Recognition: unknown
RangeGuard: Efficient, Bounded Approximate Error Correction for Reliable DNNs
Pith reviewed 2026-05-08 15:43 UTC · model grok-4.3
The pith
RangeGuard uses range identifiers to tolerate over 64 bit flips in DNN memory using only 16 parity bits without accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
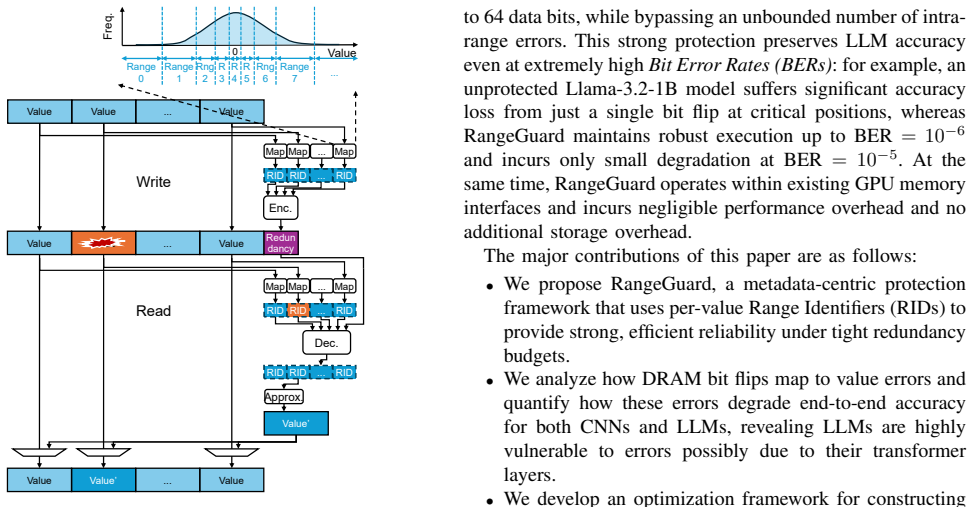
The central discovery is that by protecting the numerical range of values rather than the exact bits, RangeGuard can provide effective error correction for DNNs under tight redundancy constraints. Range Identifiers capture the range, enabling detection of harmful changes and approximate restoration that bounds error impact, leading to tolerance of many bit flips with 16-bit parity in GPU memories.
What carries the argument
Range Identifiers (RIDs) are compact metadata encoding the numerical range of each activation or weight value, used to identify and correct range-altering bit flips while tolerating intra-range noise.
Load-bearing premise
That detecting and correcting only range changes is sufficient to prevent accuracy degradation, because intra-range bit flips do not cause harmful deviations in model outputs.
What would settle it
A counterexample where substituting the representative value from the detected range causes a large accuracy loss in a tested DNN model, or where a bit flip within the same range leads to semantic change that the method misses.
Figures






read the original abstract
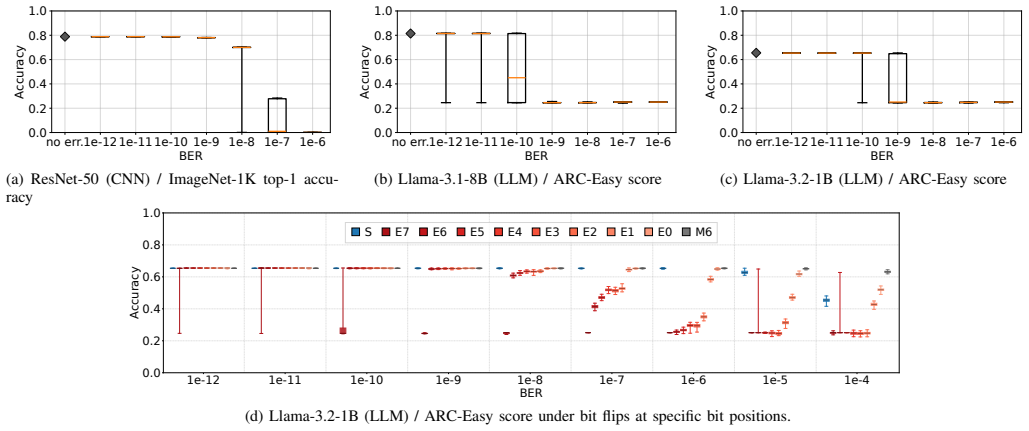
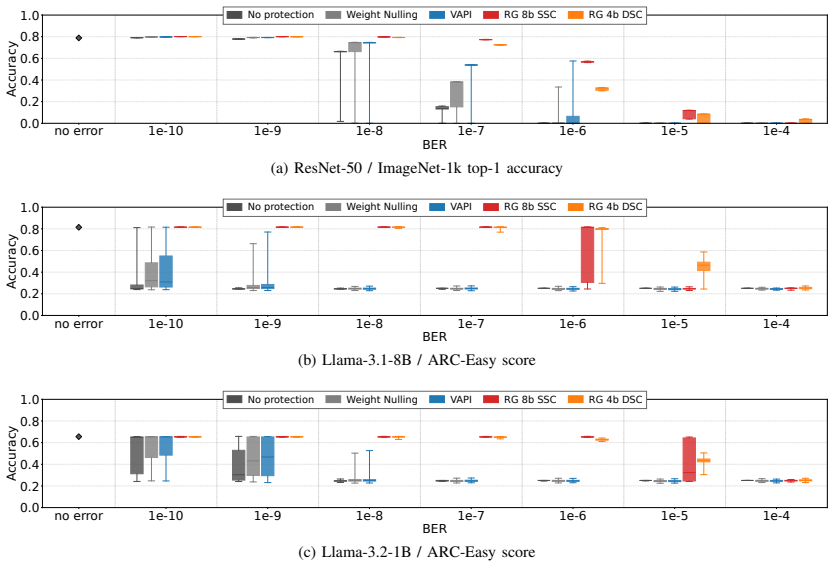
As DRAM scales in density and adopts 3D integration, raw fault rates increase and multi-bit errors are no longer rare. Such errors can severely impact Deep Neural Networks (DNNs): although DNNs tolerate small numerical perturbations, random bit flips can create extreme outliers that propagate and sharply degrade accuracy. Large Language Models (LLMs) are particularly vulnerable because attention, residual, and normalization layers can amplify and preserve a single corrupted activation across many layers, destabilizing inference. This paper introduces RangeGuard, a metadata-centric error-correcting framework that provides strong reliability and high efficiency based on bounded approximate correction. Instead of protecting raw bits, RangeGuard encodes compact Range Identifiers (RIDs) that capture the numerical range of each value. These compact metadata enable efficient use of limited redundancy and concentrate protection on range changes, which indicate harmful semantic deviations, while ignoring benign intra-range variations. Upon detecting a range change, RangeGuard restores the correct range and substitutes a representative value, ensuring that error magnitudes are bounded within the range. Based on RIDs, RangeGuard can tolerate 64+ flipped bits using only 16 bits of parity available in GPU memories without a noticeable accuracy loss. By introducing semantic range protection, RangeGuard enables reliable DNN execution even under frequent memory errors and tight redundancy budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RangeGuard, a metadata-centric approximate error correction framework for DNNs and LLMs. It encodes compact Range Identifiers (RIDs) to capture the numerical range of each activation value, enabling detection of harmful range-changing bit flips while ignoring benign intra-range variations. Upon a range change, the scheme restores the correct range using limited parity (16 bits) and substitutes a representative value from that range to bound the error magnitude. The central claim is that this approach tolerates 64+ bit flips in GPU memories with no noticeable accuracy loss by concentrating protection on semantically critical range deviations.
Significance. If the bounded substitution preserves accuracy across layers, RangeGuard would provide an efficient reliability mechanism for DNN inference on high-density, error-prone DRAM without the overhead of full ECC or retraining, addressing a practical gap as memory fault rates rise with scaling and 3D integration.
major comments (2)
- [Abstract] Abstract: the claim that 'substituting a representative value from the correct range' bounds error without degrading accuracy is load-bearing for the 64+ bit tolerance result, yet the manuscript provides no quantitative error-propagation bound or layer-wise sensitivity analysis for operations such as dot products in attention, variance in LayerNorm, or residual connections, where even intra-range magnitude shifts can accumulate.
- [Abstract and method description] The premise that 'range changes indicate harmful semantic deviations while intra-range variations are benign' (stated as the basis for RID design) is presented as an axiom without empirical validation or counter-example testing across model architectures; this directly underpins the decision to use only 16-bit parity for 64+ bit tolerance.
minor comments (2)
- Clarify the exact encoding of the 16-bit RID and how it maps to range bins, including any assumptions on value distribution.
- [Abstract] The abstract would benefit from a one-sentence statement of the RID storage and computation overhead relative to standard ECC schemes.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below and commit to revisions that will strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'substituting a representative value from the correct range' bounds error without degrading accuracy is load-bearing for the 64+ bit tolerance result, yet the manuscript provides no quantitative error-propagation bound or layer-wise sensitivity analysis for operations such as dot products in attention, variance in LayerNorm, or residual connections, where even intra-range magnitude shifts can accumulate.
Authors: We agree that a quantitative error-propagation analysis would provide stronger theoretical grounding for the bounded-substitution claim. Our evaluations rely on comprehensive end-to-end accuracy measurements across DNNs and LLMs that show no noticeable degradation under the 64+ bit-flip regime. In the revised manuscript we will add a new subsection containing a simplified propagation model for the listed operations (attention dot products, LayerNorm variance, and residual additions) together with layer-wise sensitivity results under bounded intra-range perturbations. This will directly support why the substitution strategy prevents harmful accumulation. revision: yes
-
Referee: [Abstract and method description] The premise that 'range changes indicate harmful semantic deviations while intra-range variations are benign' (stated as the basis for RID design) is presented as an axiom without empirical validation or counter-example testing across model architectures; this directly underpins the decision to use only 16-bit parity for 64+ bit tolerance.
Authors: The RID construction is motivated by prior literature on DNN robustness to small numerical noise. To address the concern directly, the revision will incorporate explicit empirical validation: controlled injection of range-changing versus intra-range errors on representative models (CNNs, Transformers, and LLMs), together with counter-example cases where intra-range shifts do or do not affect accuracy. These results will be presented in a new subsection that justifies the 16-bit parity budget and the resulting 64+ bit tolerance. revision: yes
Circularity Check
No circularity: RangeGuard derives bounded correction from newly introduced RID metadata without reduction to inputs or self-citations.
full rationale
The abstract defines RangeGuard via a new metadata scheme (compact Range Identifiers that encode numerical ranges) and a correction rule (restore range and substitute representative value on detected change). The tolerance claim follows directly from this construction and the stated assumption that range changes are the semantically critical events. No equations, fitted parameters, or prior results are invoked that would make any step equivalent to its own inputs by definition. The paper is self-contained against external benchmarks in the provided text, with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption DNNs tolerate small numerical perturbations but suffer from extreme outliers caused by bit flips.
- ad hoc to paper Range changes indicate harmful semantic deviations while intra-range variations are benign.
invented entities (1)
-
Range Identifier (RID)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
JESD79-4D: DDR4 SDRAM Standard,
JEDEC Solid State Technology Association, “JESD79-4D: DDR4 SDRAM Standard,” JEDEC, Standard, 2021
2021
-
[2]
JESD79-5C.01: DDR5 SDRAM Standard,
JEDEC Solid State Technology Association, “JESD79-5C.01: DDR5 SDRAM Standard,” JEDEC, Standard, 2024
2024
-
[3]
From correctable memory errors to uncorrectable memory errors: What error bits tell,
C. Li, Y . Zhang, J. Wang, H. Chen, X. Liu, T. Huang, L. Peng, S. Zhou, L. Wang, and S. Ge, “From correctable memory errors to uncorrectable memory errors: What error bits tell,” inInternational Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2022
2022
-
[4]
Removing obstacles before breaking through the memory wall: A close look at HBM errors in the field,
R. Wu, S. Zhou, J. Lu, Z. Shen, Z. Xu, J. Shu, K. Yang, F. Lin, and Y . Zhang, “Removing obstacles before breaking through the memory wall: A close look at HBM errors in the field,” inUSENIX Annual Technical Conference (ATC), 2024
2024
-
[5]
A 16 GB 1024 GB/s HBM3 DRAM With Source-Synchronized Bus Design and On-Die Error Control Scheme for Enhanced RAS Features,
Y . Ryu, S.-G. Ahn, J. H. Lee, J. Park, Y . K. Kim, H. Kim, Y . G. Song, H.-W. Cho, S. Cho, S. H. Song, H. Lee, U. Shin, J. Ahn, J.-M. Ryu, S. Lee, K.-H. Lim, J. Lee, J. H. Park, J.-S. Jeong, S. Joo, D. Cho, S. Y . Kim, M. Lee, H. Kim, M. Kim, J.-S. Kim, J. Kim, H. G. Kang, M.-K. Lee, S.-R. Kim, Y .-C. Kwon, Y . Y . Byun, K. Lee, S. Park, J. Youn, M.-O. K...
2023
-
[6]
Virtualized and flexible ECC for main memory,
D. H. Yoon and M. Erez, “Virtualized and flexible ECC for main memory,” inACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2010
2010
-
[7]
LOT-ECC: Localized and tiered reliability mechanisms for commodity memory systems,
A. N. Udipi, N. Muralimanohar, R. Balasubramonian, A. Davis, and N. P. Jouppi, “LOT-ECC: Localized and tiered reliability mechanisms for commodity memory systems,” inACM/IEEE International Symposium on Computer Architecture (ISCA), 2012
2012
-
[8]
Bamboo ECC: Strong, safe, and flexible codes for reliable computer memory,
J. Kim, M. Sullivan, and M. Erez, “Bamboo ECC: Strong, safe, and flexible codes for reliable computer memory,” inIEEE International Symposium on High Performance Computer Architecture (HPCA), 2015
2015
-
[9]
All-Inclusive ECC: Thorough end-to-end protection for reliable computer memory,
J. Kim, M. Sullivan, S. Lym, and M. Erez, “All-Inclusive ECC: Thorough end-to-end protection for reliable computer memory,” in ACM/IEEE International Symposium on Computer Architecture (ISCA), 2016
2016
-
[10]
Unity ECC: Unified memory protection against bit and chip errors,
D. Kim, J. Lee, W. Jung, M. B. Sullivan, and J. Kim, “Unity ECC: Unified memory protection against bit and chip errors,” inInternational Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2023
2023
-
[11]
Polynomial codes over certain finite fields,
I. S. Reed and G. Solomon, “Polynomial codes over certain finite fields,” Journal of the Society for Industrial and Applied Mathematics, 1960
1960
-
[12]
HBM (High Bandwidth Memory) DRAM Technology and Architecture,
H. Jun, J. Cho, K. Lee, H.-Y . Son, K. Kim, H. Jin, and K. Kim, “HBM (High Bandwidth Memory) DRAM Technology and Architecture,” in IEEE International Memory Workshop (IMW), 2017
2017
-
[13]
Reliability Characterization of HBM featuring HK+MG Logic Chip with Multi-stacked DRAMs,
S. Ha, S. Lee, G. Bae, D. Lee, S. Kim, B. Woo, N. Lee, Y . Lee, and S. Pae, “Reliability Characterization of HBM featuring HK+MG Logic Chip with Multi-stacked DRAMs,” inIEEE International Reliability Physics Symposium (IRPS), 2023
2023
-
[14]
Reliability Challenges in 2.5D and 3D IC Integration,
L. Li, P. Ton, M. Nagar, and P. Chia, “Reliability Challenges in 2.5D and 3D IC Integration,” inIEEE Electronic Components and Technology Conference (ECTC), 2017
2017
-
[15]
A 16-GB 640-GB/s HBM2E DRAM with a data-bus window extension technique and a synergetic on-die ECC scheme,
K. C. Chun, Y . K. Kim, Y . Ryu, J. Park, C. S. Oh, Y . Y . Byun, S. Y . Kim, D. H. Shin, J. G. Lee, B.-K. Ho, M.-S. Park, S.-J. Cho, S. Woo, B. M. Moon, B. Kil, S. Ahn, J. H. Lee, S. Y . Kim, S.-K. Choi, J.-S. Jeong, S.-G. Ahn, J. Kim, J. J. Kong, K. Sohn, N. S. Kim, and J.-B. Lee, “A 16-GB 640-GB/s HBM2E DRAM with a data-bus window extension technique a...
2020
-
[16]
High- bandwidth memory (HBM) test challenges and solutions,
H. Jun, S. Nam, H. Jin, J.-C. Lee, Y . J. Park, and J. J. Lee, “High- bandwidth memory (HBM) test challenges and solutions,”IEEE Design & Test, 2016
2016
-
[17]
13.4 A 48GB 16-High 1280GB/s HBM3E DRAM with All-Around Power TSV and a 6-Phase RDQS Scheme for TSV Area Optimization,
J. Lee, K. Cho, C. K. Lee, Y . Lee, J.-H. Park, S.-H. Oh, Y . Ju, C. Jeong, H. S. Cho, J. Lee, T.-S. Yun, J. H. Cho, S. Oh, J. Moon, Y .-J. Park, H.- S. Choi, I.-K. Kim, S. M. Yang, S.-Y . Kim, J. Jang, J. Kim, S.-H. Lee, Y . Jeon, J. Park, T.-K. Kim, D. Ka, S. Oh, J. Kim, J. Jeon, S. Kim, K. T. Kim, T. Kim, H. Yang, D. Yang, M. Lee, H. Song, D. Jang, J. ...
2024
-
[18]
Challenges of High-Capacity DRAM Stacks and Potential Directions,
A. Farmahini-Farahani, S. Gurumurthi, G. Loh, and M. Ignatowski, “Challenges of High-Capacity DRAM Stacks and Potential Directions,” inWorkshop on Memory Centric High Performance Computing, 2018
2018
-
[19]
TSV technology and challenges for 3D stacked DRAM,
C. Y . Lee, S. Kim, H. Jun, K. W. Kim, and S. J. Hong, “TSV technology and challenges for 3D stacked DRAM,” inSymposium on VLSI Technology (VLSI-Technology): Digest of Technical Papers, 2014
2014
-
[20]
Thermal Improvement of HBM with Joint Thermal Resistance Reduction for Scaling 12 Stacks and Beyond,
T. Kim, J. Lee, Y . Kim, H. Park, H. Hwang, J. Kim, H. Jung, and D. W. Kim, “Thermal Improvement of HBM with Joint Thermal Resistance Reduction for Scaling 12 Stacks and Beyond,” inIEEE Electronic Components and Technology Conference (ECTC), 2023
2023
-
[21]
A Systematic Study of DDR4 DRAM Faults in the Field,
M. V . Beigi, Y . Cao, S. Gurumurthi, C. Recchia, A. Walton, and V . Sridharan, “A Systematic Study of DDR4 DRAM Faults in the Field,” inIEEE International Symposium on High-Performance Computer Ar- chitecture (HPCA), 2023
2023
-
[22]
Predicting uncorrectable memory errors from the correctable error history: No free predictors in the field,
X. Du and C. Li, “Predicting uncorrectable memory errors from the correctable error history: No free predictors in the field,” inInternational Symposium on Memory Systems (MEMSYS), 2021
2021
-
[23]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, A. Rodriguez, A. Gregerson, A. Spataru, B. Roziere, B. Biron, B. Tang, B. Chern, C. Caucheteux, C. Nayak, C. Bi, C. Mar...
work page internal anchor Pith review arXiv 2024
-
[24]
HBM3 RAS: Enhancing resilience at scale,
S. Gurumurthi, K. Lee, M. Jang, V . Sridharan, A. Nygren, Y . Ryu, K. Sohn, T. Kim, and H. Chung, “HBM3 RAS: Enhancing resilience at scale,”IEEE Computer Architecture Letters (CAL), 2021
2021
-
[25]
A 192-Gb 12- High 896-GB/s HBM3 DRAM With a TSV Auto-Calibration Scheme and Machine-Learning-Based Layout Optimization,
M.-J. Park, H. S. Cho, T.-S. Yun, S. Byeon, Y . J. Koo, S. Yoon, D. U. Lee, S. Choi, J. Park, J. Lee, K. Cho, J. Moon, B.-K. Yoon, Y .-J. Park, S.-m. Oh, C. K. Lee, T.-K. Kim, S.-H. Lee, H.-W. Kim, Y . Ju, S.-K. Lim, S. G. Baek, K. Y . Lee, S. H. Lee, W. S. We, S. Kim, Y . Choi, S.-H. Lee, S. M. Yang, G. Lee, I.-K. Kim, Y . Jeon, J.-H. Park, J. C. Yun, C....
2022
-
[26]
Hugging Face Model Hub,
Hugging Face, “Hugging Face Model Hub,” https://huggingface.co, 2025, accessed on 2025-11-15
2025
-
[27]
JESD238A: High Band- width Memory 3 (HBM3) DRAM,
JEDEC Solid State Technology Association, “JESD238A: High Band- width Memory 3 (HBM3) DRAM,” JEDEC, Standard, 2023
2023
-
[28]
JESD270-4: High Band- width Memory 4 (HBM4) DRAM,
JEDEC Solid State Technology Association, “JESD270-4: High Band- width Memory 4 (HBM4) DRAM,” JEDEC, Standard, 2025
2025
-
[29]
NVIDIA A100 Tensor Core GPU Architecture,
NVIDIA Corporation, “NVIDIA A100 Tensor Core GPU Architecture,” NVIDIA, Tech. Rep., 2020
2020
-
[30]
Characterizing and mitigating soft errors in GPU DRAM,
M. B. Sullivan, N. Saxena, M. O’Connor, D. Lee, P. Racunas, S. Huk- erikar, T. Tsai, S. K. S. Hari, and S. W. Keckler, “Characterizing and mitigating soft errors in GPU DRAM,” inIEEE/ACM International Symposium on Microarchitecture (MICRO), 2021
2021
-
[31]
NVIDIA H100 Tensor Core GPU Architecture Whitepaper,
NVIDIA Corporation, “NVIDIA H100 Tensor Core GPU Architecture Whitepaper,” NVIDIA, Tech. Rep., 2022
2022
-
[32]
Exploiting neural networks bit- level redundancy to mitigate the impact of faults at inference,
I. Catal ´an, J. Flich, and C. Hern ´andez, “Exploiting neural networks bit- level redundancy to mitigate the impact of faults at inference,”The Journal of Supercomputing, 2025
2025
-
[33]
Robustness of neural networks against storage media errors,
M. Qin, C. Sun, and D. Vucinic, “Robustness of neural networks against storage media errors,”arXiv preprint arXiv:1709.06173, 2017
-
[34]
Value-aware parity insertion ECC for fault- tolerant deep neural network,
S.-S. Lee and J.-S. Yang, “Value-aware parity insertion ECC for fault- tolerant deep neural network,” inDesign, Automation & Test in Europe Conference & Exhibition (DATE), 2022
2022
-
[35]
PoP-ECC: Robust and flexible error correction against multi-bit upsets in DNN accelerators,
T. Park, S. Gorgin, D. Kim, J. Shin, M. B. Sullivan, and J. Kim, “PoP-ECC: Robust and flexible error correction against multi-bit upsets in DNN accelerators,” inACM/IEEE Design Automation Conference (DAC), 2025
2025
-
[36]
Terminal brain damage: Exposing the graceless degradation in deep neural net- works under hardware fault attacks,
S. Hong, P. Frigo, Y . Kaya, C. Giuffrida, and T. Dumitras ,, “Terminal brain damage: Exposing the graceless degradation in deep neural net- works under hardware fault attacks,” inUSENIX Security Symposium (USENIX Security), 2019
2019
-
[37]
Golden- Eye: A platform for evaluating emerging numerical data formats in DNN accelerators,
A. Mahmoud, T. Tambe, T. Aloui, D. Brooks, and G.-Y . Wei, “Golden- Eye: A platform for evaluating emerging numerical data formats in DNN accelerators,” inIEEE/IFIP International Conference on Dependable Systems and Networks (DSN), 2022
2022
-
[38]
Demystifying the resilience of large language model inference: An end-to-end perspective,
Y . Sun, Z. Coalson, S. Chen, H. Liu, Z. Zhang, S. Hong, B. Fang, and L. Yang, “Demystifying the resilience of large language model inference: An end-to-end perspective,” inInternational Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2025
2025
-
[39]
SwapCodes: Error codes for hardware-software cooperative GPU pipeline error detection,
M. B. Sullivan, S. K. S. Hari, B. Zimmer, T. Tsai, and S. W. Keck- ler, “SwapCodes: Error codes for hardware-software cooperative GPU pipeline error detection,” inIEEE/ACM International Symposium on Microarchitecture (MICRO), 2018
2018
-
[40]
Hardware resilience properties of text-guided image classi- fiers,
S. T. Wasim, K. H. Soboka, A. Mahmoud, S. H. Khan, D. Brooks, and G.-Y . Wei, “Hardware resilience properties of text-guided image classi- fiers,”Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[41]
A low-cost fault corrector for deep neural networks through range restriction,
Z. Chen, G. Li, and K. Pattabiraman, “A low-cost fault corrector for deep neural networks through range restriction,” inIEEE/IFIP International Conference on Dependable Systems and Networks (DSN), 2021
2021
-
[42]
DRAM fault classification through large-scale field monitoring for robust memory RAS management,
H. Chung, E. Oh, S. Baek, H. Yoon, J. Yoo, S. Lee, Y . Lee, A. Bramhanand, B. Dodds, Y . Zhou, and N. S. Kim, “DRAM fault classification through large-scale field monitoring for robust memory RAS management,” inIEEE/ACM International Symposium on Microar- chitecture (MICRO), 2025
2025
-
[43]
PyTorchFI: A runtime perturbation tool for DNNs,
A. Mahmoud, N. Aggarwal, A. Nobbe, J. R. S. Vicarte, S. V . Adve, C. W. Fletcher, I. Frosio, and S. K. S. Hari, “PyTorchFI: A runtime perturbation tool for DNNs,” inIEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), 2020
2020
-
[44]
MRFI: An open- source multiresolution fault injection framework for neural network processing,
H. Huang, C. Liu, X. Xue, B. Liu, H. Li, and X. Li, “MRFI: An open- source multiresolution fault injection framework for neural network processing,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems (TVLSI), 2024
2024
-
[45]
ReaLM: Reliable and efficient large language model inference with statistical algorithm-based fault tolerance,
T. Xie, J. Zhao, Z. Wan, Z. Zhang, Y . Wang, R. Wang, R. Huang, and M. Li, “ReaLM: Reliable and efficient large language model inference with statistical algorithm-based fault tolerance,” inACM/IEEE Design Automation Conference (DAC), 2025
2025
-
[46]
FIdelity: Efficient resilience analysis framework for deep learning accelerators,
Y . He, P. Balaprakash, and Y . Li, “FIdelity: Efficient resilience analysis framework for deep learning accelerators,” inIEEE/ACM International Symposium on Microarchitecture (MICRO), 2020
2020
-
[47]
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac’h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou, “The language model evaluation harness,” 07 2024. [Online]. Available: https://zenodo.org/re...
-
[48]
Cyclic decoding procedures for Bose-Chaudhuri- Hocquenghem codes,
R. Chien, “Cyclic decoding procedures for Bose-Chaudhuri- Hocquenghem codes,”IEEE Transactions on Information Theory (TIT), 2003
2003
-
[49]
On decoding BCH codes,
G. Forney, “On decoding BCH codes,”IEEE Transactions on Informa- tion Theory (TIT), 2003
2003
-
[50]
Efficient Berlekamp-Massey algorithm and architecture for Reed-Solomon decoder,
Z. Liang and W. Zhang, “Efficient Berlekamp-Massey algorithm and architecture for Reed-Solomon decoder,”Journal of Signal Processing Systems, 2017
2017
-
[51]
Accel-Sim: An Extensible Simulation Framework for Validated GPU Modeling,
M. Khairy, Z. Shen, T. M. Aamodt, and T. G. Rogers, “Accel-Sim: An Extensible Simulation Framework for Validated GPU Modeling,” in ACM/IEEE International Symposium on Computer Architecture (ISCA), 2020
2020
-
[52]
A characterization of the Rodinia benchmark suite with comparison to contemporary CMP workloads,
S. Che, J. W. Sheaffer, M. Boyer, L. G. Szafaryn, L. Wang, and K. Skadron, “A characterization of the Rodinia benchmark suite with comparison to contemporary CMP workloads,” inIEEE International Symposium on Workload Characterization (IISWC), 2010
2010
-
[53]
Parboil: A Revised Bench- mark Suite for Scientific and Commercial Throughput Computing,
J. A. Stratton, C. Rodrigues, I.-J. Sung, N. Obeid, L.-W. Chang, N. Anssari, G. D. Liu, and W.-m. W. Hwu, “Parboil: A Revised Bench- mark Suite for Scientific and Commercial Throughput Computing,” Center for Reliable and High-Performance Computing, 2012
2012
-
[54]
Quantizing for minimum distortion,
J. Max, “Quantizing for minimum distortion,”IRE Transactions on Information Theory, 1960
1960
-
[55]
Least squares quantization in PCM,
S. Lloyd, “Least squares quantization in PCM,”IEEE Transactions on Information Theory (TIT), 1982
1982
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.