Recognition: unknown
YOTOnet: Zero-Shot Cross-Domain Fault Diagnosis via Domain-Conditioned Mixture of Experts
Pith reviewed 2026-05-08 16:28 UTC · model grok-4.3
The pith
YOTOnet enables a single training run to diagnose bearing faults across different datasets and conditions through invariant features and adaptive expert routing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
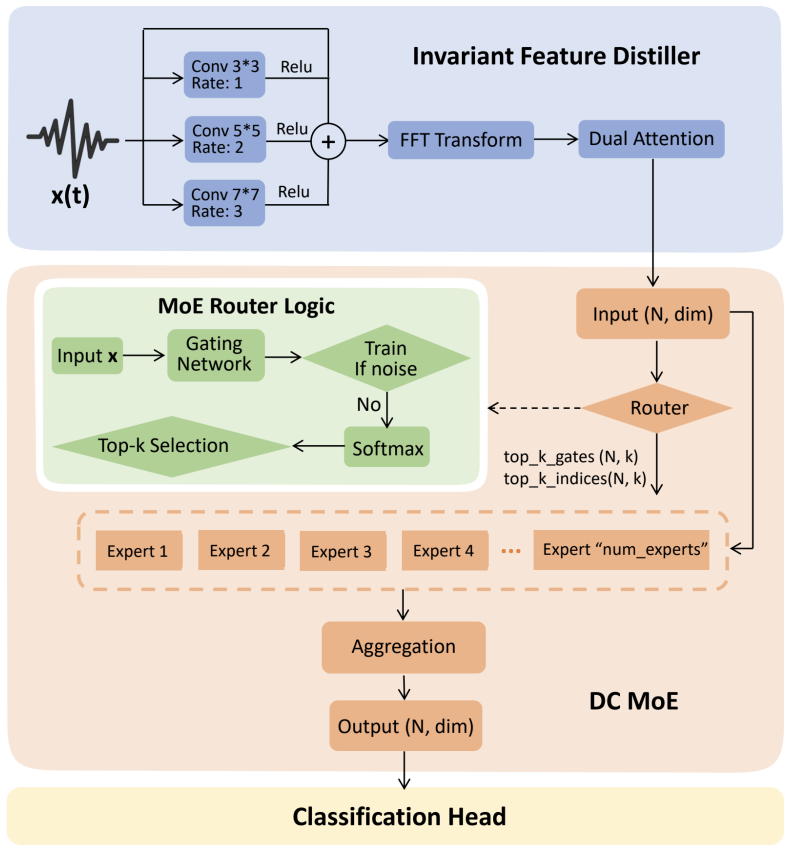
YOTOnet shows that combining a physics-aware Invariant Feature Distiller with Domain-Conditioned Sparse Experts produces better generalization in cross-domain bearing fault diagnosis. The distiller uses multi-scale dilated convolutions and FFT-based fusion to create domain-agnostic features, while the experts route samples via learned gating without any external metadata; a dual-head setup adds auxiliary supervision. On five public datasets and thirty cross-dataset tests, this yields higher F1 scores than prior methods, with average test F1 rising from 0.5339 when trained on one dataset to 0.705 when trained on four.
What carries the argument
Domain-Conditioned Sparse Experts that adaptively route inputs to specialized processors via learned gating, paired with a physics-aware Invariant Feature Distiller that extracts domain-agnostic representations using multi-scale dilated convolutions and FFT-based time-frequency fusion.
If this is right
- Average test F1 rises from 0.5339 with one training dataset to 0.705 with four, confirming a scaling benefit.
- The model supports train-once deployment for zero-shot use on new equipment or conditions.
- No external metadata is required for the expert routing to function across domains.
- The dual-head classification with auxiliary supervision improves the quality of the learned representations.
Where Pith is reading between the lines
- The same structure might transfer to fault diagnosis on other rotating machinery such as gears or pumps if the invariant features hold.
- Tracking which experts activate for different operating conditions could help identify the most informative sensor placements in new installations.
- Further gains may appear if the number of training datasets grows beyond four, following the observed trend from three to four datasets.
Load-bearing premise
The learned gating in the sparse experts routes inputs to the right specialized processors without needing domain labels, and the multi-scale convolutions with FFT fusion truly remove domain-specific information from the features.
What would settle it
On a sixth unseen bearing dataset, YOTOnet trained on the original four datasets fails to exceed the F1 scores of the strongest competing methods that were also trained on those four datasets.
Figures





read the original abstract
Mechanical equipment forms the critical backbone of modern industrial production, yet domain shift severely limits the generalization of deep learning based fault diagnosis models across different equipment and operating conditions.Inspired by the success of foundation models in achieving zero-shotgeneralization, we propose YOTOnet (You Only Train Once), a novel architecture specifically designed for cross-domain fault diagnosis in mechanical equipment.YOTOnet comprises three core components: (1) a physics-aware Invariant Feature Distiller that extracts domain-agnostic representations using multi-scale dilated convolutions and FFT-based time-frequency fusion,(2) Domain-Conditioned Sparse Experts (DC-MoE) that adaptively route inputs to specialized processors via learned gating without external meta-data, and (3) a dual-head classification system with auxiliary supervision.Extensive validation on five public bearing datasets (CWRU, MFPT, XJTU,OTTAWA, HUST) through 30 cross-dataset protocols demonstrates the superiority of YOTOnet compared with other state-of-the-art methods. Critically, we observe a clear scaling effect-average test F1 improves from 0.5339(1 training dataset) to 0.705 (4 datasets), with a clear gain when moving from 3 to 4 datasets. These findings provide empirical evidence that foundation model principles can enable robust, train-once deployment for industrial fault diagnosis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes YOTOnet (You Only Train Once), a novel architecture for zero-shot cross-domain fault diagnosis of mechanical equipment. It consists of three main components: (1) a physics-aware Invariant Feature Distiller that uses multi-scale dilated convolutions and FFT-based time-frequency fusion to extract domain-agnostic representations, (2) Domain-Conditioned Sparse Experts (DC-MoE) that perform adaptive routing to specialized experts via learned gating without external metadata, and (3) a dual-head classification system with auxiliary supervision. The work validates the approach on five public bearing datasets (CWRU, MFPT, XJTU, OTTAWA, HUST) across 30 cross-dataset protocols, reporting that average test F1 improves from 0.5339 (1 training dataset) to 0.705 (4 datasets) and outperforms other state-of-the-art methods, providing empirical support for foundation-model-style scaling in this domain.
Significance. If the empirical scaling trend and cross-domain gains hold under rigorous scrutiny, the work would be significant for industrial fault diagnosis by demonstrating that a single model trained once can generalize across equipment and operating conditions without domain-specific retraining or metadata. The explicit scaling observation (F1 rising with additional datasets) and the combination of invariant feature extraction with sparse expert routing offer a concrete architectural template that could be extended to other sensor-based diagnostic tasks.
major comments (3)
- [Methods (DC-MoE and Invariant Feature Distiller)] Methods (description of Invariant Feature Distiller and DC-MoE): The headline scaling result rests on the joint operation of the two mechanisms. If the Invariant Feature Distiller successfully produces domain-agnostic representations, the input to the learned gating network in DC-MoE necessarily contains little domain-discriminative signal, which directly undermines the premise that the gating can discover and exploit domain-specific expert specialization. The manuscript provides no analysis of expert activation statistics, gating entropy, or routing patterns conditioned on source versus target domains, leaving open whether observed gains arise from true adaptive routing or simply from increased parameter capacity and more training data.
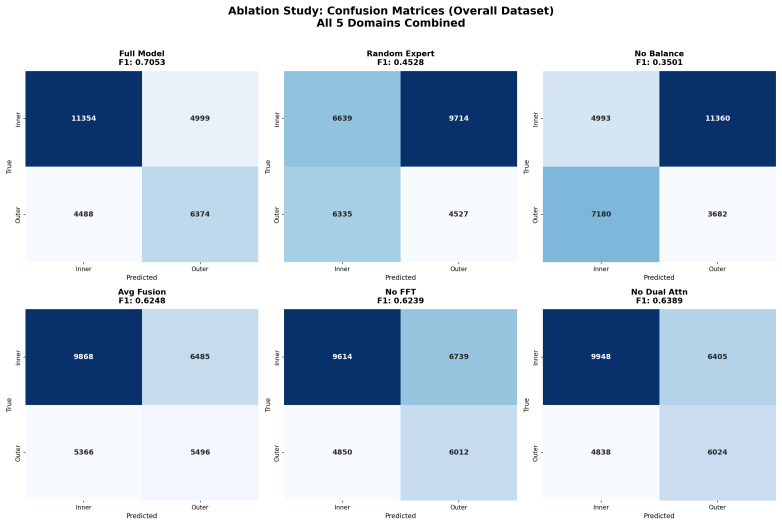
- [Experiments] Experimental results (30 cross-dataset protocols): The reported average F1 improvement from 0.5339 to 0.705 is presented without error bars, standard deviations across runs, or per-protocol breakdowns. This absence makes it impossible to determine whether the scaling trend is statistically reliable or sensitive to particular dataset pairings, which is load-bearing for the central claim of consistent superiority and foundation-model-like behavior.
- [Experiments] Baseline comparisons: The abstract states superiority over state-of-the-art methods but supplies no concrete baseline F1 scores, number of compared methods, or details on hyperparameter tuning protocols. Without these, the magnitude of improvement cannot be assessed relative to standard practices, weakening the comparative claim that underpins the practical significance.
minor comments (2)
- [Abstract and Experiments] The abstract and results sections would benefit from explicit statements of the number of experts, gating temperature, and auxiliary loss weights to allow reproducibility.
- [Methods] Notation for the FFT-based fusion and multi-scale dilated convolutions should be defined with equations rather than descriptive text only.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our work. We address each of the major comments point-by-point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Methods (DC-MoE and Invariant Feature Distiller)] Methods (description of Invariant Feature Distiller and DC-MoE): The headline scaling result rests on the joint operation of the two mechanisms. If the Invariant Feature Distiller successfully produces domain-agnostic representations, the input to the learned gating network in DC-MoE necessarily contains little domain-discriminative signal, which directly undermines the premise that the gating can discover and exploit domain-specific expert specialization. The manuscript provides no analysis of expert activation statistics, gating entropy, or routing patterns conditioned on source versus target domains, leaving open whether observed gains arise from true adaptive routing or simply from increased parameter capacity and more training data.
Authors: The referee raises a valid concern regarding the interplay between the two components. The Invariant Feature Distiller reduces domain-specific information to promote generalization, yet the DC-MoE is intended to allow specialization on residual domain or task variations through learned routing. We will revise the manuscript to include a detailed analysis of the expert activation statistics, gating entropy, and routing patterns for both source and target domains. This addition will provide evidence on whether the performance gains stem from adaptive expert specialization or other factors such as increased model capacity. revision: yes
-
Referee: [Experiments] Experimental results (30 cross-dataset protocols): The reported average F1 improvement from 0.5339 to 0.705 is presented without error bars, standard deviations across runs, or per-protocol breakdowns. This absence makes it impossible to determine whether the scaling trend is statistically reliable or sensitive to particular dataset pairings, which is load-bearing for the central claim of consistent superiority and foundation-model-like behavior.
Authors: We concur that error bars and per-protocol details are necessary to substantiate the scaling claims. In the revised manuscript, we will report the average F1 scores with standard deviations computed over multiple random seeds or runs. Additionally, we will provide a breakdown of results for each of the 30 cross-dataset protocols to allow readers to evaluate the consistency of the observed improvements. revision: yes
-
Referee: [Experiments] Baseline comparisons: The abstract states superiority over state-of-the-art methods but supplies no concrete baseline F1 scores, number of compared methods, or details on hyperparameter tuning protocols. Without these, the magnitude of improvement cannot be assessed relative to standard practices, weakening the comparative claim that underpins the practical significance.
Authors: The manuscript body contains the full set of baseline comparisons, including F1 scores for the compared methods and the hyperparameter search protocol. To improve clarity in the abstract, we will incorporate the number of baseline methods and representative F1 improvements. This will better support the claim of superiority while keeping the abstract concise. revision: partial
Circularity Check
No circularity; results are empirical validation on external public datasets
full rationale
The paper introduces an architecture (Invariant Feature Distiller + DC-MoE + dual-head classifier) and reports performance gains measured on held-out cross-dataset protocols from five independent public bearing datasets (CWRU, MFPT, XJTU, OTTAWA, HUST). No equations or derivations are presented that reduce by construction to fitted parameters or self-referential definitions; the scaling claim (F1 from 0.5339 to 0.705) is obtained by training on increasing numbers of source domains and testing on target domains outside the training distribution. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is used to substitute for independent evidence.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Domain-Conditioned Sparse Experts (DC-MoE)
no independent evidence
-
physics-aware Invariant Feature Distiller
no independent evidence
Reference graph
Works this paper leans on
-
[1]
D. Bourassa, F. Gauthier, G. Abdulnour, Equipment failures and their contribution to industrial incidents and accidents in the manufacturing industry, International journal of occupational safety and ergonomics : JOSE 22 (2015) 1–23. doi:10.1080/10803548.2015.1116814
-
[2]
S. Qiu, X. Cui, Z. Ping, N. Shan, Z. Li, X. Bao, X. Xu, Deep learn- ing techniques in intelligent fault diagnosis and prognosis for industrial systems: A review, Sensors 23 (3) (2023). doi:10.3390/s23031305
- [3]
-
[4]
F. Jiang, Y. Kuang, T. Li, S. Zhang, Z. Wu, K. Feng, W. Li, To- wards enhanced interpretability: A mechanism-driven domain adap- tation model for bearing fault diagnosis across operating condi- 16 tions, Mechanical Systems and Signal Processing 225 (2025) 112244. doi:https://doi.org/10.1016/j.ymssp.2024.112244
-
[5]
X. Pan, H. Chen, W. Wang, X. Su, Adversarial domain adap- tation based on contrastive learning for bearings fault diagno- sis, Simulation Modelling Practice and Theory 139 (2025) 103058. doi:https://doi.org/10.1016/j.simpat.2024.103058
-
[6]
Z. Yang, L. Luo, J. Ma, H. Zhang, L. Yang, Z. Wu, Enhancing bearing fault diagnosis in real damages: A hybrid multidomain generalization network for feature comparison, IEEE Transactions on Instrumentation and Measurement 74 (2025) 1–11. doi:10.1109/TIM.2025.3556828
-
[7]
X. Cui, H. Zhan, K. Han, J. Yu, R. Wang, G. Huang, Multi-bearing fault diagnosis method based on convolutional autoencoder causal de- coupling domain generalization, ISA Transactions 163 (2025) 236–250. doi:https://doi.org/10.1016/j.isatra.2025.05.008
-
[8]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollár, R. Girshick, Segment anything (2023). arXiv:2304.02643
work page internal anchor Pith review arXiv 2023
-
[9]
A. M. Bran, S. Cox, O. Schilter, C. Baldassari, A. D. White, P. Schwaller, Chemcrow: Augmenting large-language models with chem- istry tools (2023). arXiv:2304.05376
work page internal anchor Pith review arXiv 2023
-
[10]
H. Dalla-Torre, L. Gonzalez, J. M. Revilla, N. L. Carranza, A. H. Grzywaczewski, F. Oteri, C. Dallago, E. Trop, H. Sirelkhatim, G. Richard, M. Skwark, K. Beguir, M. Lopez, T. Pierrot, The nucleotide transformer: Building and evaluating robust foundation models for hu- man genomics, bioRxiv (2023). doi:10.1101/2023.01.11.523679
- [11]
- [12]
-
[13]
X. Chen, Y. Lei, Y. Li, S. Parkinson, X. Li, J. Liu, F. Lu, H. Wang, Z. Wang, B. Yang, S. Ye, Z. Zhao, Large models for machine monitoring and fault diagnostics: Opportunities, challenges, and future direction, Journal of Dynamics, Monitoring and Diagnostics 4 (2) (2025) 76–90. doi:10.37965/jdmd.2025.832
-
[14]
Szegedy, W
C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Er- han, V. Vanhoucke, A. Rabinovich, Going deeper with convolutions, in: 17 Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015
2015
-
[15]
F. Yu, V. Koltun, Multi-scale context aggregation by dilated convolu- tions, arXiv preprint arXiv:1511.07122 (2016)
work page Pith review arXiv 2016
-
[16]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recog- nition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[17]
J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in: Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2018
2018
-
[18]
C. W. R. U. B. D. Center, Case western reserve university bearing data center dataset (cwru), accessed 2025-11-01 (2019)
2025
-
[19]
X. J. University, S. U. of Technology, Xjtu-sy bearing accelerated life test dataset, accessed 2025-11-01 (2018)
2025
-
[20]
Sehri, U
A. Sehri, U. of Ottawa, University of ottawa bearing dataset, accessed 2025-11-01 (2023)
2025
-
[21]
R. Liu, B. Yang, E. Zio, X. Chen, Artificial intelligence for fault diagnosis of rotating machinery: A review, Me- chanical Systems and Signal Processing 108 (2018) 33–47. doi:https://doi.org/10.1016/j.ymssp.2018.02.016
-
[22]
Domain-Adversarial Training of Neural Networks
Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Lavio- lette, M. Marchand, V. Lempitsky, Domain-adversarial training of neu- ral networks (2016). arXiv:1505.07818. URLhttps://arxiv.org/abs/1505.07818
work page Pith review arXiv 2016
-
[23]
B. Sun, K. Saenko, Deep coral: Correlation alignment for deep domain adaptation (2016). arXiv:1607.01719. URLhttps://arxiv.org/abs/1607.01719
work page Pith review arXiv 2016
- [24]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.