Recognition: unknown
AllSERP: Exhaustive Per-Element Enrichment of the Versatile AdSERP Dataset
Pith reviewed 2026-05-08 16:07 UTC · model grok-4.3
The pith
AllSERP enriches the AdSERP dataset with pixel-accurate bounding boxes and semantic types for every SERP element.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
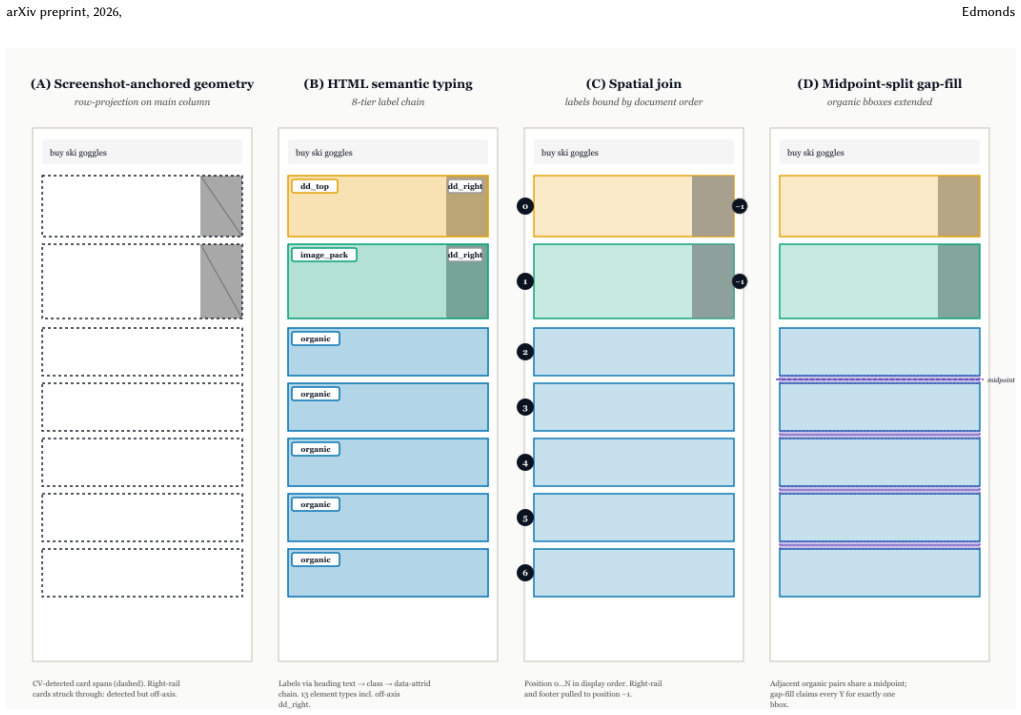
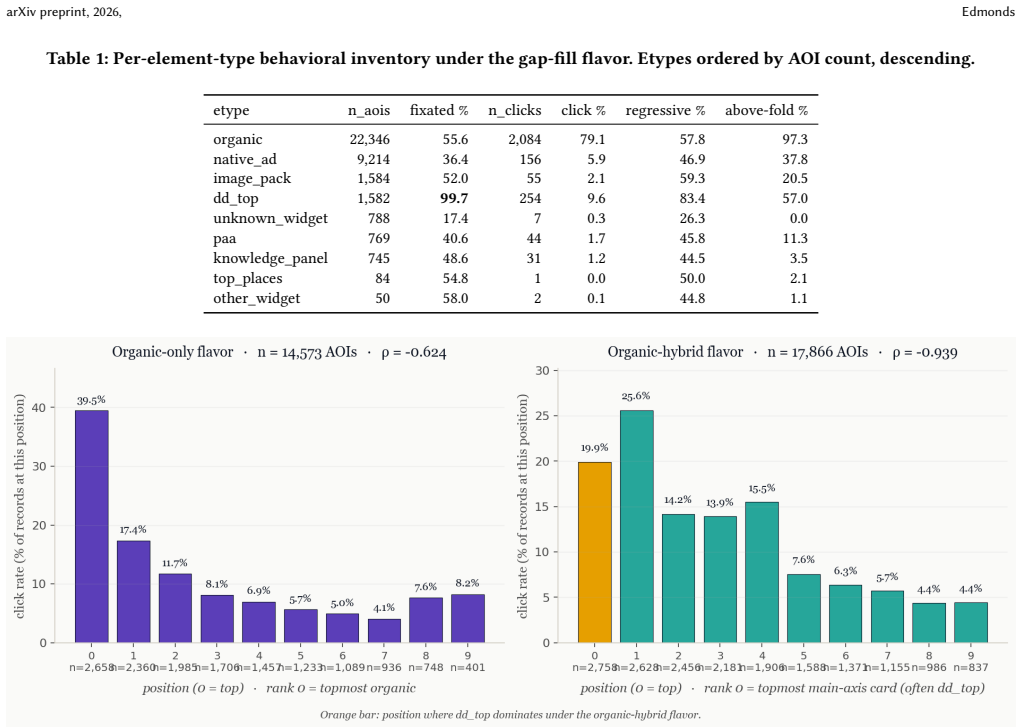
AllSERP augments the AdSERP dataset of 2,776 trials by providing pixel-accurate bounding boxes for organic and widget elements through screenshot-anchored computer vision, semantic typing via HTML parsing into thirteen categories, an inter-result typed gapfill, and click attribution covering 91.7 percent of the corpus while flagging the rest. The ad-versus-non-ad partition agrees perfectly with the shipped ad rectangles across all 38,250 classifications. The release ships the processing pipeline, per-trial JSONs, a corpus CSV, and a browser-based replay viewer, all reproducible from the AdSERP volume.
What carries the argument
Screenshot-anchored computer vision pipeline for extracting pixel-accurate bounding boxes combined with an HTML parser for semantic typing across thirteen element types, plus typed gapfill and X+Y click attribution.
If this is right
- Per-element analyses of clicks, fixations, regressions, and above-fold behavior on SERPs become possible.
- The ad versus non-ad classification matches the original rectangles with zero disagreements.
- All enrichments remain fully reproducible from the AdSERP source using the released pipeline and viewer.
- Organic results, widgets, and ads can now be studied separately in user interaction data.
Where Pith is reading between the lines
- This dataset could support training of models that predict attention or clicks on specific SERP components such as widgets.
- The approach might be extended to SERPs from other engines or eras for comparative studies of user behavior.
- High click attribution opens the door to precise element-level experiments on result layout and ranking effects.
- Combining the labels with the existing eye-tracking signals could reveal new patterns in how users scan different element types.
Load-bearing premise
The computer vision pipeline and HTML parser accurately identify and label all elements without substantial errors or omissions.
What would settle it
Independent manual annotation of bounding boxes and semantic types on a random sample of screenshots that shows significant mismatches with the automated results.
Figures

read the original abstract
We release AllSERP, a typed AOI and per-element behavioral enrichment of the AdSERP commercial-intent SERP corpus [4]. AdSERP ships 2,776 trials of full-page screenshots, captured SERP HTML, 150 Hz Gazepoint eye tracking, evtrack mouse telemetry, scroll, and pupil signals against real Google SERPs collected before AI Overviews -- but its bounding boxes cover only ad surfaces (15.5 % of attributable clicks). AllSERP adds pixel-accurate organic and widget bboxes via screenshot-anchored CV, semantic types across thirteen element types via an HTML parser, an inter-result gap-fill flavor (typed_gapfill), and X+Y click attribution that reaches 91.7 % of the corpus while flagging the rest at trial level. The Phase C ad-vs-non-ad partition is internally consistent with the shipped ad rectangles (0 disagreements across 38,250 classifications). We ship the pipeline, per-trial JSONs, a corpus CSV, and a browser-based replay viewer; everything is reproducible from the AdSERP Zenodo volume. The release enables per-element click, fixation, regression, and above-fold analyses that the shipped ads-vs-organic split could not resolve.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper releases AllSERP, an enrichment of the AdSERP SERP dataset that adds pixel-accurate bounding boxes for organic and widget elements extracted via screenshot-anchored computer vision, semantic typing across thirteen element categories via an HTML parser, a typed_gapfill method for inter-result gaps, and X+Y click attribution covering 91.7% of the corpus (with the remainder flagged at trial level). The authors ship the full processing pipeline, per-trial JSONs, a corpus-level CSV, and a browser-based replay viewer, all reproducible from the original AdSERP Zenodo volume. They additionally report zero disagreements across 38,250 ad vs. non-ad classifications in the Phase C partition.
Significance. If the bounding-box and semantic-typing accuracies are substantiated, AllSERP would enable previously unavailable per-element analyses of clicks, fixations, regressions, and above-the-fold behavior on real Google SERPs. The release of fully reproducible artifacts, the internal ad/non-ad consistency check, and the extension beyond the original 15.5% ad-only attribution constitute clear strengths for the IR community.
major comments (1)
- [Abstract] Abstract: the central claim that the new CV-derived organic/widget bounding boxes and HTML-parser semantic types are 'pixel-accurate' and enable 'reliable per-element analyses' is load-bearing, yet the manuscript reports no precision, recall, IoU, or other quantitative accuracy metrics for these pipelines, nor any independent ground-truth validation set or manual annotation comparison. Only the ad-vs-non-ad partition receives an internal consistency check (0 disagreements on 38,250 cases).
minor comments (2)
- [Abstract] The 2,776-trial count and the original 15.5% ad-attributable-click figure would benefit from explicit cross-reference to a table or methods subsection for quick verification.
- Consider reporting the exact number of elements per semantic type or the distribution of typed_gapfill instances to help readers assess coverage.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive feedback on the manuscript. We address the major comment below and indicate the revisions we will undertake.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the new CV-derived organic/widget bounding boxes and HTML-parser semantic types are 'pixel-accurate' and enable 'reliable per-element analyses' is load-bearing, yet the manuscript reports no precision, recall, IoU, or other quantitative accuracy metrics for these pipelines, nor any independent ground-truth validation set or manual annotation comparison. Only the ad-vs-non-ad partition receives an internal consistency check (0 disagreements on 38,250 cases).
Authors: We agree that the manuscript does not report precision, recall, IoU, or similar quantitative accuracy metrics for the CV-based bounding-box extraction or the HTML-parser semantic typing, and that no independent ground-truth validation set or manual annotation comparison is provided beyond the ad-versus-non-ad internal consistency check. The 'pixel-accurate' phrasing in the abstract is intended to indicate that bounding-box coordinates are obtained directly from pixel-level processing of the screenshots via computer vision, with anchoring to ensure alignment, rather than claiming perfect detection recall. The semantic types are assigned deterministically by a rule-based HTML parser operating on the released DOM structures. The full pipeline, per-trial JSONs, and replay viewer are released precisely so that downstream users can perform or extend such validations themselves. We nonetheless acknowledge the referee's point that explicit metrics would strengthen the load-bearing claims. In the revised version we will add a Methods subsection describing the CV heuristics, anchoring procedure, and parser rules in greater detail, include qualitative examples of extracted elements, and insert a short limitations paragraph clarifying the scope of the internal checks. The abstract language will be adjusted for precision. revision: yes
- We do not have an independent ground-truth validation set or manual annotation results for bounding-box and semantic-type accuracy beyond the ad/non-ad consistency check already reported.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper is a data release describing a processing pipeline that enriches the existing AdSERP corpus with bounding boxes via CV, semantic types via HTML parser, gap-fill, and click attribution. No equations, fitted parameters, predictions, or derivations are present that could reduce to inputs by construction. Internal consistency is noted only for the ad-vs-non-ad partition against shipped rectangles, but this is a verification step rather than a self-referential claim. The work relies on external Zenodo artifacts and prior corpus [4] without any load-bearing self-citation chains or ansatz smuggling. This matches the expected non-circular outcome for a dataset enrichment paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The original AdSERP corpus provides valid full-page screenshots, HTML, eye-tracking, and telemetry data collected before AI Overviews.
Reference graph
Works this paper leans on
-
[1]
Andrew T. Duchowski. 2026. Real-Time Cognitive Load Measurement of Pupillary Oscillation.Proceedings of the ACM on Computer Graphics and Interactive Tech- niques9, 2 (2026). doi:10.1145/3803537 Real-time LF/HF pupil power-ratio: FFT, DWT, and Butterworth IIR variants. Establishes minimum windows from first prin- ciples; Butterworth (1 s window) is the rea...
-
[2]
Wai-Tat Fu and Peter Pirolli. 2007. SNIF-ACT: A Cognitive Model of User Naviga- tion on the World Wide Web.Human-Computer Interaction22, 4 (2007), 355–412. doi:10.1080/07370020701638806 Comprehensive HCI treatment of SNIF-ACT; rational analysis of link-following on web pages
-
[3]
Yasith Jayawardena, Gavindya Jayawardana, and Jacek Gwizdka. 2025. Real-Time Pupillometry-based Index of Pupillary Activity (RIPA2).Journal of Eye Movement Research(2025). Method paper for RIPA2; per-fixation pupil arousal computed from short-window Savitzky-Golay smoothing
2025
-
[4]
Kayhan Latifzadeh, Jacek Gwizdka, and Luis A. Leiva. 2025. A Versatile Dataset of Mouse and Eye Movements on Search Engine Results Pages. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in arXiv preprint, 2026, Edmonds Information Retrieval (SIGIR ’25). ACM, Padua, Italy, 3412–3421. doi:10.1145/3726 302.3730325 Dat...
-
[5]
Peter Pirolli and Stuart Card. 1999. Information Foraging.Psychological Review 106, 4 (1999), 643–675. doi:10.1037/0033-295X.106.4.643 Seminal IFT paper; introduces the information-scent / patch-foraging framework
-
[6]
Mario Villaizán-Vallelado, Matteo Salvatori, Kayhan Latifzadeh, Antonio Penta, Luis A. Leiva, and Ioannis Arapakis. 2025. AdSight: Scalable and Accurate Quantifi- cation of User Attention in Multi-Slot Sponsored Search. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25). ACM, Padua...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.