Recognition: unknown
Hearing the Ocean: Bio-inspired Gammatone-CNN framework for Robust Underwater Acoustic Target Classification
Pith reviewed 2026-05-08 16:35 UTC · model grok-4.3
The pith
A Gammatone filter bank paired with a custom CNN classifies underwater acoustic targets at 98.41% accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The framework uses a Gammatone filter bank distributed according to the Equivalent Rectangular Bandwidth scale to emulate the cochlea's frequency selectivity, generating cochleagram features that preserve low-frequency tonals from engine noise while suppressing ambient interference; these are fed into a convolutional neural network with large receptive fields to integrate spectral-temporal patterns, yielding 98.41% classification accuracy on the VTUAD dataset along with 0.77 ms inference latency.
What carries the argument
Gammatone filter bank on the ERB scale that produces cochleagram inputs for the CNN.
If this is right
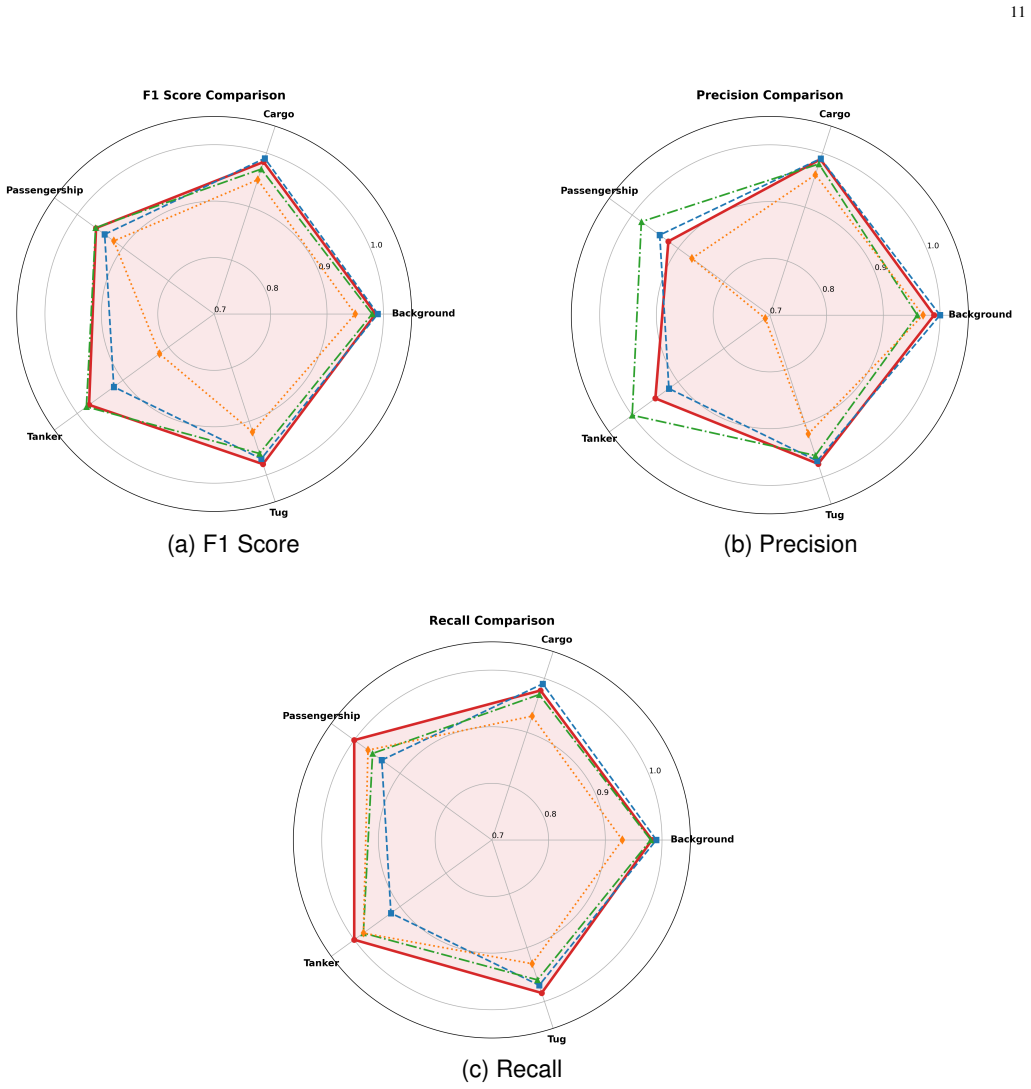
- Outperforms Continuous Wavelet Transform baseline by 3.5 percentage points.
- Outperforms Mel Frequency Cepstral Coefficients by 7.7 percentage points.
- Achieves a Cohen's Kappa score of 0.971.
- Runs with 0.77 ms inference latency suitable for low-power hardware.
Where Pith is reading between the lines
- If the bio-inspired filters generalize across ocean environments, similar approaches could enhance other marine acoustic monitoring systems.
- The lightweight design may allow integration into autonomous underwater vehicles for on-board target detection.
- Extensions to multi-class problems or varying depths could test the robustness of the ERB-scale filtering.
Load-bearing premise
The performance improvements result specifically from the Gammatone-CNN combination rather than dataset-specific optimizations or particular noise characteristics in the VTUAD data.
What would settle it
Evaluating the model on an independent underwater acoustic dataset with different vessel signatures and noise levels to check if the accuracy remains above 90%.
Figures




read the original abstract
This study presents a bio inspired signal processing framework for robust Underwater Acoustic Target Recognition (UATR). The latest state of the art methods often fail to resolve dense low frequency harmonic structures in vessel propulsion signals under high noise conditions, which is addressed by the proposed framework using a biologically inspired Gammatone filter bank that emulates the cochlea nonlinear frequency selectivity. By distributing filters according to the Equivalent Rectangular Bandwidth (ERB) scale, the framework achieves a high fidelity representation of engine radiated tonals while effectively suppressing isotropic ambient interference. The resulting Cochleagram features are processed by a lightweight, custom designed Convolutional Neural Network (CNN) that leverages large receptive fields to integrate spectral-temporal continuities. Experimental results on the VTUAD dataset demonstrate a state of the art classification accuracy of 98.41%, outperforming Continuous Wavelet Transform and Mel Frequency Cepstral Coefficients baselines by 3.5% and 7.7% respectively. Furthermore, the framework achieves an inference latency of only 0.77 ms and a 0.971 Cohen Kappa score, validating its efficacy for real time deployment on autonomous, low-power sonar hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a bio-inspired Gammatone-CNN framework for underwater acoustic target recognition (UATR). It replaces conventional time-frequency representations with a Gammatone filter bank whose center frequencies are spaced according to the Equivalent Rectangular Bandwidth (ERB) scale, producing cochleagram features that preserve low-frequency harmonic structure in vessel propulsion signals while attenuating isotropic noise. These features are classified by a lightweight CNN that employs large receptive fields to integrate spectral-temporal continuity. On the VTUAD dataset the method is reported to reach 98.41 % accuracy, 0.971 Cohen’s kappa, and 0.77 ms inference latency, outperforming Continuous Wavelet Transform and Mel-Frequency Cepstral Coefficient baselines by 3.5 % and 7.7 %, respectively.
Significance. If the performance numbers are shown to arise from the ERB-scaled Gammatone front-end and large-receptive-field CNN rather than dataset-specific tuning, the work would provide a concrete, low-latency alternative for real-time sonar classification on resource-constrained platforms. The explicit linkage to cochlear frequency selectivity supplies a principled motivation that is currently missing from many empirical UATR pipelines.
major comments (3)
- [Abstract / Experimental Results] Abstract and Experimental Results section: the central claim of 98.41 % accuracy and 3.5–7.7 % margins over CWT/MFCC is presented without any description of the train-test split, number of independent runs, stratification, or statistical significance testing. These omissions make it impossible to determine whether the reported figures are reproducible or inflated by an unrepresentative partition of VTUAD.
- [Methodology / Experimental Results] Methodology and Experimental Results: the manuscript gives no indication that the number of Gammatone filters, ERB spacing, CNN depth/width, or training schedule were held fixed across all compared methods. Without an ablation on filter-bank size or a statement that baselines received equivalent hyper-parameter search effort, the performance deltas cannot be attributed to the bio-inspired design rather than per-method tuning.
- [Evaluation] Evaluation: no secondary dataset, cross-noise-condition test, or out-of-distribution evaluation is described. The claim of “robustness … under high noise conditions” therefore rests solely on a single held-out split of VTUAD whose noise statistics are not characterized.
minor comments (2)
- [Abstract] The abstract uses the unhyphenated form “bio inspired”; standard usage in the signal-processing literature is “bio-inspired.”
- [Introduction / Methods] The term “Cochleagram” is introduced without a brief definition or citation to the original auditory-filter literature; a one-sentence clarification would aid readers unfamiliar with the representation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of experimental rigor and reproducibility. We have carefully considered each point and outline below how we will strengthen the manuscript. Our responses focus on clarifying existing procedures and adding missing details or analyses where feasible.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results section: the central claim of 98.41 % accuracy and 3.5–7.7 % margins over CWT/MFCC is presented without any description of the train-test split, number of independent runs, stratification, or statistical significance testing. These omissions make it impossible to determine whether the reported figures are reproducible or inflated by an unrepresentative partition of VTUAD.
Authors: We agree that these experimental details are necessary for reproducibility. The VTUAD dataset was partitioned using a stratified 70/30 train-test split that preserved the distribution of vessel classes. All reported metrics are means computed over five independent training runs that differed only in random seed for weight initialization and data shuffling; standard deviations and 95% confidence intervals were also calculated. Performance differences were assessed for statistical significance with paired t-tests (p < 0.05). We will insert a dedicated paragraph in the Experimental Results section describing the split, run count, and significance tests, and we will revise the abstract to reference the multi-run averaging. revision: yes
-
Referee: [Methodology / Experimental Results] Methodology and Experimental Results: the manuscript gives no indication that the number of Gammatone filters, ERB spacing, CNN depth/width, or training schedule were held fixed across all compared methods. Without an ablation on filter-bank size or a statement that baselines received equivalent hyper-parameter search effort, the performance deltas cannot be attributed to the bio-inspired design rather than per-method tuning.
Authors: The Gammatone filter-bank size (64 filters) and ERB spacing were fixed according to the cochlear model and were not re-tuned for each baseline; the identical CNN architecture, depth, width, and training schedule (Adam optimizer, fixed learning rate, early stopping) were applied to all front-end representations to enable direct comparison. Nevertheless, we acknowledge that an explicit statement of this protocol and an ablation on filter-bank size would make the attribution clearer. In the revision we will add both a clarifying sentence in the Methodology section and a new ablation table showing accuracy as a function of the number of Gammatone filters. revision: partial
-
Referee: [Evaluation] Evaluation: no secondary dataset, cross-noise-condition test, or out-of-distribution evaluation is described. The claim of “robustness … under high noise conditions” therefore rests solely on a single held-out split of VTUAD whose noise statistics are not characterized.
Authors: We accept that additional validation beyond the single VTUAD split would reinforce the robustness claim. The VTUAD recordings already encompass a range of ambient noise levels (as characterized in the dataset reference), and the ERB-scaled Gammatone front-end is specifically motivated by its ability to suppress isotropic noise while preserving low-frequency harmonics. To provide direct evidence, we will augment the Evaluation section with a controlled noise-injection study: additive white Gaussian noise at SNRs from 0 dB to 20 dB will be applied to the test set, and classification accuracy will be reported as a function of SNR. While a completely independent secondary dataset is not evaluated in the current work, we will explicitly note this as a limitation and outline plans for cross-dataset testing in future extensions. revision: partial
Circularity Check
No circularity: empirical accuracies are independent of any internal derivation chain.
full rationale
The paper's central claims consist of measured classification accuracy (98.41%) and latency on the VTUAD dataset, obtained by training and evaluating a Gammatone-filterbank + CNN pipeline. These quantities are produced by standard supervised learning on held-out splits and are not derived from any equation whose right-hand side is defined in terms of the left-hand side. No self-citation is invoked to justify uniqueness or to close a loop; the ERB scaling and CNN architecture are presented as design choices whose merit is assessed externally by cross-method comparison. Because the reported numbers are falsifiable experimental outcomes rather than algebraic identities or fitted parameters renamed as predictions, the derivation chain contains no circular reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- Gammatone filter count and ERB spacing
- CNN receptive-field sizes and layer depths
axioms (1)
- domain assumption Gammatone filters on ERB scale yield higher-fidelity representations of engine tonals than CWT or MFCC under isotropic noise
Reference graph
Works this paper leans on
-
[1]
Anthropogenic and natural sources of ambient noise in the ocean,
J. Hildebrand, “Anthropogenic and natural sources of ambient noise in the ocean,”Marine Ecology Progress Series, vol. 395, pp. 5–20, Dec. 2009, doi: 10.3354/meps08353
-
[2]
R. J. Urick,Principles of Underwater Sound. New York, NY , USA: McGraw-Hill, 1983. 15
1983
-
[3]
The soundscape of the Anthropocene ocean,
C. M. Duarteet al., “The soundscape of the Anthropocene ocean,”Science, vol. 371, no. 6529, p. eaba4658, Feb. 2021, doi: 10.1126/science.aba4658
-
[4]
F. B. Jensen, W. A. Kuperman, M. B. Porter, and H. Schmidt,Computational Ocean Acoustics. New York, NY , USA: Springer, 2000, doi: 10.1063/1.2808704
-
[5]
Performance evaluation of a gammatone filterbank for the embedded system,
Y . Jiang, Y . Zu, X. Chen, and H. Zhou, “Performance evaluation of a gammatone filterbank for the embedded system,”Applied Mechanics and Materials, vols. 336–338, pp. 1459–1462, 2013, doi: 10.4028/www.scientific.net/AMM.336-338.1459
work page doi:10.4028/www.scientific.net/amm.336-338.1459 2013
-
[6]
Vessel type classification utilizing underwater acoustic data and deep learning,
S. S. Nathala, R. R. Yakkati, A. Dayal, M. S. Manikandan, J. Zhou, and L. R. Cenkeramaddi, “Vessel type classification utilizing underwater acoustic data and deep learning,” inProc. IEEE 19th Conf. Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 2024, pp. 1–6, doi: 10.1109/ICIEA61579.2024.10665252
-
[7]
L. C. F. Domingos, P. E. Santos, P. S. M. Skelton, R. S. A. Brinkworth, and K. Sammut, “An investigation of preprocessing filters and deep learning methods for vessel type classification with underwater acoustic data,”IEEE Access, vol. 10, pp. 117582–117596, 2022, doi: 10.1109/ACCESS.2022.3220265
-
[8]
Acoustic classification of maritime vessels using learnable filterbanks,
J. Elsborg, T. Vegge, and A. Bhowmik, “Acoustic classification of maritime vessels using learnable filterbanks,”arXiv preprint arXiv:2505.23964, 2025. [Online]. Available: https://arxiv.org/abs/2505.23964
-
[9]
Underwater acoustic target recognition based on attention residual network,
J. Li, B. Wang, X. Cui, S. Li, and J. Liu, “Underwater acoustic target recognition based on attention residual network,”Entropy, vol. 24, no. 11, Art. no. 1657, 2022, doi: 10.3390/e24111657
-
[10]
L. Zhang, D. Wu, X. Han, and Z. Zhu, “Feature extraction of underwater target signal using mel frequency cepstrum coefficients based on acoustic vector sensor,”Journal of Sensors, vol. 2016, pp. 1–11, 2016, doi: 10.1155/2016/7864213
-
[11]
Enhancing underwater acoustic signal classification with CAM++ and change point features,
Y . Li, Q. Xiao, K. Hu, Y . Fang, and J. Duan, “Enhancing underwater acoustic signal classification with CAM++ and change point features,” inProc. IEEE 13th Data Driven Control and Learning Systems Conf. (DDCLS), May 2024, pp. 2253–2258, doi: 10.1109/DDCLS61622.2024.10606598
-
[12]
Comparative evaluation of various MFCC implementations on the speaker verification task,
T. D. Ganchev, N. Fakotakis, and G. K. Kokkinakis, “Comparative evaluation of various MFCC implementations on the speaker verification task,” inProc. Int. Conf. Speech and Computer (SPECOM), 2007
2007
-
[13]
Mallat,A Wavelet Tour of Signal Processing: The Sparse Way, 3rd ed
S. Mallat,A Wavelet Tour of Signal Processing: The Sparse Way, 3rd ed. Amsterdam, The Netherlands: Elsevier/Academic Press, 2009, doi: 10.1016/B978-0-12-374370-1.X0001-8
-
[14]
R. D. Patterson, M. H. Allerhand, and C. Gigu `ere, “Time-domain modeling of peripheral auditory processing: A modular architecture and a software platform,”J. Acoust. Soc. Am., vol. 98, no. 4, pp. 1890–1904, Oct. 1995, doi: 10.1121/1.414456
-
[15]
Frequency analysis and synthesis using a gammatone filterbank,
V . Hohmann, “Frequency analysis and synthesis using a gammatone filterbank,”Acta Acustica united with Acustica, vol. 88, pp. 433–442, 2002
2002
-
[16]
Derivation of auditory filter shapes from notched-noise data,
B. R. Glasberg and B. C. J. Moore, “Derivation of auditory filter shapes from notched-noise data,”Hearing Research, vol. 47, no. 1–2, pp. 103–138, Aug. 1990, doi: 10.1016/0378-5955(90)90170-T
-
[17]
VTUAD: Vessel type underwater acoustic data,
L. Domingos, P. Skelton, and P. Santos, “VTUAD: Vessel type underwater acoustic data,”IEEE Dataport, Sep. 8, 2022, doi: 10.21227/msg0-ag12
-
[18]
A review of underwater target recognition based on deep learning,
Y . Chen, H. Niu, H. Chen, and X. Liu, “A review of underwater target recognition based on deep learning,”J. Phys.: Conf. Ser., vol. 1881, Art. no. 042031, 2021, doi: 10.1088/1742-6596/1881/4/042031
-
[19]
R. F. Lyon,Human and Machine Hearing: Extracting Meaning from Sound. Cambridge, U.K.: Cambridge Univ. Press, 2017, doi: 10.1017/9781139051699
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.