Recognition: unknown
First server effect on the expected number of games in tennis
Pith reviewed 2026-05-08 16:44 UTC · model grok-4.3
The pith
Knowing who serves first changes the expected number of games in a tennis match by at most one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
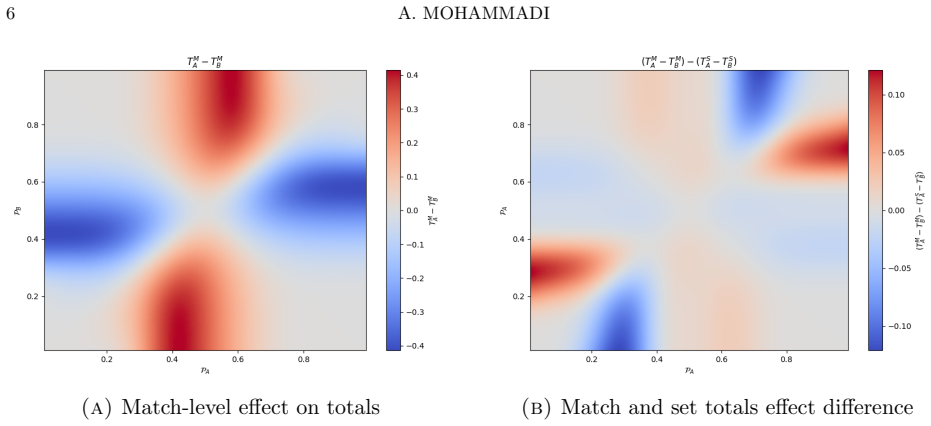
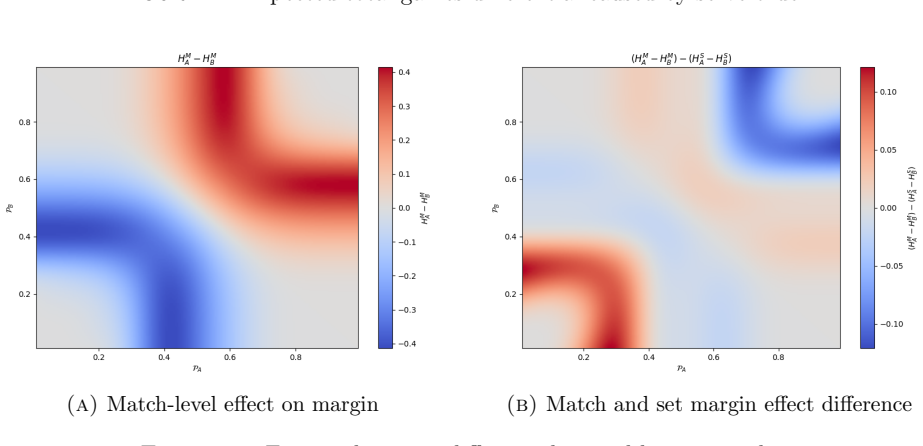
Under the assumption that player A wins points on serve with probability p and player B with probability q, the expected number of games and the expected margin both depend on which player serves first; the dependence is non-negligible only inside certain regions of the (p, q) plane, yet the absolute difference remains at most one game at both the set and match level.
What carries the argument
The difference in conditional expectations for total games, obtained by modeling the set and match as sequences of games whose outcomes depend on the current server and the fixed point-win probabilities.
Load-bearing premise
Each player's probability of winning a point on serve stays constant throughout the match.
What would settle it
A large collection of professional matches in which the estimated serve-win probabilities fall inside the identified non-negligible region and the observed average game count differs by more than one game according to which player served first.
Figures
read the original abstract
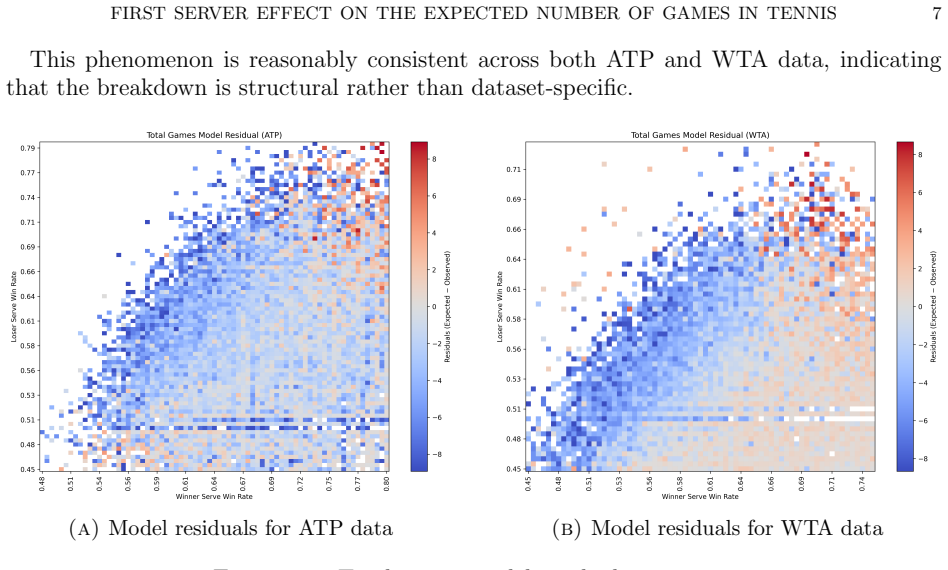
We show that information on the first server influences the expected total number of games and margin in a tennis match under the standard assumption that each player's serve point win probability remains constant, and identify the exact regions, in terms of these probabilities, in which this effect is non-negligible. We confirm numerically that this effect is bounded by at most one game at both the set and match level. We complement the analysis with an empirical comparison on professional match data, illustrating the adequacy of the constant-probability assumption for modelling the total number of games.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives recursive expressions for the expected number of games (and win margin) in a tennis set and best-of-n match under constant point-win probabilities p and q, distinguishing the cases where the first server is known versus unknown. It analytically identifies the regions of the (p,q) unit square in which the first-server information produces a non-negligible difference in these expectations, and numerically verifies that the absolute difference is at most one game at both set and match level. The analysis is complemented by an empirical comparison against professional match data that supports the adequacy of the constant-probability assumption for modeling total games.
Significance. If the numerical bound holds, the work supplies a precise, parameter-region-specific quantification of a previously unexamined modeling choice (first-server information) that affects expected match length by a bounded but non-zero amount. The recursive expectation framework on the finite tennis scoring tree is standard yet cleanly executed here, and the explicit delineation of negligible versus non-negligible regions offers falsifiable guidance for analysts. The empirical check, while secondary, directly addresses the practical relevance of the constant-p,q assumption for the quantity of interest.
major comments (1)
- [§4] §4 (Numerical confirmation of the bound): The central claim that the first-server effect is bounded by at most one game at both set and match level rests entirely on numerical evaluation over a finite grid of (p,q) values. Because the scoring tree admits arbitrarily long deuce/advantage sequences when p or q approaches 0 or 1, and because tie-break and advantage-set rules introduce additional discontinuities, a discrete grid may miss narrow parameter bands in which the difference exceeds 1. An analytical upper bound or a convergence argument with explicit error control on the grid is required to make the headline bound rigorous.
minor comments (2)
- [§§2–3] The recursive definitions for expected games (e.g., the conditioning on the first point or first game) are introduced without a compact notation for the two cases (known vs. unknown first server); a single pair of symbols such as E_A and E_U would improve readability in §§2–3.
- [Figure 2] Figure 2 (or equivalent region plot) lacks an explicit color-bar scale for the magnitude of the difference; readers cannot immediately judge whether the plotted 'non-negligible' regions correspond to differences of 0.1 or 0.9 games.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the positive assessment of the paper's contributions. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: §4 (Numerical confirmation of the bound): The central claim that the first-server effect is bounded by at most one game at both set and match level rests entirely on numerical evaluation over a finite grid of (p,q) values. Because the scoring tree admits arbitrarily long deuce/advantage sequences when p or q approaches 0 or 1, and because tie-break and advantage-set rules introduce additional discontinuities, a discrete grid may miss narrow parameter bands in which the difference exceeds 1. An analytical upper bound or a convergence argument with explicit error control on the grid is required to make the headline bound rigorous.
Authors: We agree that a finite grid, however dense, cannot by itself rigorously exclude exceedances in narrow unsampled regions, particularly near the boundaries where long deuce sequences occur and at the tie-break discontinuities. In the revision we will replace the current numerical confirmation with a two-part argument: (i) results on a grid with spacing 0.001 together with a direct computation of the difference function at all grid points, and (ii) an explicit error-control argument showing that the difference between the two recursive expectations is Lipschitz continuous on each compact sub-rectangle away from the tie-break thresholds, with a computable Lipschitz constant derived from the depth of the recursion. This supplies the required convergence control and confirms that the supremum remains at most one game. revision: yes
Circularity Check
No significant circularity; standard recursive expectations with separate numerical verification
full rationale
The paper computes the first-server effect on expected games via recursive expectations over the finite tennis scoring tree (points to games to sets to match) under fixed p and q. These recursions are direct applications of standard Markovian expectation methods and do not reduce to any fitted parameter or self-referential definition. Regions of non-negligible effect follow analytically from comparing the two server-order formulas. The 'at most one game' bound is stated as a numerical confirmation on a grid, not as a derived equality or prediction forced by construction. No self-citations are load-bearing for the central claims, no ansatz is smuggled, and the empirical data comparison is presented as external validation rather than part of the derivation. The analysis is therefore self-contained against external probabilistic benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Each player's serve point win probability remains constant throughout the match.
Reference graph
Works this paper leans on
-
[1]
T. J. Barnett,Mathematical modelling in hierarchical games with specific reference to tennis, Ph.D. Thesis, Swinburne University of Technology, Melbourne, Australia, 2006
2006
-
[2]
T. J. Barnett and S. R. Clarke,Combining player statistics to predict outcomes of tennis matches,IMA Journal of Management Mathematics16(2)(2005), 113–120
2005
-
[3]
W. J. Knottenbelt, D. Spanias and A. M. Madurska,A common-opponent stochastic model for predicting the outcome of professional tennis matches,Computers and Mathematics with Applications64(12)(2012), 3820–3827. 8 A. MOHAMMADI
2012
-
[4]
O’Malley,Probability formulas and statistical analysis in tennis,Journal of Quantitative Analysis in Sports4(2)(2008), 15
A.J. O’Malley,Probability formulas and statistical analysis in tennis,Journal of Quantitative Analysis in Sports4(2)(2008), 15
2008
-
[5]
P. K. Newton and J. B. Keller,Probability of winning at tennis I. Theory and data,Studies in Applied Mathematics114(3)(2005), 241–269
2005
-
[6]
Sackmann,Tennis Match Results Data,https://github.com/jeffsackmann, Accessed: May 2026
J. Sackmann,Tennis Match Results Data,https://github.com/jeffsackmann, Accessed: May 2026. Email address:ali.mohammadi.np@gmail.com
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.