Recognition: unknown
Anny-Fit: All-Age Human Mesh Recovery
Pith reviewed 2026-05-08 17:26 UTC · model grok-4.3
The pith
A joint camera-space optimization recovers accurate 3D human meshes for people of all ages by combining depth maps, outlines, keypoints, and age estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
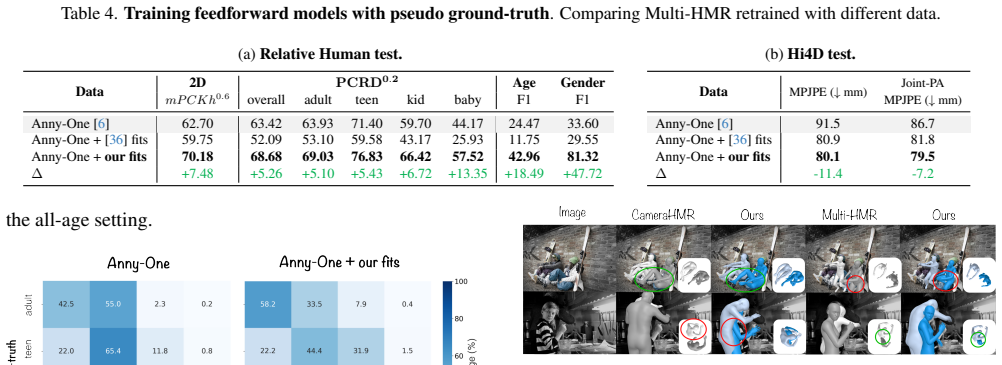
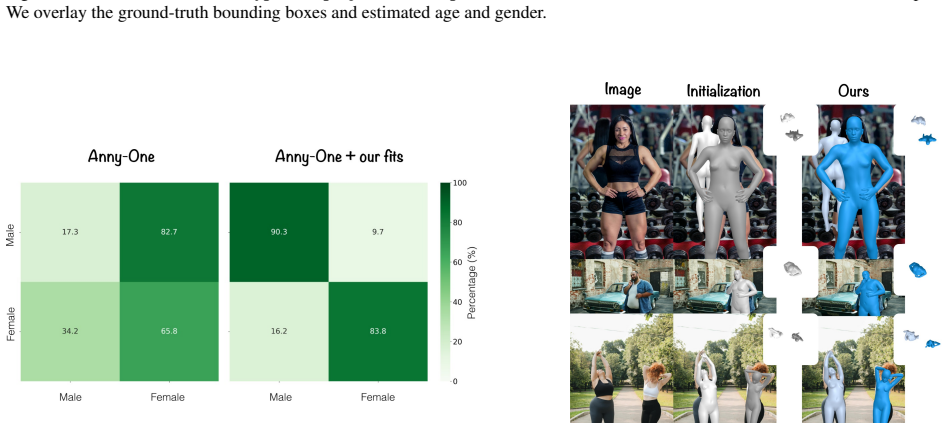
Anny-Fit is a multi-person camera-space optimization framework that fuses metric depth maps, instance segmentation, 2D keypoints, and VLM-derived age and gender attributes to jointly recover 3D human meshes across the full age spectrum. These signals together resolve the depth-scale ambiguity that arises when body proportions vary with age. The resulting meshes show higher 2D reprojection accuracy, better relative depth ordering, lower 3D error, and improved shape fidelity, while also supplying pseudo-ground-truth labels that let adult-trained HMR models learn semantically meaningful shape parameters without retraining.
What carries the argument
Joint camera-space optimization that integrates metric depth, instance segmentation, 2D keypoints, and age-gender attributes from off-the-shelf networks to constrain all-age multi-person scenes.
Load-bearing premise
The separate networks that supply depth maps, segmentations, keypoints, and age-gender labels must deliver signals accurate and complementary enough to resolve scale without introducing dominant new errors or biases.
What would settle it
Applying the method to a dataset of mixed-age group images with known 3D ground truth and observing that 3D joint errors or depth-ordering mistakes exceed those from standard per-person adult HMR methods would falsify the benefit of the joint optimization.
Figures











read the original abstract
Recovering 3D human pose and shape from a single image remains a cornerstone of human-centric vision, yet most methods assume adult subjects and optimize each person independently. These assumptions fail in real-world, all-age scenes, where body proportions and depth must be resolved jointly. We introduce Anny-Fit, a multi-person, camera-space optimization framework for all-age 3D human mesh recovery (HMR). Unlike existing per-person fitting methods, Anny-Fit jointly optimizes all individuals directly in the camera coordinate system, enforcing global spatial consistency. At the core of our approach is the use of multiple forms of expert knowledge -- including metric depth maps, instance segmentation, 2D keypoints, and, VLM-derived semantic attributes such as age and gender -- each obtained from dedicated off-the-shelf networks. These complementary signals jointly guide the optimization, constraining the depth-scale ambiguity characteristic of all-age scenes. Across diverse datasets, Anny-Fit consistently improves 2D reprojection accuracy (+13 to 16), relative depth ordering (+6 to 7), 3D estimation error (-9 to -29) and shape estimation (+25 to +82), producing more coherent scenes. Finally, we show that VLM-based semantic knowledge can be distilled into an HMR model via the pseudo-ground-truth annotations produced by Anny-Fit on training data, enabling it to learn semantically meaningful shape parameters while improving HMR performance. Our approach bridges adult-only and all-age modeling by enabling zero-shot adaptation of adult-trained HMR pipelines to the full age spectrum without retraining. Code is publicly available at https://github.com/naver/anny-fit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Anny-Fit, a multi-person camera-space optimization framework for all-age 3D human mesh recovery from single images. It jointly optimizes all persons using complementary signals from off-the-shelf networks (metric depth maps, instance segmentation, 2D keypoints, and VLM-derived age/gender attributes) to enforce global spatial consistency and resolve depth-scale ambiguity. The paper reports consistent quantitative improvements in 2D reprojection accuracy (+13 to 16), relative depth ordering (+6 to 7), 3D estimation error (-9 to -29), and shape estimation (+25 to +82), along with a distillation step that uses the optimized pseudo-ground-truth to inject semantic knowledge into standard HMR models for zero-shot all-age adaptation without retraining. Code is released publicly.
Significance. If the results hold under rigorous validation, the work is significant for bridging adult-centric HMR methods to realistic all-age multi-person scenes. The public code release supports reproducibility, and the distillation mechanism offers a practical route to incorporate VLM semantic priors into parametric body models.
major comments (2)
- [Methods (joint optimization)] The central optimization (described in the methods) assumes that off-the-shelf metric depth maps and VLM age/gender signals are sufficiently accurate and complementary to jointly constrain all persons without introducing dominant per-instance scale drift or age-specific biases. No quantitative error analysis or validation of these input signals on all-age data (especially ages under 10) is provided, which directly underpins the claimed gains in relative depth ordering and 3D error.
- [Experiments and results] The reported quantitative gains (e.g., +13 to 16 in 2D reprojection, -9 to -29 in 3D error) lack accompanying details on experimental protocol, baseline implementations, error bars, dataset splits, and ablations isolating each signal's contribution. This makes it impossible to verify whether the improvements are robust or attributable to the proposed joint formulation.
minor comments (2)
- [Abstract] The abstract refers to 'VLM-derived semantic attributes' without naming the specific VLM or extraction procedure; this detail should be added for clarity.
- [Methods] Notation for optimization variables and loss terms could be introduced with a summary table or equation list in the methods for easier reference.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment point by point below, providing clarifications from the manuscript and outlining revisions where needed to strengthen the presentation.
read point-by-point responses
-
Referee: [Methods (joint optimization)] The central optimization (described in the methods) assumes that off-the-shelf metric depth maps and VLM age/gender signals are sufficiently accurate and complementary to jointly constrain all persons without introducing dominant per-instance scale drift or age-specific biases. No quantitative error analysis or validation of these input signals on all-age data (especially ages under 10) is provided, which directly underpins the claimed gains in relative depth ordering and 3D error.
Authors: We agree that an explicit quantitative validation of the off-the-shelf signals on all-age data would strengthen the methodological justification. The manuscript relies on the complementarity of the signals (metric depth, segmentation, keypoints, and VLM attributes) to mitigate individual inaccuracies, as evidenced by the consistent improvements in relative depth ordering and 3D error across datasets. However, we did not include a dedicated error analysis of the input networks on young children. In the revised version, we will add a new subsection with quantitative evaluation of each signal's accuracy on all-age benchmarks (including ages under 10), along with an analysis of how the joint optimization reduces per-instance drift. revision: yes
-
Referee: [Experiments and results] The reported quantitative gains (e.g., +13 to 16 in 2D reprojection, -9 to -29 in 3D error) lack accompanying details on experimental protocol, baseline implementations, error bars, dataset splits, and ablations isolating each signal's contribution. This makes it impossible to verify whether the improvements are robust or attributable to the proposed joint formulation.
Authors: The experimental protocol, baseline implementations (including per-person fitting methods), dataset splits, and evaluation metrics are detailed in Section 4 and the supplementary material. That said, we acknowledge the referee's point that error bars, explicit ablations for each signal, and more granular protocol descriptions would improve verifiability. We will revise the experiments section to include standard error bars over multiple runs, a full ablation table isolating the contribution of depth, segmentation, keypoints, and VLM signals, and expanded descriptions of the baselines and splits. revision: yes
Circularity Check
No significant circularity: optimization relies on independent off-the-shelf signals and distillation uses separate evaluation
full rationale
The paper's core derivation uses metric depth, segmentation, 2D keypoints and VLM age/gender attributes from dedicated off-the-shelf networks as external inputs to a joint camera-space optimization. These signals are not derived from the fitted meshes themselves. The subsequent distillation step generates pseudo-GT meshes from Anny-Fit outputs to supervise an HMR model, but the reported gains (+13-16 reprojection, -9 to -29 3D error, etc.) are measured on held-out test data against external ground truth rather than reducing to quantities defined inside the same fitted equations. No load-bearing self-citations, self-definitional loops, or ansatz smuggling appear in the derivation chain; the framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- signal weighting coefficients
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 3, 4, 7
work page internal anchor Pith review arXiv 2025
-
[2]
Multi-hmr: Multi-person whole-body human mesh recovery in a single shot
Fabien Baradel, Matthieu Armando, Salma Galaaoui, Ro- main Br ´egier, Philippe Weinzaepfel, Gr ´egory Rogez, and Thomas Lucas. Multi-hmr: Multi-person whole-body human mesh recovery in a single shot. InEuropean Conference on Computer Vision, pages 202–218. Springer, 2024. 2, 3, 6
2024
-
[3]
Chat- garment: Garment estimation, generation and editing via large language models
Siyuan Bian, Chenghao Xu, Yuliang Xiu, Artur Grigorev, Zhen Liu, Cewu Lu, Michael J Black, and Yao Feng. Chat- garment: Garment estimation, generation and editing via large language models. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 2924–2934,
-
[4]
Keep it smpl: Automatic estimation of 3d human pose and shape from a single image
Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J Black. Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. InEuropean conference on computer vision, pages 561–578. Springer, 2016. 2
2016
-
[5]
Ask, pose, unite: Scaling data acquisi- tion for close interaction meshes with vision language mod- els
Laura Bravo-S ´anchez, Jaewoo Heo, Zhenzhen Weng, and Kuan-Chieh Wang. Ask, pose, unite: Scaling data acquisi- tion for close interaction meshes with vision language mod- els. InSynthetic Data for Computer Vision Workshop@ CVPR 2025, 2025. 2
2025
-
[6]
Condimen: Conditional multi-person mesh recovery
Romain Br ´egier, Fabien Baradel, Thomas Lucas, Salma Galaaoui, Matthieu Armando, Philippe Weinzaepfel, and Gr´egory Rogez. Condimen: Conditional multi-person mesh recovery. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3880–3890, 2025. 2, 3, 8
2025
-
[7]
Human mesh modeling for anny body.arXiv preprint arXiv:2511.03589, 2025
Romain Br ´egier, Gu ´enol´e Fiche, Laura Bravo-S ´anchez, Thomas Lucas, Matthieu Armando, Philippe Weinzaepfel, Gr´egory Rogez, and Fabien Baradel. Human mesh modeling for anny body.arXiv preprint arXiv:2511.03589, 2025. 2, 3, 4, 6, 7, 1
-
[8]
Meyer, Yuning Chai, Dennis Park, and Yong Jae Lee
Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, and Yong Jae Lee. Mak- ing large multimodal models understand arbitrary visual prompts. InIEEE Conference on Computer Vision and Pat- tern Recognition, 2024. 7
2024
-
[9]
Accurate 3d body shape regression using metric and semantic attributes
Vasileios Choutas, Lea M ¨uller, Chun-Hao P Huang, Siyu Tang, Dimitrios Tzionas, and Michael J Black. Accurate 3d body shape regression using metric and semantic attributes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2718–2728, 2022. 2, 3
2022
-
[10]
Adversarial parametric pose prior
Andrey Davydov, Anastasia Remizova, Victor Constantin, Sina Honari, Mathieu Salzmann, and Pascal Fua. Adversarial parametric pose prior. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 10997–11005, 2022. 3
2022
-
[11]
PoseScript: Linking 3D Human Poses and Natural Lan- guage.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Delmas, Ginger and Weinzaepfel, Philippe and Lucas, Thomas and Moreno-Noguer, Francesc and Rogez, Gr´egory. PoseScript: Linking 3D Human Poses and Natural Lan- guage.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 3
2024
-
[12]
PoseFix: Correcting 3D Human Poses with Natural Language
Delmas, Ginger and Weinzaepfel, Philippe and Moreno- Noguer, Francesc and Rogez, Gr´egory. PoseFix: Correcting 3D Human Poses with Natural Language. InProceedings of the IEEE/CVF international conference on computer vision (ICCV), 2023
2023
-
[13]
PoseEmbroider: Towards a 3D, Visual, Semantic-aware Human Pose Rep- resentation
Delmas, Ginger and Weinzaepfel, Philippe and Moreno- Noguer, Francesc and Rogez, Gr ´egory. PoseEmbroider: Towards a 3D, Visual, Semantic-aware Human Pose Rep- resentation. InEuropean Conference on Computer Vision (ECCV), 2024. 3
2024
-
[14]
Teach clip to develop a number sense for ordinal regression
Yao Du, Qiang Zhai, Weihang Dai, and Xiaomeng Li. Teach clip to develop a number sense for ordinal regression. InEuropean Conference on Computer Vision, pages 1–17. Springer, 2024. 5
2024
-
[15]
Chatpose: Chatting about 3d human pose
Yao Feng, Jing Lin, Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, and Michael J Black. Chatpose: Chatting about 3d human pose. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2093–2103,
2093
-
[16]
Three- dimensional reconstruction of human interactions
Mihai Fieraru, Mihai Zanfir, Elisabeta Oneata, Alin-Ionut Popa, Vlad Olaru, and Cristian Sminchisescu. Three- dimensional reconstruction of human interactions. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7214–7223, 2020. 3
2020
-
[17]
Humans in 4d: Re- constructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Re- constructing and tracking humans with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14783–14794, 2023. 2
2023
-
[18]
Computer vision for medical infant motion analysis: State of the art and rgb-d data set
Nikolas Hesse, Christoph Bodensteiner, Michael Arens, Ulrich G Hofmann, Raphael Weinberger, and A Sebas- tian Schroeder. Computer vision for medical infant motion analysis: State of the art and rgb-d data set. InProceed- ings of the European conference on computer vision (ECCV) workshops, pages 0–0, 2018. 3
2018
-
[19]
Learning an infant body model from rgb-d data for accurate full body motion analysis
Nikolas Hesse, Sergi Pujades, Javier Romero, Michael J Black, Christoph Bodensteiner, Michael Arens, Ulrich G Hofmann, Uta Tacke, Mijna Hadders-Algra, Raphael Wein- berger, et al. Learning an infant body model from rgb-d data for accurate full body motion analysis. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention, ...
2018
-
[20]
Closely interactive human reconstruction with proxemics and physics-guided adaption
Buzhen Huang, Chen Li, Chongyang Xu, Liang Pan, Yan- gang Wang, and Gim Hee Lee. Closely interactive human reconstruction with proxemics and physics-guided adaption. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1011–1021, 2024. 3
2024
-
[21]
Panoptic studio: A massively multiview sys- tem for social interaction capture.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2017
Hanbyul Joo, Tomas Simon, Xulong Li, Hao Liu, Lei Tan, Lin Gui, Sean Banerjee, Timothy Scott Godisart, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh. Panoptic studio: A massively multiview sys- tem for social interaction capture.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2017. 6, 3
2017
-
[22]
End-to-end recovery of human shape and pose
Angjoo Kanazawa, Michael J Black, David W Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7122–7131, 2018. 3 9
2018
-
[23]
Harmony4d: A video dataset for in- the-wild close human interactions.Advances in Neural In- formation Processing Systems, 37:107270–107285, 2024
Rawal Khirodkar, Jyun-Ting Song, Jinkun Cao, Zhengyi Luo, and Kris Kitani. Harmony4d: A video dataset for in- the-wild close human interactions.Advances in Neural In- formation Processing Systems, 37:107270–107285, 2024. 3
2024
-
[24]
Learning to reconstruct 3d human pose and shape via model-fitting in the loop
Nikos Kolotouros, Georgios Pavlakos, Michael J Black, and Kostas Daniilidis. Learning to reconstruct 3d human pose and shape via model-fitting in the loop. InProceedings of the IEEE/CVF international conference on computer vision, pages 2252–2261, 2019. 2, 3
2019
-
[25]
Cliff: Carrying location information in full frames into human pose and shape estimation
Zhihao Li, Jianzhuang Liu, Zhensong Zhang, Songcen Xu, and Youliang Yan. Cliff: Carrying location information in full frames into human pose and shape estimation. InEuro- pean Conference in Computer Vision, 2022. 3
2022
-
[26]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 8
2014
-
[27]
Improved baselines with visual instruction tuning, 2023
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2023. 3
2023
-
[28]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023. 3
2023
-
[29]
Smpl: A skinned multi- person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi- person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023. 3, 6
2023
-
[30]
Junzhe Lu, Jing Lin, Hongkun Dou, Ailing Zeng, Yue Deng, Xian Liu, Zhongang Cai, Lei Yang, Yulun Zhang, Hao- qian Wang, and Ziwei Liu. Dposer-x: Diffusion model as robust 3d whole-body human pose prior.arXiv preprint arXiv:2508.00599, 2025. 3
-
[31]
SmolVLM: Redefining small and efficient multimodal models
Andr ´es Marafioti, Orr Zohar, Miquel Farr ´e, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, et al. Smolvlm: Redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299, 2025. 7
work page internal anchor Pith review arXiv 2025
-
[32]
V olumetricsmpl: A neural volumet- ric body model for efficient interactions, contacts, and colli- sions
Marko Mihajlovic, Siwei Zhang, Gen Li, Kaifeng Zhao, Lea Muller, and Siyu Tang. V olumetricsmpl: A neural volumet- ric body model for efficient interactions, contacts, and colli- sions. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 5060–5070, 2025. 8
2025
-
[33]
On self-contact and human pose
Lea Muller, Ahmed AA Osman, Siyu Tang, Chun-Hao P Huang, and Michael J Black. On self-contact and human pose. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 9990–9999,
-
[34]
Generative proxemics: A prior for 3d social interaction from images
Lea Muller, Vickie Ye, Georgios Pavlakos, Michael Black, and Angjoo Kanazawa. Generative proxemics: A prior for 3d social interaction from images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9687–9697, 2024. 2
2024
-
[35]
Black, and Angjoo Kanazawa
Lea Muller, Vickie Ye, Georgios Pavlakos, Michael J. Black, and Angjoo Kanazawa. Generative proxemics: A prior for 3D social interaction from images. 2024. 3, 6, 8
2024
-
[36]
Camerahmr: Aligning people with perspective
Priyanka Patel and Michael J Black. Camerahmr: Aligning people with perspective. In2025 International Conference on 3D Vision (3DV), pages 1562–1571. IEEE, 2025. 2, 3, 5, 6, 7, 8
2025
-
[37]
Agora: Avatars in geography optimized for regression analysis
Priyanka Patel, Chun-Hao P Huang, Joachim Tesch, David T Hoffmann, Shashank Tripathi, and Michael J Black. Agora: Avatars in geography optimized for regression analysis. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 13468–13478, 2021. 2, 3
2021
-
[38]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10975–10985, 2019. 3
2019
-
[39]
Pexels stock photos.https://www.pexels
Pexels. Pexels stock photos.https://www.pexels. com/, 2025. 3
2025
-
[40]
Unidepthv2: Universal monocular metric depth estimation made simpler
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mat- tia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. UniDepthV2: Universal monocular metric depth estimation made simpler.arXiv preprint arXiv:2502.20110, 2025. 6
-
[41]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kun- chang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159, 2024. 6
work page internal anchor Pith review arXiv 2024
-
[42]
Dex: Deep expectation of apparent age from a single image
Rasmus Rothe, Radu Timofte, and Luc Van Gool. Dex: Deep expectation of apparent age from a single image. InProceed- ings of the IEEE international conference on computer vision workshops, pages 10–15, 2015. 3
2015
-
[43]
Neural localizer fields for continuous 3d human pose and shape estimation
Istv ´an S ´ar´andi and Gerard Pons-Moll. Neural localizer fields for continuous 3d human pose and shape estimation. Advances in Neural Information Processing Systems, 37: 140032–140065, 2024. 1
2024
-
[44]
Syn- thetic training for accurate 3d human pose and shape esti- mation in the wild
Akash Sengupta, Ignas Budvytis, and Roberto Cipolla. Syn- thetic training for accurate 3d human pose and shape esti- mation in the wild. InBritish Machine Vision Conference (BMVC), 2020. 3
2020
-
[45]
Deep regression forests for age estimation
Wei Shen, Yilu Guo, Yan Wang, Kai Zhao, Bo Wang, and Alan L Yuille. Deep regression forests for age estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2304–2313, 2018. 3
2018
-
[46]
Body talk: Crowdshaping realistic 3d avatars with words.ACM Transactions on Graphics (TOG), 35(4):1–14, 2016
Stephan Streuber, M Alejandra Quiros-Ramirez, Matthew Q Hill, Carina A Hahn, Silvia Zuffi, Alice O’Toole, and Michael J Black. Body talk: Crowdshaping realistic 3d avatars with words.ACM Transactions on Graphics (TOG), 35(4):1–14, 2016. 3
2016
-
[47]
Sat- hmr: Real-time multi-person 3d mesh estimation via scale- adaptive tokens
Chi Su, Xiaoxuan Ma, Jiajun Su, and Yizhou Wang. Sat- hmr: Real-time multi-person 3d mesh estimation via scale- adaptive tokens. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2025. 3, 6
2025
-
[48]
Aios: All-in-one-stage expressive human pose and shape estimation
Qingping Sun, Yanjun Wang, Ailing Zeng, Wanqi Yin, Chen Wei, Wenjia Wang, Haiyi Mei, Chi-Sing Leung, Ziwei Liu, Lei Yang, et al. Aios: All-in-one-stage expressive human pose and shape estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[49]
Monocular, One-stage, Regression of Multiple 3D People
Yu Sun, Qian Bao, Wu Liu, Yili Fu, Black Michael J., and 10 Tao Mei. Monocular, One-stage, Regression of Multiple 3D People. InICCV, 2021
2021
-
[50]
Putting people in their place: Monocular regression of 3d people in depth
Yu Sun, Wu Liu, Qian Bao, Yili Fu, Tao Mei, and Michael J Black. Putting people in their place: Monocular regression of 3d people in depth. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13243–13252, 2022. 2, 3, 6, 7, 1
2022
-
[51]
Deco: Dense estimation of 3d human-scene contact in the wild
Shashank Tripathi, Agniv Chatterjee, Jean-Claude Passy, Hongwei Yi, Dimitrios Tzionas, and Michael J Black. Deco: Dense estimation of 3d human-scene contact in the wild. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8001–8013, 2023. 2
2023
-
[52]
Body size and depth disambiguation in multi-person reconstruction from single images
Nicolas Ugrinovic, Adria Ruiz, Antonio Agudo, Alberto Sanfeliu, and Francesc Moreno-Noguer. Body size and depth disambiguation in multi-person reconstruction from single images. In2021 International Conference on 3D Vision (3DV), pages 53–63. IEEE, 2021. 2, 3, 7
2021
-
[53]
arXiv preprint arXiv:2511.13282 (2025) 6, 14, 26
Kaiwen Wang, Kaili Zheng, Yiming Shi, Chenyi Guo, and Ji Wu. Towards metric-aware multi-person mesh recovery by jointly optimizing human crowd in camera space.arXiv preprint arXiv:2511.13282, 2025. 3
-
[54]
Refit: Recurrent fit- ting network for 3d human recovery
Yufu Wang and Kostas Daniilidis. Refit: Recurrent fit- ting network for 3d human recovery. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14644–14654, 2023. 2
2023
-
[55]
Prompthmr: Promptable human mesh recovery
Yufu Wang, Yu Sun, Priyanka Patel, Kostas Daniilidis, Michael J Black, and Muhammed Kocabas. Prompthmr: Promptable human mesh recovery. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1148–1159, 2025. 2, 3
2025
-
[56]
Humphreys, Lee M
Zhenzhen Weng, Laura Bravo-S ´anchez, Zeyu Wang, Christopher Howard, Maria Xenochristou, Nicole Meis- ter, Angjoo Kanazawa, Arnold Milstein, Elika Bergelson, Kathryn L. Humphreys, Lee M. Sanders, and Serena Yeung- Levy. Artificial intelligence–powered 3d analysis of video- based caregiver-child interactions.Science Advances, 11(8): eadp4422, 2025. 3
2025
-
[57]
Reconstructing humans with a biome- chanically accurate skeleton
Yan Xia, Xiaowei Zhou, Etienne V ouga, Qixing Huang, and Georgios Pavlakos. Reconstructing humans with a biome- chanically accurate skeleton. InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 5355–5365, 2025. 2
2025
-
[58]
Ghum & ghuml: Generative 3d human shape and articulated pose models
Hongyi Xu, Eduard Gabriel Bazavan, Andrei Zanfir, William T Freeman, Rahul Sukthankar, and Cristian Smin- chisescu. Ghum & ghuml: Generative 3d human shape and articulated pose models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6184–6193, 2020. 3
2020
-
[59]
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. Vitpose+: Vision transformer foundation model for generic body pose estimation.arXiv preprint arXiv:2212.04246,
-
[60]
Hi4d: 4d instance segmentation of close human interaction
Yifei Yin, Chen Guo, Manuel Kaufmann, Juan Zarate, Jie Song, and Otmar Hilliges. Hi4d: 4d instance segmentation of close human interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[61]
Monocular 3d pose and shape estimation of mul- tiple people in natural scenes-the importance of multiple scene constraints
Andrei Zanfir, Elisabeta Marinoiu, and Cristian Sminchis- escu. Monocular 3d pose and shape estimation of mul- tiple people in natural scenes-the importance of multiple scene constraints. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2148–2157,
-
[62]
Pymaf-x: To- wards well-aligned full-body model regression from monoc- ular images.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 45(10):12287–12303, 2023
Hongwen Zhang, Yating Tian, Yuxiang Zhang, Mengcheng Li, Liang An, Zhenan Sun, and Yebin Liu. Pymaf-x: To- wards well-aligned full-body model regression from monoc- ular images.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 45(10):12287–12303, 2023. 2
2023
-
[63]
Metrichmr: Metric human mesh recovery from monocular images.arXiv preprint arXiv:2506.09919, 2025
He Zhang, Chentao Song, Hongwen Zhang, and Tao Yu. Metrichmr: Metric human mesh recovery from monocular images.arXiv preprint arXiv:2506.09919, 2025. 2, 3
-
[64]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language mod- els.arXiv preprint arXiv:2303.18223, 2023. 5
work page internal anchor Pith review arXiv 2023
-
[65]
Single view metrology in the wild
Rui Zhu, Xingyi Yang, Yannick Hold-Geoffroy, Federico Perazzi, Jonathan Eisenmann, Kalyan Sunkavalli, and Man- mohan Chandraker. Single view metrology in the wild. In European Conference on Computer Vision, pages 316–333. Springer, 2020. 2
2020
-
[66]
Kbody: Towards general, robust, and aligned monocular whole-body estima- tion
Nikolaos Zioulis and James F O’Brien. Kbody: Towards general, robust, and aligned monocular whole-body estima- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 6215–6225,
-
[67]
2 11 Anny-Fit: All-Age Human Mesh Recovery Supplementary Material
-
[68]
Age estimation prompt
Implementation details 7.1. Anny model mapping We utilize the semantic shape space of the Anny model [7] to propose a direct mapping from shape attribute descrip- tors to normalized shape values. This mapping inherently accounts for the body model interpolation described in the same work. Figure 9 illustrates our complete mapping scheme for all experiment...
-
[69]
Experiment details 8.1. Metrics Percentage of Correct Keypoints (PCK). To robustly ac- count for missing keypoint detections, prior work often as- signs a fixed “punishment value” to unmatched predictions when computing the MPJPE. However, such heuristics dis- tort the numerical scale of the evaluation and can introduce undesirable incentives—e.g., a miss...
-
[70]
As a case study, we explore diverse body shapes
Beyond all-age shape estimation While not our primary objective, our shape estimation for- mulation generalizes to account for attributes beyond age and gender. As a case study, we explore diverse body shapes. To manage a diverse range of shapes with a com- pact categorization for VLM querying, we define a dis- crete mapping to weight and muscle attribute...
-
[71]
While this multi-expert strat- egy improves robustness, it also makes performance depen- dent on the accuracy of each expert
Limitations Our method integrates multiple expert predictions to guide the optimization for all-age human reconstruction, which enhances overall robustness. While this multi-expert strat- egy improves robustness, it also makes performance depen- dent on the accuracy of each expert. Errors in keypoints or depth under occlusion or extreme viewpoints can pro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.