Recognition: 3 theorem links
· Lean TheoremFrom Parameter Dynamics to Risk Scoring : Quantifying Sample-Level Safety Degradation in LLM Fine-tuning
Pith reviewed 2026-05-08 18:03 UTC · model grok-4.3
The pith
Benign fine-tuning drifts LLM parameters toward danger directions, enabling per-sample risk scores via projection differences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Benign fine-tuning causes parameters to cumulatively drift toward danger-aligned directions, progressively undermining the model's safety. This finding suggests that samples contributing more to this drift has greater fine-tuning risks. SQSD quantifies the influence of each training sample on safety degradation by computing continuous risk scores from the projection difference of its induced parameter updates between danger and safety directions.
What carries the argument
Projection difference of each sample's induced parameter updates onto danger versus safety directions, which yields a continuous risk score quantifying contribution to safety degradation.
If this is right
- Samples with higher SQSD scores cause measurably greater erosion of safety behaviors when included in fine-tuning data.
- Risk scoring can be performed continuously during the fine-tuning process itself rather than only before or after.
- The method remains effective across model architectures, parameter scales, and parameter-efficient fine-tuning techniques.
- Filtering or reweighting high-risk samples identified by SQSD can reduce overall safety degradation in the resulting model.
Where Pith is reading between the lines
- The dynamic drift view implies safety could be monitored and corrected in real time during training rather than relying on static post-training checks.
- Direction-based scoring might extend to quantifying risks for other alignment properties such as truthfulness or bias beyond safety.
- If the directions prove stable across tasks, the approach could support proactive data curation to preserve multiple model behaviors at once.
Load-bearing premise
Danger-aligned and safety directions can be reliably identified in advance and remain stable enough that their projections on single-sample updates accurately measure risk.
What would settle it
If high-risk samples according to the scores produce no greater safety degradation on benchmarks than low-risk samples, or if the computed projection differences fail to correlate with observed safety loss after fine-tuning.
Figures








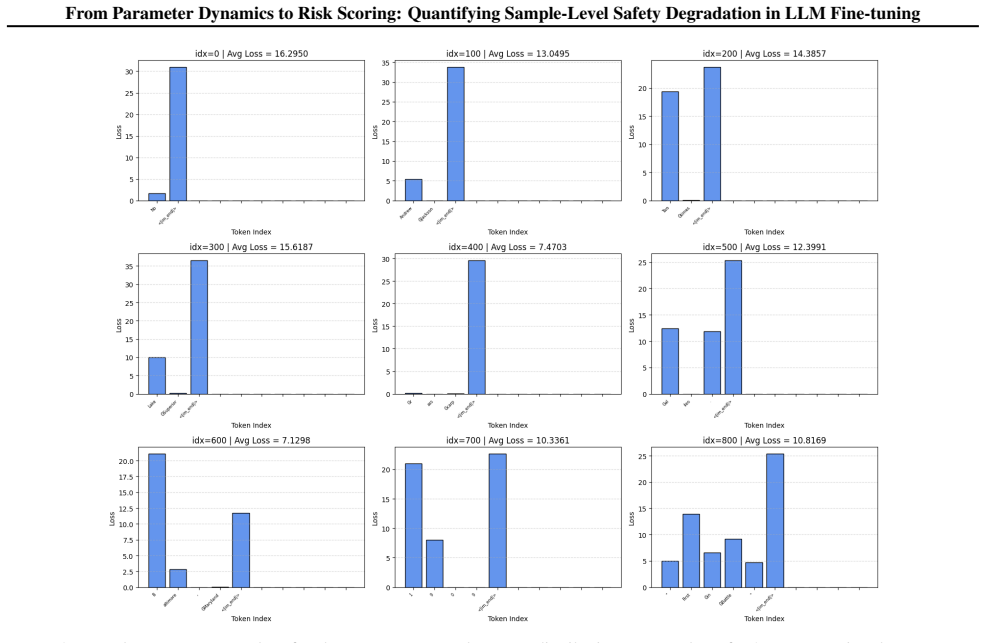
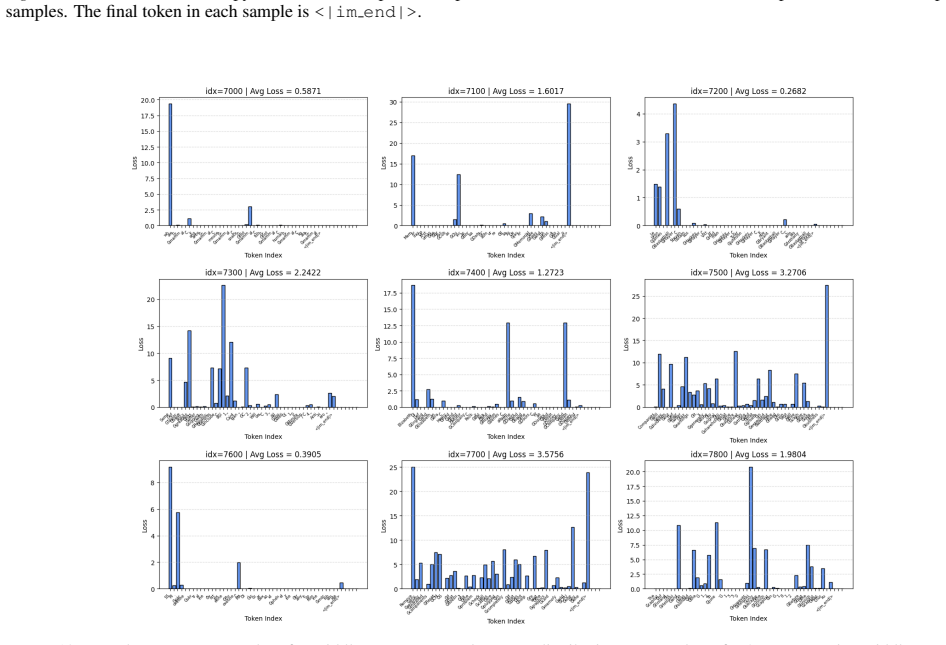
read the original abstract
Safety alignment of Large Language Models (LLMs) is extremely fragile, as fine-tuning on a small number of benign samples can erase safety behaviors learned from millions of preference examples. Existing studies attempt to explain this phenomenon by comparing parameters and hidden states before and after fine-tuning, but overlook their dynamic evolution during fine-tuning. In this paper, we uncover a critical mechanism underlying safety degradation by analyzing parameter dynamics, where benign fine-tuning causes parameters to cumulatively drift toward danger-aligned directions, progressively undermining the model's safety. This finding suggests that samples contributing more to this drift has greater fine-tuning risks. Based on this insight, we propose a method of Sample-Level Quantification of Safety Degradation (SQSD), which quantifies the influence of each training sample on safety degradation. Specifically, SQSD computes continuous risk scores to samples by measuring their induced parameter updates' projection difference between danger and safety directions. Extensive experiments across multiple models and datasets demonstrate that SQSD effectively quantifies sample-level fine-tuning risks and exhibits strong transferability across model architectures, parameter scales, and parameter-efficient methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that benign fine-tuning on LLMs induces cumulative parameter drift toward danger-aligned directions, progressively eroding safety. It introduces Sample-Level Quantification of Safety Degradation (SQSD), which assigns continuous risk scores to individual training samples by measuring the projection difference of each sample's induced parameter update onto danger versus safety directions. Experiments across multiple models, datasets, and parameter-efficient methods are reported to show that SQSD quantifies fine-tuning risks effectively and transfers across architectures and scales.
Significance. If the danger and safety directions can be shown to be defined independently of the fine-tuning data and trajectories, and if the projection-difference scores are demonstrated to be predictive rather than post-hoc, the work would provide a concrete, sample-level diagnostic for safety degradation that goes beyond static before/after comparisons. This could inform safer fine-tuning practices and sample selection in alignment pipelines.
major comments (2)
- [SQSD method definition] The central SQSD construction (described in the method section following the parameter-dynamics analysis) defines risk via projection differences onto danger-aligned and safety directions. The manuscript must specify exactly how these directions are extracted (e.g., contrastive gradients, PCA on hidden states, or fixed reference prompts) and must prove that the extraction uses only data or model states disjoint from the fine-tuning runs and samples being scored. Any overlap renders the metric circular by construction, undermining the claim that SQSD quantifies 'influence' or 'risk' rather than recovering the direction definition itself.
- [Experiments and transferability results] The abstract and experimental claims assert 'strong transferability' and 'continuous risk scores' that track progressive safety degradation. However, the manuscript does not appear to test whether the fixed initial directions remain stationary as fine-tuning rotates the effective subspace; if projections are taken only onto the initial directions, cumulative drift may invalidate the scores after the first few epochs. A direct check (e.g., recomputing directions at intermediate checkpoints and measuring rank correlation of per-sample scores) is required to support the dynamic-drift narrative.
minor comments (2)
- Notation for the projection operator and the danger/safety direction vectors should be introduced with explicit equations and kept consistent between the method description and the experimental figures.
- The abstract states that 'samples contributing more to this drift has greater fine-tuning risks'; the grammar and the precise causal link between drift contribution and downstream safety violation should be clarified.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important aspects of methodological clarity and empirical validation that we have addressed through targeted revisions. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [SQSD method definition] The central SQSD construction (described in the method section following the parameter-dynamics analysis) defines risk via projection differences onto danger-aligned and safety directions. The manuscript must specify exactly how these directions are extracted (e.g., contrastive gradients, PCA on hidden states, or fixed reference prompts) and must prove that the extraction uses only data or model states disjoint from the fine-tuning runs and samples being scored. Any overlap renders the metric circular by construction, undermining the claim that SQSD quantifies 'influence' or 'risk' rather than recovering the direction definition itself.
Authors: We appreciate this clarification request. In the revised manuscript we have expanded the method section (now Section 3.2) to state explicitly that safety and danger directions are obtained via contrastive gradients on a fixed collection of reference prompts drawn from established safety benchmarks. These reference prompts are drawn from a held-out pool that shares no samples or trajectories with any fine-tuning dataset used in the reported experiments. We have added a short formal argument (new Appendix C) showing that the direction vectors are computed solely from this disjoint reference set, thereby eliminating circularity and confirming that SQSD measures genuine per-sample influence on the observed drift. revision: yes
-
Referee: [Experiments and transferability results] The abstract and experimental claims assert 'strong transferability' and 'continuous risk scores' that track progressive safety degradation. However, the manuscript does not appear to test whether the fixed initial directions remain stationary as fine-tuning rotates the effective subspace; if projections are taken only onto the initial directions, cumulative drift may invalidate the scores after the first few epochs. A direct check (e.g., recomputing directions at intermediate checkpoints and measuring rank correlation of per-sample scores) is required to support the dynamic-drift narrative.
Authors: We agree that stationarity of the reference directions merits explicit verification. Although the core narrative concerns cumulative drift from the initial state, we have added a new subsection (Section 4.4) containing the requested check: directions are recomputed at multiple intermediate checkpoints, and rank correlations of the resulting per-sample SQSD scores are reported. The observed Spearman correlations remain high (average ρ > 0.75 across models and epochs), indicating that projections onto the initial directions continue to track the drift trajectory. These results have been incorporated to strengthen the transferability claims. revision: yes
Circularity Check
No circularity: directions derived from observed dynamics; SQSD is a downstream quantification, not a tautology.
full rationale
The paper first analyzes the full fine-tuning trajectory to identify cumulative parameter drift toward danger-aligned directions (an empirical observation across the run). SQSD then applies a projection-difference metric to individual sample updates using those directions. This is a standard post-hoc attribution step rather than a self-referential definition: the directions are not fitted to the per-sample risk scores, nor are the risk scores used to define the directions. No equation reduces the output risk score to the input by algebraic identity or by re-using the same fitted parameters. The method remains falsifiable against held-out samples or external safety benchmarks. No self-citation load-bearing step or ansatz smuggling appears in the provided derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Danger-aligned and safety directions exist and can be identified from model parameters or gradients.
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.LogicAsFunctionalEquation (J = ½(x+x⁻¹)−1 uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Vsafety = θ̂aligned − θ0, Vdanger = θ̂harmful − θ0 (task-vector formulation via DPO/SFT on safety datasets).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y ., Jones, A., Ndousse, K., Askell, A., Chen, A., Das- Sarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with rein- forcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022a. Bai, Y ., Jones, A., Ndousse, K., Askell, A., Chen, A., Das- Sarma, N., Drain, D., Fort, S., Gangu...
-
[3]
Chen, P.-Y ., Shen, H., Das, P., and Chen, T. Fundamental safety-capability trade-offs in fine-tuning large language models.arXiv preprint arXiv:2503.20807,
-
[4]
Ghosh, S., Varshney, P., Galinkin, E., and Parisien, C. Aegis: Online adaptive ai content safety moderation with ensem- ble of llm experts.arXiv preprint arXiv:2404.05993,
-
[5]
Benign samples matter! fine-tuning on outlier benign samples severely breaks safety
Guan, Z., Hu, M., Zhu, R., Li, S., and Vullikanti, A. Benign samples matter! fine-tuning on outlier benign samples severely breaks safety. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025,
2025
-
[6]
He, L., Xia, M., and Henderson, P. What is in your safe data? identifying benign data that breaks safety.arXiv preprint arXiv:2404.01099,
-
[7]
Hsiung, L., Pang, T., Tang, Y .-C., Song, L., Ho, T.-Y ., Chen, P.-Y ., and Yang, Y . Why llm safety guardrails collapse after fine-tuning: A similarity analysis be- tween alignment and fine-tuning datasets.arXiv preprint arXiv:2506.05346,
-
[8]
T., Wortsman, M., Schmidt, L., Hajishirzi, H., and Farhadi, A
Ilharco, G., Ribeiro, M. T., Wortsman, M., Schmidt, L., Hajishirzi, H., and Farhadi, A. Editing models with task arithmetic. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023,
2023
-
[9]
Fine-tuning and utilization methods of domain- specific llms.arXiv preprint arXiv:2401.02981,
Jeong, C. Fine-tuning and utilization methods of domain- specific llms.arXiv preprint arXiv:2401.02981,
-
[10]
Li, G., Chen, K., Guo, S., Zhang, J., Qiu, H., Zhang, C., Wang, G., Zhang, T., and Li, J. Picky llms and unreliable rms: An empirical study on safety alignment after instruc- tion tuning.arXiv preprint arXiv:2502.01116, 2025a. Li, H., Li, L., Lu, Z., Wei, X., Li, R., Shao, J., and Sha, L. Layer-aware representation filtering: Purifying finetuning data to ...
-
[11]
URLhttps://arxiv.org/abs/2407.21783. Lu, W., Luu, R. K., and Buehler, M. J. Fine-tuning large language models for domain adaptation: Exploration of training strategies, scaling, model merging and synergis- tic capabilities.npj Computational Materials, 11(1):84,
work page internal anchor Pith review arXiv
-
[12]
S., Simko, S., Pelrine, K., and Jin, Z
Pandey, P. S., Simko, S., Pelrine, K., and Jin, Z. Accidental misalignment: Fine-tuning language models induces un- expected vulnerability.arXiv preprint arXiv:2505.16789,
-
[13]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Qi, X., Zeng, Y ., Xie, T., Chen, P.-Y ., Jia, R., Mittal, P., and Henderson, P. Fine-tuning aligned language models compromises safety, even when users do not intend to! arXiv preprint arXiv:2310.03693,
work page internal anchor Pith review arXiv
-
[14]
Qian, C., Zhang, J., Yao, W., Liu, D., Yin, Z., Qiao, Y ., Liu, Y ., and Shao, J. Towards tracing trustworthiness dy- namics: Revisiting pre-training period of large language models.arXiv preprint arXiv:2402.19465,
-
[15]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review arXiv
-
[16]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review arXiv
-
[17]
B., and Kang, D
Zhan, Q., Fang, R., Bindu, R., Gupta, A., Hashimoto, T. B., and Kang, D. Removing rlhf protections in gpt-4 via fine-tuning. InProceedings of the 2024 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 2: Short Papers), pp. 681–687,
2024
-
[18]
Table 5 presents the top-5 high-sensitivity parameter states for different models and danger directions. E.3. Initialization States for Main Experiments Our main experiments (§6.3) evaluate SQSD across 12 configurations: 3 models (Qwen3-8B, Llama-3.1-8B-Instruct, Llama-2-7B-Chat) × 2 datasets (Dolly, Alpaca) × 2 danger-safety direction pairs. For each con...
1958
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.