Recognition: unknown
MIRAGE: Retrieval and Generation of Multimodal Images and Texts for Medical Education
Pith reviewed 2026-05-08 16:46 UTC · model grok-4.3
The pith
MIRAGE creates a shared latent space to retrieve and generate medical images and texts for education.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
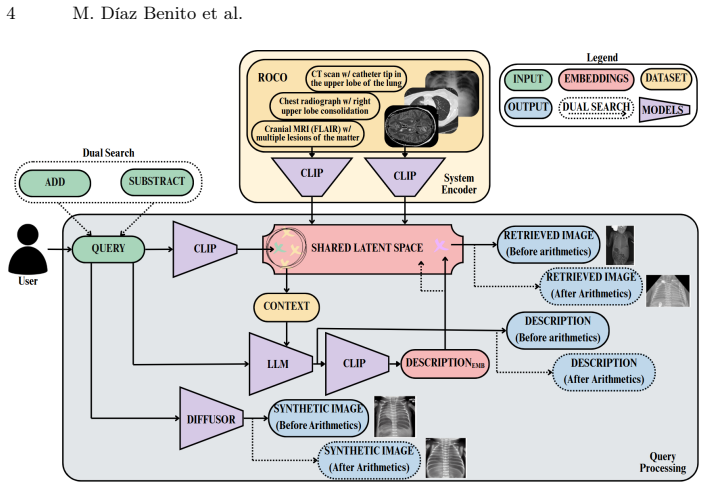
MIRAGE is built on a fine-tuned medical CLIP model (MedICaT-ROCO) trained with the ROCO dataset from PubMed Central. Users can retrieve images, generate new ones with a medical diffusion model called Prompt2MedImage, and obtain enriched text from Dolly-v2-3b. It supports dual search for comparing conditions and relies only on public models for reproducibility.
What carries the argument
The shared latent space from the fine-tuned MedICaT-ROCO model that enables semantically meaningful queries across text and image modalities.
Load-bearing premise
The model outputs are clinically accurate and do not introduce misleading information for learners.
What would settle it
If medical educators find that a significant portion of retrieved or generated images for a standard condition like appendicitis are inaccurate or unhelpful, the system's value would be questioned.
Figures


read the original abstract
Access to diverse, well-annotated medical images with interactive learning tools is fundamental for training practitioners in medicine and related fields to improve their diagnostic skills and understanding of anatomical structures. While medical atlases are valuable, they are often impractical due to their size and lack of interactivity, whereas online image search may provide mislabeled or incomplete material. To address this, we propose MIRAGE, a multimodal medical text and image retrieval and generation system that allows users to find and generate clinically relevant images from trustworthy sources by mapping both text and images to a shared latent space, enabling semantically meaningful queries. The system is based on a fine-tuned medical version of CLIP (MedICaT-ROCO), trained with the ROCO dataset, obtained from PubMed Central. MIRAGE allows users to give prompts to retrieve images, generate synthetic ones through a medical diffusion model (Prompt2MedImage) and receive enriched descriptions from a large language model (Dolly-v2-3b). It also supports a dual search option, enabling the visual comparison of different medical conditions. A key advantage of the system is that it relies entirely on publicly available pretrained models, ensuring reproducibility and accessibility. Our goal is to provide a free, transparent and easy-to-use didactic tool for medical students, especially those without programming skills. The system features an interface that enables interactive and personalized visual learning through medical image retrieval and generation. The system is accessible to medical students worldwide without requiring local computational resources or technical expertise, and is currently deployed on Kaggle: http://www-vpu.eps.uam.es/mirage
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MIRAGE, a multimodal system for medical image and text retrieval and generation aimed at education. It fine-tunes a CLIP variant (MedICaT-ROCO) on the ROCO dataset from PubMed Central to map queries into a shared latent space, employs the Prompt2MedImage diffusion model to synthesize images from text prompts, and uses Dolly-v2-3b to generate enriched descriptions. The system supports single and dual-mode searches for comparing conditions, relies exclusively on public pretrained models, and is deployed on Kaggle for interactive use by students without programming expertise.
Significance. If validated, MIRAGE could meaningfully advance accessible medical education by offering an interactive, reproducible alternative to static atlases and unreliable web searches. The explicit reliance on publicly available models is a clear strength, supporting transparency, reproducibility, and global accessibility without local compute demands. However, the absence of any empirical validation substantially reduces the assessed significance of the contribution as presented.
major comments (3)
- [Abstract] Abstract: The central claim that MIRAGE supplies 'clinically relevant images from trustworthy sources' and 'enriched descriptions' suitable for medical education is unsupported, as no retrieval metrics (e.g., recall@K on held-out ROCO data), generation quality scores (e.g., FID or medical-specific metrics for Prompt2MedImage), or expert clinical ratings are reported anywhere in the manuscript.
- [Methods / System Description] System architecture description: The fine-tuning of MedICaT-ROCO is described at a high level but lacks any details on training procedure, hyperparameters, dataset splits, or quantitative performance, making it impossible to evaluate whether the shared latent space actually produces semantically meaningful and clinically accurate retrievals.
- [Abstract] Abstract and conclusion: The assertion that the system avoids 'mislabeled or incomplete material' from conventional search is not backed by any comparative evaluation or error analysis demonstrating that outputs from the fine-tuned CLIP, diffusion model, or LLM are free of hallucinations or clinically misleading content.
minor comments (2)
- [Abstract] The provided Kaggle deployment URL should be accompanied by a permanent identifier or DOI if possible, and the manuscript should clarify whether the interface code is also released for full reproducibility.
- [Full text] Notation for model names (MedICaT-ROCO, Prompt2MedImage) is introduced without explicit definitions of their training objectives or input/output formats, which would aid readers in understanding the pipeline.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive criticism. The comments correctly identify that the manuscript, as a system description, does not include empirical evaluations to support its claims. We will revise the manuscript accordingly to moderate the language in the abstract and conclusion, expand the methods description, and add a limitations section. Our responses to the major comments are as follows.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that MIRAGE supplies 'clinically relevant images from trustworthy sources' and 'enriched descriptions' suitable for medical education is unsupported, as no retrieval metrics (e.g., recall@K on held-out ROCO data), generation quality scores (e.g., FID or medical-specific metrics for Prompt2MedImage), or expert clinical ratings are reported anywhere in the manuscript.
Authors: We agree with this assessment. The paper presents MIRAGE as an integrated educational tool built on publicly available medical models and datasets, without conducting new quantitative evaluations. In the revised manuscript, we will update the abstract to qualify these claims, for example by stating that the system retrieves images from the ROCO dataset derived from PubMed Central and generates images using a medical diffusion model, while noting that clinical relevance and quality are inherited from the underlying pretrained components. We will also introduce a limitations section discussing the absence of such metrics and the need for future expert validation. revision: yes
-
Referee: [Methods / System Description] System architecture description: The fine-tuning of MedICaT-ROCO is described at a high level but lacks any details on training procedure, hyperparameters, dataset splits, or quantitative performance, making it impossible to evaluate whether the shared latent space actually produces semantically meaningful and clinically accurate retrievals.
Authors: The fine-tuning details were summarized at a high level to maintain focus on the user-facing system and its educational applications. We will revise the Methods section to include more specifics on the training procedure, such as the optimizer, learning rate, number of epochs, batch size, and the train/validation/test splits applied to the ROCO dataset. Regarding quantitative performance, we note that detailed metrics from the fine-tuning were not computed or reported in the original work; we will clarify this and discuss it as a limitation. revision: partial
-
Referee: [Abstract] Abstract and conclusion: The assertion that the system avoids 'mislabeled or incomplete material' from conventional search is not backed by any comparative evaluation or error analysis demonstrating that outputs from the fine-tuned CLIP, diffusion model, or LLM are free of hallucinations or clinically misleading content.
Authors: We acknowledge that no comparative study or error analysis was performed to demonstrate superiority over web searches in terms of accuracy or reduced hallucinations. The design relies on using domain-specific models and a curated dataset from scientific literature to mitigate these issues. In the revision, we will rephrase the abstract and conclusion to present this as an intended benefit of the approach rather than a validated property, and expand the discussion to address potential risks of hallucinations in the generated content from the diffusion model and LLM. revision: yes
- The lack of retrieval metrics, generation quality scores, and expert clinical ratings, since no such evaluations were carried out in this work.
- A direct comparative evaluation or error analysis against conventional search methods.
Circularity Check
No circularity: system description without derivations or self-referential predictions
full rationale
The manuscript describes an applied retrieval-generation pipeline (fine-tuned MedICaT-ROCO CLIP on ROCO, Prompt2MedImage diffusion, Dolly-v2-3b enrichment) built from publicly available pretrained models. No equations, parameter fits, uniqueness theorems, or predictions appear that reduce by construction to the paper's own inputs. All load-bearing components are external and independently trained; the central claims concern system functionality, reproducibility, and accessibility rather than any derived result that is definitionally equivalent to its premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tonsaker, Bartlett, Trpkov: Health information on the Internet: gold mine or mine- field? Can. Fam. Physician60(5), 407–408 (2014).https://www.ncbi.nlm.nih. gov/pmc/articles/PMC4020634/
2014
-
[2]
, Xie X: A survey on evaluation of large language models
Chang et al.: A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol.15(3), 39:1–39:45 (2024).https://doi.org/10.1145/3641289
-
[3]
arXiv preprint arXiv:2409.19492 (2024).https://arxiv
Agarwal et al.: MedHalu: Hallucinations in Responses to Healthcare Queries by Large Language Models. arXiv preprint arXiv:2409.19492 (2024).https://arxiv. org/abs/2409.19492
-
[4]
Krones et al.: Review of multimodal machine learning approaches in healthcare. Inf. Fusion114, 102690 (2025).https://doi.org/10.1016/j.inffus.2024.102690
-
[5]
Wang et al.: MedCLIP: Contrastive Learning from Unpaired Medical Images and Text. In: Proc. EMNLP 2022, pp. 3876–3887. ACL, Abu Dhabi (2022).https: //doi.org/10.18653/v1/2022.emnlp-main.256
-
[6]
Learning Transferable Visual Models From Natural Language Supervision
Radford et al.: Learning Transferable Visual Models From Natural Language Su- pervision. In: Proc. 38th Int. Conf. on Machine Learning (ICML), vol.139, pp. 8748–8763 (2021).https://arxiv.org/abs/2103.00020
work page internal anchor Pith review arXiv 2021
-
[7]
Luo et al.: BioGPT: Generative pre-trained transformer for biomedical text gener- ation and mining. Brief. Bioinform.23(6), bbac409 (2022).https://doi.org/10. 1093/bib/bbac409
2022
-
[8]
Online resource,https://www.databricks.com/blog/2023/04/12/ dolly-first-open-commercially-viable-instruction-tuned-llm, last accessed 2023-06-30
Conover et al.: Free Dolly: Introducing the world’s first truly open instruction- tuned LLM. Online resource,https://www.databricks.com/blog/2023/04/12/ dolly-first-open-commercially-viable-instruction-tuned-llm, last accessed 2023-06-30
2023
-
[9]
Du et al.: A Survey on Composed Image Retrieval. ACM Trans. Multimedia Com- put. Commun. Appl. (2025).https://doi.org/10.1145/3723879
-
[10]
Nan et al.: Revisiting medical image retrieval via knowledge consolidation. Med. Image Anal.102, 103553 (2025).https://doi.org/10.1016/j.media.2025.103553
-
[11]
Yang et al.: Diffusion Models: A Comprehensive Survey of Methods and Applica- tions. ACM Comput. Surv.56(4), 105 (2023).https://doi.org/10.1145/3626235
-
[12]
Kazerouni et al.: Diffusion models in medical imaging: A comprehensive survey. Med. Image Anal.88, 102846 (2023).https://doi.org/10.1016/j.media.2023. 102846
-
[13]
Preiksaitis, Rose: Opportunities, challenges, and future directions of generative artificial intelligence in medical education: scoping review. JMIR Med. Educ.9, e48785 (2023).https://doi.org/10.2196/48785
-
[14]
Boscardin et al.: ChatGPT and generative artificial intelligence for medical educa- tion: potential impact and opportunity. Acad. Med.99(1), 22–27 (2024)
2024
-
[15]
JMIR Med
Eysenbach: The role of ChatGPT, generative language models, and artificial intel- ligence in medical education: a conversation with ChatGPT and a call for papers. JMIR Med. Educ.9(1), e46885 (2023)
2023
-
[16]
Stretton et al.: ChatGPT-based learning: generative artificial intelligence in med- ical education. Med. Sci. Educ.34(1), 215–217 (2024) 10 M. Díaz Benito et al
2024
-
[17]
npj Digit
Rao et al.: Synthetic medical education in dermatology leveraging generative arti- ficial intelligence. npj Digit. Med.8(1), 247 (2025)
2025
-
[18]
Janumpally et al.: Generative artificial intelligence in graduate medical education. Front. Med.11, 1525604 (2025)
2025
-
[19]
In: Intravascular Imaging and Computer Assisted Stenting and Large-Scale Annota- tion of Biomedical Data and Expert Label Synthesis, pp
Pelka et al.: Radiology Objects in COntext (ROCO): A Multimodal Image Dataset. In: Intravascular Imaging and Computer Assisted Stenting and Large-Scale Annota- tion of Biomedical Data and Expert Label Synthesis, pp. 180–189. Springer, Cham (2018)
2018
-
[20]
Lahitani et al.: Cosine similarity to determine similarity measure: Study case in online essay assessment. In: Proc. 2016 4th Int. Conf. on Cyber and IT Service Management (CITSM), pp. 1–6. IEEE (2016).https://doi.org/10.1109/CITSM. 2016.7577578
-
[21]
MedEdPublish10(18) (2021).https://doi.org/10
Challa et al.: Modern techniques of teaching and learning in medical education: a descriptive literature review. MedEdPublish10(18) (2021).https://doi.org/10. 15694/mep.2021.000018.1
-
[22]
Patterns (N.Y.)5(11), 101093 (2024).https://doi.org/10.1016/j.patter.2024.101093
de Weerd et al.: Latent space arithmetic on data embeddings from healthy multi- tissue human RNA-seq decodes disease modules. Patterns (N.Y.)5(11), 101093 (2024).https://doi.org/10.1016/j.patter.2024.101093
-
[23]
arXiv preprint arXiv:2504.18819 (2025).https://arxiv.org/abs/2504.18819
Wasswa, Nanyonga, Lynar: Preserving seasonal and trend information: A varia- tional autoencoder-latent space arithmetic based approach for non-stationary learn- ing. arXiv preprint arXiv:2504.18819 (2025).https://arxiv.org/abs/2504.18819
-
[24]
Abdullakutty et al.: Transforming Tabular Data for Multi-Modality: Enhancing BreastCancerMetastasisPredictionThroughDataConversion.In:Proc.2024IEEE Int. Conf. on Image Processing Challenges and Workshops (ICIPCW), pp. 4149– 4155 (2024).https://doi.org/10.1109/ICIPCW64161.2024.10769174
-
[25]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiyetal.:AnImageisWorth16×16Words:TransformersforImageRecog- nition at Scale. arXiv preprint arXiv:2010.11929 (2020). Presented at ICLR 2021. https://arxiv.org/abs/2010.11929
work page internal anchor Pith review arXiv 2010
-
[26]
Moradimokhles et al.: Study of Deep Learning in Medical Education: Opportuni- ties, Achievements and Future Challenges. J. Adv. Med. Educ. Prof.12(3), 148–162 (2024).https://doi.org/10.30476/JAMP.2024.99740.1853
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.