Recognition: unknown
Benchmarking POS Tagging for the Tajik Language: A Comparative Study of Neural Architectures on the TajPersParallel Corpus
Pith reviewed 2026-05-08 16:29 UTC · model grok-4.3
The pith
mBERT with LoRA achieves the highest scores in the first POS tagging benchmark for Tajik on isolated dictionary words.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
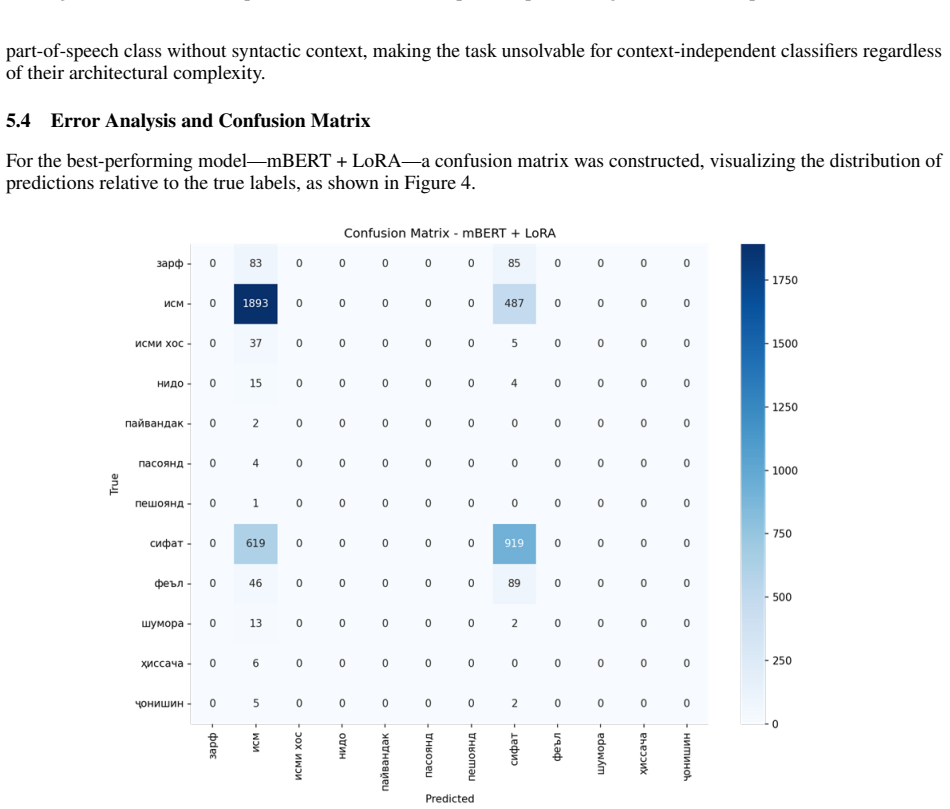
The study presents the first systematic comparison of neural architectures for Tajik POS tagging, including BiLSTM-CRF and multilingual transformers like mBERT, XLM-RoBERTa, ParsBERT, and ruBERT, all adapted with LoRA on the TajPersParallel corpus of isolated lexical units. Results indicate that mBERT + LoRA yields the highest scores with macro F1 of 0.11 and weighted F1 of 0.62. Models excel at common classes such as nouns and adjectives but fail entirely on rare function words, and zero-shot tests confirm greater similarity to Persian and Russian.
What carries the argument
Comparative evaluation of recurrent and transformer models with parameter-efficient LoRA fine-tuning applied to context-independent lexical classification for Tajik POS tagging.
If this is right
- The mBERT + LoRA combination provides the strongest baseline for Tajik POS tagging among tested models.
- Absence of syntactic context causes all models to struggle with resolving morphological ambiguities.
- High-frequency classes like noun and adjective are classified reliably while rare classes see zero performance.
- Zero-shot results suggest Tajik is typologically closest to Persian and Russian among the evaluated languages.
- The benchmark establishes a starting point for future development of Tajik language processing systems.
Where Pith is reading between the lines
- Expanding the corpus with full sentences would likely improve model performance by providing necessary context for disambiguation.
- Further adaptation techniques or larger training data from related languages could address the low macro F1 scores.
- Similar benchmarking approaches may apply to other under-resourced languages using dictionary resources.
- Integration of these models into practical Tajik NLP applications would require handling the observed class imbalances.
Load-bearing premise
That performing POS tagging on isolated lexical units from a dictionary corpus without sentences is a valid and informative proxy for real-world Tajik grammatical analysis.
What would settle it
Evaluating the same models on a corpus of Tajik sentences with full syntactic context and observing whether weighted F1 scores substantially exceed 0.62 or macro F1 rises above 0.11 would test the claim.
Figures




read the original abstract
This paper presents the first benchmark for the task of automatic part-of-speech (POS) tagging for the Tajik language. Despite the existence of multilingual language models demonstrating high effectiveness for many of the world's languages, their capacity for grammatical analysis of Tajik has remained unexplored until now. The aim of this study is to fill this gap through a systematic comparison of classical neural network architectures and modern multilingual transformers. Experiments were conducted on the TajPersParallel corpus, a parallel lexical resource comprising approximately 44,000 dictionary entries. Due to the absence of full-fledged example sentences in the current version of the corpus, the task was performed at the level of isolated lexical units, representing a challenging case of context-independent classification. The study compares the following architectures: a recurrent BiLSTM-CRF model, as well as multilingual models XLM-RoBERTa (large), mBERT, ParsBERT (Persian), and ruBERT (Russian), adapted using the parameter-efficient fine-tuning method LoRA. The testing results showed that the best performance is achieved by the mBERT + LoRA model (macro F1-score = 0.11, weighted F1-score = 0.62). It was established that in the absence of syntactic context, all models experience significant difficulty in resolving morphological ambiguity, successfully classifying primarily high-frequency classes ("noun," "adjective") while demonstrating zero effectiveness for rare function words. Zero-shot evaluation revealed the greatest typological proximity of Tajik to Persian (ParsBERT) and Russian (ruBERT). The obtained results form a foundation for further research and development in the field of automatic processing of the Tajik language.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to deliver the first benchmark for automatic POS tagging in Tajik by evaluating BiLSTM-CRF and several LoRA-adapted multilingual transformers (XLM-RoBERTa large, mBERT, ParsBERT, ruBERT) on the TajPersParallel corpus of ~44k dictionary entries. Because the corpus lacks example sentences, the task is reduced to context-independent classification of isolated lexical units; the headline result is that mBERT+LoRA achieves the highest scores (macro F1 = 0.11, weighted F1 = 0.62), with all models struggling on rare function words and zero-shot results indicating closest typological proximity to Persian and Russian.
Significance. If the proxy task is accepted as informative, the work supplies the first quantitative baseline for Tajik grammatical analysis and usefully identifies mBERT+LoRA as strongest while documenting the expected difficulty of context-free morphological disambiguation. The zero-shot cross-lingual findings also offer a modest typological signal. These contributions are modest in scope but could seed future sentence-level resources for Tajik NLP.
major comments (3)
- [Abstract] Abstract and Introduction: The central claim that the study constitutes 'the first benchmark for the task of automatic part-of-speech tagging for the Tajik language' is undermined by the explicit reduction to isolated lexical-unit classification. Standard POS tagging is a sequence-labeling problem whose primary difficulty is contextual disambiguation; the reported macro F1 of 0.11 versus weighted F1 of 0.62, together with zero recall on rare function words, is the signature of majority-class prediction on an imbalanced lexicon rather than evidence about model capacity for Tajik grammar.
- [Methodology] Methodology and Results sections: No train/test splits, hyperparameter settings, cross-validation procedure, or statistical significance tests are described for the reported F1 scores. Without these details the numerical comparison (including the claim that mBERT+LoRA is best) cannot be reproduced or evaluated for robustness.
- [Results] Results and Discussion: The zero-shot evaluation is presented as evidence of 'typological proximity' to Persian and Russian, yet the paper provides no quantitative measure (e.g., confusion matrices or per-class transfer gaps) to support this interpretation beyond the headline F1 numbers.
minor comments (2)
- [Abstract] The abstract should more prominently foreground the context-free limitation when stating the headline result rather than relegating it to a single sentence.
- [Results] Table captions and axis labels in the results figures should explicitly note that evaluation is performed on isolated dictionary entries, not sentences.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the current work is a proxy task on isolated lexical units rather than full contextual POS tagging, and that additional methodological details and quantitative support are needed. We will revise the manuscript to clarify the scope, add the missing experimental details, and strengthen the analysis of zero-shot results. Point-by-point responses are provided below.
read point-by-point responses
-
Referee: [Abstract] Abstract and Introduction: The central claim that the study constitutes 'the first benchmark for the task of automatic part-of-speech tagging for the Tajik language' is undermined by the explicit reduction to isolated lexical-unit classification. Standard POS tagging is a sequence-labeling problem whose primary difficulty is contextual disambiguation; the reported macro F1 of 0.11 versus weighted F1 of 0.62, together with zero recall on rare function words, is the signature of majority-class prediction on an imbalanced lexicon rather than evidence about model capacity for Tajik grammar.
Authors: We acknowledge that the task performed is context-independent classification of dictionary entries rather than sequence labeling with syntactic context, and that the low macro F1 (0.11) and struggles with rare function words reflect class imbalance and the absence of disambiguation cues. The TajPersParallel corpus in its current form contains only isolated lexical units without sentences, making full contextual POS tagging impossible at this stage. We will revise the abstract and introduction to explicitly frame the contribution as the first benchmark for context-free POS tagging on Tajik lexical units, while discussing the limitations for grammatical analysis and the value of this initial quantitative baseline for a low-resource language. revision: yes
-
Referee: [Methodology] Methodology and Results sections: No train/test splits, hyperparameter settings, cross-validation procedure, or statistical significance tests are described for the reported F1 scores. Without these details the numerical comparison (including the claim that mBERT+LoRA is best) cannot be reproduced or evaluated for robustness.
Authors: We agree that these details are required for reproducibility and fair evaluation of model comparisons. In the revised manuscript we will add a new subsection detailing the 80/10/10 train/validation/test split, all hyperparameter values (including LoRA rank, alpha, learning rate, and epochs for each architecture), the training procedure, and the use of 5-fold cross-validation. We will also report statistical significance tests (e.g., paired t-tests or McNemar’s test) on the F1 differences to support the claim that mBERT+LoRA performs best. revision: yes
-
Referee: [Results] Results and Discussion: The zero-shot evaluation is presented as evidence of 'typological proximity' to Persian and Russian, yet the paper provides no quantitative measure (e.g., confusion matrices or per-class transfer gaps) to support this interpretation beyond the headline F1 numbers.
Authors: The zero-shot results show comparatively higher weighted F1 for ParsBERT and ruBERT, which we interpret as a signal of typological proximity. To provide stronger quantitative support we will add per-class F1 scores across models and confusion matrices for the zero-shot setting in the revised Results section, along with explicit discussion of per-class transfer gaps. This will allow readers to evaluate the typological claim more rigorously. revision: partial
Circularity Check
Purely empirical benchmarking with no derivations or self-referential reductions
full rationale
The paper performs a direct experimental comparison of neural models on a fixed corpus of ~44k isolated dictionary entries, reporting macro and weighted F1 scores as model outputs on held-out data. No equations, parameter fits, uniqueness theorems, or predictions are claimed; the central results are simply the observed performance numbers of mBERT+LoRA and baselines. The task definition (context-independent classification) is stated explicitly in the abstract and does not reduce to any fitted input or self-citation. This is standard empirical benchmarking whose validity can be assessed externally against the stated proxy, but the reported numbers do not circularly presuppose themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of supervised classification apply to context-free word-level POS tagging
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-04-09
URLhttps://aclanthology.org/ 2020.acl-main.747/. Accessed: 2026-04-09. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techno...
2020
-
[2]
URLhttps://doi.org/10.1007/ s11063-021-10528-4. Y. Kuratov and M. Arkhipov. Adaptation of deep bidirectional multilingual transformers for Russian language. In Proceedings of the Dialogue 2019 Conference, pages 333–339, Moscow,
2019
-
[3]
ru/media/4281/kuratovy.pdf
URLhttps://www.dialog-21. ru/media/4281/kuratovy.pdf. Accessed: 2026-04-09. E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. In10th International Conference on Learning Representations (ICLR 2022), Virtual,
2026
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
URL https://arxiv.org/abs/2106.09685. Accessed: 2026-04-09. I. M. Oranskii.Introduction to Iranian Philology. Nauka, Moscow, 2nd, enlarged edition,
work page internal anchor Pith review arXiv 2026
-
[5]
EDN LQLURB. S. Jafari, F. Farsi, N. Ebrahimi, M. B. Sajadi, and S. Eetemadi. DadmaTools V2: An adapter-based natural language processing toolkit for the Persian language. InProceedings of the 1st Workshop on NLP for Languages Using Arabic Script (AbjadNLP 2025), pages 37–43, Abu Dhabi, UAE,
2025
-
[6]
Association for Computational Linguistics. M. K. Arabov. TajPersLexon: A Tajik–Persian lexical resource and hybrid model for cross-script low-resource NLP. In The Proceedings of the First Workshop on NLP and LLMs for the Iranian Language Family (SilkRoadNLP 2026), pages 29–37, Rabat, Morocco, 2026a. Association for Computational Linguistics. R. Etezadi, M...
2026
-
[7]
Association for Computational Linguistics. S. Jafari, V. Hoste, E. Lefever, T. Azin, F. Roodi, Z. Dehghani Tafti, S. Bali, et al. APARSIN: A multi-variety sentiment and translation benchmark for Iranic languages. InThe Proceedings of the First Workshop on NLP and LLMs for the Iranian Language Family (SilkRoadNLP 2026), pages 83–97, Rabat, Morocco,
2026
-
[8]
Accessed: 2026-04-05
URL https://www.dslib.net/math-mod/ matematicheskie-osnovy-avtomatizirovannoj-tadzhiksko-persidskoj-konversii.html. Accessed: 2026-04-05. (In Russian). R. Merchant and K. Tang. ParsText: A digraphic corpus for Tajik-Farsi transliteration. InProceedings of the Second Workshop on Computation and Written Language (CAWL) @ LREC-COLING 2024, pages 1–7, Torino, Italia,
2026
-
[9]
ELRA and ICCL. M. A. SadraeiJavaheri, E. Asgari, and H. R. Rabiee. Transformers for bridging Persian dialects: Transliteration model forTajikandIranianscripts. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 16770–16775, Torino, Italia,
2024
-
[10]
ELRA and ICCL. R. Merchant and K. Tang. ParsTranslit: Truly versatile Tajik-Farsi transliteration. InFindings of the Association for Computational Linguistics: EACL 2026, pages 1431–1443, Rabat, Morocco,
2026
-
[11]
Mullosharaf K
Association for Computational Linguistics. Mullosharaf K. Arabov. A systematic benchmark of machine transliteration models for the Tajik-Farsi language pair: A comparative study from rule-based to transformer architectures, 2026b. URLhttps://arxiv.org/abs/2605. 02270. A. M. Kurbonovich. Character-level transformer for Tajik–Persian transliteration with a ...
2026
-
[12]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N
Association for Computational Linguistics. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems 30 (NIPS 2017), pages 5998–6008,
2017
-
[13]
URLhttps://papers.nips.cc/paper_files/paper/2017/hash/ 3f5ee243547dee91fbd053c1c4a845aa-Abstract.html. D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate. In 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA,
2017
-
[14]
Neural Machine Translation by Jointly Learning to Align and Translate
URL https://arxiv.org/abs/1409.0473. Accessed: 2026-04-09. TajikNLPWorld. TajikNLPWorld profile on Hugging Face. Hugging Face,
work page internal anchor Pith review arXiv 2026
-
[15]
Accessed: 2026-04-05
URLhttps://huggingface.co/ TajikNLPWorld. Accessed: 2026-04-05. 10
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.