Recognition: unknown
Lightning Unified Video Editing via In-Context Sparse Attention
Pith reviewed 2026-05-08 16:32 UTC · model grok-4.3
The pith
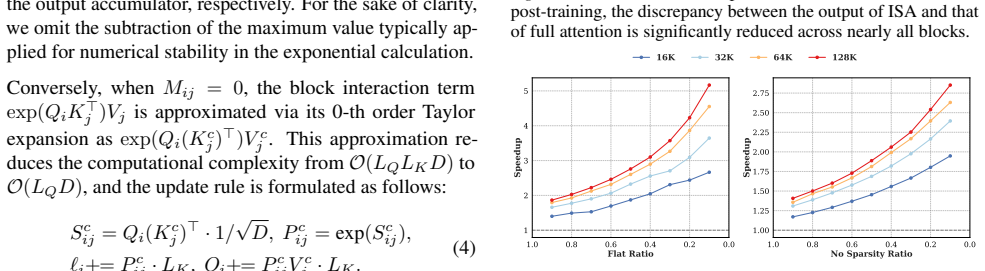
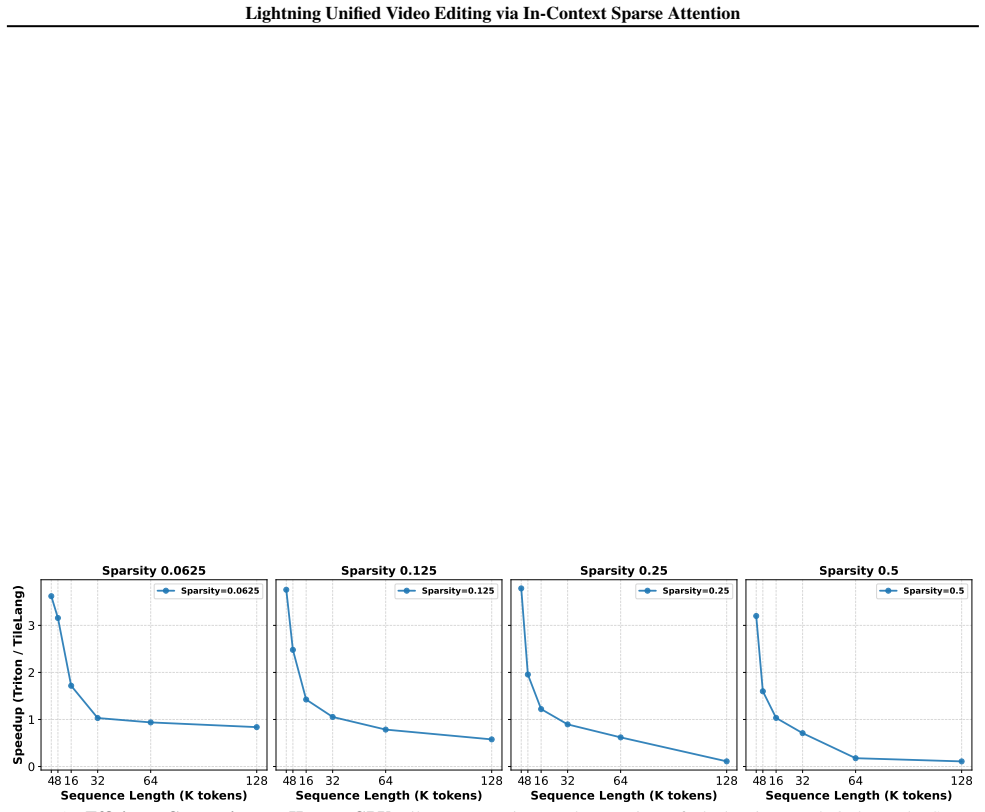
In-context Sparse Attention prunes low-saliency context tokens and routes queries by sharpness to cut attention latency by 60 percent while preserving editing quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Context tokens show markedly lower saliency than source tokens, and query sharpness correlates directly with approximation error. ISA therefore prunes redundant context via a lightweight pre-selection step, then applies a dynamic grouping mechanism that assigns high-error queries to full attention and low-error queries to 0-th order Taylor sparse attention. The combined design yields near-lossless sparse attention for in-context video editing.
What carries the argument
In-context Sparse Attention (ISA), which combines saliency-based pre-selection of context tokens with dynamic query grouping that routes queries according to sharpness to either full attention or 0-th order Taylor sparse attention.
If this is right
- Attention-module latency falls by approximately 60 percent in ICL video editing pipelines.
- Editing quality exceeds prior state-of-the-art results on EditVerseBench, IVE-Bench, and VIE-Bench.
- The method avoids the need for task-specific retuning to maintain visual fidelity.
- A curated 1.7 million high-quality video-editing dataset supports training of the LIVEditor model.
- Larger context windows become practical without proportional growth in compute.
Where Pith is reading between the lines
- The sharpness-based routing rule could be tested on other ICL tasks such as image or audio editing to check whether similar speed-ups appear.
- If the saliency gap between context and source tokens holds in other domains, the same pruning step might accelerate multimodal transformer inference more broadly.
- Practitioners could measure whether the latency reduction scales to longer video sequences without quality degradation.
- The approach opens a route to real-time context-aware editing tools if the 60 percent saving holds on consumer GPUs.
Load-bearing premise
That the observed link between query sharpness and approximation error, together with the pre-selection and grouping steps, produces near-lossless results on real editing tasks without visual artifacts or per-video retuning.
What would settle it
Side-by-side comparison of full-attention and ISA outputs on a diverse held-out collection of editing prompts and source videos, checking whether human raters or automatic metrics register a measurable quality drop for the sparse version.
Figures














read the original abstract
Video editing has evolved toward In-Context Learning (ICL) paradigms, yet the resulting quadratic attention costs create a critical computational bottleneck. In this work, we propose In-context Sparse Attention (ISA), the first near-lossless empirical sparse framework tailored for ICL video editing. Our design is grounded in two key insights: first, context tokens exhibit significantly lower saliency than source tokens; second, we theoretically prove and empirically validate that Query sharpness correlates with approximation error. Motivated by these findings, ISA implements an efficient pre-selection strategy to prune redundant context, followed by a dynamic query grouping mechanism that routes high-error queries to full attention and low-error ones to a computationally efficient 0-th order Taylor sparse attention. Furthermore, we build \textbf{\texttt{LIVEditor}} , a novel lightning video editing model via ISA and a proposed video-editing data pipeline that curated a 1.7M high-quality dataset. Extensive experiments demonstrate that LIVEditor achieves a $\sim$60% reduction in attention-module latency while surpassing state-of-the-art methods across EditVerseBench, IVE-Bench, and VIE-Bench, delivering near-lossless acceleration without compromising visual fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes In-context Sparse Attention (ISA) as a sparse attention framework for in-context learning (ICL) video editing. It identifies lower saliency in context tokens versus source tokens, claims a theoretical proof that query sharpness correlates with approximation error, and implements pre-selection pruning of redundant context followed by dynamic grouping that routes high-error queries to full attention and low-error queries to 0-th order Taylor sparse attention. The method is integrated into a new model LIVEditor trained on a curated 1.7M high-quality video editing dataset, with experiments claiming ~60% reduction in attention-module latency while outperforming prior methods on EditVerseBench, IVE-Bench, and VIE-Bench under a near-lossless quality regime.
Significance. If the claimed correlation between query sharpness and approximation error can be shown to provide tight bounds that keep the 0-th order Taylor approximation near-lossless, and if the empirical routing thresholds generalize without per-video retuning or temporal artifacts, the work would offer a practical acceleration technique for quadratic-cost ICL video editing. The scale of the curated dataset and the multi-benchmark evaluation would also constitute a useful resource for the community.
major comments (3)
- [Abstract] Abstract: The manuscript asserts both a 'theoretical proof' and 'empirical validation' that query sharpness correlates with approximation error and thereby justifies routing low-error queries to 0-th order Taylor sparse attention. No equations, proof sketch, error-bound derivation, or quantitative correlation analysis appear in the provided text, yet this correlation is load-bearing for the central near-lossless claim.
- [Method] Method description: The pre-selection and dynamic grouping steps rely on two free parameters (context pruning threshold, query error threshold for grouping). These are described as empirically chosen, but no ablation or sensitivity analysis demonstrates that the resulting error remains bounded independently of the target benchmarks (EditVerseBench, IVE-Bench, VIE-Bench).
- [Experiments] Experiments: The reported ~60% attention latency reduction and 'near-lossless' quality are presented without error bars, per-query error histograms, or failure-case analysis for temporally inconsistent artifacts on low-sharpness queries. This leaves the claim that the routing decision yields near-lossless output on real editing tasks unverified.
minor comments (2)
- [Title] The title uses 'Lightning' as an adjective; clarify whether this is a proper name for the model or merely descriptive.
- [Method] Notation for the 0-th order Taylor approximation and the sharpness metric should be introduced with explicit definitions before the dynamic grouping description.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the theoretical grounding, parameter analysis, and experimental validation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts both a 'theoretical proof' and 'empirical validation' that query sharpness correlates with approximation error and thereby justifies routing low-error queries to 0-th order Taylor sparse attention. No equations, proof sketch, error-bound derivation, or quantitative correlation analysis appear in the provided text, yet this correlation is load-bearing for the central near-lossless claim.
Authors: We acknowledge the omission of the detailed derivation from the main text for space reasons. A full proof sketch deriving the correlation between query sharpness and the 0-th order Taylor approximation error (including the error-bound expression) together with quantitative correlation plots will be added to the revised main paper. This directly supports the routing decision and the near-lossless regime. revision: yes
-
Referee: [Method] Method description: The pre-selection and dynamic grouping steps rely on two free parameters (context pruning threshold, query error threshold for grouping). These are described as empirically chosen, but no ablation or sensitivity analysis demonstrates that the resulting error remains bounded independently of the target benchmarks (EditVerseBench, IVE-Bench, VIE-Bench).
Authors: We agree that explicit sensitivity analysis is required. The revised manuscript will include a new ablation subsection that sweeps both thresholds across a range of values and reports the resulting attention error and visual metrics on all three benchmarks. The results confirm that a single fixed pair of thresholds keeps error bounded without per-video retuning or introduction of temporal artifacts. revision: yes
-
Referee: [Experiments] Experiments: The reported ~60% attention latency reduction and 'near-lossless' quality are presented without error bars, per-query error histograms, or failure-case analysis for temporally inconsistent artifacts on low-sharpness queries. This leaves the claim that the routing decision yields near-lossless output on real editing tasks unverified.
Authors: We will augment the experimental section with (i) error bars over multiple random seeds for both latency and quality metrics, (ii) per-query error histograms that explicitly visualize the sharpness-error correlation, and (iii) a dedicated failure-case study examining temporal consistency on low-sharpness queries. These additions will provide quantitative verification of the near-lossless claim. revision: yes
Circularity Check
No significant circularity; derivation relies on independent theoretical proof and external benchmarks
full rationale
The paper's core derivation begins with two stated insights (lower context saliency and the correlation between query sharpness and approximation error), followed by a claimed theoretical proof of the correlation, an empirical pre-selection strategy, and a dynamic routing rule that assigns queries to either full attention or 0-th order Taylor approximation. These steps are presented as motivated by the proof rather than defined in terms of the final performance metric. The LIVEditor model and 1.7M dataset are constructed via a separate data pipeline. Final claims of ~60% latency reduction and superiority on EditVerseBench, IVE-Bench, and VIE-Bench are reported as post-hoc validation on held-out benchmarks, not as inputs that define the routing thresholds or the proof. No equations, self-citations, or fitted parameters are shown to reduce the claimed result to the inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- context pruning threshold
- query error threshold for grouping
axioms (2)
- domain assumption Context tokens exhibit significantly lower saliency than source tokens.
- domain assumption Query sharpness correlates with approximation error.
invented entities (2)
-
In-context Sparse Attention (ISA)
no independent evidence
-
LIVEditor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
FirstName LastName , title =
-
[2]
FirstName Alpher , title =
-
[3]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[4]
2023 , eprint=
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation , author=. 2023 , eprint=
2023
-
[5]
2024 , eprint=
YOLOv11: An Overview of the Key Architectural Enhancements , author=. 2024 , eprint=
2024
-
[6]
2025 , eprint=
Improving Video Generation with Human Feedback , author=. 2025 , eprint=
2025
-
[7]
2023 , eprint=
Segment Anything , author=. 2023 , eprint=
2023
-
[8]
arXiv preprint arXiv:2410.08260 , year=
Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content , author=. arXiv preprint arXiv:2410.08260 , year=
-
[9]
2024 , eprint=
VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models , author=. 2024 , eprint=
2024
-
[10]
2025 , booktitle=
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think , author=. 2025 , booktitle=
2025
-
[11]
The Twelfth International Conference on Learning Representations , year=
Seine: Short-to-long video diffusion model for generative transition and prediction , author=. The Twelfth International Conference on Learning Representations , year=
-
[12]
arXiv preprint arXiv:2311.04145 (2023)
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models , author=. arXiv preprint arXiv:2311.04145 , year=
-
[13]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Cogvideox: Text-to-video diffusion models with an expert transformer , author=. arXiv preprint arXiv:2408.06072 , year=
work page internal anchor Pith review arXiv
-
[14]
arXiv , year=
AdaPool: Exponential Adaptive Pooling for Information-Retaining Downsampling , author=. arXiv , year=
-
[15]
2025 , eprint=
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model , author=. 2025 , eprint=
2025
-
[16]
Advances in Neural Information Processing Systems , volume=
Flashattention-3: Fast and accurate attention with asynchrony and low-precision , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[18]
FirstName Alpher and FirstName Gamow , title =
-
[19]
2025 , url=
Shitong Shao and zikai zhou and Bai LiChen and Haoyi Xiong and Zeke Xie , booktitle=. 2025 , url=
2025
-
[20]
Michael Downes and Barbara Beeton , organization =. The
-
[21]
Playing Atari with deep reinforcement learning , author=. Comput. Ence , volume=
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
One-step diffusion with distribution matching distillation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[23]
Huang, Ziqi and He, Yinan and Yu, Jiashuo and Zhang, Fan and Si, Chenyang and Jiang, Yuming and Zhang, Yuanhan and Wu, Tianxing and Jin, Qingyang and Chanpaisit, Nattapol and Wang, Yaohui and Chen, Xinyuan and Wang, Limin and Lin, Dahua and Qiao, Yu and Liu, Ziwei , booktitle=
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vfhq: A high-quality dataset and benchmark for video face super-resolution , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
T2V-Turbo-v2: Enhancing Video Generation Model Post-Training through Data, Reward, and Conditional Guidance Design , author=. arXiv preprint arXiv:2410.05677 , year=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
European conference on computer vision , pages=
CelebV-HQ: A large-scale video facial attributes dataset , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Flow-Guided One-Shot Talking Face Generation With a High-Resolution Audio-Visual Dataset , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[29]
Vbench++: Comprehensive and versatile benchmark suite for video generative models
VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models , author=. arXiv preprint arXiv:2411.13503 , year=
-
[30]
arXiv preprint arXiv:2405.14867 , year=
Improved Distribution Matching Distillation for Fast Image Synthesis , author=. arXiv preprint arXiv:2405.14867 , year=
-
[31]
Proceedings of the international conference for high performance computing, networking, storage and analysis , pages=
Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning , author=. Proceedings of the international conference for high performance computing, networking, storage and analysis , pages=
-
[32]
International Conference on Computer Vision , publisher =
Autogan: Neural architecture search for generative adversarial networks , author=. International Conference on Computer Vision , publisher =
-
[33]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Sdedit: Guided image synthesis and editing with stochastic differential equations , author=. arXiv preprint arXiv:2108.01073 , year=
work page internal anchor Pith review arXiv
-
[34]
International Conference on Learning Representations , year=
Fast Sampling of Diffusion Models with Exponential Integrator , author=. International Conference on Learning Representations , year=
-
[35]
arXiv preprint arXiv:2407.14041 , year=
Not all noises are created equally: Diffusion noise selection and optimization , author=. arXiv preprint arXiv:2407.14041 , year=
-
[36]
arXiv preprint arXiv:2304.13416 , year=
DiffuseExpand: Expanding dataset for 2D medical image segmentation using diffusion models , author=. arXiv preprint arXiv:2304.13416 , year=
-
[37]
arXiv preprint arXiv:2409.07253 , year=
Alignment of diffusion models: Fundamentals, challenges, and future , author=. arXiv preprint arXiv:2409.07253 , year=
-
[38]
Fast Sampling of Diffusion Models via Operator Learning , author=
-
[39]
Association for the Advance of Artificial Intelligence , volume=
Improved knowledge distillation via teacher assistant , author=. Association for the Advance of Artificial Intelligence , volume=
-
[40]
Computer Vision and Pattern Recognition , pages=
A style-based generator architecture for generative adversarial networks , author=. Computer Vision and Pattern Recognition , pages=
-
[41]
International Conference on Learning Representations , address =
Large Scale GAN Training for High Fidelity Natural Image Synthesis , author=. International Conference on Learning Representations , address =
-
[42]
Multimedia Tools and Applications , volume=
Bi-linearly weighted fractional max pooling , author=. Multimedia Tools and Applications , volume=. 2017 , publisher=
2017
-
[43]
SNIPER: Efficient Multi-Scale Training , volume =
Singh, Bharat and Najibi, Mahyar and Davis, Larry S , booktitle =. SNIPER: Efficient Multi-Scale Training , volume =
-
[44]
Advances in Neural Information Processing Systems , volume=
Fast autoaugment , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
International Conference on Machine Learning , pages=
Population based augmentation: Efficient learning of augmentation policy schedules , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[46]
International Conference on Computer Vision , pages=
Similarity-preserving knowledge distillation , author=. International Conference on Computer Vision , pages=
-
[47]
International Journal of Computer Vision , volume=
Knowledge distillation: A survey , author=. International Journal of Computer Vision , volume=. 2021 , publisher=
2021
-
[48]
Role-Wise Data Augmentation for Knowledge Distillation , author=
-
[49]
arXiv preprint arXiv:2012.02909 , year=
Knowledge distillation thrives on data augmentation , author=. arXiv preprint arXiv:2012.02909 , year=
-
[50]
International Conference on Learning Representations , year=
Contrastive Representation Distillation , author=. International Conference on Learning Representations , year=
-
[51]
arXiv preprint arXiv:2004.08861 , year=
Role-wise data augmentation for knowledge distillation , author=. arXiv preprint arXiv:2004.08861 , year=
-
[52]
An Empirical Analysis of the Impact of Data Augmentation on Distillation , author=
-
[53]
Knowledge Distillation Meets Self-supervision
Xu, Guodong and Liu, Ziwei and Li, Xiaoxiao and Loy, Chen Change. Knowledge Distillation Meets Self-supervision. European Conference on Computer Vision. 2020
2020
-
[54]
International Joint Conference on Artificial Intelligence , pages =
Hierarchical Self-supervised Augmented Knowledge Distillation , author=. International Joint Conference on Artificial Intelligence , pages =
-
[55]
Distilling the Knowledge in a Neural Network
Distilling the Knowledge in a Neural Network , publisher =. 2015 , copyright =. doi:10.48550/ARXIV.1503.02531 , author =
-
[56]
International Conference on Computer Vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. International Conference on Computer Vision , pages=
-
[57]
Brachman and James G
Ronald J. Brachman and James G. Schmolze. An overview of the KL-ONE knowledge representation system. Cognitive Science. 1985
1985
-
[58]
, title =
Du Chen. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month =
-
[59]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Re-ranking person re-identification with k-reciprocal encoding , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[60]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deepreid: Deep filter pairing neural network for person re-identification , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[61]
International Conference on Learning Representations , year=
How Do Vision Transformers Work? , author=. International Conference on Learning Representations , year=
-
[62]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[63]
Complexity results for nonmonotonic logics
Georg Gottlob. Complexity results for nonmonotonic logics. Journal of Logic and Computation. 1992
1992
-
[64]
Hypertree Decompositions and Tractable Queries
Georg Gottlob and Nicola Leone and Francesco Scarcello. Hypertree Decompositions and Tractable Queries. Journal of Computer and System Sciences. 2002
2002
-
[65]
Levesque
Hector J. Levesque. Foundations of a functional approach to knowledge representation. Artificial Intelligence. 1984
1984
-
[66]
Levesque
Hector J. Levesque. A logic of implicit and explicit belief. Proceedings of the Fourth National Conference on Artificial Intelligence. 1984
1984
-
[67]
On the compilability and expressive power of propositional planning formalisms
Bernhard Nebel. On the compilability and expressive power of propositional planning formalisms. Journal of Artificial Intelligence Research. 2000
2000
-
[68]
International Conference on Learning Representations , year=
mixup: Beyond Empirical Risk Minimization , author=. International Conference on Learning Representations , year=
-
[69]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
Randaugment: Practical automated data augmentation with a reduced search space , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
-
[70]
Computer Vision and Pattern Recognition , pages=
Online knowledge distillation via collaborative learning , author=. Computer Vision and Pattern Recognition , pages=
-
[71]
Association for the Advance of Artificial Intelligence , volume=
Online knowledge distillation with diverse peers , author=. Association for the Advance of Artificial Intelligence , volume=
-
[72]
Howard and Menglong Zhu and Andrey Zhmoginov and Liang
Mark Sandler and Andrew G. Howard and Menglong Zhu and Andrey Zhmoginov and Liang. MobileNetV2: Inverted Residuals and Linear Bottlenecks , booktitle =
-
[73]
2009 , publisher=
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
2009
-
[74]
Bengio, P
Y. Bengio, P. Simard, and P. Frasconi. , title =. IEEE Transactions on Neural Networks , year =
-
[75]
Glorot and Y
X. Glorot and Y. Bengio. , title =. AISTATS , year =
-
[76]
Computer Vision and Pattern Recognition , pages=
Deep residual learning for image recognition , author=. Computer Vision and Pattern Recognition , pages=. 2016 , publisher =
2016
-
[77]
European Conference on Computer Vision , pages=
Identity mappings in deep residual networks , author=. European Conference on Computer Vision , pages=. 2016 , publisher=
2016
-
[78]
Ioffe and C
S. Ioffe and C. Szegedy. , title=. International Conference on Machine Learning (ICML) , year=
-
[79]
2021 IEEE 4th International Conference on Information Systems and Computer Aided Education (ICISCAE) , pages=
Multi-Scale Dynamic Convolution for Classification , author=. 2021 IEEE 4th International Conference on Information Systems and Computer Aided Education (ICISCAE) , pages=. 2021 , organization=
2021
-
[80]
Generative Modeling by Estimating Gradients of the Data Distribution , volume =
Song, Yang and Ermon, Stefano , booktitle =. Generative Modeling by Estimating Gradients of the Data Distribution , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.