Recognition: no theorem link
FAAST: Forward-Only Associative Learning via Closed-Form Fast Weights for Test-Time Supervised Adaptation
Pith reviewed 2026-05-11 01:46 UTC · model grok-4.3
The pith
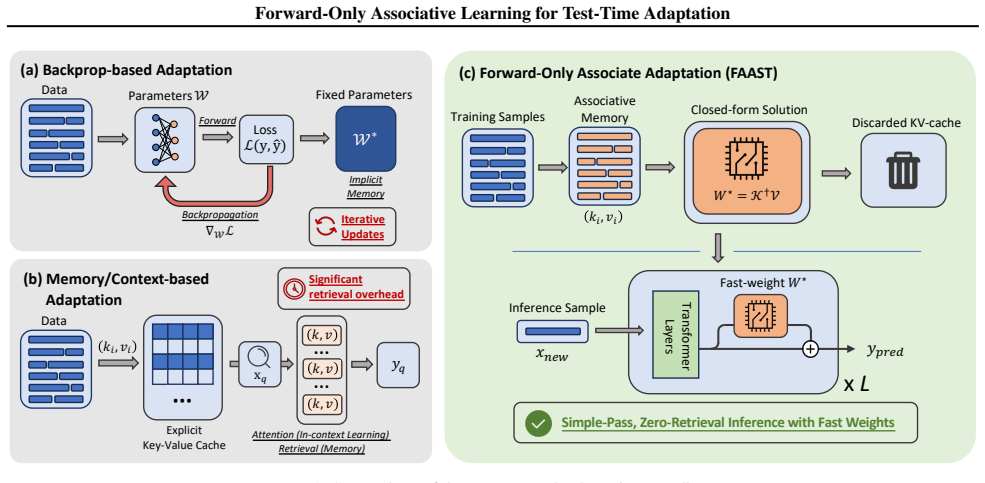
FAAST performs supervised adaptation of pretrained models by analytically compiling labeled examples into fast weights from a single forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FAAST analytically computes fast weights from a single forward pass over labeled examples to perform supervised adaptation at test time. This forward-only method matches or exceeds the performance of backpropagation-based fine-tuning while cutting adaptation time by more than 90 percent and uses up to 95 percent less memory than context or memory-based approaches, across image classification and language modeling benchmarks.
What carries the argument
Closed-form fast weights computed associatively from a single forward pass over labeled examples, which encode task-specific input-to-label mappings without iterative gradients or stored context.
If this is right
- Adaptation time drops by more than 90 percent relative to backpropagation methods.
- Memory footprint shrinks by up to 95 percent compared with memory or context-based adaptation.
- Inference runs in constant time independent of the number of adaptation examples.
- Task-specific information is separated from the pretrained model's representations.
- The same procedure applies to both image classification and language modeling without task-specific redesign.
Where Pith is reading between the lines
- The method suggests that associative compilation of examples can substitute for gradient-based updates in many adaptation settings.
- Constant-time inference could support repeated adaptation on the same device without accumulating costs.
- Decoupling adaptation from the base model may simplify combining multiple specialized tasks.
- The approach opens a route to test-time adaptation on hardware that cannot support backpropagation.
Load-bearing premise
That fast weights calculated analytically from one forward pass on labeled examples hold enough task-specific information to match results from iterative backpropagation or stored memory methods.
What would settle it
A benchmark result where FAAST accuracy falls well below backpropagation-based adaptation on the same set of labeled examples for a standard image classification or language modeling task.
Figures





read the original abstract
Adapting pretrained models typically involves a trade-off between the high training costs of backpropagation and the heavy inference overhead of memory-based or in-context learning. We propose FAAST, a forward-only associative adaptation method that analytically compiles labeled examples into fast weights in a single pass. By eliminating memory or context dependence, FAAST achieves constant-time inference and decouples task adaptation from pretrained representation. Across image classification and language modeling benchmarks, FAAST matches or exceeds backprop-based adaptation while reducing adaptation time by over 90% and is competitive to memory/context-based adaptation while saving memory usage by up to 95%. These results demonstrate FAAST as a highly efficient, scalable solution for supervised task adaptation, particularly for resource-constrained models. We release the code and models at https://github.com/baoguangsheng/faast.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FAAST, a forward-only associative adaptation method that analytically compiles labeled examples into closed-form fast weights via a single forward pass on pretrained models. It claims to match or exceed backprop-based test-time adaptation in performance on image classification and language modeling benchmarks while reducing adaptation time by over 90%, and to remain competitive with memory/context-based methods while using up to 95% less memory, with constant-time inference and decoupling of adaptation from the base representation. Code and models are released.
Significance. If the central analytical construction and empirical results hold, FAAST offers a notable efficiency advance for supervised test-time adaptation in resource-constrained settings. The parameter-free closed-form derivation, single-pass nature, and released code provide direct support for the claimed time and memory savings and enhance reproducibility.
minor comments (2)
- [Abstract] Abstract: the claim of 'matches or exceeds' performance would be strengthened by a brief parenthetical reference to the specific closed-form expression used for the fast weights.
- [§4] §4 (Experiments): confirm that all reported gains include standard deviations across multiple runs or seeds, particularly for the >90% time reduction and 95% memory savings figures.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of the efficiency claims, and recommendation for minor revision. The referee's assessment aligns with our intended contributions regarding the closed-form fast weights and resource savings. No major comments were provided in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core method is an analytical closed-form computation of fast weights from a single forward pass on labeled examples, presented as parameter-free and independent of iterative optimization or memory storage. No equations or steps reduce predictions to fitted inputs by construction, nor rely on load-bearing self-citations whose validity is internal to the work. Benchmarks and released code provide external verifiability for efficiency claims. The derivation remains self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
invented entities (1)
-
fast weights
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Alain, G. and Bengio, Y . Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644,
-
[2]
Z., Rae, J., Wierstra, D., and Hass- abis, D
Blundell, C., Uria, B., Pritzel, A., Li, Y ., Ruderman, A., Leibo, J. Z., Rae, J., Wierstra, D., and Hass- abis, D. Model-free episodic control.arXiv preprint arXiv:1606.04460,
-
[3]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
work page 1901
-
[4]
Overview of the iwslt 2017 evaluation campaign
Cettolo, M., Federico, M., Bentivogli, L., Niehues, J., St¨uker, S., Sudoh, K., Yoshino, K., and Federmann, C. Overview of the iwslt 2017 evaluation campaign. InPro- ceedings of the 14th International Conference on Spoken Language Translation, pp. 2–14,
work page 2017
-
[5]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
work page 2019
-
[6]
Graves, A., Wayne, G., and Danihelka, I. Neural turing machines.arXiv preprint arXiv:1410.5401,
work page internal anchor Pith review arXiv
-
[7]
Ha, D. and Schmidhuber, J. World models.arXiv preprint arXiv:1803.10122, 2(3),
work page internal anchor Pith review arXiv
-
[8]
The forward-forward algorithm: Some preliminary investigations.arXiv preprint arXiv:2212.13345,
Hinton, G. The forward-forward algorithm: Some prelimi- nary investigations.arXiv preprint arXiv:2212.13345, 2 (3):5,
-
[9]
Hopfield, J. J. Hopfield network.Scholarpedia, 2(5):1977,
work page 1977
-
[10]
Universal language model fine-tuning for text classification
Howard, J. and Ruder, S. Universal language model fine-tuning for text classification.arXiv preprint arXiv:1801.06146,
-
[11]
Generalization through memorization: Nearest neighbor language models
Khandelwal, U., Levy, O., Jurafsky, D., Zettlemoyer, L., and Lewis, M. Generalization through memorization: Nearest neighbor language models.arXiv preprint arXiv:1911.00172,
-
[12]
Revisiting self- supervised visual representation learning
Kolesnikov, A., Zhai, X., and Beyer, L. Revisiting self- supervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1920–1929,
work page 1920
-
[13]
The Power of Scale for Parameter-Efficient Prompt Tuning
Lester, B., Al-Rfou, R., and Constant, N. The power of scale for parameter-efficient prompt tuning.arXiv preprint arXiv:2104.08691,
work page internal anchor Pith review arXiv
-
[14]
Li, X. L. and Liang, P. Prefix-tuning: Optimizing continuous prompts for generation.arXiv preprint arXiv:2101.00190,
work page internal anchor Pith review arXiv
-
[15]
Pointer Sentinel Mixture Models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843,
work page internal anchor Pith review arXiv
-
[16]
Oord, A. v. d., Li, Y ., and Vinyals, O. Representation learn- ing with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Press, O., Smith, N. A., and Lewis, M. Train short, test long: Attention with linear biases enables input length extrapolation.arXiv preprint arXiv:2108.12409,
work page internal anchor Pith review arXiv
- [18]
-
[19]
Weston, J., Chopra, S., and Bordes, A. Memory networks. arXiv preprint arXiv:1410.3916,
-
[20]
11 Forward-Only Associative Learning for Test-Time Adaptation A. Related Work While individual components of FAAST – associative memory, fast weights, frozen representations, and pseudoinverse solutions – have been studied in isolation, prior work does not simultaneously achieve forward-only learning, closed-form associative memory, non-parametric storage...
work page 2019
-
[21]
However, these methods still require gradient-based optimization
reduce the cost of downstream adaptation by introducing small trainable parameter sets. However, these methods still require gradient-based optimization. FAAST computes task-specific mappings analytically via forward-only associative memory, eliminating the need for any parameter training for downstream adaptation. In-Context Learning and Test-Time Adapta...
work page 2020
-
[22]
exist but rely on stochastic search rather than deterministic closed-form fast weights. Fast weights and associative memories.Associative memory has a long history, from Hopfield networks (Hopfield, 1982
work page 1982
-
[23]
and Hebbian learning (Hebb, 1949; Kanter & Sompolinsky, 1987; Personnaz et al.,
work page 1949
-
[24]
Traditional approaches rely on iterative updates or learned plasticity rules
to modern fast-weight models (Schmidhuber, 1992; Ba et al., 2016). Traditional approaches rely on iterative updates or learned plasticity rules. FAAST differs by computing task-specific fast weights analytically from stored key-value pairs in a single forward pass, yielding deterministic, optimizer-free adaptation. Pseudoinverse-based associative memories...
work page 1992
-
[25]
support high-fidelity retrieval but have not been combined with pretrained representations or inference-time compression. Non-parametric memory and retrieval-augmented models.Memory-augmented neural networks, such as Neural Turing Machines (Graves et al., 2014), Memory Networks (Weston et al., 2014), Differentiable Neural Computers (Graves et al., 2016), ...
work page 2014
-
[26]
and RAG (Lewis et al., 2020), also rely on querying stored key-value pairs at inference time. FAAST compresses all stored associations into a single fast-weight matrix, eliminating memory queries at inference while retaining the ability to adapt to new tasks. 12 Forward-Only Associative Learning for Test-Time Adaptation B. Theoretical Foundations This sec...
work page 2020
-
[27]
as the backbone model, using frozen image and text encoders. Image embeddings serve as keys, and text embeddings of class prompts “A photo of a {label}.” serve as values. All adaptation is performed on these fixed representations. Baselines.All methods operate on identical frozen features to isolate the effect of associative memory.CLIP zero- Shotmakes pr...
work page 2021
-
[28]
with k= min(n,10) .Softmax memorydoes attention-based retrieval (Vaswani et al., 2017). For k-NN, softmax memory, and FAAST, predictions are linearly interpolated with CLIP zero-shot predictions using the same prior count N0. We set N0 to 40 times the number of classes, yielding N0 = 400 for CIFAR-10 and N0 = 800 for mini-ImageNet. All other hyperparamete...
work page 2017
-
[29]
datasets.CIFAR-10contains 10 classes with 50,000 training and 10,000 test images; we use the training split as support set and the test split as query set.mini-ImageNetcontains 100 classes. We use the 20-class test split only, randomly dividing each class into equal size, obtaining 6,000 samples for support set and another 6,000 for query set. We evaluate...
work page 2016
-
[30]
During training, to avoid the dominance of historical fast weights computed using outdated readout and weighting, we apply a discount to incremental updateN t before each update, with an empirical value of 0.9. Backprop Model Training.Table 7 summarizes the training configurations for backpropagation-based baselines in language modeling. Both linear proje...
work page 1955
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.