Recognition: no theorem link
ReflectDrive-2: Reinforcement-Learning-Aligned Self-Editing for Discrete Diffusion Driving
Pith reviewed 2026-05-13 01:43 UTC · model grok-4.3
The pith
Full-rollout reinforcement learning enables effective in-place self-editing in a discrete diffusion driving planner.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReflectDrive-2 shows that a masked discrete diffusion planner for driving trajectories can be trained to perform useful in-place revisions of its own discrete token plans when the full decision-draft-reflect sequence is optimized end-to-end with reinforcement learning and terminal driving rewards; this full-rollout credit assignment is essential, because supervised training on perturbed experts yields only marginal editing benefit while the RL stage produces a substantially larger improvement in final trajectory quality.
What carries the argument
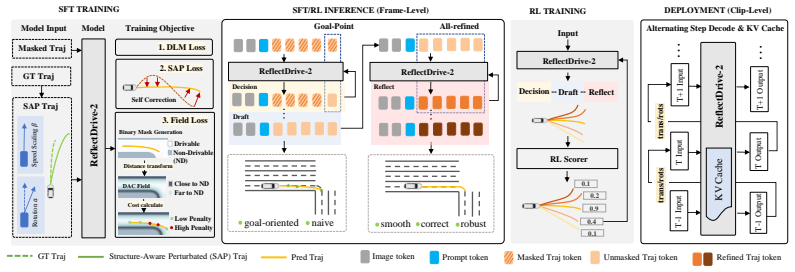
The two-stage training procedure that first supervises recovery from longitudinal and lateral perturbations and then applies policy-gradient updates across full decision-draft-reflect rollouts to align the AutoEdit self-revision behavior with terminal driving rewards.
If this is right
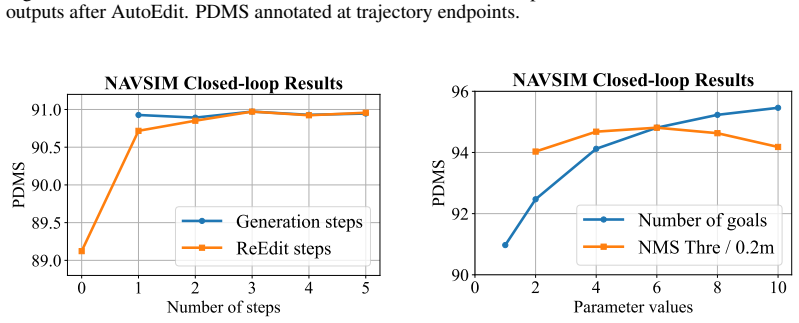
- The planner reaches 91.0 PDMS with camera-only input and 94.8 PDMS in a best-of-6 oracle setting on NAVSIM.
- Average inference runs at 31.8 ms on NVIDIA Thor hardware through the co-designed reflective decoding stack.
- Shared-prefix KV reuse, Alternating Step Decode, and fused unmasking keep the decision-draft-reflect pipeline computationally efficient.
- Discrete token representation allows trajectory revision without training or deploying a separate refinement model.
- The separation of an action expert supports modular policy updates while keeping the diffusion backbone fixed.
Where Pith is reading between the lines
- The same full-rollout RL alignment could be applied to other discrete generative planners where self-correction steps need to be learned rather than hand-designed.
- Terminal rewards alone appear sufficient to train multi-step generation-plus-editing when the rollout explicitly includes the editing transitions.
- Structure-aware perturbation directions may transfer to training self-editing in continuous-trajectory or non-driving planning domains.
- Reducing reliance on auxiliary refinement networks could simplify deployment of generative planners in resource-constrained vehicles.
Load-bearing premise
That structure-aware perturbations along longitudinal and lateral directions together with terminal driving rewards will train effective in-place editing without introducing distribution shift that harms performance outside the training distribution.
What would settle it
A controlled comparison on NAVSIM showing that the RL-fine-tuned model produces no larger AutoEdit improvement than the supervised-only baseline, or that edited trajectories yield lower driving metrics than non-edited ones when evaluated in closed-loop simulation.
Figures


read the original abstract
We introduce ReflectDrive-2, a masked discrete diffusion planner with separate action expert for autonomous driving that represents plans as discrete trajectory tokens and generates them through parallel masked decoding. This discrete token space enables in-place trajectory revision: AutoEdit rewrites selected tokens using the same model, without requiring an auxiliary refinement network. To train this capability, we use a two-stage procedure. First, we construct structure-aware perturbations of expert trajectories along longitudinal progress and lateral heading directions and supervise the model to recover the original expert trajectory. We then fine-tune the full decision--draft--reflect rollout with reinforcement learning (RL), assigning terminal driving reward to the final post-edit trajectory and propagating policy-gradient credit through full-rollout transitions. Full-rollout RL proves crucial for coupling drafting and editing: under supervised training alone, inference-time AutoEdit improves PDMS by at most $0.3$, whereas RL increases its gain to $1.9$. We also co-design an efficient reflective decoding stack for the decision--draft--reflect pipeline, combining shared-prefix KV reuse, Alternating Step Decode, and fused on-device unmasking. On NAVSIM, ReflectDrive-2 achieves $91.0$ PDMS with camera-only input and $94.8$ PDMS in a best-of-6 oracle setting, while running at $31.8$ ms average latency on NVIDIA Thor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReflectDrive-2, a masked discrete diffusion planner for autonomous driving that represents plans as discrete trajectory tokens and generates them via parallel masked decoding. It enables in-place self-editing (AutoEdit) without an auxiliary network. Training uses a two-stage process: supervised recovery from structure-aware perturbations of expert trajectories along longitudinal/lateral axes, followed by RL fine-tuning on full decision-draft-reflect rollouts using terminal driving rewards. The central claim is that full-rollout RL is crucial for coupling drafting and editing, as supervised training alone yields at most +0.3 PDMS improvement from AutoEdit while RL increases this to +1.9. On NAVSIM it reports 91.0 PDMS (camera-only) and 94.8 in best-of-6, with 31.8 ms average latency on NVIDIA Thor via a co-designed reflective decoding stack.
Significance. If the RL coupling result holds under rigorous controls, the approach could meaningfully advance self-correcting diffusion planners for driving by eliminating separate refinement networks and using on-policy RL to align draft and edit stages. The efficient decoding co-design (shared-prefix KV reuse, Alternating Step Decode, fused unmasking) is a practical strength for real-time deployment.
major comments (2)
- [Abstract] Abstract and training procedure: the supervised stage trains the editor exclusively on structure-aware perturbations of expert trajectories along longitudinal progress and lateral heading. No evidence is provided that these perturbations match the token-level error distribution (magnitude, direction, or correlations) produced by the diffusion drafter at inference, especially after RL policy updates. This leaves open the possibility that the reported 1.9 PDMS gain reflects on-policy training rather than a fundamental requirement for full-rollout RL to couple the stages.
- [Results] Results and evaluation: the headline comparison (supervised AutoEdit gain +0.3 PDMS vs. RL gain +1.9 PDMS) is presented without ablations on perturbation design, error-distribution matching, or intermediate reward signals. The terminal driving reward alone provides no gradient to distinguish useful edits from reward hacking, weakening the causal claim that full-rollout RL is required for effective self-editing.
minor comments (2)
- [Abstract] Clarify whether the 31.8 ms latency figure includes the full decision-draft-reflect pipeline or only the diffusion forward pass.
- [Results] The best-of-6 oracle result (94.8 PDMS) should be accompanied by variance or selection criteria to allow fair comparison with single-shot baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We respond point-by-point to the major comments below, providing clarifications on our design choices while acknowledging limitations in the presented evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract and training procedure: the supervised stage trains the editor exclusively on structure-aware perturbations of expert trajectories along longitudinal progress and lateral heading. No evidence is provided that these perturbations match the token-level error distribution (magnitude, direction, or correlations) produced by the diffusion drafter at inference, especially after RL policy updates. This leaves open the possibility that the reported 1.9 PDMS gain reflects on-policy training rather than a fundamental requirement for full-rollout RL to couple the stages.
Authors: The perturbations are constructed along longitudinal and lateral axes to target the dominant sources of trajectory error in driving, providing a practical initialization for the editor to recover expert-like behavior. We do not claim or demonstrate that these exactly replicate the token-level error statistics of the diffusion drafter at inference time, particularly after RL updates. The supervised stage initializes recovery capability, while the subsequent full-rollout RL exposes the model to the actual on-policy errors arising from the joint draft-edit process. The observed gap in AutoEdit gains (+0.3 PDMS supervised-only versus +1.9 PDMS after RL) is consistent with RL being necessary to align the two stages under realistic inference conditions. We can add further discussion of the perturbation rationale in a revision. revision: partial
-
Referee: [Results] Results and evaluation: the headline comparison (supervised AutoEdit gain +0.3 PDMS vs. RL gain +1.9 PDMS) is presented without ablations on perturbation design, error-distribution matching, or intermediate reward signals. The terminal driving reward alone provides no gradient to distinguish useful edits from reward hacking, weakening the causal claim that full-rollout RL is required for effective self-editing.
Authors: Our experiments prioritize the direct comparison of supervised versus RL training regimes to isolate the contribution of full-rollout RL. We did not perform exhaustive ablations on alternative perturbation designs or intermediate rewards, which would require substantial additional compute. The terminal reward is applied to the final post-edit trajectory and optimized via policy gradients over the complete rollout, allowing credit to flow to both drafting and editing decisions. While this does not explicitly penalize reward hacking at the edit level, the gains are measured on held-out NAVSIM scenarios and remain consistent. We can incorporate a limitations discussion on these aspects in the revised manuscript. revision: partial
- Empirical verification that the chosen perturbations match the precise token-level error distribution of the diffusion drafter at inference after RL updates
- Ablations using intermediate reward signals or alternative perturbation distributions to isolate their effects
Circularity Check
No circularity: empirical gains measured on external benchmark
full rationale
The paper's central claim compares measured PDMS scores (0.3 under supervised perturbations of expert trajectories vs. 1.9 after full-rollout RL) on the NAVSIM benchmark. These are direct evaluation outcomes from distinct training procedures, not quantities defined in terms of the inputs or fitted parameters. The two-stage process (supervised recovery on longitudinal/lateral perturbations, then RL with terminal reward) is described explicitly without self-referential equations or load-bearing self-citations that reduce the result to its own assumptions. No ansatz smuggling, renaming of known results, or uniqueness theorems imported from prior author work appear in the derivation chain. The performance numbers remain falsifiable external measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume =
Structured Denoising Diffusion Models in Discrete State-Spaces , author =. Advances in Neural Information Processing Systems , volume =
-
[3]
International Conference on Learning Representations , year =
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author =. International Conference on Learning Representations , year =
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Blended Diffusion for Text-Driven Editing of Natural Images , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[5]
Bie, Tiwei and Cao, Maosong and Chen, Kun and Du, Lun and Gong, Mingliang and Gong, Zhuochen and Gu, Yanmei and Hu, Jiaqi and Huang, Zenan and Lan, Zhenzhong and Li, Chengxi and Li, Chongxuan and Li, Jianguo and Li, Zehuan and Liu, Huabin and Liu, Ling and Lu, Guoshan and Lu, Xiaocheng and Ma, Yuxin and Tan, Jianfeng and Wei, Lanning and Wen, Ji-Rong and ...
-
[6]
Bie, Tiwei and Cao, Maosong and Cao, Xiang and Chen, Bingsen and Chen, Fuyuan and Chen, Kun and Du, Lun and Feng, Daozhuo and Feng, Haibo and Gong, Mingliang and Gong, Zhuocheng and Gu, Yanmei and Guan, Jian and Guan, Kaiyuan and He, Hongliang and Huang, Zenan and Jiang, Juyong and Jiang, Zhonghui and Lan, Zhenzhong and Li, Chengxi and Li, Jianguo and Li,...
-
[7]
Black, Kevin and Brown, Noah and Darpinian, James and Dhabalia, Karan and Driess, Danny and Esmail, Adnan and Equi, Michael Robert and Finn, Chelsea and Fusai, Niccolo and Galliker, Manuel Y. and Ghosh, Dibya and Groom, Lachy and Hausman, Karol and Ichter, Brian and Jakubczak, Szymon and Jones, Tim and Ke, Liyiming and LeBlanc, Devin and Levine, Sergey an...
work page 2025
-
[8]
International Conference on Learning Representations , year =
Training Diffusion Models with Reinforcement Learning , author =. International Conference on Learning Representations , year =
-
[9]
Black, Kevin and Brown, Noah and Driess, Danny and Esmail, Adnan and Equi, Michael and Finn, Chelsea and Fusai, Niccolo and Groom, Lachy and Hausman, Karol and Ichter, Brian and Jakubczak, Szymon and Jones, Tim and Ke, Liyiming and Levine, Sergey and Li-Bell, Adrian and Mothukuri, Mohith and Nair, Suraj and Pertsch, Karl and Shi, Lucy Xiaoyang and Tanner,...
-
[10]
Brohan, Anthony and Brown, Noah and Carbajal, Justice and Chebotar, Yevgen and Chen, Xi and Choromanski, Krzysztof and Ding, Tianli and Driess, Danny and Dubey, Avinava and Finn, Chelsea and Florence, Pete and Fu, Chuyuan and Arenas, Montse Gonzalez and Gopalakrishnan, Keerthana and Han, Kehang and Hausman, Karol and Herzog, Alexander and Hsu, Jasmine and...
-
[11]
Caesar, Holger and Bankiti, Varun and Lang, Alex H. and Vora, Sourabh and Liong, Venice Erin and Xu, Qiang and Krishnan, Anush and Pan, Yu and Baldan, Giancarlo and Beijbom, Oscar , booktitle =
-
[12]
and Fletcher, Luke and Beijbom, Oscar and Omari, Sammy , journal =
Caesar, Holger and Kabzan, Juraj and Tan, Kok Seang and Fong, Whye Kit and Wolff, Eric and Lang, Alex H. and Fletcher, Luke and Beijbom, Oscar and Omari, Sammy , journal =
-
[13]
Robotics: Science and Systems , year =
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion , author =. Robotics: Science and Systems , year =
-
[14]
Chang, Huiwen and Zhang, Han and Jiang, Lu and Liu, Ce and Freeman, William T. , booktitle =
-
[15]
International Conference on Machine Learning , year =
Muse: Text-to-Image Generation via Masked Generative Transformers , author =. International Conference on Machine Learning , year =
-
[16]
Chitta, Kashyap and Prakash, Aditya and Jaeger, Bernhard and Yu, Zehao and Renz, Katrin and Geiger, Andreas , journal =
-
[17]
IEEE International Conference on Robotics and Automation , pages =
End-to-End Driving via Conditional Imitation Learning , author =. IEEE International Conference on Robotics and Automation , pages =
-
[18]
Couairon, Guillaume and Verbeek, Jakob and Schwenk, Holger and Cord, Matthieu , booktitle =
-
[19]
International Conference on Learning Representations , year =
Directly Fine-Tuning Diffusion Models on Differentiable Rewards , author =. International Conference on Learning Representations , year =
-
[20]
Dang, Chenxu and Ang, Sining and Li, Yongkang and Tian, Haochen and Wang, Jie and Li, Guang and Ye, Hangjun and Ma, Jie and Chen, Long and Wang, Yan , journal =
-
[21]
Dauner, Daniel and Hallgarten, Matthias and Li, Tianyu and Weng, Xinshuo and Huang, Zhiyu and Yang, Zetong and Li, Hongyang and Gilitschenski, Igor and Ivanovic, Boris and Pavone, Marco and Geiger, Andreas and Chitta, Kashyap , booktitle =
-
[22]
Generative Modeling via Drifting
Generative Modeling via Drifting , author =. arXiv preprint arXiv:2602.04770 , year =
work page internal anchor Pith review arXiv
-
[23]
Dosovitskiy, Alexey and Ros, German and Codevilla, Felipe and Lopez, Antonio and Koltun, Vladlen , booktitle =
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Large Scale Interactive Motion Forecasting for Autonomous Driving: The Waymo Open Motion Dataset , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[25]
International Conference on Learning Representations , year =
Diffusion Policy Policy Optimization , author =. International Conference on Learning Representations , year =
-
[26]
Fan, Haoyang and Zhu, Fan and Liu, Changchun and Zhang, Liangliang and Zhuang, Li and Li, Dong and Zhu, Weichuan and Hu, Jiangtao and Li, Hongye and Kong, Qi , journal =. Baidu
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Vector Quantized Diffusion Model for Text-to-Image Synthesis , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[28]
International Conference on Learning Representations , year =
Diffusion-Based Planning for Autonomous Driving with Flexible Guidance , author =. International Conference on Learning Representations , year =
-
[29]
Advances in Neural Information Processing Systems , volume =
Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research , author =. Advances in Neural Information Processing Systems , volume =
-
[30]
Gong, Shansan and Zhang, Ruixiang and Zheng, Huangjie and Gu, Jiatao and Jaitly, Navdeep and Kong, Lingpeng and Zhang, Yizhe , booktitle =. 2026 , url =
work page 2026
-
[31]
He, Zhengfu and Sun, Tianxiang and Wang, Kuanning and Huang, Xuanjing and Qiu, Xipeng , journal =
-
[32]
Advances in Neural Information Processing Systems , volume =
Denoising Diffusion Probabilistic Models , author =. Advances in Neural Information Processing Systems , volume =
-
[33]
Hu, Shengchao and Chen, Li and Wu, Penghao and Li, Hongyang and Yan, Junchi and Tao, Dacheng , booktitle =
-
[34]
Hu, Anthony and Russell, Lloyd and Yeo, Harrison and Murez, Zak and Fedoseev, Georgy and Kendall, Alex and Shotton, Jamie and Corrado, Greg , journal =
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Planning-Oriented Autonomous Driving , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[36]
International Conference on Machine Learning , pages =
Planning with Diffusion for Flexible Behavior Synthesis , author =. International Conference on Machine Learning , pages =
-
[37]
Jiang, Chiyu and Cornman, Andre and Park, Cheolho and Sapp, Benjamin and Zhou, Yin and Anguelov, Dragomir , booktitle =
-
[38]
Jiang, Bo and Chen, Shaoyu and Xu, Qing and Liao, Bencheng and Chen, Jiajie and Zhou, Helong and Zhang, Qian and Liu, Wenyu and Huang, Chang and Wang, Xinggang , booktitle =
-
[39]
Li, Yingyan and Shang, Shuyao and Liu, Weisong and Zhan, Bing and Wang, Haochen and Wang, Yuqi and Chen, Yuntao and Wang, Xiaoman and An, Yasong and Tang, Chufeng and Hou, Lu and Fan, Lue and Zhang, Zhaoxiang , journal =
-
[41]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success , author =. arXiv preprint arXiv:2502.19645 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
ACM/IEEE International Conference on Cyber-Physical Systems , pages =
Autoware on Board: Enabling Autonomous Vehicles with Embedded Systems , author =. ACM/IEEE International Conference on Cyber-Physical Systems , pages =
-
[43]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with
-
[44]
Liao, Bencheng and Chen, Shaoyu and Yin, Haoran and Jiang, Bo and Wang, Cheng and Yan, Sixu and Zhang, Xinbang and Li, Xiangyu and Zhang, Ying and Zhang, Qian and Wang, Xinggang , booktitle =. 2025 , doi =
work page 2025
-
[45]
Li, Qixiu and Liang, Yaobo and Wang, Zeyu and Luo, Lin and Chen, Xi and Liao, Mozheng and Wei, Fangyun and Deng, Yu and Xu, Sicheng and Zhang, Yizhong and Wang, Xiaofan and Liu, Bei and Fu, Jianlong and Bao, Jianmin and Chen, Dong and Shi, Yuanchun and Yang, Jiaolong and Guo, Baining , journal =
-
[46]
Li, Shufan and Kallidromitis, Konstantinos and Bansal, Hritik and Gokul, Akash and Kato, Yusuke and Kozuka, Kazuki and Kuen, Jason and Lin, Zhe and Chang, Kai-Wei and Grover, Aditya , journal =
-
[47]
Proceedings of the IEEE International Conference on Computer Vision , pages =
Focal Loss for Dense Object Detection , author =. Proceedings of the IEEE International Conference on Computer Vision , pages =
-
[48]
International Conference on Learning Representations , year =
Flow Matching for Generative Modeling , author =. International Conference on Learning Representations , year =
-
[49]
International Conference on Machine Learning , year =
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author =. International Conference on Machine Learning , year =
-
[50]
Lugmayr, Andreas and Danelljan, Martin and Romero, Andres and Yu, Fisher and Timofte, Radu and Van Gool, Luc , booktitle =
-
[51]
Meng, Chenlin and He, Yutong and Song, Yang and Song, Jiaming and Wu, Jiajun and Zhu, Jun-Yan and Ermon, Stefano , booktitle =
-
[52]
and Pearce, Tim and Fleuret, Fran
Alonso, Eloi and Jelley, Adam and Micheli, Vincent and Kanervisto, Anssi and Storkey, Amos J. and Pearce, Tim and Fleuret, Fran. Diffusion for World Modeling: Visual Details Matter in. Advances in Neural Information Processing Systems , year =
-
[54]
Octo: An Open-Source Generalist Robot Policy
Octo: An Open-Source Generalist Robot Policy , author =. arXiv preprint arXiv:2405.12213 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open. arXiv preprint arXiv:2310.08864 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Pertsch, Karl and Stachowicz, Kyle and Ichter, Brian and Driess, Danny and Nair, Suraj and Vuong, Quan and Mees, Oier and Finn, Chelsea and Levine, Sergey , booktitle =. 2025 , url =
work page 2025
-
[57]
Sima, Chonghao and Renz, Katrin and Chitta, Kashyap and Chen, Li and Zhang, Hanxue and Xie, Chunguang and Luo, Ping and Geiger, Andreas and Li, Hongyang , booktitle =
-
[58]
International Conference on Machine Learning , pages =
Consistency Models , author =. International Conference on Machine Learning , pages =
-
[59]
International Conference on Learning Representations , year =
Score-Based Generative Modeling through Stochastic Differential Equations , author =. International Conference on Learning Representations , year =
-
[61]
Tian, Xiaoyu and Gu, Junru and Li, Bailin and Liu, Yicheng and Hu, Chenxu and Wang, Yang and Zhan, Kun and Jia, Peng and Lang, Xianpeng and Zhao, Hang , booktitle =
-
[62]
Advances in Neural Information Processing Systems , volume =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , volume =
-
[63]
Wen, Yuqing and Li, Hebei and Gu, Kefan and Zhao, Yucheng and Wang, Tiancai and Sun, Xiaoyan , journal =
-
[64]
Wu, Chengyue and Zhang, Hao and Xue, Shuchen and Liu, Zhijian and Diao, Shizhe and Zhu, Ligeng and Luo, Ping and Han, Song and Xie, Enze , journal =
-
[65]
Wang, Guanghan and Schiff, Yair and Turok, Gilad and Kuleshov, Volodymyr , journal =
-
[66]
and Tian, Yuandong and Liu, Bo , journal =
Wang, Chenyu and Rashidinejad, Paria and Su, DiJia and Jiang, Song and Wang, Sid and Zhao, Siyan and Zhou, Cai and Shen, Shannon Zejiang and Chen, Feiyu and Jaakkola, Tommi S. and Tian, Yuandong and Liu, Bo , journal =
-
[67]
Feng, Xiaoxin and Gao, Ziyan and Kan, Yuheng and Wu, Wei , journal =
-
[68]
International Conference on Machine Learning , pages =
Xiao, Guangxuan and Lin, Ji and Seznec, Micka. International Conference on Machine Learning , pages =
-
[69]
and Li, Zhenguo and Zhao, Hengshuang , journal =
Xu, Zhenhua and Zhang, Yujia and Xie, Enze and Zhao, Zhen and Guo, Yong and Wong, Kwan-Yee K. and Li, Zhenguo and Zhao, Hengshuang , journal =
-
[70]
Yang, Ling and Tian, Ye and Li, Bowen and Zhang, Xinchen and Shen, Ke and Tong, Yunhai and Wang, Mengdi , journal =
-
[71]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Paint by Example: Exemplar-Based Image Editing with Diffusion Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[72]
Dream 7B: Diffusion Large Language Models
Dream 7B: Diffusion Large Language Models , author =. arXiv preprint arXiv:2508.15487 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
Zhai, Andy and Liu, Brae and Fang, Bruno and Cai, Chalse and Ma, Ellie and Yin, Ethan and Wang, Hao and Zhou, Hugo and Wang, James and Shi, Lights and Liang, Lucy and Wang, Make and Wang, Qian and Gan, Roy and Yu, Ryan and Li, Shalfun and Liu, Starrick and Chen, Sylas and Chen, Vincent and Xu, Zach , journal =. Igniting
-
[75]
IEEE International Conference on Robotics and Automation , pages =
Guided Conditional Diffusion for Controllable Traffic Simulation , author =. IEEE International Conference on Robotics and Automation , pages =. 2023 , doi =
work page 2023
-
[76]
Proceedings of The 7th Conference on Robot Learning , pages =
Language-Guided Traffic Simulation via Scene-Level Diffusion , author =. Proceedings of The 7th Conference on Robot Learning , pages =. 2023 , url =
work page 2023
-
[78]
Li, Yongkang and Xiong, Kaixin and Guo, Xiangyu and Li, Fang and Yan, Sixu and Xu, Gangwei and Zhou, Lijun and Chen, Long and Sun, Haiyang and Wang, Bing and Chen, Guang and Ye, Hangjun and Liu, Wenyu and Wang, Xinggang , journal =
-
[79]
Zhao, Siyan and Gupta, Devaansh and Zheng, Qinqing and Grover, Aditya , journal =
-
[80]
Xing, Zebin and Zhang, Xingyu and Hu, Yang and Jiang, Bo and He, Tong and Zhang, Qian and Long, Xiaoxiao and Yin, Wei , booktitle =
-
[81]
and Zhang, Yun and Huang, Zhiyu and Zhou, Bolei and Ma, Jiaqi , booktitle =
Zhou, Zewei and Cai, Tianhui and Zhao, Seth Z. and Zhang, Yun and Huang, Zhiyu and Zhou, Bolei and Ma, Jiaqi , booktitle =. 2025 , url =
work page 2025
-
[82]
and Salazar, Grecia and Ryoo, Michael S
Zitkovich, Brianna and Yu, Tianhe and Xu, Sichun and Xu, Peng and Xiao, Ted and Xia, Fei and Wu, Jialin and Wohlhart, Paul and Welker, Stefan and Wahid, Ayzaan and Vuong, Quan and Vanhoucke, Vincent and Tran, Huong and Soricut, Radu and Singh, Anikait and Singh, Jaspiar and Sermanet, Pierre and Sanketi, Pannag R. and Salazar, Grecia and Ryoo, Michael S. a...
work page 2023
-
[83]
Bansal, Mayank and Krizhevsky, Alex and Ogale, Abhijit , booktitle =
-
[84]
Wang, Xiaofeng and Zhu, Zheng and Huang, Guan and Chen, Xinze and Lu, Jiwen , journal =
-
[85]
Conference on Robot Learning , pages =
Learning by Cheating , author =. Conference on Robot Learning , pages =
-
[87]
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. In International Conference on Learning Representations, 2025. URL https://arxiv.org/abs/2503.09573
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.