Recognition: unknown
DiCLIP: Diffusion Model Enhances CLIP's Dense Knowledge for Weakly Supervised Semantic Segmentation
Pith reviewed 2026-05-08 18:29 UTC · model grok-4.3
The pith
Diffusion model integration refines CLIP features for superior weakly supervised segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DiCLIP enhances CLIP's dense knowledge across visual and text modalities by leveraging a diffusion model's generative capabilities. The Visual Correlation Enhancement module employs Attention Clustering Refinement to extract diverse correlation maps that bias CLIP's self-attention toward more discriminative distributions, addressing over-smoothing. The Text Semantic Augmentation module uses diffusion to maintain a dynamic key-value cache, transforming CAM generation into a visual knowledge retrieval process that better captures category variability.
What carries the argument
Visual Correlation Enhancement (VCE) with Attention Clustering Refinement (ACR) and Text Semantic Augmentation (TSA) with dynamic key-value cache, which transfer spatial consistency and generative power from the diffusion model to CLIP.
If this is right
- Achieves higher segmentation accuracy than previous state-of-the-art methods on PASCAL VOC and MS COCO datasets.
- Reduces the training costs associated with weakly supervised semantic segmentation.
- Improves the quality of class activation maps by mitigating over-smoothing in attention mechanisms.
- Enables a shift from simple patch-text matching to a more robust visual knowledge retrieval paradigm for dense predictions.
Where Pith is reading between the lines
- The method's reliance on diffusion models suggests potential applicability to other dense prediction tasks where vision-language models lack spatial precision.
- Extending the dynamic cache idea could support online adaptation to new visual categories without full retraining.
- Future work might test whether similar enhancements work with alternative generative models to reduce dependency on diffusion specifically.
Load-bearing premise
The spatial consistency and generative abilities of the diffusion model can be effectively transferred to CLIP's visual and text features without causing new artifacts or instability in the segmentation process.
What would settle it
Evaluating the full DiCLIP pipeline on the PASCAL VOC validation set and checking whether the mean intersection over union score surpasses current leading methods while measuring a reduction in GPU hours used for training.
Figures









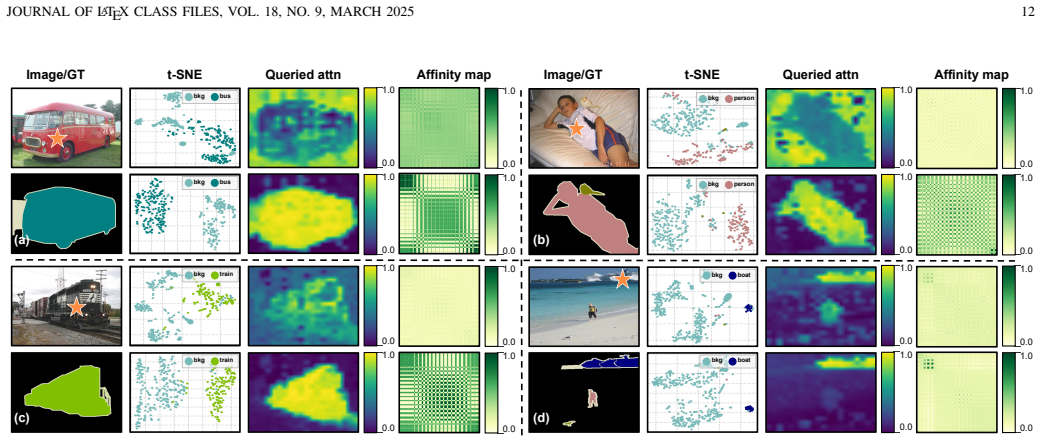
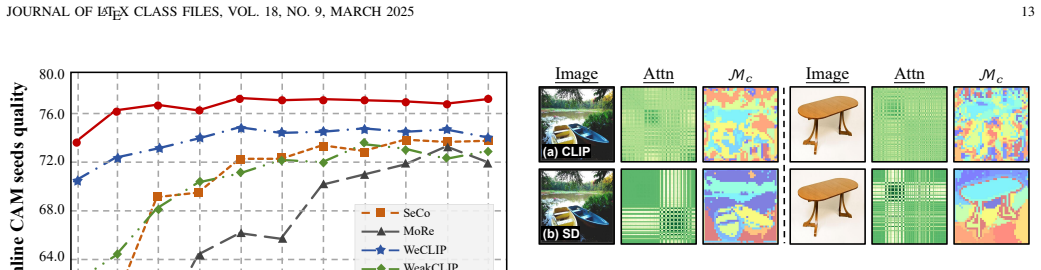

read the original abstract
Weakly Supervised Semantic Segmentation (WSSS) with image-level labels typically leverages Class Activation Maps (CAMs) to achieve pixel-level predictions. Recently, Contrastive Language-Image Pre-training (CLIP) has been introduced to generate CAMs in WSSS. However, previous WSSS methods solely adopt CLIP's vision-language paired property for dense localization, neglecting its inherently limited dense knowledge across both visual and text modalities, which renders CAM generation suboptimal. In this work, we propose DiCLIP, a novel WSSS framework that leverages the generative diffusion model to enhance CLIP's dense knowledge across two modalities. Specifically, Visual Correlation Enhancement (VCE) and Text Semantic Augmentation (TSA) modules are proposed for dense prediction enhancement. To improve the spatial awareness of visual features, our VCE module utilizes diffusion's reliable spatial consistency to mitigate the over-smoothing issue in CLIP's attention. It designs the Attention Clustering Refinement (ACR) module to reliably extract diverse correlation maps from the diffusion model. The correlation maps act as a diversity bias for CLIP's self-attention, recursively pushing its visual features towards a more discriminative dense distribution. To augment the semantics of text embeddings, our TSA module argues that a single text modality is insufficient to encompass the variability of visual categories. Thus, we leverage diffusion's generative power to maintain a dynamic key-value cache model, shifting CAM generation from a patch-text matching mechanism to a novel visual knowledge retrieval paradigm. With these enhancements, DiCLIP not only outperforms state-of-the-art methods on PASCAL VOC and MS COCO but also significantly reduces training costs. Code is publicly available at https://github.com/zwyang6/DiCLIP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DiCLIP, a WSSS framework that augments CLIP with a frozen diffusion model via two new modules: Visual Correlation Enhancement (VCE) containing an Attention Clustering Refinement (ACR) submodule that injects diffusion-derived correlation maps as a diversity bias into CLIP self-attention, and Text Semantic Augmentation (TSA) that maintains a dynamic key-value cache of diffusion-generated visual features to shift CAM generation from patch-text matching to visual knowledge retrieval. The central claim is that these enhancements yield SOTA mIoU on PASCAL VOC and MS COCO while also lowering training costs relative to prior CLIP-based WSSS methods.
Significance. If the performance and cost claims are substantiated, the work would demonstrate a practical way to transfer spatial consistency and generative priors from diffusion models into CLIP-based dense prediction without full fine-tuning, potentially improving efficiency in the image-level supervision regime. Public code release supports reproducibility.
major comments (3)
- [Abstract, §3] Abstract and §3 (Method): The headline claim that DiCLIP 'significantly reduces training costs' is load-bearing for the contribution yet is unsupported by any quantitative evidence. The VCE/ACR recursion, TSA dynamic cache, and repeated diffusion forward passes introduce non-trivial overhead even with a frozen backbone; without a table reporting wall-clock time, GPU-hours, or FLOPs versus the cited CLIP-CAM baselines (e.g., §4.2), it is impossible to verify whether the net training cost is lower.
- [§4] §4 (Experiments): The outperformance claim on PASCAL VOC and MS COCO is central but the abstract and method description provide no dataset statistics, number of runs, error bars, or ablation isolating the contribution of ACR versus the dynamic cache. A single table of final mIoU numbers is insufficient to establish that the gains are robust and not due to hyper-parameter tuning or favorable splits.
- [§3.2] §3.2 (ACR module): The recursive refinement of CLIP self-attention by diffusion correlation maps is described as 'pushing visual features towards a more discriminative dense distribution,' but no equation or convergence analysis is given for the recursion depth or the weighting between CLIP attention and the diffusion bias; without this, it is unclear whether the procedure is stable or merely adds another tunable hyper-parameter.
minor comments (2)
- [§3.3] Notation for the dynamic key-value cache in TSA is introduced without a formal definition or update rule; a small diagram or pseudocode would clarify the retrieval step.
- [§2] The paper cites several recent WSSS methods but does not discuss why diffusion was chosen over other generative priors (e.g., GANs or VAEs) that might incur lower inference cost.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to improve clarity, rigor, and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Method): The headline claim that DiCLIP 'significantly reduces training costs' is load-bearing for the contribution yet is unsupported by any quantitative evidence. The VCE/ACR recursion, TSA dynamic cache, and repeated diffusion forward passes introduce non-trivial overhead even with a frozen backbone; without a table reporting wall-clock time, GPU-hours, or FLOPs versus the cited CLIP-CAM baselines (e.g., §4.2), it is impossible to verify whether the net training cost is lower.
Authors: We agree that the claim requires quantitative backing, which is currently missing. Although the diffusion model remains frozen and CLIP is not fine-tuned (reducing overall optimization cost relative to prior methods that train additional heads or adapters), the added modules incur overhead. We will insert a new table in §4 reporting wall-clock training time, peak GPU memory, and approximate FLOPs for DiCLIP versus the CLIP-CAM baselines cited in §4.2. This will allow direct verification of the net cost reduction. revision: yes
-
Referee: [§4] §4 (Experiments): The outperformance claim on PASCAL VOC and MS COCO is central but the abstract and method description provide no dataset statistics, number of runs, error bars, or ablation isolating the contribution of ACR versus the dynamic cache. A single table of final mIoU numbers is insufficient to establish that the gains are robust and not due to hyper-parameter tuning or favorable splits.
Authors: We acknowledge the need for greater statistical detail. The current §4 contains component ablations, yet they do not report multiple random seeds, standard deviations, or fully isolate ACR from the TSA cache. We will expand the experimental section to include: (i) explicit dataset statistics, (ii) mean mIoU and standard deviation over at least three independent runs, and (iii) additional ablations that separately disable ACR and the dynamic cache while keeping all other factors fixed. These additions will demonstrate robustness beyond a single table of final scores. revision: yes
-
Referee: [§3.2] §3.2 (ACR module): The recursive refinement of CLIP self-attention by diffusion correlation maps is described as 'pushing visual features towards a more discriminative dense distribution,' but no equation or convergence analysis is given for the recursion depth or the weighting between CLIP attention and the diffusion bias; without this, it is unclear whether the procedure is stable or merely adds another tunable hyper-parameter.
Authors: We thank the referee for highlighting this omission. The ACR recursion is presented descriptively but lacks a formal update rule. We will add the precise mathematical formulation of the refined self-attention (including the weighting coefficient between the original CLIP attention and the diffusion-derived bias) together with the stopping criterion for recursion depth. We will also include an ablation table showing mIoU sensitivity to recursion depth (1–4 iterations) and discuss empirical stability; the diffusion maps are fixed and therefore do not introduce new trainable parameters beyond the existing weighting scalar. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes DiCLIP as a framework that introduces VCE (with ACR module) and TSA (with dynamic key-value cache) modules to leverage diffusion model properties for enhancing CLIP's dense knowledge in WSSS. No equations, mathematical derivations, or self-referential definitions appear in the abstract or method summary that would equate any claimed prediction or result to its inputs by construction. Performance gains and cost reductions are presented as empirical outcomes of the proposed enhancements rather than tautological or fitted-by-design quantities. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation are evident. The derivation chain remains self-contained against external benchmarks and properties of the base models.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CLIP has inherently limited dense knowledge across visual and text modalities
- domain assumption Diffusion model provides reliable spatial consistency and generative power usable for dense prediction
invented entities (4)
-
Visual Correlation Enhancement (VCE) module
no independent evidence
-
Text Semantic Augmentation (TSA) module
no independent evidence
-
Attention Clustering Refinement (ACR) module
no independent evidence
-
dynamic key-value cache model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fully convolutional networks for semantic segmentation,
J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” inCVPR, 2015, pp. 3431–3440
2015
-
[2]
Segformer: Simple and efficient design for semantic segmentation with transformers,
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo, “Segformer: Simple and efficient design for semantic segmentation with transformers,”NeurIPS, vol. 34, pp. 12 077–12 090, 2021
2021
-
[3]
Polyp-mamba: Polyp segmentation with visual mamba,
Z. Xu, F. Tang, Z. Chen, Z. Zhou, W. Wu, Y . Yang, Y . Liang, J. Jiang, X. Cai, and J. Su, “Polyp-mamba: Polyp segmentation with visual mamba,” inMICCAI. Springer, 2024
2024
-
[4]
Rethinking semantic segmentation with multi-grained logical prototype,
A. Yu, K. Gao, X. You, Y . Zhong, Y . Su, B. Liu, and C. Qiu, “Rethinking semantic segmentation with multi-grained logical prototype,”IEEE Transactions on Image Processing, 2025
2025
-
[5]
Haformer: Unleashing the power of hierarchy-aware features for lightweight semantic segmenta- tion,
G. Xu, W. Jia, T. Wu, L. Chen, and G. Gao, “Haformer: Unleashing the power of hierarchy-aware features for lightweight semantic segmenta- tion,”IEEE Transactions on Image Processing, 2024
2024
-
[6]
What’s the point: Semantic segmentation with point supervision,
A. Bearman, O. Russakovsky, V . Ferrari, and L. Fei-Fei, “What’s the point: Semantic segmentation with point supervision,” inCom- puter Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part VII 14. Springer, 2016, pp. 549–565
2016
-
[7]
Scribblesup: Scribble- supervised convolutional networks for semantic segmentation,
D. Lin, J. Dai, J. Jia, K. He, and J. Sun, “Scribblesup: Scribble- supervised convolutional networks for semantic segmentation,” inCVPR, 2016, pp. 3159–3167
2016
-
[8]
Learning random-walk label propaga- tion for weakly-supervised semantic segmentation,
P. Vernaza and M. Chandraker, “Learning random-walk label propaga- tion for weakly-supervised semantic segmentation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 7158–7166
2017
-
[9]
Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation,
J. Dai, K. He, and J. Sun, “Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation,” inICCV, 2015, pp. 1635–1643
2015
-
[10]
Bbam: Bounding box attribution map for weakly supervised semantic and instance segmentation,
J. Lee, J. Yi, C. Shin, and S. Yoon, “Bbam: Bounding box attribution map for weakly supervised semantic and instance segmentation,” in CVPR, 2021, pp. 2643–2652
2021
-
[11]
More: Class patch attention needs regularization for weakly supervised semantic segmentation,
Z. Yang, Y . Meng, K. Fu, S. Wang, and Z. Song, “More: Class patch attention needs regularization for weakly supervised semantic segmentation,”arXiv preprint arXiv:2412.11076, 2024
-
[12]
Learning pixel-level semantic affinity with image- level supervision for weakly supervised semantic segmentation,
J. Ahn and S. Kwak, “Learning pixel-level semantic affinity with image- level supervision for weakly supervised semantic segmentation,” in CVPR, 2018, pp. 4981–4990
2018
-
[13]
Learning affinity from attention: end- to-end weakly-supervised semantic segmentation with transformers,
L. Ru, Y . Zhan, B. Yu, and B. Du, “Learning affinity from attention: end- to-end weakly-supervised semantic segmentation with transformers,” in CVPR, 2022, pp. 16 846–16 855
2022
-
[14]
From image-level to pixel-level labeling with convolutional networks,
P. O. Pinheiro and R. Collobert, “From image-level to pixel-level labeling with convolutional networks,” inCVPR, 2015, pp. 1713–1721
2015
-
[15]
Z. Yang, Y . Meng, K. Fu, S. Wang, and Z. Song, “Tackling ambi- guity from perspective of uncertainty inference and affinity diversifi- cation for weakly supervised semantic segmentation,”arXiv preprint arXiv:2404.08195, 2024
-
[16]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inCVPR, 2022, pp. 10 684–10 695
2022
-
[17]
Learning deep features for discriminative localization,
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2921– 2929
2016
-
[18]
Dual graph inference network for weakly supervised semantic segmentation,
J. Zhang, B. Peng, and X. Wu, “Dual graph inference network for weakly supervised semantic segmentation,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[19]
Class activation map calibration for weakly supervised seman- tic segmentation,
J. Wang, T. Dai, X. Zhao, ´A. F. Garc ´ıa-Fern´andez, E. G. Lim, and J. Xiao, “Class activation map calibration for weakly supervised seman- tic segmentation,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[20]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[21]
Weakly-supervised semantic segmentation by iteratively mining common object features,
X. Wang, S. You, X. Li, and H. Ma, “Weakly-supervised semantic segmentation by iteratively mining common object features,” inCVPR, 2018, pp. 1354–1362
2018
-
[22]
Clims: cross language image matching for weakly supervised semantic segmentation,
J. Xie, X. Hou, K. Ye, and L. Shen, “Clims: cross language image matching for weakly supervised semantic segmentation,” inCVPR, 2022, pp. 4483–4492
2022
-
[23]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 618–626
2017
-
[24]
Frozen clip: A strong backbone for weakly supervised semantic segmentation,
B. Zhang, S. Yu, Y . Wei, Y . Zhao, and J. Xiao, “Frozen clip: A strong backbone for weakly supervised semantic segmentation,” inCVPR, 2024, pp. 3796–3806
2024
-
[25]
Weakclip: Adapting clip for weakly-supervised semantic segmentation,
L. Zhu, X. Wang, J. Feng, T. Cheng, Y . Li, B. Jiang, D. Zhang, and J. Han, “Weakclip: Adapting clip for weakly-supervised semantic segmentation,”International Journal of Computer Vision, pp. 1–21, 2024
2024
-
[26]
Unbounded cache model for online language modeling with open vocabulary,
E. Grave, M. M. Cisse, and A. Joulin, “Unbounded cache model for online language modeling with open vocabulary,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[27]
Tip-adapter: Training-free adaption of clip for few-shot classification,
R. Zhang, W. Zhang, R. Fang, P. Gao, K. Li, J. Dai, Y . Qiao, and H. Li, “Tip-adapter: Training-free adaption of clip for few-shot classification,” pp. 493–510, 2022
2022
-
[28]
Weakly supervised semantic segmentation via alternate self- dual teaching,
D. Zhang, H. Li, W. Zeng, C. Fang, L. Cheng, M.-M. Cheng, and J. Han, “Weakly supervised semantic segmentation via alternate self- dual teaching,”IEEE Transactions on Image Processing, 2023
2023
-
[29]
Multi-granularity denoising and bidirec- tional alignment for weakly supervised semantic segmentation,
T. Chen, Y . Yao, and J. Tang, “Multi-granularity denoising and bidirec- tional alignment for weakly supervised semantic segmentation,”IEEE Transactions on Image Processing, vol. 32, pp. 2960–2971, 2023
2023
-
[30]
Weakly supervised semantic segmentation by pixel-to-prototype contrast,
Y . Du, Z. Fu, Q. Liu, and Y . Wang, “Weakly supervised semantic segmentation by pixel-to-prototype contrast,” inCVPR, June 2022, pp. 4320–4329
2022
-
[31]
Extracting class activation maps from non- discriminative features as well,
Z. Chen and Q. Sun, “Extracting class activation maps from non- discriminative features as well,” inCVPR, June 2023, pp. 3135–3144
2023
-
[32]
Cross-block sparse class token contrast for weakly supervised semantic segmentation,
K. Cheng, J. Tang, H. Gu, H. Wan, and M. Li, “Cross-block sparse class token contrast for weakly supervised semantic segmentation,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[33]
Fine-grained background representation for weakly supervised semantic segmenta- tion,
X. Yin, W. Im, D. Min, Y . Huo, F. Pan, and S.-E. Yoon, “Fine-grained background representation for weakly supervised semantic segmenta- tion,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[34]
Pixel-level domain adaptation: A new perspective for enhancing weakly supervised semantic segmentation,
Y . Du, Z. Fu, and Q. Liu, “Pixel-level domain adaptation: A new perspective for enhancing weakly supervised semantic segmentation,” IEEE Transactions on Image Processing, 2024
2024
-
[35]
Spatial structure constraints for weakly supervised semantic segmentation,
T. Chen, Y . Yao, X. Huang, Z. Li, L. Nie, and J. Tang, “Spatial structure constraints for weakly supervised semantic segmentation,” IEEE Transactions on Image Processing, vol. 33, pp. 1136–1148, 2024
2024
-
[36]
Separate and conquer: Decoupling co-occurrence via decomposition and repre- sentation for weakly supervised semantic segmentation,
Z. Yang, K. Fu, M. Duan, L. Qu, S. Wang, and Z. Song, “Separate and conquer: Decoupling co-occurrence via decomposition and repre- sentation for weakly supervised semantic segmentation,” inCVPR, June 2024, pp. 3606–3615
2024
-
[37]
Token contrast for weakly- supervised semantic segmentation,
L. Ru, H. Zheng, Y . Zhan, and B. Du, “Token contrast for weakly- supervised semantic segmentation,” pp. 3093–3102, 2023. JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, MARCH 2025 16
2023
-
[38]
Group-wise semantic mining for weakly supervised semantic segmentation,
X. Li, T. Zhou, J. Li, Y . Zhou, and Z. Zhang, “Group-wise semantic mining for weakly supervised semantic segmentation,” inAAAI, vol. 35, no. 3, 2021, pp. 1984–1992
2021
-
[39]
Uncovering prototypical knowledge for weakly open- vocabulary semantic segmentation,
F. Zhang, T. Zhou, B. Li, H. He, C. Ma, T. Zhang, J. Yao, Y . Zhang, and Y . Wang, “Uncovering prototypical knowledge for weakly open- vocabulary semantic segmentation,”Advances in Neural Information Processing Systems, vol. 36, pp. 73 652–73 665, 2023
2023
-
[40]
Clip is also an efficient segmenter: A text-driven approach for weakly supervised semantic segmentation,
Y . Lin, M. Chen, W. Wang, B. Wu, K. Li, B. Lin, H. Liu, and X. He, “Clip is also an efficient segmenter: A text-driven approach for weakly supervised semantic segmentation,” pp. 15 305–15 314, 2023
2023
-
[41]
Question-answer cross language image matching for weakly supervised semantic segmentation,
S. Deng, W. Zhuo, J. Xie, and L. Shen, “Question-answer cross language image matching for weakly supervised semantic segmentation,”arXiv preprint arXiv:2401.09883, 2024
-
[42]
Prompting classes: exploring the power of prompt class learning in weakly supervised semantic segmentation,
B. Murugesan, R. Hussain, R. Bhattacharya, I. Ben Ayed, and J. Dolz, “Prompting classes: exploring the power of prompt class learning in weakly supervised semantic segmentation,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 291–302
2024
-
[43]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international con- ference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer, 2015, pp. 234–241
2015
-
[44]
Unleashing text- to-image diffusion models for visual perception,
W. Zhao, Y . Rao, Z. Liu, B. Liu, J. Zhou, and J. Lu, “Unleashing text- to-image diffusion models for visual perception,” inICCV, 2023, pp. 5729–5739
2023
-
[45]
Diffusion models for open-vocabulary segmentation,
L. Karazija, I. Laina, A. Vedaldi, and C. Rupprecht, “Diffusion models for open-vocabulary segmentation,” inEuropean Conference on Com- puter Vision. Springer, 2024, pp. 299–317
2024
-
[46]
Diffusion- guided weakly supervised semantic segmentation,
S.-H. Yoon, H. Kwon, J. Jeong, D. Park, and K.-J. Yoon, “Diffusion- guided weakly supervised semantic segmentation,” inEuropean Confer- ence on Computer Vision. Springer, 2024, pp. 393–411
2024
-
[47]
Exploring limits of diffusion-synthetic training with weakly supervised semantic segmentation,
R. Yoshihashi, Y . Otsuka, T. Tanaka, H. Kataokaet al., “Exploring limits of diffusion-synthetic training with weakly supervised semantic segmentation,” inACCV, 2024, pp. 2300–2318
2024
-
[48]
Image augmentation with controlled diffusion for weakly-supervised semantic segmentation,
W. Wu, T. Dai, X. Huang, F. Ma, and J. Xiao, “Image augmentation with controlled diffusion for weakly-supervised semantic segmentation,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 6175–6179
2024
-
[49]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page Pith review arXiv 2010
-
[50]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,”arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review arXiv 2016
-
[51]
Diffusion model is secretly a training-free open vocabulary semantic segmenter,
J. Wang, X. Li, J. Zhang, Q. Xu, Q. Zhou, Q. Yu, L. Sheng, and D. Xu, “Diffusion model is secretly a training-free open vocabulary semantic segmenter,”IEEE Transactions on Image Processing, 2025
2025
-
[52]
K-means text dynamic clustering algorithm based on kl divergence,
Z. Huan, Z. Pengzhou, and G. Zeyang, “K-means text dynamic clustering algorithm based on kl divergence,” in2018 IEEE/ACIS 17th Interna- tional Conference on Computer and Information Science (ICIS). IEEE, 2018, pp. 659–663
2018
-
[53]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[54]
Least squares quantization in pcm,
S. Lloyd, “Least squares quantization in pcm,”IEEE transactions on information theory, vol. 28, no. 2, pp. 129–137, 1982
1982
-
[55]
Sfc: Shared feature calibration in weakly supervised semantic segmentation,
X. Zhao, F. Tang, X. Wang, and J. Xiao, “Sfc: Shared feature calibration in weakly supervised semantic segmentation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 7, 2024, pp. 7525–7533
2024
-
[56]
Class tokens infusion for weakly supervised semantic segmentation,
S.-H. Yoon, H. Kwon, H. Kim, and K.-J. Yoon, “Class tokens infusion for weakly supervised semantic segmentation,” inCVPR, 2024, pp. 3595–3605
2024
-
[57]
Hunting attributes: Context prototype-aware learning for weakly supervised semantic seg- mentation,
F. Tang, Z. Xu, Z. Qu, W. Feng, X. Jiang, and Z. Ge, “Hunting attributes: Context prototype-aware learning for weakly supervised semantic seg- mentation,” inCVPR, 2024, pp. 3324–3334
2024
-
[58]
Pot: Prototypical optimal transport for weakly supervised semantic segmen- tation,
J. Wang, T. Dai, B. Zhang, S. Yu, E. G. Lim, and J. Xiao, “Pot: Prototypical optimal transport for weakly supervised semantic segmen- tation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 15 055–15 064
2025
-
[59]
Efficient inference in fully connected crfs with gaussian edge potentials,
P. Kr ¨ahenb¨uhl and V . Koltun, “Efficient inference in fully connected crfs with gaussian edge potentials,”NeurIPS, vol. 24, 2011
2011
-
[60]
L2g: A simple local-to- global knowledge transfer framework for weakly supervised semantic segmentation,
P.-T. Jiang, Y . Yang, Q. Hou, and Y . Wei, “L2g: A simple local-to- global knowledge transfer framework for weakly supervised semantic segmentation,” inCVPR, 2022, pp. 16 886–16 896
2022
-
[61]
Regional semantic contrast and aggregation for weakly supervised semantic segmentation,
T. Zhou, M. Zhang, F. Zhao, and J. Li, “Regional semantic contrast and aggregation for weakly supervised semantic segmentation,” inCVPR, 2022, pp. 4299–4309
2022
-
[62]
Treating pseudo- labels generation as image matting for weakly supervised semantic segmentation,
C. Wang, R. Xu, S. Xu, W. Meng, and X. Zhang, “Treating pseudo- labels generation as image matting for weakly supervised semantic segmentation,” inICCV, 2023, pp. 755–765
2023
-
[63]
Weakly supervised semantic segmentation using out-of-distribution data,
J. Lee, S. J. Oh, S. Yun, J. Choe, E. Kim, and S. Yoon, “Weakly supervised semantic segmentation using out-of-distribution data,” in CVPR, 2022, pp. 16 897–16 906
2022
-
[64]
Fpr: False positive rectification for weakly supervised semantic segmentation,
L. Chen, C. Lei, R. Li, S. Li, Z. Zhang, and L. Zhang, “Fpr: False positive rectification for weakly supervised semantic segmentation,” in ICCV, 2023, pp. 1108–1118
2023
-
[65]
Boundary-enhanced co-training for weakly supervised semantic segmentation,
S. Rong, B. Tu, Z. Wang, and J. Li, “Boundary-enhanced co-training for weakly supervised semantic segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 19 574–19 584
2023
-
[66]
Mctformer+: Multi-class token transformer for weakly supervised semantic segmentation,
L. Xu, M. Bennamoun, F. Boussaid, H. Laga, W. Ouyang, and D. Xu, “Mctformer+: Multi-class token transformer for weakly supervised semantic segmentation,”IEEE transactions on pattern analysis and machine intelligence, 2024
2024
-
[67]
Psdpm: Prototype- based secondary discriminative pixels mining for weakly supervised semantic segmentation,
X. Zhao, Z. Yang, T. Dai, B. Zhang, and J. Xiao, “Psdpm: Prototype- based secondary discriminative pixels mining for weakly supervised semantic segmentation,” inCVPR, June 2024, pp. 3437–3446
2024
-
[68]
Dupl: Dual student with trustworthy progressive learning for robust weakly supervised semantic segmentation,
Y . Wu, X. Ye, K. Yang, J. Li, and X. Li, “Dupl: Dual student with trustworthy progressive learning for robust weakly supervised semantic segmentation,” inCVPR, June 2024, pp. 3534–3543
2024
-
[69]
Ffr: Frequency feature rectification for weakly supervised semantic segmentation,
Z. Yang, X. Zhao, X. Wang, Q. Zhang, and J. Xiao, “Ffr: Frequency feature rectification for weakly supervised semantic segmentation,” in Proceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 30 261–30 270
2025
-
[70]
Weakly supervised semantic segmentation via pro- gressive confidence region expansion,
X. Xu, P. Zhang, W. Huang, Y . Shen, H. Chen, J. Lin, W. Li, G. He, J. Xie, and S. Lin, “Weakly supervised semantic segmentation via pro- gressive confidence region expansion,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 9829–9838
2025
-
[71]
Multi-label prototype visual spatial search for weakly supervised semantic segmentation,
S. Duan, X. Yang, and N. Wang, “Multi-label prototype visual spatial search for weakly supervised semantic segmentation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 30 241–30 250
2025
-
[72]
Know your attention maps: Class-specific token masking for weakly supervised semantic segmentation,
J. Hanna and D. Borth, “Know your attention maps: Class-specific token masking for weakly supervised semantic segmentation,”arXiv preprint arXiv:2507.06848, 2025
-
[73]
More: Class patch attention needs regularization for weakly supervised semantic segmentation,
Z. Yang, Y . Meng, K. Fu, S. Wang, and Z. Song, “More: Class patch attention needs regularization for weakly supervised semantic segmentation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9400–9408
2025
-
[74]
Dial: Dense image- text alignment for weakly supervised semantic segmentation,
S. Jang, J. Yun, J. Kwon, E. Lee, and Y . Kim, “Dial: Dense image- text alignment for weakly supervised semantic segmentation,” inECCV. Springer, 2024, pp. 248–266
2024
-
[75]
Usage: A unified seed area generation paradigm for weakly supervised semantic segmentation,
Z. Peng, G. Wang, L. Xie, D. Jiang, W. Shen, and Q. Tian, “Usage: A unified seed area generation paradigm for weakly supervised semantic segmentation,” inICCV, 2023, pp. 624–634
2023
-
[76]
Out-of-candidate rectification for weakly supervised semantic segmentation,
Z. Cheng, P. Qiao, K. Li, S. Li, P. Wei, X. Ji, L. Yuan, C. Liu, and J. Chen, “Out-of-candidate rectification for weakly supervised semantic segmentation,” inCVPR, 2023, pp. 23 673–23 684
2023
-
[77]
Class re-activation maps for weakly-supervised semantic segmentation,
Z. Chen, T. Wang, X. Wu, X.-S. Hua, H. Zhang, and Q. Sun, “Class re-activation maps for weakly-supervised semantic segmentation,” in CVPR, 2022, pp. 969–978
2022
-
[78]
Max pooling with vision transformers reconciles class and shape in weakly supervised semantic segmentation,
S. Rossetti, D. Zappia, M. Sanzari, M. Schaerf, and F. Pirri, “Max pooling with vision transformers reconciles class and shape in weakly supervised semantic segmentation,” inEuropean conference on computer vision. Springer, 2022, pp. 446–463
2022
-
[79]
The pascal visual object classes challenge: A retrospective,
M. Everingham, S. A. Eslami, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes challenge: A retrospective,”IJCV, vol. 111, pp. 98–136, 2015
2015
-
[80]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inECCV. Springer, 2014, pp. 740–755
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.