Recognition: no theorem link
Hierarchical Multiagent Reinforcement Learning for Multi-Group Tax Game
Pith reviewed 2026-05-12 01:48 UTC · model grok-4.3
The pith
A bilevel multi-agent reinforcement learning framework with curriculum learning and closed-loop sequential updates learns stable tax policies in multi-group competitive games.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that taxation can be modeled as a hierarchical multi-group game with intra-group leader-follower dynamics and inter-group competition, and that a bilevel MARL framework equipped with curriculum learning and closed-loop sequential updates solves this structure well enough to produce stable, sustainable tax policies that prevent premature game collapse.
What carries the argument
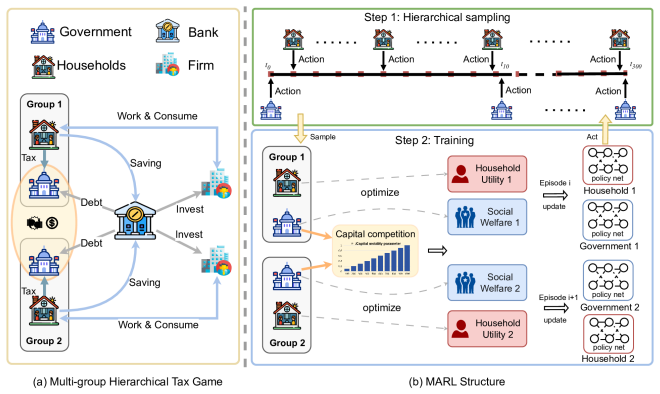
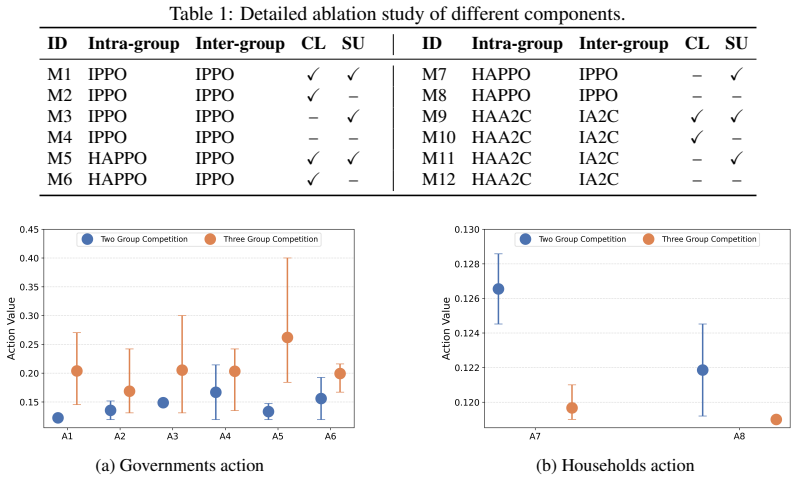
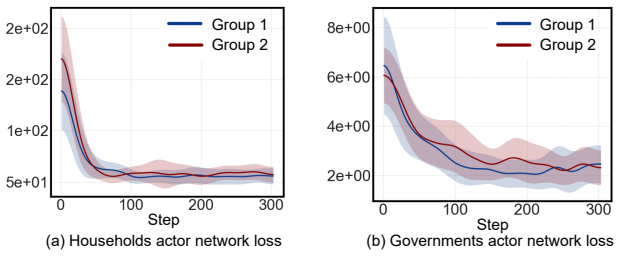
Bilevel MARL framework that separates intra-group leader-follower interactions from inter-group government competition, trained with curriculum learning to ramp up complexity and closed-loop sequential updates to maintain training stability.
If this is right
- Stable tax policies emerge without premature game collapse in multi-group settings.
- Effective game duration extends by 60.92 percent compared with a baseline lacking the proposed mechanisms.
- GDP disparities among governments shrink by 44.12 percent.
- Fiscal policies can be trained to handle inter-group spillovers while preserving household responses within each group.
Where Pith is reading between the lines
- The same bilevel structure could be applied to other multi-government policy domains such as trade tariffs or environmental regulations.
- Integration with empirical tax data from real countries would test whether the learned policies match observed outcomes.
- Scaling the number of groups beyond two may introduce new coordination failures that require further curriculum adjustments.
Load-bearing premise
The taxation simulation environment grounded in classical economic models sufficiently captures the strategic interactions, household responses, and inter-group spillovers of real multi-government tax competition.
What would settle it
Running the proposed bilevel method in the same simulation and finding no increase in game duration or reduction in GDP disparities relative to the two-group baseline would falsify the stability claim.
Figures







read the original abstract
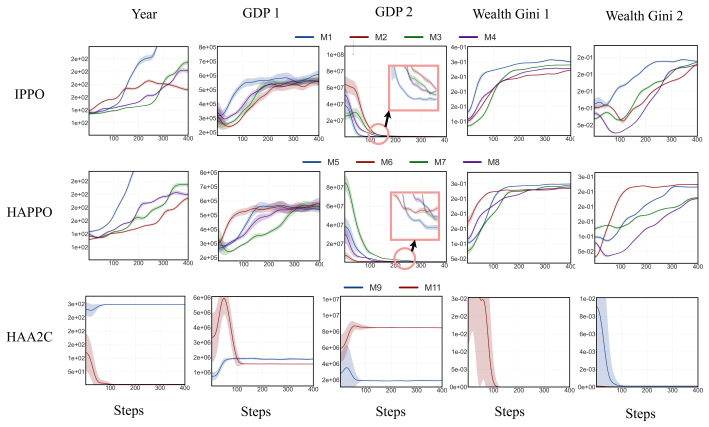
Reinforcement learning has increasingly been applied to economic decision-making, including taxation, public spending, and labor supply. However, existing RL-based economic models typically consider only a single government-household group, overlooking strategic interactions among competing governments. To address this limitation, we formulate taxation as a hierarchical multi-group game. Within each group, the government and households form a leader--follower game, while governments compete across groups through strategic fiscal policies. This coupled structure is difficult to solve using standard multi-agent reinforcement learning (MARL) methods. We therefore propose a bilevel MARL framework with \textit{Curriculum Learning} and a \textit{Closed-Loop Sequential Update} mechanism to improve training stability and convergence. We instantiate the framework in a taxation simulation environment grounded in classical economic models, supporting the evaluation of taxation policies under inter-group competition. Experiments show that the proposed method learns stable and sustainable tax policies. Compared with a two-group baseline without the proposed mechanisms, our approach avoids premature game collapse, extends the effective game duration by 60.92\%, and reduces GDP disparities among governments by 44.12\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates taxation as a hierarchical multi-group game in which each group consists of a government-household leader-follower pair and governments compete across groups via fiscal policies. It introduces a bilevel MARL framework that augments standard training with curriculum learning and a closed-loop sequential update rule to improve stability. Experiments in a custom simulator grounded in classical economic models report that the method avoids premature collapse, extends effective game duration by 60.92%, and reduces GDP disparities by 44.12% relative to a two-group baseline lacking these mechanisms.
Significance. If the reported stability gains can be shown to be robust and not artifacts of the simulator, the work would supply a concrete hierarchical MARL architecture for multi-agent economic policy problems and demonstrate measurable improvements in avoiding collapse under inter-group competition.
major comments (2)
- [Experiments] Experiments section: the headline metrics (60.92% extension in game duration and 44.12% reduction in GDP disparity) are reported without the number of independent runs, standard deviations across random seeds, or any statistical significance tests, leaving the central performance claim only partially supported.
- [Simulation Environment] Simulation environment description: no calibration against observed tax-competition equilibria, no sensitivity sweeps on inter-group spillover or household labor-supply parameters, and no comparison of emergent tax rates to closed-form predictions from the underlying game-theoretic model are provided; without these checks the stability improvements cannot be distinguished from environment-specific artifacts.
minor comments (2)
- [Abstract and §3] The abstract and method sections should explicitly state whether the two-group baseline implements the same bilevel structure but omits only the curriculum and closed-loop mechanisms, or whether it uses an entirely different architecture.
- [§3] Notation for government and household value functions and policy updates should be unified across the bilevel formulation and the update-rule equations to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below, indicating the changes we will make to the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline metrics (60.92% extension in game duration and 44.12% reduction in GDP disparity) are reported without the number of independent runs, standard deviations across random seeds, or any statistical significance tests, leaving the central performance claim only partially supported.
Authors: We agree that statistical details are necessary to fully support the central claims. The headline metrics were computed over multiple independent training runs with different random seeds, but these details were omitted from the initial submission. In the revised manuscript we will report the exact number of runs, the mean and standard deviation of game duration and GDP disparity across seeds, and the results of statistical significance tests (e.g., two-sample t-tests) comparing our method against the baseline. revision: yes
-
Referee: [Simulation Environment] Simulation environment description: no calibration against observed tax-competition equilibria, no sensitivity sweeps on inter-group spillover or household labor-supply parameters, and no comparison of emergent tax rates to closed-form predictions from the underlying game-theoretic model are provided; without these checks the stability improvements cannot be distinguished from environment-specific artifacts.
Authors: The environment is constructed directly from classical economic models of taxation, labor supply, and inter-group competition, as described in Section 3. We will add sensitivity sweeps over the inter-group spillover coefficient and household labor-supply elasticity parameters in the revised manuscript to demonstrate robustness. Direct calibration to observed real-world tax-competition equilibria and closed-form solutions for the full hierarchical multi-group game are not feasible within the scope of this work, as suitable multi-group empirical datasets are unavailable and analytic solutions for the bilevel stochastic game are intractable; we will instead include a qualitative discussion of how emergent tax rates align with predictions from simplified single-group and two-group cases and will explicitly list these validations as limitations. revision: partial
- Calibration against observed real-world tax-competition equilibria and direct comparison of emergent rates to closed-form predictions for the complete hierarchical model.
Circularity Check
No significant circularity in framework derivation or experimental claims
full rationale
The paper defines a bilevel MARL framework with curriculum learning and closed-loop sequential updates to address stability in a hierarchical multi-group tax game. This structure is constructed from standard leader-follower and inter-group competition primitives rather than self-referential definitions. Experimental gains (60.92% longer duration, 44.12% lower GDP disparity) are measured against an explicit baseline that omits the proposed mechanisms, supplying an independent comparison. No load-bearing self-citations, fitted parameters renamed as predictions, or ansatzes imported from prior author work appear in the derivation chain. The simulation is instantiated from classical economic models, but the central claims remain falsifiable outcomes of the training procedure rather than reductions to the inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- Curriculum progression schedule
- Closed-loop update timing parameters
axioms (1)
- domain assumption The leader-follower structure within groups and strategic competition across groups accurately represent real-world multi-government tax dynamics.
Reference graph
Works this paper leans on
-
[1]
S. Rao Aiyagari. Uninsured idiosyncratic risk and aggregate saving*. The Quarterly Journal of Economics, 109(3):659–684, 08 1994
work page 1994
-
[2]
S. Rao Aiyagari. Optimal capital income taxation with incomplete markets, borrowing con- straints, and constant discounting. Journal of Political Economy, 103(6):1158–1175, 1995
work page 1995
-
[3]
Lectures on public economics: Updated edition
Anthony B Atkinson and Joseph E Stiglitz. Lectures on public economics: Updated edition. Princeton University Press, 2015
work page 2015
-
[4]
Why agents?: on the varied motivations for agent computing in the social sciences, volume 17
Robert Axtell. Why agents?: on the varied motivations for agent computing in the social sciences, volume 17. Center on Social and Economic Dynamics Washington, DC, 2000
work page 2000
-
[5]
Roland Benabou. Tax and education policy in a heterogeneous-agent economy: What levels of redistribution maximize growth and efficiency? Econometrica, 70(2):481–517, 2002
work page 2002
-
[6]
Stackelberg pomdp: A reinforcement learning approach for economic design
Gianluca Brero, Alon Eden, Darshan Chakrabarti, Matthias Gerstgrasser, Amy Greenwald, Vincent Li, and David C Parkes. Stackelberg pomdp: A reinforcement learning approach for economic design. arXiv preprint arXiv:2210.03852, 2022
-
[7]
Optimal taxation of capital income in general equilibrium with infinite lives
Christophe Chamley. Optimal taxation of capital income in general equilibrium with infinite lives. Econometrica: Journal of the Econometric Society, pages 607–622, 1986
work page 1986
-
[8]
Deep reinforce- ment learning in a monetary model
Mingli Chen, Andreas Joseph, Michael Kumhof, Xinlei Pan, and Xuan Zhou. Deep reinforce- ment learning in a monetary model. arXiv preprint arXiv:2104.09368, 2021
-
[9]
An overview of bilevel optimization
Benoît Colson, Patrice Marcotte, and Gilles Savard. An overview of bilevel optimization. Annals of operations research, 153(1):23–56, 2007
work page 2007
-
[10]
Michael Curry, Alexander Trott, Soham Phade, Yu Bai, and Stephan Zheng. Analyzing micro- founded general equilibrium models with many agents using deep reinforcement learning.arXiv preprint arXiv:2201.01163, 2022
-
[11]
Christian Schroeder De Witt, Tarun Gupta, Denys Makoviichuk, Viktor Makoviychuk, Philip HS Torr, Mingfei Sun, and Shimon Whiteson. Is independent learning all you need in the starcraft multi-agent challenge? arXiv preprint arXiv:2011.09533, 2020
- [12]
-
[13]
Optimal tax progressivity: An analytical framework
Jonathan Heathcote, Kjetil Storesletten, and Giovanni L Violante. Optimal tax progressivity: An analytical framework. The Quarterly Journal of Economics, 132(4):1693–1754, 2017
work page 2017
-
[14]
Optimal monetary policy using reinforcement learning
Natascha Hinterlang and Alina Tänzer. Optimal monetary policy using reinforcement learning. 2021
work page 2021
-
[15]
Dynamics of the mixed economy: Toward a theory of interventionism
Sanford Ikeda. Dynamics of the mixed economy: Toward a theory of interventionism. Rout- ledge, 2002
work page 2002
- [16]
-
[17]
Fiscal competition and the pattern of public spending
Michael Keen and Maurice Marchand. Fiscal competition and the pattern of public spending. Journal of Public Economics, 66(1):33–53, 1997
work page 1997
-
[18]
Multi-agent actor-critic for mixed cooperative-competitive environments
Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. Advances in neural information processing systems, 30, 2017. 10
work page 2017
-
[19]
arXiv preprint arXiv:2309.16307 , year=
Qirui Mi, Siyu Xia, Yan Song, Haifeng Zhang, Shenghao Zhu, and Jun Wang. Taxai: A dynamic economic simulator and benchmark for multi-agent reinforcement learning. arXiv preprint arXiv:2309.16307, 2023
-
[20]
Learning macroeconomic policies through dynamic stackelberg mean-field games
Qirui Mi, Zhiyu Zhao, Chengdong Ma, Siyu Xia, Yan Song, Mengyue Yang, Jun Wang, and Haifeng Zhang. Learning macroeconomic policies through dynamic stackelberg mean-field games. arXiv preprint arXiv:2403.12093, 2024
-
[21]
An exploration in the theory of optimum income taxation
James A Mirrlees. An exploration in the theory of optimum income taxation. The review of economic studies, 38(2):175–208, 1971
work page 1971
-
[22]
Deep reinforcement learning and macroeconomic modelling
Rui Aruhan Shi. Deep reinforcement learning and macroeconomic modelling. PhD thesis, University of Warwick, 2023
work page 2023
-
[23]
arXiv preprint arXiv:2108.02904 , year=
Alexander Trott, Sunil Srinivasa, Douwe van der Wal, Sebastien Haneuse, and Stephan Zheng. Building a foundation for data-driven, interpretable, and robust policy design using the ai economist. arXiv preprint arXiv:2108.02904, 2021
-
[24]
Springer Science & Business Media, 2011
Heinrich V on Stackelberg.Market Structure and Equilibrium. Springer Science & Business Media, 2011. First published in 1934, this is the translation
work page 2011
-
[25]
John Douglas Wilson. Theories of tax competition. National tax journal, 52(2):269–304, 1999
work page 1999
-
[26]
The surprising effectiveness of ppo in cooperative multi-agent games
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games. Advances in neural information processing systems, 35:24611–24624, 2022
work page 2022
-
[27]
Kaiqing Zhang, Zhuoran Yang, and Tamer Ba¸ sar. Multi-agent reinforcement learning: A selective overview of theories and algorithms.Handbook of reinforcement learning and control, pages 321–384, 2021
work page 2021
-
[28]
The ai economist: Taxation policy design via two-level deep multiagent reinforcement learning
Stephan Zheng, Alexander Trott, Sunil Srinivasa, David C Parkes, and Richard Socher. The ai economist: Taxation policy design via two-level deep multiagent reinforcement learning. Science advances, 8(18):eabk2607, 2022
work page 2022
-
[29]
Heterogeneous-agent reinforcement learning
Yifan Zhong, Jakub Grudzien Kuba, Xidong Feng, Siyi Hu, Jiaming Ji, and Yaodong Yang. Heterogeneous-agent reinforcement learning. Journal of Machine Learning Research, 25(32):1– 67, 2024
work page 2024
-
[30]
George R. Zodrow and Peter Mieszkowski. Pigou, tiebout, property taxation, and the underpro- vision of local public goods. Journal of Urban Economics, 19(3):356–370, 1986. 11 A Bewley–Aiyagari Model The Bewley–Aiyagari model describes a minimal economic circulation system that includes four entities: household, government, firm, and financial intermediary...
work page 1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.