Recognition: unknown
Communication Offloading on SmartNIC DPUs: A Quantitative Approach
Pith reviewed 2026-05-08 17:20 UTC · model grok-4.3
The pith
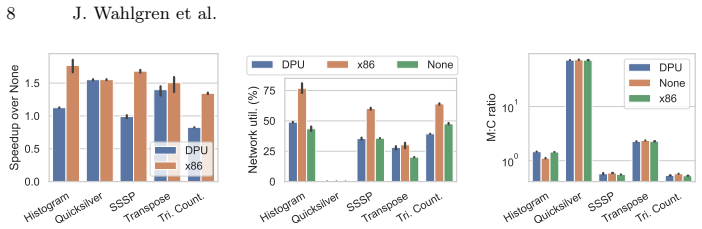
Offloading communication tasks to SmartNIC DPUs speeds up host-dominated workloads by up to 1.55x when the memory-to-communication ratio is high.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The memory-to-communication ratio reliably indicates when the Buddy offloading engine, running on a SmartNIC DPU such as the Nvidia BlueField-3, will deliver net speedup by decoupling message routing from the application process. In host-dominated workloads the speedup reaches 1.55x; across the tested set the absence of Direct Cache Access support on the DPU produces a 625x rise in DRAM traffic, demonstrating both the practical value of the offload strategy and the hardware feature required for its full effectiveness.
What carries the argument
The Buddy engine, which decouples the fire-and-forget message-routing service from the main application thread and executes it on either a DPU or a generic x86 core.
If this is right
- Workloads whose memory operations greatly exceed communication volume obtain measurable CPU relief by moving routing to the DPU.
- The memory-to-communication ratio supplies a lightweight decision metric for choosing when to activate offload.
- SmartNIC designs that add Direct Cache Access support would eliminate the large DRAM-traffic penalty observed here.
- Buddy's portable implementation allows the same offload logic to run on spare host cores when a DPU is unavailable.
- Asynchronous fire-and-forget communication models become more attractive once the ratio-based predictor is applied.
Where Pith is reading between the lines
- If the ratio predictor proves stable, runtime systems could insert automatic offload decisions without programmer intervention.
- The observed DRAM-traffic explosion suggests that cache-coherence features will become a gating item for wider DPU adoption in memory-intensive codes.
- Repeating the experiments on additional DPUs or on applications drawn from other domains would test whether the ratio rule generalizes beyond the five codes studied.
- The same decoupling approach could be applied to other network services such as collective operations or RDMA request handling.
Load-bearing premise
The memory-to-communication ratio accurately forecasts offloading benefit and the overhead of running Buddy on the DPU stays low enough to produce net gains in real applications.
What would settle it
Measuring the same five applications after offloading communication to the DPU and finding either no speedup in the high-ratio cases or a DRAM-traffic increase far below 625x would falsify the central claims.
Figures





read the original abstract
SmartNIC Data Processing Units (DPUs) offer a promising solution for saving high-end CPU resources by offloading tasks to programmable cores near the network interface. In this work, we explore the feasibility of SmartNIC DPUs in supporting an asynchronous communication model called "fire-and-forget", particularly its core message routing service. We design a communication offloading engine called Buddy that decouples communication tasks from the application process. Buddy runs flexibly on SmartNIC DPUs such as the Nvidia BlueField-3 DPU and generic x86 CPUs. Our evaluation results in five applications identify the memory-to-communication ratio as a key predictor of the offloading performance. Host-dominated workloads, such as Quicksilver and Sparse Matrix Transpose, achieved up to 1.55x speedup with communication offloaded to the DPU. We further identify a 625x increase in DRAM traffic due to the absence of Direct Cache Access support on the DPU, highlighting a critical need in future SmartNIC designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Buddy, a flexible communication offloading engine for SmartNIC DPUs (e.g., Nvidia BlueField-3) that decouples asynchronous 'fire-and-forget' message routing from the host application process. Evaluation across five applications identifies the memory-to-communication ratio as the key predictor of offloading benefit; host-dominated workloads (Quicksilver, Sparse Matrix Transpose) achieve up to 1.55x speedup when offloaded to the DPU, while the absence of Direct Cache Access on the DPU produces a 625x increase in DRAM traffic.
Significance. If the empirical results hold after improved controls, the work supplies concrete, workload-characteristic guidance for deciding when communication offloading to DPUs is profitable and flags a concrete hardware limitation (missing DCA) that future SmartNIC designs must address. The quantitative framing and real-hardware measurements on a production DPU are strengths that could influence both systems software and hardware roadmaps in distributed and high-performance computing.
major comments (2)
- [Evaluation] Evaluation section: the central claim that the memory-to-communication ratio reliably predicts offloading benefit rests on results from only five applications without reported isolation of DPU kernel execution time versus host savings, without a CPU-based offload baseline, and without controls for message-size distribution or cache behavior. Consequently the 1.55x speedup figures for Quicksilver and Sparse Matrix Transpose cannot yet be attributed causally to the ratio rather than to unmeasured confounding factors.
- [Evaluation] Evaluation section: no error bars, standard deviations, or run counts are supplied for any speedup or traffic number (including the 625x DRAM-traffic increase), and baseline details plus exclusion criteria are absent. This directly weakens the soundness of the quantitative claims that the abstract presents as concrete evidence.
minor comments (2)
- [Abstract] Abstract: the phrase 'five applications' should be followed by the explicit list of workloads (Quicksilver, Sparse Matrix Transpose, …) so readers immediately see the sampling scope.
- [Evaluation] The manuscript would benefit from a short table summarizing per-application memory-to-communication ratios together with the observed speedups; this would make the predictive claim visually testable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation. We address each major comment below and indicate the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: Evaluation section: the central claim that the memory-to-communication ratio reliably predicts offloading benefit rests on results from only five applications without reported isolation of DPU kernel execution time versus host savings, without a CPU-based offload baseline, and without controls for message-size distribution or cache behavior. Consequently the 1.55x speedup figures for Quicksilver and Sparse Matrix Transpose cannot yet be attributed causally to the ratio rather than to unmeasured confounding factors.
Authors: We agree that isolating DPU kernel time from host savings and adding a CPU offload baseline would improve causal attribution. Buddy supports execution on both DPU and CPU; we will add a direct CPU baseline comparison in the revision. We will also include per-workload breakdowns of DPU versus host execution time for Quicksilver and Sparse Matrix Transpose. The five applications were chosen to cover a spectrum of memory-to-communication ratios, and we will expand the text to detail how message-size distributions and cache behavior were controlled or measured. We will qualify the predictive claim to note that it is supported by observed trends across the tested workloads rather than proven in isolation. revision: partial
-
Referee: Evaluation section: no error bars, standard deviations, or run counts are supplied for any speedup or traffic number (including the 625x DRAM-traffic increase), and baseline details plus exclusion criteria are absent. This directly weakens the soundness of the quantitative claims that the abstract presents as concrete evidence.
Authors: We acknowledge the omission. All reported speedups and traffic figures are averages over at least five runs per configuration; we will add error bars, standard deviations, and explicit run counts to the revised figures and tables. We will also expand the evaluation section with full baseline hardware/software configurations and any data exclusion criteria to improve reproducibility. revision: yes
Circularity Check
No circularity: results from direct hardware measurements
full rationale
The paper reports an empirical quantitative study of the Buddy offloading engine on real SmartNIC DPUs (Nvidia BlueField-3) and x86 CPUs across five applications. The memory-to-communication ratio is identified post hoc as a predictor solely from observed performance data and speedups (e.g., 1.55x on Quicksilver and Sparse Matrix Transpose) measured on hardware; no equations, fitted parameters, or first-principles derivations are presented that could reduce to inputs by construction. The 625x DRAM traffic observation is likewise a direct hardware measurement. No self-citations, uniqueness theorems, or ansatzes are invoked to justify core claims. The evaluation is self-contained against external benchmarks via real-system testing rather than any closed derivation loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The DPU can execute the Buddy communication engine with low enough overhead to produce net performance gains in host-dominated workloads.
Forward citations
Cited by 1 Pith paper
-
Post-Moore Technologies for Plasma Simulation: A Community Roadmap
No single post-Moore technology replaces current HPC for plasma simulations, but FPGA-class accelerators offer near-term kernel offload, non-von Neumann architectures medium-term operator acceleration, and quantum com...
Reference graph
Works this paper leans on
-
[1]
In: 2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS) (2020)
Alian, M., Yuan, Y., Zhang, J., Wang, R., Jung, M., Kim, N.S.: Data direct I/O characterization for future I/O system exploration. In: 2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS) (2020)
2020
-
[2]
In: International Conference on High Performance Computing (2021)
Bayatpour, M., Sarkauskas, N., Subramoni, H., Maqbool Hashmi, J., Panda, D.K.: BluesMPI: Efficient MPI non-blocking Alltoall offloading designs on modern Blue- Field smart NICs. In: International Conference on High Performance Computing (2021)
2021
-
[3]
In: Proceedings of the 48th International Conference on Parallel Processing (2019)
Brock, B., Buluç, A., Yelick, K.: BCL: A cross-platform distributed data structures library. In: Proceedings of the 48th International Conference on Parallel Processing (2019)
2019
-
[4]
In: 2020 USENIX Annual Technical Conference (USENIX ATC 20) (2020)
Farshin, A., Roozbeh, A., Maguire Jr, G.Q., Kostić, D.: Reexamining direct cache access to optimize I/O intensive applications for multi-hundred-gigabit networks. In: 2020 USENIX Annual Technical Conference (USENIX ATC 20) (2020)
2020
-
[5]
In: Proceedings of the 2006 ACM/IEEE conference on Supercomputing (2006)
Garg, R., Sabharwal, Y.: Software routing and aggregation of messages to optimize the performance of HPCC Randomaccess benchmark. In: Proceedings of the 2006 ACM/IEEE conference on Supercomputing (2006)
2006
-
[6]
In: Proceedings of the 2024 SIGCOMM Workshop on Networks for AI Computing (2024)
Gu, T., Fei, J., Canini, M.: OmNICCL: Zero-cost sparse AllReduce with direct cache access and SmartNICs. In: Proceedings of the 2024 SIGCOMM Workshop on Networks for AI Computing (2024)
2024
-
[7]
In: 2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS) (2022)
Karamati, S., Hughes, C., Hemmert, K.S., Grant, R.E., Schonbein, W.W., Levy, S., Conte, T.M., Young, J., Vuduc, R.W.: “Smarter” NICs for faster molecular dynam- ics: a case study. In: 2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS) (2022)
2022
-
[8]
In: 15th Annual IEEE Symposium on High- Performance Interconnects (HOTI 2007) (2007)
León, E.A., Ferreira, K.B., Maccabe, A.B.: Reducing the impact of the memory wall for I/O using cache injection. In: 15th Annual IEEE Symposium on High- Performance Interconnects (HOTI 2007) (2007)
2007
-
[9]
In: 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS)
Li, Y., Kashyap, A., Chen, W., Guo, Y., Lu, X.: Accelerating lossy and lossless compression on emerging bluefield dpu architectures. In: 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS). pp. 373–385 (2024)
2024
-
[10]
In: 2019 IEEE/ACM 9th Workshop on Irregular Applications: Architectures and Algorithms (IA3) (2019)
Maley, F.M., DeVinney, J.G.: Conveyors for streaming many-to-many communica- tion. In: 2019 IEEE/ACM 9th Workshop on Irregular Applications: Architectures and Algorithms (IA3) (2019)
2019
-
[11]
IEEE Computer Architecture Letters (2025)
Mamandipoor, A., Tran, H.D., Alian, M.: SDT: Cutting datacenter tax through simultaneous data-delivery threads. IEEE Computer Architecture Letters (2025)
2025
-
[12]
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (2023)
Steil, T., Reza, T., Priest, B., Pearce, R.: Embracing irregular parallelism in HPC with YGM. In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (2023)
2023
-
[13]
In: 2023 IEEE International Parallel and Distributed Processing Symposium (IPDPS) (2023)
Suresh, K.K., Michalowicz, B., Ramesh, B., Contini, N., Yao, J., Xu, S., Shafi, A., Subramoni, H., Panda, D.: A novel framework for efficient offloading of commu- nication operations to BlueField SmartNICs. In: 2023 IEEE International Parallel and Distributed Processing Symposium (IPDPS) (2023)
2023
-
[14]
Future Generation Computer Sys- tems (2025)
Tibbetts, N., Ibtisum, S., Puri, S.: A survey on heterogeneous computing using SmartNICs and emerging data processing units. Future Generation Computer Sys- tems (2025)
2025
-
[15]
In: International Conference on High Performance Com- puting (2021) Communication Offloading on SmartNIC DPUs: A Quantitative Approach 15
Tithi, J.J., Petrini, F., Richards, D.F.: Lessons learned from accelerating Quicksil- ver on programmable integrated unified memory architecture (PIUMA) and how that’s different from CPU. In: International Conference on High Performance Com- puting (2021) Communication Offloading on SmartNIC DPUs: A Quantitative Approach 15
2021
-
[16]
In: Proceedings of the In- ternational Conference for High Performance Computing, Networking, Storage and Analysis (2025)
Usman, M., Benito, M., Iserte, S., Peña, A.J.: ODOS-MPI: HPC-friendly Smart- NIC offloading of computation/communication kernels. In: Proceedings of the In- ternational Conference for High Performance Computing, Networking, Storage and Analysis (2025)
2025
-
[17]
In: Proceedings of the SC’23 Workshops of The International Con- ference on High Performance Computing, Network, Storage, and Analysis (2023)
Usman,M.,Iserte,S.,Ferrer,R.,Peña,A.J.:DPUoffloadingprogrammingwiththe OpenMP API. In: Proceedings of the SC’23 Workshops of The International Con- ference on High Performance Computing, Network, Storage, and Analysis (2023)
2023
-
[18]
Proceedings of the ACM on Measurement and Analysis of Computing Systems6(1) (2022)
Wang, M., Xu, M., Wu, J.: Understanding I/O direct cache access performance for end host networking. Proceedings of the ACM on Measurement and Analysis of Computing Systems6(1) (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.