Recognition: unknown
UniVer: A Unified Perspective for Multi-step and Multi-draft Speculative Decoding
Pith reviewed 2026-05-08 16:42 UTC · model grok-4.3
The pith
UniVer unifies multi-step and multi-draft speculative decoding as a conditional optimal transport problem to raise acceptance rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
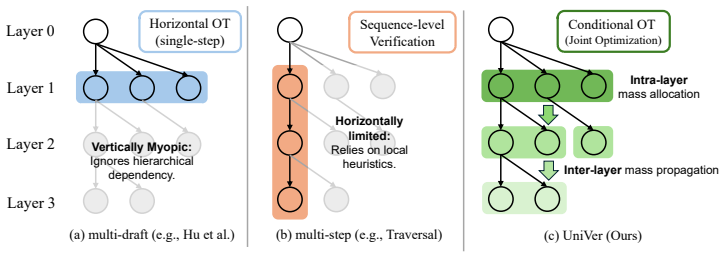
We propose a unified perspective that casts tree-based verification as a conditional OT problem. Our key insight is that vertical dependencies can be abstracted through prefix acceptance probabilities, which act as dynamic scaling factors to actively guide horizontal draft selection. Based on this principle, we introduce UniVer, a verification algorithm that jointly optimizes across tree levels by composing local optimal transport plans under prefix constraints. We prove that UniVer remains lossless and achieves the optimal acceptance rate under the proposed conditional framework.
What carries the argument
The conditional optimal transport formulation, with prefix acceptance probabilities acting as dynamic scaling factors to guide horizontal draft selection.
If this is right
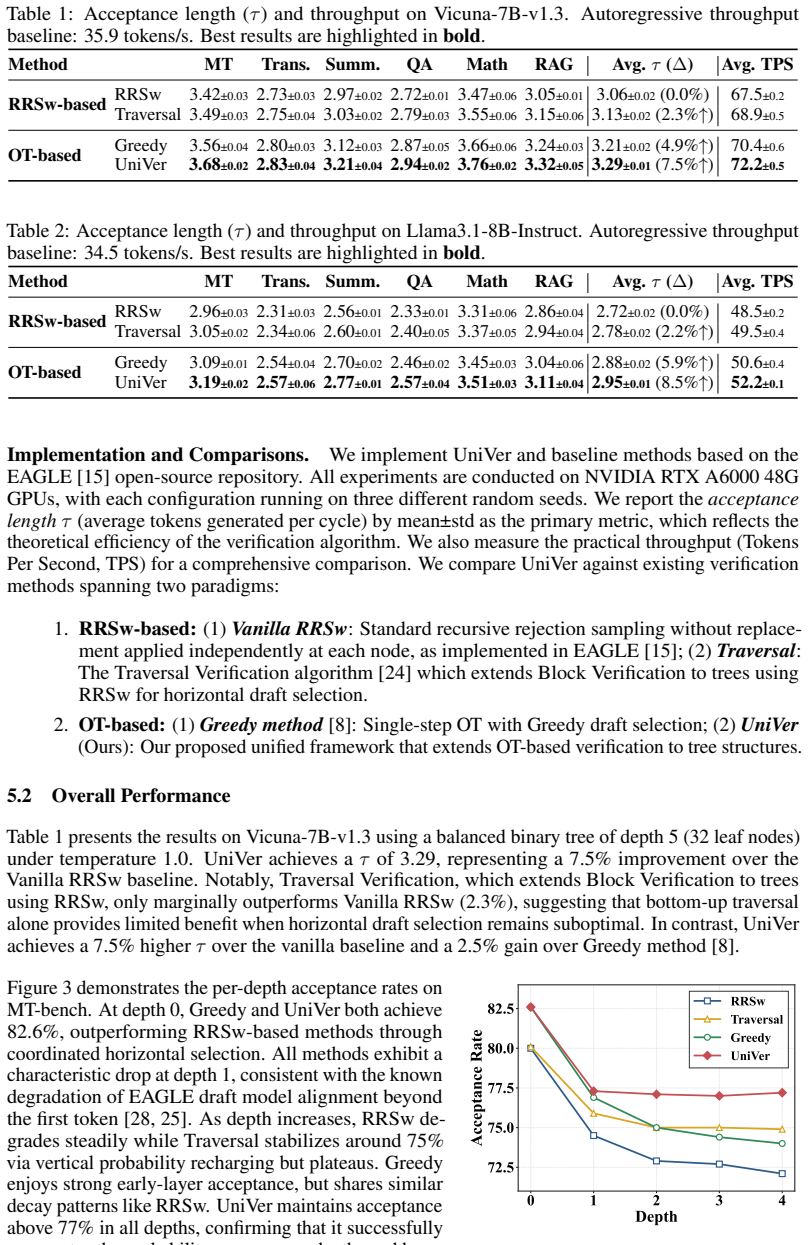
- UniVer improves acceptance length by 4.2% to 8.5% over standard recursive rejection sampling without replacement.
- It maintains exact distributional alignment with the target model.
- The method achieves the optimal acceptance rate under the conditional framework.
- Joint optimization across tree levels is enabled without loss of correctness.
Where Pith is reading between the lines
- This conditional approach could be adapted to optimize other aspects of tree-based sampling in AI generation.
- It suggests potential for combining with multi-draft strategies in different model architectures.
- Future work might test it on larger scale models to see if gains scale.
Load-bearing premise
Vertical dependencies can be abstracted through prefix acceptance probabilities, which act as dynamic scaling factors to actively guide horizontal draft selection.
What would settle it
A direct comparison on a held-out model and task where UniVer's acceptance length does not exceed that of recursive rejection sampling, or where generated samples do not match the target model's distribution.
Figures


read the original abstract
Speculative decoding accelerates Large Language Models via draft-then-verify, where verification can be framed as an Optimal Transport (OT) problem. Existing approaches typically handle multi-draft and multi-step aspects in isolation, applying either flat OT to single-step drafts or per-token rejection sampling to tree-structured candidates. This separation leaves the joint regime (where multi-step dependencies meet multi-draft branching) poorly optimized, as local verification rules fail to exploit the coupling between horizontal and vertical dimensions of candidate trees. In this paper, we propose a unified perspective that casts tree-based verification as a conditional OT problem. Our key insight is that vertical dependencies can be abstracted through prefix acceptance probabilities, which act as dynamic scaling factors to actively guide horizontal draft selection. Based on this principle, we introduce UniVer, a verification algorithm that jointly optimizes across tree levels by composing local optimal transport plans under prefix constraints. We prove that UniVer remains lossless and achieves the optimal acceptance rate under the proposed conditional framework. Extensive experiments across different tasks and models demonstrate that UniVer improves acceptance length by 4.2% to 8.5% over standard recursive rejection sampling without replacement, while maintaining exact distributional alignment with the target model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniVer, a verification algorithm for multi-step and multi-draft speculative decoding that frames tree-based verification as a conditional optimal transport (OT) problem. Vertical dependencies across tree levels are abstracted through prefix acceptance probabilities acting as dynamic scaling factors to guide horizontal draft selection. Local OT plans are composed under these prefix constraints, with a claimed proof that UniVer is lossless (maintains exact target distribution) and achieves the optimal acceptance rate. Experiments report acceptance length improvements of 4.2% to 8.5% over standard recursive rejection sampling without replacement while preserving distributional alignment.
Significance. If the proof of losslessness and optimality holds under the proposed abstraction, UniVer would supply a principled unification of multi-step and multi-draft regimes in speculative decoding. This could yield more efficient LLM inference by jointly optimizing across tree dimensions without introducing approximation error or distributional shift. The modest but consistent experimental gains suggest practical value, provided the conditional OT composition is exact.
major comments (1)
- [Conditional OT formulation and proof of optimality (Section 4)] The optimality and losslessness claims rest on the abstraction that vertical dependencies can be exactly captured by prefix acceptance probabilities as dynamic scaling factors, enabling composition of local OT plans to yield the global optimum. If acceptance at step t induces non-factorizable changes to the conditional draft distribution at t+1 (beyond simple scaling), the composition may fail to preserve both exactness and optimality simultaneously. Please provide the detailed derivation (including any lemmas on the conditional OT plans) showing why the abstraction introduces no approximation error, or a concrete argument that such interactions are absent in the tree verification setting.
minor comments (3)
- [Abstract] The abstract states improvements 'across different tasks and models' but provides no specifics on model sizes, tree depths, or task types; including these in the abstract or a summary table would clarify the scope of the 4.2%-8.5% gains.
- [Experiments] Clarify the precise implementation of the 'standard recursive rejection sampling without replacement' baseline, including how tree structures and without-replacement sampling are handled, to allow direct comparison with UniVer's joint optimization.
- [Method and Notation] Ensure that the notation for prefix acceptance probabilities and the composition of local plans is introduced consistently and used uniformly in all equations and proofs.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need for greater clarity on the conditional OT proof. We address the major comment below and are prepared to expand the derivation in the revised manuscript.
read point-by-point responses
-
Referee: [Conditional OT formulation and proof of optimality (Section 4)] The optimality and losslessness claims rest on the abstraction that vertical dependencies can be exactly captured by prefix acceptance probabilities as dynamic scaling factors, enabling composition of local OT plans to yield the global optimum. If acceptance at step t induces non-factorizable changes to the conditional draft distribution at t+1 (beyond simple scaling), the composition may fail to preserve both exactness and optimality simultaneously. Please provide the detailed derivation (including any lemmas on the conditional OT plans) showing why the abstraction introduces no approximation error, or a concrete argument that such interactions are absent in the tree verification setting.
Authors: We appreciate this observation. In the tree verification setting the acceptance decision at level t is strictly prefix-conditioned: a candidate at level t+1 is only evaluated if its prefix up to t has been accepted. Consequently the conditional draft distribution at t+1 is exactly the original proposal distribution re-weighted by the scalar prefix-acceptance probability p_accept(prefix_t). Because the tree is Markovian (each level depends only on its immediate prefix) and the verification decisions factorize given the prefix, the scaling remains multiplicative and introduces no non-factorizable cross terms. Lemma 4.2 in the manuscript shows that any local OT plan computed under this exact scaling composes to the globally optimal joint transport plan; the proof proceeds by induction on tree depth, verifying that the marginals and the cost functional are preserved at each composition step. We acknowledge that the current write-up compresses several intermediate steps and will insert the expanded derivation (including the explicit induction and the verification that the scaling equals the true conditional probability) in the revision. revision: yes
Circularity Check
No significant circularity; derivation self-contained within defined conditional OT framework
full rationale
The paper defines a conditional OT formulation by abstracting vertical dependencies via prefix acceptance probabilities, introduces UniVer as composition of local plans under those constraints, and states a proof of losslessness plus optimality within that framework. No equations or steps reduce a claimed prediction or optimality result back to a fitted parameter, self-citation, or input by construction. The abstraction and proof are presented as independent mathematical content rather than tautological renaming or load-bearing self-reference. This matches the default expectation of non-circularity for a methods paper whose central claims rest on an explicitly constructed model.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Speculative decoding verification can be framed as an Optimal Transport problem
- ad hoc to paper Vertical dependencies in candidate trees can be abstracted through prefix acceptance probabilities acting as dynamic scaling factors
Reference graph
Works this paper leans on
-
[1]
Ondrej Bojar, Christian Buck, Christian Federmann, Barry Haddow, Philipp Koehn, Johannes Leveling, Christof Monz, Pavel Pecina, Matt Post, Herve Saint-Amand, Radu Soricut, Lucia Specia, and Ales Tamchyna. 2014. Findings of the 2014 workshop on statistical machine translation. InProceedings of the Ninth Workshop on Statistical Machine Translation, WMT@ACL ...
2014
-
[2]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. 2024. Medusa: Simple LLM inference acceleration framework with multiple decoding heads. InProceedings of the International Conference on Machine Learning
2024
-
[3]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318
work page internal anchor Pith review arXiv 2023
-
[4]
Zhuoming Chen, Avner May, Ruslan Svirschevski, Yuhsun Huang, Max Ryabinin, Zhihao Jia, and Beidi Chen. 2024. Sequoia: Scalable and robust speculative decoding. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024
2024
-
[5]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168
work page internal anchor Pith review arXiv 2021
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, and 1 others
-
[7]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783
work page internal anchor Pith review arXiv
-
[8]
Zhengmian Hu and Heng Huang. 2024. Accelerated speculative sampling based on tree monte carlo. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024
2024
-
[9]
Rossi, Yihan Wu, Dinesh Manocha, and Heng Huang
Zhengmian Hu, Tong Zheng, Vignesh Viswanathan, Ziyi Chen, Ryan A. Rossi, Yihan Wu, Dinesh Manocha, and Heng Huang. 2025. Towards optimal multi-draft speculative decoding. InThe Thirteenth International Conference on Learning Representations
2025
- [10]
-
[11]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020
2020
-
[12]
Ashish J Khisti, MohammadReza Ebrahimi, Hassan Dbouk, Arash Behboodi, Roland Memisevic, and Christos Louizos. 2025. Multi-draft speculative sampling: Canonical decomposition and theoretical limits. InThe Thirteenth International Conference on Learning Representations
2025
-
[13]
Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: a benchmark for question answering research...
2019
-
[14]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast inference from transformers via speculative decoding. InProceedings of the International Conference on Machine Learning
2023
-
[15]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2024. EAGLE-2: faster inference of language models with dynamic draft trees. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024
2024
-
[16]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2024. EAGLE: speculative sampling requires rethinking feature uncertainty. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024
2024
-
[17]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2025. EAGLE-3: Scaling up inference acceleration of large language models via training-time test. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. 10
2025
-
[18]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. 2024. Specinfer: Accelerating large language model serving with tree-based speculative inference and verification. InProceedings of the 29th...
2024
-
[19]
Ramesh Nallapati, Bowen Zhou, Cícero Nogueira dos Santos, Çaglar Gülçehre, and Bing Xiang. 2016. Abstractive text summarization using sequence-to-sequence rnns and beyond. InProceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, CoNLL 2016, Berlin, Germany, August 11-12, 2016
2016
-
[20]
Ryan Sun, Tianyi Zhou, Xun Chen, and Lichao Sun. 2024. SpecHub: Provable acceleration to multi-draft speculative decoding. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
2024
-
[21]
Ziteng Sun, Uri Mendlovic, Yaniv Leviathan, Asaf Aharoni, Jae Hun Ro, Ahmad Beirami, and Ananda Theertha Suresh. 2025. Block verification accelerates speculative decoding. InThe Thirteenth International Conference on Learning Representations
2025
-
[22]
Ziteng Sun, Ananda Theertha Suresh, Jae Hun Ro, Ahmad Beirami, Himanshu Jain, and Felix X. Yu. 2023. Spectr: Fast speculative decoding via optimal transport. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023
2023
- [23]
-
[24]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, and 49 others. 2023. Llama 2: Open foundation and fine-tuned chat models
2023
-
[25]
Yepeng Weng, Qiao Hu, Xujie Chen, Li Liu, Dianwen Mei, Huishi Qiu, Jiang Tian, and Zhongchao Shi
-
[26]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
Traversal verification for speculative tree decoding. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[27]
Yepeng Weng, Dianwen Mei, Huishi Qiu, Xujie Chen, Li Liu, Jiang Tian, and Zhongchao Shi. 2025. CORAL: Learning consistent representations across multi-step training with lighter speculative drafter. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5580–5593, Vienna, Austria
2025
-
[28]
Heming Xia, Zhe Yang, Qingxiu Dong, Peiyi Wang, Yongqi Li, Tao Ge, Tianyu Liu, Wenjie Li, and Zhifang Sui. 2024. Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding. InFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024
2024
- [29]
-
[30]
Lefan Zhang, Xiaodan Wang, Yanhua Huang, and Ruiwen Xu. 2025. Learning harmonized representations for speculative sampling. InInternational Conference on Learning Representations
2025
-
[31]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.