'a l, and C. Szepesv \'a ri. Improved algorithms for linear stochastic bandits. Advances in Neural Information Processing Systems (NIPS), 24: 0 2312--2320, 2011 a
2011
-
[56]
Y. Abbasi-Yadkori, D. P \'a l, and C. Szepesv \'a ri. Online least squares estimation with self-normalized processes: An application to bandit problems. arXiv preprint arXiv:1102.2670, 2011 b
-
[57]
P. Auer, N. Cesa-Bianchi, Y. Freund, and R. E. Schapire. Gambling in a rigged casino: The adversarial multi-armed bandit problem. In Proceedings of IEEE 36th Annual Foundations of Computer Science (FOCS), pages 322--331, 1995
1995
-
[58]
P. Auer, N. Cesa-Bianchi, and P. Fischer. Finite-time analysis of the multiarmed bandit problem. Machine Learning, 47 0 (2): 0 235--256, 2002
2002
-
[59]
M. G. Azar, Z. D. Guo, B. Piot, R. Munos, M. Rowland, M. Valko, and D. Calandriello. A general theoretical paradigm to understand learning from human preferences. In Proceedings of the 27th International Conference on Artificial Intelligence and Statistics (AISTATS), pages 4447--4455, 2024
2024
- [60]
-
[61]
R. A. Bradley and M. E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39 0 (3/4): 0 324--345, 1952
1952
-
[62]
S. Cen, J. Mei, K. Goshvadi, H. Dai, T. Yang, S. Yang, D. Schuurmans, Y. Chi, and B. Dai. Value-incentivized preference optimization: A unified approach to online and offline rlhf. In The 13th International Conference on Learning Representations (ICLR), 2024
2024
-
[63]
M. Chen, Y. Chen, W. Sun, and X. Zhang. Avoiding exp (r) scaling in rlhf through preference-based exploration. Advances in Neural Information Processing Systems (NeurIPS), 39: 0 to appear, 2025
2025
-
[64]
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems (NeurIPS), 30: 0 4299--4307, 2017
2017
-
[65]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[66]
H. Dong, W. Xiong, B. Pang, H. Wang, H. Zhao, Y. Zhou, N. Jiang, D. Sahoo, C. Xiong, and T. Zhang. Rlhf workflow: From reward modeling to online rlhf a comprehensive practical alignment recipe of iterative preference learning. Transactions on Machine Learning Research, 2024
2024
-
[67]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Y. Dubois, B. Galambosi, P. Liang, and T. B. Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators. arXiv preprint arXiv:2404.04475, 2024
work page internal anchor Pith review arXiv 2024
-
[68]
Dwaracherla, S
V. Dwaracherla, S. M. Asghari, B. Hao, and B. Van Roy. Efficient exploration for llms. In Proceedings of the 41st International Conference on Machine Learning (ICML), pages 12215--12227, 2024
2024
- [69]
-
[70]
Hendrycks, C
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. In The 10th International Conference on Learning Representations (ICLR), 2021
2021
-
[71]
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. In The 13th International Conference on Learning Representations (ICLR), 2024
2024
-
[72]
T. L. Lai and H. Robbins. Asymptotically efficient adaptive allocation rules. Advances in Applied Mathematics, 6 0 (1): 0 4--22, 1985
1985
-
[73]
L. Li, W. Chu, J. Langford, and R. E. Schapire. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th International Conference on World Wide Web (WWW), pages 661--670, 2010
2010
-
[74]
L. Li, Y. Qian, P. Zhao, and Z. Zhou. Provably efficient RLHF pipeline: A unified view from contextual bandits. In Advances in Neural Information Processing Systems 38 (NeurIPS), page to appear, 2025
2025
-
[75]
P. Li, T. J. Hastie, and K. W. Church. Very sparse random projections. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pages 287--296, 2006
2006
-
[76]
S. Lin, J. Hilton, and O. Evans. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), pages 3214--3252, 2022
2022
-
[77]
X. Ma, S. Zhao, Z. Yin, and W. Li. Clustered reinforcement learning. Frontiers of Computer Science, 19: 0 194313, 2025
2025
-
[78]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems (NeurIPS), 35: 0 27730--27744, 2022
2022
-
[79]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems (NeurIPS), 36: 0 53728--53741, 2023
2023
-
[80]
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling, 2024
2024
-
[81]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[82]
Sherman and W
J. Sherman and W. J. Morrison. Adjustment of an inverse matrix corresponding to a change in one element of a given matrix. The Annals of Mathematical Statistics, 21 0 (1): 0 124--127, 1950
1950
-
[83]
Y. Song, G. Swamy, A. Singh, J. Bagnell, and W. Sun. The importance of online data: Understanding preference fine-tuning via coverage. Advances in Neural Information Processing Systems (NeurIPS), 37: 0 12243--12270, 2024
2024
-
[84]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review arXiv 2023
-
[85]
arXiv preprint arXiv:2510.11686 , year=
J. Tuyls, D. J. Foster, A. Krishnamurthy, and J. T. Ash. Representation-based exploration for language models: From test-time to post-training. arXiv preprint arXiv:2510.11686, 2025
-
[86]
J. Wang, M. Yu, P. Zhao, and Z.-H. Zhou. Learning with adaptive resource allocation. In Proceedings of the 41st International Conference on Machine Learning (ICML), pages 52099--52116, 2024
2024
-
[87]
R. Wang, K. Xue, Y. Wang, P. Yang, H. Fu, Q. Fu, and C. Qian. Diversity from human feedback. Frontiers of Computer Science, 20: 0 2002320, 2026
2026
-
[88]
T. Xie, D. J. Foster, A. Krishnamurthy, C. Rosset, A. H. Awadallah, and A. Rakhlin. Exploratory preference optimization: Harnessing implicit q*-approximation for sample-efficient rlhf. In The 13th International Conference on Learning Representations (ICLR), 2024
2024
-
[89]
Xiong, C
W. Xiong, C. Shi, J. Shen, A. Rosenberg, Z. Qin, D. Calandriello, M. Khalman, R. Joshi, B. Piot, M. Saleh, et al. Building math agents with multi-turn iterative preference learning. In The 13th International Conference on Learning Representations (ICLR), 2024
2024
- [90]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.