Recognition: unknown
Lightweight Cross-Spectral Face Recognition via Contrastive Alignment and Distillation
Pith reviewed 2026-05-08 17:00 UTC · model grok-4.3
The pith
Adapting a hybrid CNN-Transformer model creates a lightweight framework for cross-spectral face recognition that trains on small paired datasets while preserving RGB performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
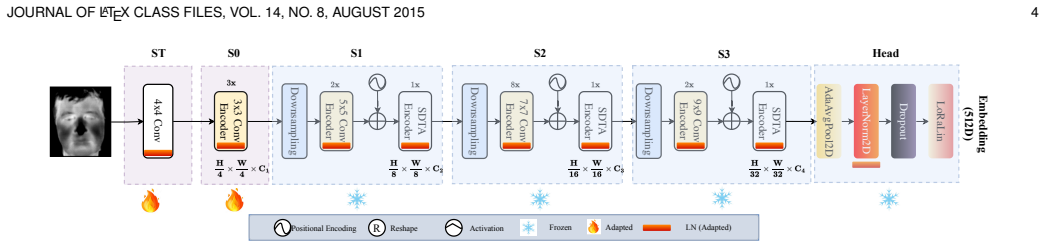
The central claim is that a hybrid CNN-Transformer architecture originally developed for RGB face recognition can be adapted for heterogeneous face recognition through contrastive alignment and distillation, allowing efficient end-to-end training with only a small amount of paired heterogeneous data while still delivering state-of-the-art or competitive results on both HFR benchmarks and standard RGB face recognition tasks at low computational cost.
What carries the argument
Contrastive alignment and distillation applied to an adapted hybrid CNN-Transformer backbone that aligns features across modalities without enlarging the model or requiring large paired datasets.
If this is right
- The same model handles both cross-spectral and ordinary RGB face recognition without needing separate architectures.
- Training remains feasible when only limited paired images exist across sensor types such as NIR-visible or thermal-visible.
- Computational cost stays low enough for deployment on resource-constrained hardware.
- Performance on standard face-recognition benchmarks does not degrade after the adaptation.
Where Pith is reading between the lines
- The small paired-data requirement could simplify adaptation to new sensor pairs in domains beyond faces, such as medical or satellite imagery.
- Keeping the backbone unchanged opens the possibility of swapping in newer lightweight transformers without redesigning the alignment steps.
- Real-time cross-modal verification on mobile devices becomes more practical if the low-compute property holds across additional modalities.
Load-bearing premise
The hybrid CNN-Transformer backbone originally trained on RGB data can be successfully repurposed for cross-modal matching using only small amounts of paired heterogeneous images while retaining its original accuracy on homogeneous tasks.
What would settle it
An ablation test on a thermal-to-visible benchmark where the contrastive alignment and distillation losses are removed and accuracy falls below current competitive HFR methods without any increase in model size.
Figures



read the original abstract
Heterogeneous Face Recognition (HFR) aims at matching face images captured across different sensing modalities, such as thermal-to-visible or near-infrared-to-visible, enhancing the usability of face recognition systems in challenging real-world conditions. Although recent HFR methods have achieved significant improvements in performance, many rely on computationally expensive models, making them impractical for deployment on resource-limited edge devices. In this work, we introduce a lightweight yet effective HFR framework by adapting a hybrid CNN-Transformer model originally developed for RGB homogeneous face recognition. Our approach enables efficient end-to-end training with only a small amount of paired heterogeneous data, while still maintaining strong performance on standard RGB face recognition benchmarks. This makes it suitable for both homogeneous and heterogeneous settings. Comprehensive experiments on several challenging HFR and face recognition benchmarks show that our method achieves state-of-the-art or competitive performance while keeping computational requirements low.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a lightweight framework for heterogeneous face recognition (HFR) by adapting a hybrid CNN-Transformer model pretrained on RGB data. It employs contrastive alignment and distillation to support efficient end-to-end training using only a small amount of paired cross-spectral data, while claiming to retain strong performance on both HFR benchmarks (e.g., NIR-VIS) and homogeneous RGB face recognition tasks with low computational overhead.
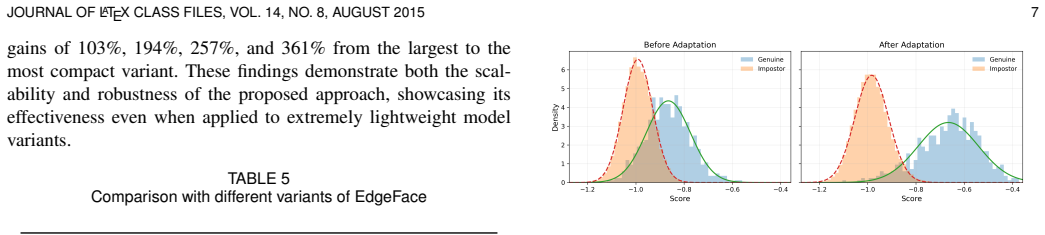
Significance. If the performance claims hold, the work would provide a practical advance for edge-device deployment of cross-modal face recognition by reducing reliance on large paired heterogeneous datasets. The adaptation of an established RGB architecture via alignment and distillation could bridge homogeneous and heterogeneous settings efficiently. However, the significance is limited by insufficient experimental validation of the data-efficiency premise.
major comments (1)
- [Section 4] Section 4 (Experiments): No ablation varies the fraction of paired heterogeneous training data (e.g., 5%, 10%, 20% subsets of CASIA NIR-VIS or similar) while reporting rank-1 accuracy or TAR@FAR curves. This directly undermines the Abstract claim of 'efficient end-to-end training with only a small amount of paired heterogeneous data,' as it is impossible to determine whether the reported SOTA/competitive results require the full paired set or are largely carried by RGB pre-training alone.
minor comments (2)
- [Abstract] Abstract: the assertion of 'comprehensive experiments showing SOTA or competitive results' should be supported by explicit mention of datasets, metrics, and at least one quantitative comparison in the abstract itself.
- [Section 3] The description of the contrastive alignment and distillation losses in Section 3 would be clearer with explicit equations and hyperparameter values rather than high-level prose.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. The major comment regarding experimental validation of data efficiency is well-taken, and we address it point-by-point below with plans for revision.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Experiments): No ablation varies the fraction of paired heterogeneous training data (e.g., 5%, 10%, 20% subsets of CASIA NIR-VIS or similar) while reporting rank-1 accuracy or TAR@FAR curves. This directly undermines the Abstract claim of 'efficient end-to-end training with only a small amount of paired heterogeneous data,' as it is impossible to determine whether the reported SOTA/competitive results require the full paired set or are largely carried by RGB pre-training alone.
Authors: We agree that an explicit ablation on varying fractions of paired heterogeneous data would strengthen the data-efficiency premise highlighted in the abstract. Our design uses contrastive alignment and distillation to transfer knowledge from the RGB-pretrained hybrid CNN-Transformer backbone, enabling effective adaptation with limited paired samples, but the reported results follow standard HFR protocol by using full paired training sets for direct comparability with prior work. To address this, we will add the requested ablation in the revised Section 4, evaluating performance on 5%, 10%, 20%, and 50% random subsets of the paired training data from CASIA NIR-VIS (and similarly for other benchmarks if space permits), reporting rank-1 accuracy and TAR@FAR curves. These new results will isolate the contribution of our alignment and distillation modules beyond RGB pre-training alone. revision: yes
Circularity Check
No circularity detected; derivation relies on independent adaptation of established components
full rationale
The paper adapts a pre-existing hybrid CNN-Transformer architecture (originally for RGB face recognition) via standard contrastive alignment and distillation losses to handle cross-spectral data. No equations, predictions, or first-principles results are shown to reduce by construction to fitted inputs or self-referential definitions. Performance claims rest on experimental benchmarks rather than tautological equivalence, and no load-bearing self-citations or uniqueness theorems imported from the authors' prior work close the derivation loop. The approach is self-contained against external benchmarks and standard ML techniques.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained RGB face recognition models can be effectively adapted to heterogeneous modalities with limited paired data.
Reference graph
Works this paper leans on
-
[1]
Labeled faces in the wild: A survey,
E. Learned-Miller, G. B. Huang, A. RoyChowdhury, H. Li, and G. Hua, “Labeled faces in the wild: A survey,”Advances in face detection and facial image analysis, vol. 1, pp. 189–248, 2016
2016
-
[2]
Illumination invariant face recognition using near-infrared images,
S. Z. Li, R. Chu, S. Liao, and L. Zhang, “Illumination invariant face recognition using near-infrared images,”IEEE Transactions on pattern analysis and machine intelligence, vol. 29, no. 4, pp. 627–639, 2007
2007
-
[3]
A comprehensive evaluation on multi-channel biometric face presentation attack detection,
A. George, D. Geissbuhler, and S. Marcel, “A comprehensive evaluation on multi-channel biometric face presentation attack detection,”arXiv preprint arXiv:2202.10286, 2022
-
[4]
Heterogeneous face recognition using kernel prototype similarities,
B. F. Klare and A. K. Jain, “Heterogeneous face recognition using kernel prototype similarities,”IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 6, pp. 1410–1422, 2012
2012
-
[5]
Wasserstein CNN: Learning invariant features for Nir-Vis face recognition,
R. He, X. Wu, Z. Sun, and T. Tan, “Wasserstein CNN: Learning invariant features for Nir-Vis face recognition,”IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 7, pp. 1761–1773, 2018
2018
-
[6]
Transformers in vision: A survey,
S. Khan, M. Naseer, M. Hayat, S. W. Zamir, F. S. Khan, and M. Shah, “Transformers in vision: A survey,”ACM computing surveys (CSUR), vol. 54, no. 10s, pp. 1–41, 2022
2022
-
[7]
Edgeface: Efficient face recognition model for edge devices,
A. George, C. Ecabert, H. O. Shahreza, K. Kotwal, and S. Marcel, “Edgeface: Efficient face recognition model for edge devices,”IEEE Transactions on Biometrics, Behavior, and Identity Science, vol. 6, no. 2, pp. 158–168, 2024
2024
-
[8]
Heterogeneous face recog- nition from local structures of normalized appearance,
S. Liao, D. Yi, Z. Lei, R. Qin, and S. Z. Li, “Heterogeneous face recog- nition from local structures of normalized appearance,” inInternational Conference on Biometrics. Springer, 2009, pp. 209–218
2009
-
[9]
Matching forensic sketches to mug shot photos,
B. Klare, Z. Li, and A. K. Jain, “Matching forensic sketches to mug shot photos,”IEEE transactions on pattern analysis and machine intelligence, vol. 33, no. 3, pp. 639–646, 2010
2010
-
[10]
Learning invariant deep represen- tation for Nir-Vis face recognition,
R. He, X. Wu, Z. Sun, and T. Tan, “Learning invariant deep represen- tation for Nir-Vis face recognition,” inThirty-First AAAI Conference on Artificial Intelligence, 2017
2017
-
[11]
A novel quaternary pattern of local max- imum quotient for heterogeneous face recognition,
H. Roy and D. Bhattacharjee, “A novel quaternary pattern of local max- imum quotient for heterogeneous face recognition,”Pattern Recognition Letters, vol. 113, pp. 19–28, 2018
2018
-
[12]
Composite components- based face sketch recognition,
D. Liu, J. Li, N. Wang, C. Peng, and X. Gao, “Composite components- based face sketch recognition,”Neurocomputing, vol. 302, pp. 46–54, 2018
2018
-
[13]
Towards robust facial recognition: Gabor filter-based feature extraction for nir-vis heterogeneous face recognition,
J. V . de Andrade, A. Freire, G. C. Pereira, C. Millan-Arias, B. Fernandes, C. Bastos-Filho, J. Tortato, L. Da Rocha, and A. M. Maciel, “Towards robust facial recognition: Gabor filter-based feature extraction for nir-vis heterogeneous face recognition,” inProceedings of the 40th ACM/SI- GAPP Symposium on Applied Computing, 2025, pp. 1275–1281
2025
-
[14]
Face matching between near infrared and visible light images,
D. Yi, R. Liu, R. Chu, Z. Lei, and S. Z. Li, “Face matching between near infrared and visible light images,” inInternational Conference on Biometrics. Springer, 2007, pp. 523–530
2007
-
[15]
Bypassing synthesis: PLS for face recognition with pose, low-resolution and sketch,
A. Sharma and D. W. Jacobs, “Bypassing synthesis: PLS for face recognition with pose, low-resolution and sketch,” inCVPR 2011. IEEE, 2011, pp. 593–600
2011
-
[16]
Coupled spectral regression for matching heteroge- neous faces,
Z. Lei and S. Z. Li, “Coupled spectral regression for matching heteroge- neous faces,” in2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009, pp. 1123–1128
2009
-
[17]
Heterogeneous face recognition using domain specific units,
T. de Freitas Pereira, A. Anjos, and S. Marcel, “Heterogeneous face recognition using domain specific units,”IEEE Transactions on Informa- tion Forensics and Security, vol. 14, no. 7, pp. 1803–1816, 2018
2018
-
[18]
Heterogeneous face recognition using domain invariant units,
A. George and S. Marcel, “Heterogeneous face recognition using domain invariant units,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 4780–4784
2024
-
[19]
Coupled attribute learning for heterogeneous face recognition,
D. Liu, X. Gao, N. Wang, J. Li, and C. Peng, “Coupled attribute learning for heterogeneous face recognition,”IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 11, pp. 4699–4712, 2020
2020
-
[20]
Modality-agnostic augmented multi-collaboration representation for semi-supervised heterogenous face recognition,
D. Liu, W. Yang, C. Peng, N. Wang, R. Hu, and X. Gao, “Modality-agnostic augmented multi-collaboration representation for semi-supervised heterogenous face recognition,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 4647– 4656
2023
-
[21]
From modalities to styles: Rethinking the domain gap in heterogeneous face recognition,
A. George and S. Marcel, “From modalities to styles: Rethinking the domain gap in heterogeneous face recognition,”IEEE Transactions on Biometrics, Behavior, and Identity Science, vol. 6, no. 4, pp. 475–485, 2024
2024
-
[22]
Bridging the Gap: Heterogeneous face recognition with condi- tional adaptive instance modulation,
——, “Bridging the Gap: Heterogeneous face recognition with condi- tional adaptive instance modulation,” in2023 International Joint Confer- ence on Biometrics (IJCB). IEEE, 2023
2023
-
[23]
Modality agnostic heterogeneous face recognition with switch style modulators,
——, “Modality agnostic heterogeneous face recognition with switch style modulators,” in2024 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 2024, pp. 1–10
2024
-
[24]
Face photo-sketch synthesis and recognition,
X. Wang and X. Tang, “Face photo-sketch synthesis and recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 31, no. 11, pp. 1955–1967, 2008
1955
-
[25]
A nonlinear approach for face sketch synthesis and recognition,
Q. Liu, X. Tang, H. Jin, H. Lu, and S. Ma, “A nonlinear approach for face sketch synthesis and recognition,” in2005 IEEE Computer Society conference on computer vision and pattern recognition (CVPR’05), vol. 1. IEEE, 2005, pp. 1005–1010
2005
-
[26]
Unpaired Image- to-Image Translation using Cycle-Consistent Adversarial Networks,
J.-Y . Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired Image- to-Image Translation using Cycle-Consistent Adversarial Networks,” arXiv:1703.10593 [cs], Mar. 2017
-
[27]
Generative adversar- ial network-based synthesis of visible faces from polarimetric thermal faces,
H. Zhang, V . M. Patel, B. S. Riggan, and S. Hu, “Generative adversar- ial network-based synthesis of visible faces from polarimetric thermal faces,” in2017 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 2017, pp. 100–107
2017
-
[28]
DVG-face: Dual variational generation for heterogeneous face recognition,
C. Fu, X. Wu, Y . Hu, H. Huang, and R. He, “DVG-face: Dual variational generation for heterogeneous face recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
2021
-
[29]
Heterogeneous face interpretable disentangled representation for joint face recognition and synthesis,
D. Liu, X. Gao, C. Peng, N. Wang, and J. Li, “Heterogeneous face interpretable disentangled representation for joint face recognition and synthesis,”IEEE transactions on neural networks and learning systems, vol. 33, no. 10, pp. 5611–5625, 2021
2021
-
[30]
Memory-modulated trans- former network for heterogeneous face recognition,
M. Luo, H. Wu, H. Huang, W. He, and R. He, “Memory-modulated trans- former network for heterogeneous face recognition,”IEEE Transactions on Information Forensics and Security, 2022
2022
-
[31]
Prepended domain trans- former: Heterogeneous face recognition without bells and whistles,
A. George, A. Mohammadi, and S. Marcel, “Prepended domain trans- former: Heterogeneous face recognition without bells and whistles,” IEEE Transactions on Information Forensics and Security, 2022
2022
-
[32]
Robust cross-domain pseudo- labeling and contrastive learning for unsupervised domain adaptation nir- vis face recognition,
Y . Yang, W. Hu, H. Lin, and H. Hu, “Robust cross-domain pseudo- labeling and contrastive learning for unsupervised domain adaptation nir- vis face recognition,”IEEE Transactions on Image Processing, vol. 32, pp. 5231–5244, 2023
2023
-
[33]
Pseudo label association and prototype- based invariant learning for semi-supervised nir-vis face recognition,
W. Hu, Y . Yang, and H. Hu, “Pseudo label association and prototype- based invariant learning for semi-supervised nir-vis face recognition,” IEEE Transactions on Image Processing, vol. 33, pp. 1448–1463, 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 11
2024
-
[34]
Unsupervised nir-vis face recognition via homogeneous-to-heterogeneous learning and residual-invariant enhance- ment,
Y . Yang, W. Hu, and H. Hu, “Unsupervised nir-vis face recognition via homogeneous-to-heterogeneous learning and residual-invariant enhance- ment,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 2112–2126, 2023
2023
-
[35]
Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices,
S. Chen, Y . Liu, X. Gao, and Z. Han, “Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices,” inBiometric Recognition: 13th Chinese Conference, CCBR 2018, Urumqi, China, August 11-12, 2018, Proceedings 13. Springer, 2018, pp. 428–438
2018
-
[36]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convo- lutional neural networks for mobile vision applications,”arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review arXiv 2017
-
[37]
Mobilenetv2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4510–4520
2018
-
[38]
Mixfacenets: Extremely efficient face recognition networks,
F. Boutros, N. Damer, M. Fang, F. Kirchbuchner, and A. Kuijper, “Mixfacenets: Extremely efficient face recognition networks,” in2021 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 2021, pp. 1–8
2021
-
[39]
Mixconv: Mixed depthwise convolutional kernels,
M. Tan and Q. V . Le, “Mixconv: Mixed depthwise convolutional kernels,” arXiv preprint arXiv:1907.09595, 2019
-
[40]
Shift: A zero flop, zero parameter alterna- tive to spatial convolutions,
B. Wu, A. Wan, X. Yue, P. Jin, S. Zhao, N. Golmant, A. Gholaminejad, J. Gonzalez, and K. Keutzer, “Shift: A zero flop, zero parameter alterna- tive to spatial convolutions,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 9127–9135
2018
-
[41]
Shufflefacenet: A lightweight face architecture for efficient and highly-accurate face recog- nition,
Y . Martindez-Diaz, L. S. Luevano, H. Mendez-Vazquez, M. Nicolas- Diaz, L. Chang, and M. Gonzalez-Mendoza, “Shufflefacenet: A lightweight face architecture for efficient and highly-accurate face recog- nition,” inProceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019, pp. 0–0
2019
-
[42]
Shufflenet v2: Practical guidelines for efficient cnn architecture design,
N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “Shufflenet v2: Practical guidelines for efficient cnn architecture design,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 116–131
2018
-
[43]
Pocketnet: Extreme lightweight face recognition network using neural architecture search and multistep knowledge distillation,
F. Boutros, P. Siebke, M. Klemt, N. Damer, F. Kirchbuchner, and A. Kuijper, “Pocketnet: Extreme lightweight face recognition network using neural architecture search and multistep knowledge distillation,” IEEE Access, vol. 10, pp. 46 823–46 833, 2022
2022
-
[44]
Learning Face Representation from Scratch
D. Yi, Z. Lei, S. Liao, and S. Z. Li, “Learning face representation from scratch,”arXiv preprint arXiv:1411.7923, 2014
work page Pith review arXiv 2014
-
[45]
Vargfacenet: An efficient variable group convolutional neural network for lightweight face recognition,
M. Yan, M. Zhao, Z. Xu, Q. Zhang, G. Wang, and Z. Su, “Vargfacenet: An efficient variable group convolutional neural network for lightweight face recognition,” inProceedings of the IEEE/CVF International Confer- ence on Computer Vision Workshops, 2019, pp. 0–0
2019
-
[46]
Lightweight face recognition challenge,
J. Deng, J. Guo, D. Zhang, Y . Deng, X. Lu, and S. Shi, “Lightweight face recognition challenge,” inProceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019, pp. 0–0
2019
-
[47]
Knowledge distillation for face recognition using synthetic data with dynamic latent sampling,
H. O. Shahreza, A. George, and S. Marcel, “Knowledge distillation for face recognition using synthetic data with dynamic latent sampling,” IEEE Access, 2024
2024
-
[48]
Digi2real: Bridging the realism gap in synthetic data face recognition via foundation models,
A. George and S. Marcel, “Digi2real: Bridging the realism gap in synthetic data face recognition via foundation models,” inProceedings of the Winter Conference on Applications of Computer Vision, 2025, pp. 1469–1478
2025
-
[49]
Model ru- bik’s cube: Twisting resolution, depth and width for tinynets,
K. Han, Y . Wang, Q. Zhang, W. Zhang, C. Xu, and T. Zhang, “Model ru- bik’s cube: Twisting resolution, depth and width for tinynets,”Advances in Neural Information Processing Systems, vol. 33, pp. 19 353–19 364, 2020
2020
-
[50]
Ghostfacenets: Lightweight face recognition model from cheap opera- tions,
M. Alansari, O. A. Hay, S. Javed, A. Shoufan, Y . Zweiri, and N. Werghi, “Ghostfacenets: Lightweight face recognition model from cheap opera- tions,”IEEE Access, 2023
2023
-
[51]
Edgenext: efficiently amalgamated cnn- transformer architecture for mobile vision applications,
M. Maaz, A. Shaker, H. Cholakkal, S. Khan, S. W. Zamir, R. M. Anwer, and F. Shahbaz Khan, “Edgenext: efficiently amalgamated cnn- transformer architecture for mobile vision applications,” inComputer Vision–ECCV 2022 Workshops: Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part VII. Springer, 2023, pp. 3–20
2022
-
[52]
EFaR 2023: Efficient face recognition competition,
J. N. Kolf, F. Boutros, J. Elliesen, M. Theuerkauf, N. Damer, M. Alansari, O. A. Hay, S. Alansari, S. Javed, N. Werghiet al., “EFaR 2023: Efficient face recognition competition,” in2023 International Joint Conference on Biometrics (IJCB). IEEE, 2023
2023
-
[53]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review arXiv 2016
-
[54]
Image style transfer using convolutional neural networks,
L. A. Gatys, A. S. Ecker, and M. Bethge, “Image style transfer using convolutional neural networks,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2414–2423
2016
-
[55]
Tuning layernorm in attention: Towards efficient multi-modal LLM finetuning,
B. Zhao, H. Tu, C. Wei, J. Mei, and C. Xie, “Tuning layernorm in attention: Towards efficient multi-modal LLM finetuning,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=YR3ETaElNK
2024
-
[56]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[57]
Understanding and im- proving layer normalization,
J. Xu, X. Sun, Z. Zhang, G. Zhao, and J. Lin, “Understanding and im- proving layer normalization,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[58]
Webface260m: A benchmark unveiling the power of million-scale deep face recognition,
Z. Zhu, G. Huang, J. Deng, Y . Ye, J. Huang, X. Chen, J. Zhu, T. Yang, J. Lu, D. Duet al., “Webface260m: A benchmark unveiling the power of million-scale deep face recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10 492–10 502
2021
-
[59]
Bob: a free signal processing and machine learning toolbox for researchers,
A. Anjos, L. E. Shafey, R. Wallace, M. G ¨unther, C. McCool, and S. Marcel, “Bob: a free signal processing and machine learning toolbox for researchers,” in20th ACM Conference on Multimedia Systems (ACMMM), Nara, Japan, Oct. 2012. [Online]. Available: https://publications.idiap.ch/downloads/papers/2012/Anjos Bob ACMMM12.pdf
2012
-
[60]
Continuously reproducing toolchains in pattern recognition and machine learning experiments,
A. Anjos, M. G ¨unther, T. de Freitas Pereira, P. Korshunov, A. Mohammadi, and S. Marcel, “Continuously reproducing toolchains in pattern recognition and machine learning experiments,” in International Conference on Machine Learning (ICML), Aug. 2017. [Online]. Available: http://publications.idiap.ch/downloads/papers/2017/ Anjos ICML2017-2 2017.pdf
2017
-
[61]
A comprehensive database for benchmarking imaging systems,
K. Panetta, Q. Wan, S. Agaian, S. Rajeev, S. Kamath, R. Rajendran, S. P. Rao, A. Kaszowska, H. A. Taylor, A. Samaniet al., “A comprehensive database for benchmarking imaging systems,”IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 3, pp. 509–520, 2018
2018
-
[62]
The high-quality wide multi-channel attack (hq-wmca) database,
Z. Mostaani, A. George, G. Heusch, D. Geissbuhler, and S. Marcel, “The high-quality wide multi-channel attack (hq-wmca) database,”arXiv preprint arXiv:2009.09703, 2020
-
[63]
A polarimetric thermal database for face recognition research,
S. Hu, N. J. Short, B. S. Riggan, C. Gordon, K. P. Gurton, M. Thielke, P. Gurram, and A. L. Chan, “A polarimetric thermal database for face recognition research,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2016, pp. 119–126
2016
-
[64]
SCface–surveillance cameras face database,
M. Grgic, K. Delac, and S. Grgic, “SCface–surveillance cameras face database,”Multimedia tools and applications, vol. 51, no. 3, pp. 863– 879, 2011
2011
-
[65]
Coupled information-theoretic encoding for face photo-sketch recognition,
W. Zhang, X. Wang, and X. Tang, “Coupled information-theoretic encoding for face photo-sketch recognition,” inCVPR 2011. IEEE, 2011, pp. 513–520
2011
-
[66]
The FERET database and evaluation procedure for face-recognition algorithms,
P. J. Phillips, H. Wechsler, J. Huang, and P. J. Rauss, “The FERET database and evaluation procedure for face-recognition algorithms,”Im- age and vision computing, vol. 16, no. 5, pp. 295–306, 1998
1998
-
[67]
Identity-aware CycleGAN for face photo-sketch synthesis and recognition,
Y . Fang, W. Deng, J. Du, and J. Hu, “Identity-aware CycleGAN for face photo-sketch synthesis and recognition,”Pattern Recognition, vol. 102, p. 107249, 2020
2020
-
[68]
The CASIA Nir-Vis 2.0 face database,
S. Li, D. Yi, Z. Lei, and S. Liao, “The CASIA Nir-Vis 2.0 face database,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2013, pp. 348–353
2013
-
[69]
xEdgeFace: Efficient cross-spectral face recognition for edge devices,
A. George and S. Marcel, “xEdgeFace: Efficient cross-spectral face recognition for edge devices,” pp. 1–10, 2025
2025
-
[70]
Labeled faces in the wild: A database forstudying face recognition in unconstrained environments,
G. B. Huang, M. Mattar, T. Berg, and E. Learned-Miller, “Labeled faces in the wild: A database forstudying face recognition in unconstrained environments,” inWorkshop on faces in’Real-Life’Images: detection, alignment, and recognition, 2008
2008
-
[71]
Cross-Age LFW: A Database for Studying Cross-Age Face Recognition in Unconstrained Environments
T. Zheng, W. Deng, and J. Hu, “Cross-age lfw: A database for study- ing cross-age face recognition in unconstrained environments,”arXiv preprint arXiv:1708.08197, 2017
work page Pith review arXiv 2017
-
[72]
Cross-pose lfw: A database for studying cross- pose face recognition in unconstrained environments,
T. Zheng and W. Deng, “Cross-pose lfw: A database for studying cross- pose face recognition in unconstrained environments,”Beijing University of Posts and Telecommunications, Tech. Rep, vol. 5, no. 7, 2018
2018
-
[73]
Frontal to profile face verification in the wild,
S. Sengupta, J.-C. Chen, C. Castillo, V . M. Patel, R. Chellappa, and D. W. Jacobs, “Frontal to profile face verification in the wild,” in2016 IEEE winter conference on applications of computer vision (WACV). IEEE, 2016, pp. 1–9
2016
-
[74]
Agedb: the first manually collected, in-the-wild age database,
S. Moschoglou, A. Papaioannou, C. Sagonas, J. Deng, I. Kotsia, and S. Zafeiriou, “Agedb: the first manually collected, in-the-wild age database,” inproceedings of the IEEE conference on computer vision and pattern recognition workshops, 2017, pp. 51–59
2017
-
[75]
A light CNN for deep face representation with noisy labels,
X. Wu, R. He, Z. Sun, and T. Tan, “A light CNN for deep face representation with noisy labels,”IEEE Transactions on Information Forensics and Security, vol. 13, no. 11, pp. 2884–2896, 2018. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 12
2018
-
[76]
Dual variational generation for low shot heterogeneous face recognition,
C. Fu, X. Wu, Y . Hu, H. Huang, and R. He, “Dual variational generation for low shot heterogeneous face recognition,” inAdvances in Neural Information Processing Systems, 2019
2019
-
[77]
Heterogeneous face recognition using inter-session variability modelling,
T. de Freitas Pereira and S. Marcel, “Heterogeneous face recognition using inter-session variability modelling,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2016, pp. 111–118
2016
-
[78]
Cross-eyed 2017: Cross-spectral iris/periocular recognition com- petition,
A. F. Sequeira, L. Chen, J. Ferryman, P. Wild, F. Alonso-Fernandez, J. Bigun, K. B. Raja, R. Raghavendra, C. Busch, T. de Freitas Pereira et al., “Cross-eyed 2017: Cross-spectral iris/periocular recognition com- petition,” in2017 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 2017, pp. 725–732
2017
-
[79]
The facesketchid system: Matching facial composites to mugshots,
S. J. Klum, H. Han, B. F. Klare, and A. K. Jain, “The facesketchid system: Matching facial composites to mugshots,”IEEE Transactions on Information Forensics and Security, vol. 9, no. 12, pp. 2248–2263, 2014
2014
-
[80]
Seeing the forest from the trees: A holistic approach to near-infrared heterogeneous face recognition,
C. Reale, N. M. Nasrabadi, H. Kwon, and R. Chellappa, “Seeing the forest from the trees: A holistic approach to near-infrared heterogeneous face recognition,” inIEEE Conference on Computer Vision and Pattern Recognition Workshops, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.