Recognition: unknown
How Does Chunking Affect Retrieval-Augmented Code Completion? A Controlled Empirical Study
Pith reviewed 2026-05-08 17:23 UTC · model grok-4.3
The pith
Chunking strategy significantly affects retrieval-augmented code completion quality, with function chunking performing the worst.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Chunking strategy has a statistically significant effect on RAG-based code completion. Function chunking underperforms all other strategies by 3.57--5.64 percentage points on RepoEval with Cliff's delta of -1.0 and is never Pareto-optimal. Sliding Window and cAST strategies dominate both benchmarks. Cross-file context length is the dominant parameter, improving results by up to 4.2 points when doubled, while chunk size shows weaker, non-monotonic effects. The patterns hold across all retriever-generator combinations.
What carries the argument
The large-scale controlled experiment that crosses four chunking strategies with retrievers and generators to measure isolated effects on code completion performance.
If this is right
- Function chunking should be replaced by sliding window or cAST methods to improve completion accuracy without added cost.
- Doubling cross-file context length provides a straightforward way to gain up to 4.2 percentage points in performance.
- Chunk size tuning is less critical since its impact is weaker and varies non-monotonically.
- Sliding Window and cAST chunking achieve the best tradeoffs on the cost-quality Pareto front for both benchmarks.
Where Pith is reading between the lines
- Code tool developers could improve their RAG pipelines immediately by adopting non-function chunking strategies.
- Preserving contiguous code context appears more valuable for retrieval than aligning with program structure boundaries.
- The effect might generalize to other code intelligence tasks that use retrieval, such as test generation or repair.
- Replications in additional languages or with newer models would strengthen or limit the applicability of these results.
Load-bearing premise
The measured differences in performance stem directly from the choice of chunking strategy and are not driven by unexamined interactions with the specific retrievers, generators, or benchmark properties.
What would settle it
A follow-up experiment using different retrievers or benchmarks where function chunking performs equally well or better would indicate that the effect is not general.
Figures




read the original abstract
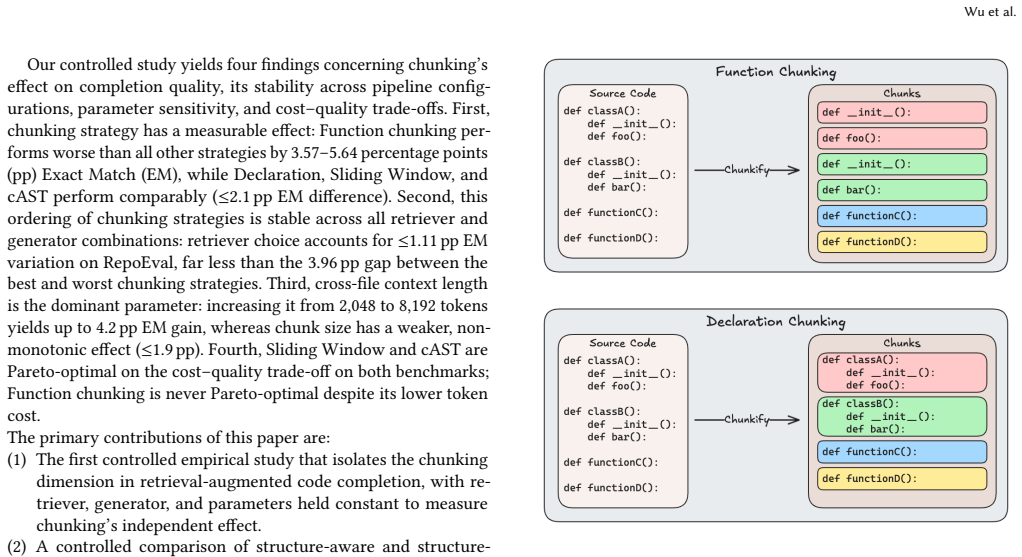
Retrieval-augmented generation (RAG) pipelines for code completion rely on chunking to segment source files into retrievable units, yet chunking strategies are typically adopted without empirical justification, and practitioner recommendations are notably inconsistent. We present a controlled empirical study isolating the effect of chunking on code completion quality by crossing four representative strategies (Function, Declaration, Sliding Window, and cAST) with four retrievers, five generators, and nine parameter configurations on two benchmarks (RepoEval and CrossCodeEval), totaling 864 experimental settings. Our results reveal that chunking strategy has a statistically significant effect on RAG-based code completion. Contrary to intuition, chunking based on functions underperforms all other strategies by 3.57--5.64 percentage points on RepoEval (Cliff's delta = -1.0), while the remaining chunking strategies perform comparably. Our further analysis demonstrates that this observation holds across all retriever--generator combinations. We also find that cross-file context length is the dominant parameter: doubling from 2,048 to 8,192 tokens yields up to 4.2 percentage points of improvement, whereas chunk size has a weaker, non-monotonic effect. On the cost--quality Pareto front, Sliding Window and cAST dominate both benchmarks; Function chunking is never Pareto-optimal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a controlled empirical study isolating the effect of chunking on RAG-based code completion. It crosses four chunking strategies (Function, Declaration, Sliding Window, cAST) with four retrievers, five generators, and nine parameter settings on RepoEval and CrossCodeEval for 864 total configurations. Results show chunking strategy has a statistically significant effect; function chunking underperforms the others by 3.57-5.64 percentage points on RepoEval (Cliff's delta = -1.0) and is never Pareto-optimal, while Sliding Window and cAST dominate the cost-quality front. Cross-file context length is the dominant parameter (up to 4.2 pp gain from 2048 to 8192 tokens), with chunk size having weaker non-monotonic effects. The performance gaps hold across all retriever-generator pairs.
Significance. If the results hold, this work provides actionable empirical guidance for a common but under-justified design choice in AI-assisted code completion. The scale (864 settings), use of statistical significance testing, effect sizes, and explicit checks for interactions across retriever-generator pairs are methodological strengths that support the reliability of the central claim. The finding that function chunking is suboptimal challenges practitioner intuition and highlights context length as more important than chunk size, offering clear recommendations for improving RAG pipelines in software engineering tools.
minor comments (2)
- The claim that results hold across all retriever-generator combinations is central but would be strengthened by a summary table or figure explicitly showing per-pair performance deltas rather than relying solely on aggregate statistics.
- The nine parameter configurations are referenced but not enumerated in the provided abstract or summary; a concise table listing the exact values (e.g., specific chunk sizes and context lengths) would improve reproducibility and clarity.
Simulated Author's Rebuttal
We thank the referee for their positive and detailed summary of our controlled empirical study on chunking strategies for RAG-based code completion. We appreciate the recognition of the study's scale (864 configurations), statistical rigor, effect-size reporting, and the practical implications for software engineering tools. The recommendation for minor revision is noted. No specific major comments were raised, so we have no points requiring rebuttal or clarification at this time. We will incorporate any additional minor suggestions from the editor during the revision process.
Circularity Check
No significant circularity: pure empirical comparison
full rationale
The paper is a controlled empirical study that crosses four chunking strategies with multiple retrievers, generators, and parameter settings across two benchmarks (864 total configurations). All reported effects, including the underperformance of function chunking (3.57--5.64 pp, Cliff's delta = -1.0) and Pareto dominance of other strategies, are measured directly via execution on held-out benchmarks rather than derived from equations, fitted parameters, or self-referential predictions. No load-bearing derivations, self-citations for uniqueness theorems, or ansatzes appear in the claims; statistical significance and interaction testing are performed on the experimental data itself. The central result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RepoEval and CrossCodeEval are representative of real-world code completion scenarios.
Reference graph
Works this paper leans on
-
[1]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
-
[2]
Wei Cheng, Yuhan Wu, and Wei Hu. 2024. Dataflow-Guided Retrieval Augmen- tation for Repository-Level Code Completion. doi:10.48550/arXiv.2405.19782 arXiv:2405.19782 [cs]
-
[3]
Yangruibo Ding, Zijian Wang, Wasi Uddin Ahmad, Hantian Ding, Ming Tan, Nihal Jain, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, and Bing Xiang. 2023. CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion. doi:10.48550/arXiv.2310.11248 arXiv:2310.11248 [cs]
-
[4]
Timur Galimzyanov, Olga Kolomyttseva, and Egor Bogomolov. 2025. Practi- cal Code RAG at Scale: Task-Aware Retrieval Design Choices under Compute Budgets. doi:10.48550/arXiv.2510.20609 arXiv:2510.20609 [cs]
-
[5]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guant- ing Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang
-
[6]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence. doi:10.48550/arXiv.2401.14196 arXiv:2401.14196 [cs]
work page internal anchor Pith review doi:10.48550/arxiv.2401.14196
-
[7]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. 2024. Qwen2.5-Coder Technical Report. doi:10.48550/arXiv.2409...
work page internal anchor Pith review doi:10.48550/arxiv.2409.12186 2024
-
[8]
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2020. CodeSearchNet Challenge: Evaluating the State of Semantic Code Search. doi:10.48550/arXiv.1909.09436 arXiv:1909.09436 [cs]
work page internal anchor Pith review doi:10.48550/arxiv.1909.09436 2020
-
[9]
Tianyue Jiang, Yanli Wang, Yanlin Wang, Daya Guo, Ensheng Shi, Yuchi Ma, Jiachi Chen, and Zibin Zheng. 2026. AlignCoder: Aligning Retrieval with Target Intent for Repository-Level Code Completion. doi:10.48550/arXiv.2601.19697 arXiv:2601.19697 [cs]
-
[10]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. doi:10.48550/arXiv.2309.06180 arXiv:2309.06180 [cs]
work page internal anchor Pith review doi:10.48550/arxiv.2309.06180 2023
-
[11]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. [n. d.]. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. ([n. d.])
-
[12]
Xiangyang Li, Kuicai Dong, Yi Quan Lee, Wei Xia, Hao Zhang, Xinyi Dai, Yasheng Wang, and Ruiming Tang. [n. d.]. COIR: A Comprehensive Benchmark for Code Information Retrieval Models. ([n. d.])
- [13]
-
[14]
Xing Han Lù. 2024. BM25S: Orders of magnitude faster lexical search via eager sparse scoring. doi:10.48550/arXiv.2407.03618 arXiv:2407.03618 [cs]
-
[15]
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. 2023. MTEB: Massive Text Embedding Benchmark. doi:10.48550/arXiv.2210.07316 arXiv:2210.07316 [cs]
-
[16]
Siru Ouyang, Wenhao Yu, Kaixin Ma, Zilin Xiao, Zhihan Zhang, Mengzhao Jia, Jiawei Han, Hongming Zhang, and Dong Yu. 2025. RepoGraph: Enhancing AI Software Engineering with Repository-level Code Graph. doi:10.48550/arXiv. 2410.14684 arXiv:2410.14684 [cs]
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[17]
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundare- san, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. CodeBLEU: a Method for Automatic Evaluation of Code Synthesis. doi:10.48550/arXiv.2009.10297 arXiv:2009.10297 [cs]
work page internal anchor Pith review doi:10.48550/arxiv.2009.10297 2020
-
[18]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Frame- work: BM25 and Beyond.Foundations and Trends®in Information Retrieval3, 4 (2009), 333–389. doi:10.1561/1500000019
-
[19]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. doi:10.48550/arXiv.2401.18059 arXiv:2401.18059 [cs]
-
[20]
ByteDance Seed, Yuyu Zhang, Jing Su, Yifan Sun, Chenguang Xi, Xia Xiao, Shen Zheng, Anxiang Zhang, Kaibo Liu, Daoguang Zan, Tao Sun, Jinhua Zhu, Shulin Xin, Dong Huang, Yetao Bai, Lixin Dong, Chao Li, Jianchong Chen, Hanzhi Zhou, Yifan Huang, Guanghan Ning, Xierui Song, Jiaze Chen, Siyao Liu, Kai Shen, Liang Xiang, and Yonghui Wu. 2025. Seed-Coder: Let th...
- [21]
-
[22]
Maojun Sun, Yue Wu, Yifei Xie, Ruijian Han, Binyan Jiang, Defeng Sun, Yancheng Yuan, and Jian Huang. 2026. DARE: Aligning LLM Agents with the R Statisti- cal Ecosystem via Distribution-Aware Retrieval. doi:10.48550/arXiv.2603.04743 arXiv:2603.04743 [cs]
- [23]
-
[24]
Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, Daniel Cer, Alice Lisak, Min Choi, Lucas Gonzalez, Omar Sanseviero, Glenn Cameron, Ian Ballantyne, Kat Black, Kaifeng Chen, Weiyi Wang, Zhe Li, Gus Martins, Jinhyuk Lee, Mark Sherwood, Juyeong Ji, Renjie Wu, ...
-
[25]
Yanlin Wang, Yanli Wang, Daya Guo, Jiachi Chen, Ruikai Zhang, Yuchi Ma, and Zibin Zheng. 2024. RLCoder: Reinforcement Learning for Repository-Level Code Completion. doi:10.48550/arXiv.2407.19487 arXiv:2407.19487 [cs]
-
[26]
Di Wu, Wasi Uddin Ahmad, Dejiao Zhang, Murali Krishna Ramanathan, and Xiaofei Ma. 2024. Repoformer: Selective Retrieval for Repository-Level Code Completion. doi:10.48550/arXiv.2403.10059 arXiv:2403.10059 [cs]
- [27]
-
[28]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[29]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models. doi:10.48550/arXiv.2506.05176 arXiv:2506.05176 [cs]
work page internal anchor Pith review doi:10.48550/arxiv.2506.05176
-
[30]
Yilin Zhang, Xinran Zhao, Zora Zhiruo Wang, Chenyang Yang, Jiayi Wei, and Tongshuang Wu. 2025. cAST: Enhancing Code Retrieval-Augmented Generation with Structural Chunking via Abstract Syntax Tree. doi:10.48550/arXiv.2506. 15655 arXiv:2506.15655 [cs]. 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.