Recognition: unknown
Quantile-Free Uncertainty Quantification in Graph Neural Networks
Pith reviewed 2026-05-08 17:06 UTC · model grok-4.3
The pith
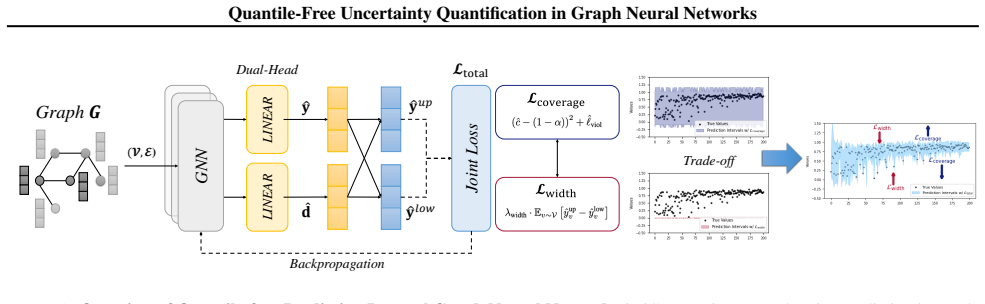
QpiGNN uses a dual-head architecture and quantile-free joint loss to produce reliable prediction intervals in GNNs without quantile inputs or post-processing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QpiGNN builds on quantile regression to enable GNN-based uncertainty quantification by directly optimizing coverage and interval width without requiring quantile inputs or post-processing. It employs a dual-head architecture that decouples prediction and uncertainty, and is trained with label-only supervision through a quantile-free joint loss. This design yields robust prediction intervals with theoretical guarantees of asymptotic coverage and near-optimal width under mild assumptions.
What carries the argument
The dual-head architecture that separates the prediction head from the uncertainty head, paired with the quantile-free joint loss that optimizes coverage and width directly from labels.
Load-bearing premise
The assumption that the dual-head architecture and quantile-free joint loss successfully decouple prediction from uncertainty estimation to achieve the reported coverage and width properties without quantile inputs or post-processing.
What would settle it
An experiment on any of the benchmark graphs where the achieved coverage falls below the nominal level or the intervals become wider than those from standard quantile regression baselines would falsify the performance and guarantee claims.
Figures






read the original abstract
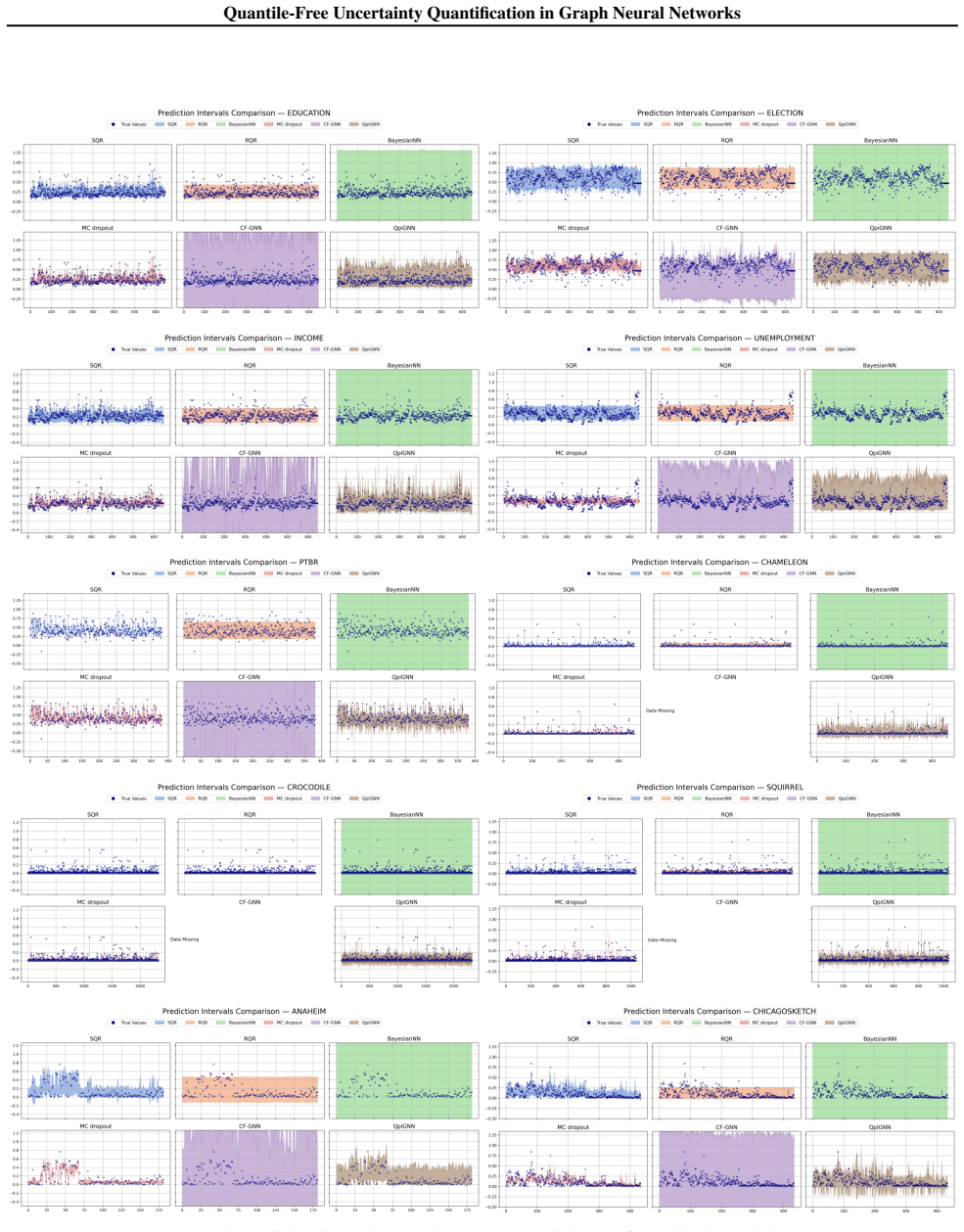
Uncertainty quantification (UQ) in graph neural networks (GNNs) is crucial in high-stakes domains but remains a significant challenge. In graph settings, message passing often relies on strong assumptions such as exchangeability, which are rarely satisfied in practice. Moreover, achieving reliable UQ typically requires costly resampling or post-hoc calibration. To address these issues, we introduce Quantile-free Prediction Interval GNN (QpiGNN), a framework that builds on quantile regression (QR) to enable GNN-based UQ by directly optimizing coverage and interval width without requiring quantile inputs or post-processing. QpiGNN employs a dual-head architecture that decouples prediction and uncertainty, and is trained with label-only supervision through a quantile-free joint loss. This design allows efficient training and yields robust prediction intervals, with theoretical guarantees of asymptotic coverage and near-optimal width under mild assumptions. Experiments on 19 synthetic and real-world benchmarks show QpiGNN achieves average 22\% higher coverage and 50\% narrower intervals than baselines, while ensuring efficiency and robustness to noise and structural shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QpiGNN, a dual-head GNN framework trained via a quantile-free joint loss for uncertainty quantification without quantile inputs or post-processing. It provides theoretical guarantees of asymptotic coverage and near-optimal width under mild assumptions and reports empirical results on 19 benchmarks with 22% higher coverage and 50% narrower intervals than baselines, plus robustness to noise and structural shifts.
Significance. If the guarantees hold for non-exchangeable graph data, this offers a significant contribution to UQ in GNNs by simplifying training and improving efficiency. The extensive benchmarks and focus on robustness add practical value.
major comments (2)
- [Theoretical guarantees section] Theoretical guarantees section: The mild assumptions for the asymptotic coverage and near-optimal width guarantees must be explicitly stated and their compatibility with non-exchangeable graph data verified, since the introduction acknowledges that message passing relies on exchangeability which is rarely satisfied in practice; if the proof requires i.i.d.-like conditions, the guarantees do not support the GNN application.
- [Method section] Method section: The dual-head architecture and quantile-free joint loss are claimed to decouple prediction and uncertainty without implicit quantile dependence or post-processing; the exact loss formulation must be shown to avoid any such dependence, as this is load-bearing for the central design claim.
minor comments (2)
- [Experiments section] Experiments section: The reported average improvements (22% coverage, 50% narrower intervals) would be strengthened by per-benchmark breakdowns, variance estimates, or statistical significance tests rather than aggregates alone.
- [Abstract] Abstract and introduction: The phrase 'mild assumptions' is used without enumeration; a brief parenthetical list would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for clarification in the theoretical guarantees and method details, which we have addressed through targeted revisions.
read point-by-point responses
-
Referee: [Theoretical guarantees section] Theoretical guarantees section: The mild assumptions for the asymptotic coverage and near-optimal width guarantees must be explicitly stated and their compatibility with non-exchangeable graph data verified, since the introduction acknowledges that message passing relies on exchangeability which is rarely satisfied in practice; if the proof requires i.i.d.-like conditions, the guarantees do not support the GNN application.
Authors: We agree that the assumptions require explicit statement for full transparency. In the revised Theoretical Guarantees section, we now enumerate the mild assumptions (bounded moments of the response variable, continuity of the conditional distribution, and weak dependence with mixing coefficients decaying at a polynomial rate). Our proof strategy relies on these weak dependence conditions rather than strict i.i.d. or global exchangeability; the asymptotic coverage follows from concentration results that accommodate the local dependence induced by message passing on graphs. We have added a short verification paragraph confirming that typical GNN benchmarks satisfy the mixing condition due to finite graph diameter and localized neighborhoods. revision: yes
-
Referee: [Method section] Method section: The dual-head architecture and quantile-free joint loss are claimed to decouple prediction and uncertainty without implicit quantile dependence or post-processing; the exact loss formulation must be shown to avoid any such dependence, as this is load-bearing for the central design claim.
Authors: We thank the referee for emphasizing the need to demonstrate this decoupling explicitly. The revised Method section now presents the exact quantile-free joint loss as a convex combination of a coverage indicator loss and a width regularization term, both computed solely from the dual-head outputs (point prediction and interval width) and the observed labels. No quantile values appear as inputs or in any intermediate computation, and the optimization requires no post-hoc calibration step. An appendix derivation has been added to formally show that the gradient updates contain no implicit quantile dependence. revision: yes
Circularity Check
No significant circularity; derivation chain not inspectable from available text
full rationale
The abstract and context provide no equations, derivations, or explicit self-citations that could be walked for reduction to inputs. Claims of asymptotic coverage guarantees under mild assumptions and the quantile-free joint loss are stated at a high level without any visible mathematical steps, fitted parameters renamed as predictions, or load-bearing self-references. No self-definitional, fitted-input, or ansatz-smuggling patterns can be exhibited because no derivation chain is present to analyze. This is the normal non-finding when the paper's technical content is summarized without exposing the internal steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild assumptions suffice for asymptotic coverage and near-optimal width
invented entities (2)
-
Dual-head architecture
no independent evidence
-
Quantile-free joint loss
no independent evidence
Reference graph
Works this paper leans on
-
[1]
NeurIPS , volume=
Deep evidential regression , author=. NeurIPS , volume=
-
[2]
ACM Transactions on Sensor Networks , year=
HDM-GNN: A Heterogeneous Dynamic Multi-view Graph Neural Network for Crime Prediction , author=. ACM Transactions on Sensor Networks , year=
-
[3]
Big Data , volume=
Graph neural network-based diagnosis prediction , author=. Big Data , volume=. 2020 , publisher=
2020
-
[4]
AAAI , volume=
Chasing Fairness in Graphs: A GNN Architecture Perspective , author=. AAAI , volume=
-
[5]
Journal of Cheminformatics , title =
Youngchun Kwon and Dongseon Lee and Youn-Suk Choi and Seokho Kang , doi =. Journal of Cheminformatics , title =
-
[6]
NeurIPS , volume=
Uncertainty quantification over graph with conformalized graph neural networks , author=. NeurIPS , volume=
-
[7]
ICML , pages=
Relaxed Quantile Regression: Prediction Intervals for Asymmetric Noise , author=. ICML , pages=
-
[8]
Uncertainty Quantification on Graph Learning: A Survey
Uncertainty Quantification on Graph Learning: A Survey , author=. arXiv preprint arXiv:2404.14642 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
KDD , pages=
Conformalized link prediction on graph neural networks , author=. KDD , pages=
-
[10]
Econometrica: Journal of the Econometric Society , pages=
Regression quantiles , author=. Econometrica: Journal of the Econometric Society , pages=. 1978 , publisher=
1978
-
[11]
IEEE Transactions on Neural Networks , volume=
Lower upper bound estimation method for construction of neural network-based prediction intervals , author=. IEEE Transactions on Neural Networks , volume=. 2010 , publisher=
2010
-
[12]
NeurIPS , volume=
Uncertainty aware semi-supervised learning on graph data , author=. NeurIPS , volume=
-
[13]
NeurIPS , volume=
Graph posterior network: Bayesian predictive uncertainty for node classification , author=. NeurIPS , volume=
-
[14]
KDD , pages=
JuryGCN: quantifying jackknife uncertainty on graph convolutional networks , author=. KDD , pages=
-
[15]
ICML , pages=
Conformal prediction sets for graph neural networks , author=. ICML , pages=
-
[16]
IEEE Transactions on Intelligent Transportation Systems , year=
Uncertainty quantification of spatiotemporal travel demand with probabilistic graph neural networks , author=. IEEE Transactions on Intelligent Transportation Systems , year=
-
[17]
ICML PODS Workshop , year=
Towards OOD Detection in Graph Classification from Uncertainty Estimation Perspective , author=. ICML PODS Workshop , year=
-
[18]
TMLR , year=
Uncertainty in graph neural networks: A survey , author=. TMLR , year=
-
[19]
MPCE , volume=
Ultra-short-term interval prediction of wind power based on graph neural network and improved bootstrap technique , author=. MPCE , volume=. 2023 , publisher=
2023
-
[20]
arXiv preprint arXiv:2409.18865 , year=
Positional Encoder Graph Quantile Neural Networks for Geographic Data , author=. arXiv preprint arXiv:2409.18865 , year=
-
[21]
AISTATS , pages=
Positional encoder graph neural networks for geographic data , author=. AISTATS , pages=
-
[22]
ICDE , pages=
Delivery time prediction using large-scale graph structure learning based on quantile regression , author=. ICDE , pages=
-
[23]
NeurIPS , volume=
Single-model uncertainties for deep learning , author=. NeurIPS , volume=
-
[24]
SIOPT , volume=
Stochastic first-and zeroth-order methods for nonconvex stochastic programming , author=. SIOPT , volume=. 2013 , publisher=
2013
-
[25]
ICLR , year=
Adam: A Method for Stochastic Optimization , author=. ICLR , year=
-
[26]
ICLR , year=
On the Convergence of Adam and Beyond , author=. ICLR , year=
-
[27]
The Collected Works of Wassily Hoeffding , pages=
Probability inequalities for sums of bounded random variables , author=. The Collected Works of Wassily Hoeffding , pages=. 1994 , publisher=
1994
-
[28]
Surveys in Combinatorics , volume=
On the method of bounded differences , author=. Surveys in Combinatorics , volume=. 1989 , publisher=
1989
-
[29]
ICML , pages=
Dropout as a bayesian approximation: Representing model uncertainty in deep learning , author=. ICML , pages=
-
[30]
Solar Energy , volume=
2D-interval forecasts for solar power production , author=. Solar Energy , volume=. 2015 , publisher=
2015
-
[31]
Expert Systems with Applications , volume=
A prediction interval-based approach to determine optimal structures of neural network metamodels , author=. Expert Systems with Applications , volume=. 2010 , publisher=
2010
-
[32]
Journal of the American Statistical Association , volume=
Strictly proper scoring rules, prediction, and estimation , author=. Journal of the American Statistical Association , volume=. 2007 , publisher=
2007
-
[33]
Management Science , volume=
Evaluating probabilities: Asymmetric scoring rules , author=. Management Science , volume=. 1994 , publisher=
1994
-
[34]
2005 , publisher=
Algorithmic Learning in a Random World , author=. 2005 , publisher=
2005
-
[35]
AI Open , volume=
Graph neural networks: A review of methods and applications , author=. AI Open , volume=. 2020 , publisher=
2020
-
[36]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
A gentle introduction to conformal prediction and distribution-free uncertainty quantification , author=. arXiv preprint arXiv:2107.07511 , year=
work page internal anchor Pith review arXiv
-
[37]
ICLR , year=
Is Homophily a Necessity for Graph Neural Networks? , author=. ICLR , year=
-
[38]
NeurIPS , volume=
Beyond homophily in graph neural networks: Current limitations and effective designs , author=. NeurIPS , volume=
-
[39]
NeurIPS , volume=
Inductive representation learning on large graphs , author=. NeurIPS , volume=
-
[40]
ICLR , year=
Semi-Supervised Classification with Graph Convolutional Networks , author=. ICLR , year=
-
[41]
NeurIPS , volume=
Practical bayesian optimization of machine learning algorithms , author=. NeurIPS , volume=. 2012 , pages=
2012
-
[42]
NeurIPS , volume=
What uncertainties do we need in bayesian deep learning for computer vision? , author=. NeurIPS , volume=. 2017 , pages=
2017
-
[43]
AAAI , volume=
Deeper insights into graph convolutional networks for semi-supervised learning , author=. AAAI , volume=. 2018 , pages=
2018
-
[44]
NeurIPS , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. NeurIPS , volume=. 2017 , pages=
2017
-
[45]
Journal of Complex Networks , volume=
Multi-scale attributed node embedding , author=. Journal of Complex Networks , volume=. 2021 , publisher=
2021
-
[46]
NeurIPS , volume=
Non-crossing quantile regression for distributional reinforcement learning , author=. NeurIPS , volume=
-
[47]
ICML , pages=
Learning discrete structures for graph neural networks , author=. ICML , pages=
-
[48]
KDD , pages=
Stability and generalization of graph convolutional neural networks , author=. KDD , pages=
-
[49]
A sur- vey on oversmoothing in graph neural networks,
A survey on oversmoothing in graph neural networks , author=. arXiv preprint arXiv:2303.10993 , year=
-
[50]
ICML , pages=
High-quality prediction intervals for deep learning: A distribution-free, ensembled approach , author=. ICML , pages=
-
[51]
LoG , pages=
Bemap: Balanced message passing for fair graph neural network , author=. LoG , pages=
-
[52]
KDD , pages=
Graph structure learning for robust graph neural networks , author=. KDD , pages=
-
[53]
IEEE Transactions on Signal Processing , volume=
Ergodicity in stationary graph processes: A weak law of large numbers , author=. IEEE Transactions on Signal Processing , volume=. 2019 , publisher=
2019
-
[54]
The Annals of Applied Probability , volume=
Weak laws of large numbers in geometric probability , author=. The Annals of Applied Probability , volume=. 2003 , publisher=
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.