Recognition: unknown
On the Influence of the Feature Computation Budget on Per-Instance Algorithm Selection for Black-Box Optimization
Pith reviewed 2026-05-08 16:23 UTC · model grok-4.3
The pith
PIAS in black-box optimization remains effective even when a quarter of the budget is spent on features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
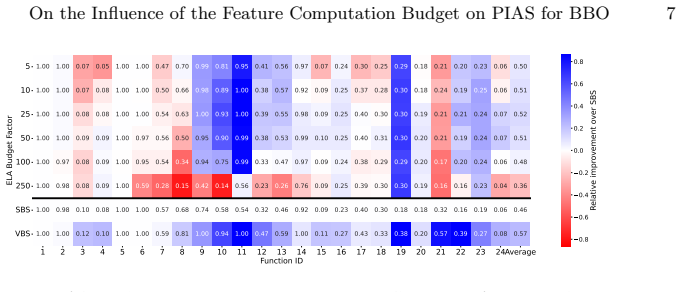
Per-instance algorithm selection based on features computed via sampling from the optimization budget outperforms the single best algorithm in the majority of tested black-box optimization scenarios, even when as much as a quarter of the total budget is allocated to feature computation, with the optimal feature budget fraction depending on the particular algorithm selection scenario and with feature computation explaining on average 20 percent of the performance loss relative to the virtual best solver.
What carries the argument
Per-instance algorithm selection (PIAS) that chooses an algorithm for each instance based on features sampled from the black-box function using a fraction of the evaluation budget.
If this is right
- A substantial share of the optimization budget can be used for features without eliminating the advantage of PIAS over the single best solver.
- The best fraction of budget for feature computation must be selected according to the specific portfolio and problem characteristics.
- Feature computation costs explain a measurable portion of why PIAS does not reach virtual best solver performance.
- PIAS can be considered for black-box problems where the total number of evaluations is strictly limited.
Where Pith is reading between the lines
- More efficient or accurate feature computation techniques could reduce the remaining gap to the virtual best solver.
- Allowing the algorithm selector to adjust the feature budget dynamically during optimization might improve results further.
- The observed viability suggests PIAS could be embedded in practical optimization libraries with automatic budget allocation rules.
Load-bearing premise
That sampling-based feature computation yields features accurate enough for reliable algorithm selection decisions on the tested problem sets.
What would settle it
Finding a set of scenarios where any positive fraction of budget spent on feature computation causes PIAS performance to fall below that of the single best algorithm.
Figures







read the original abstract
Per-instance algorithm selection (PIAS) takes advantage of complementarity between a set of algorithms by deciding which algorithm to run on a given instance. This decision is based on features of the instances, which, in the context of black-box optimization (BBO), require a part of the optimization budget to be computed. This raises two questions: (a) from which fraction of the budget spent on feature computation does PIAS become worth it for BBO, and (b) which fraction of the budget optimizes the tradeoff between feature accuracy and PIAS performance. To this end, we perform a broad study where PIAS with varying sampling budgets for feature computation is compared to the single best algorithm on a broad range of algorithm selection scenarios. These scenarios consist of two portfolio sizes, three problem sets, 4 dimensionalities, and 10 target budgets. We find that PIAS is viable for the majority of tested scenarios, even when as much as a quarter of the total budget is spent on feature computation. The tradeoff for the fraction of the budget spent on feature computation to maximize the benefit of PIAS is highly dependent on the specific AS scenario. Further, on average 20 percent of PIAS loss to the virtual best solver is explained by the budget spent on feature computation, highlighting the importance of properly accounting for the feature budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines how the fraction of the black-box optimization budget allocated to sampling-based instance feature computation affects the performance of per-instance algorithm selection (PIAS) relative to the single best solver. Across experiments with two portfolio sizes, three problem sets, four dimensionalities, and ten target budgets, it reports that PIAS remains viable in the majority of scenarios even at up to 25% feature budget, that the optimal feature-budget fraction is scenario-dependent, and that on average 20% of PIAS loss to the virtual best solver is explained by feature computation cost.
Significance. If robust, the results offer concrete practical guidance on budget allocation when deploying PIAS for black-box optimization, an area where feature costs are often overlooked. The multi-factor experimental design is a strength and supports broader applicability than single-scenario studies. However, the central claims rest on the unverified assumption that low-budget sampling yields sufficiently stable and informative features; without direct fidelity checks this limits the reliability and impact of the viability and loss-attribution findings.
major comments (2)
- [Experimental design / results sections] Experimental design / results sections: No direct validation of sampling-based feature fidelity is reported (e.g., intra-sample variance, correlation with full-budget features, or selector sensitivity to feature perturbation). This is load-bearing for the headline claims, because high variance or bias in low-budget features could cause suboptimal selections, confounding both the reported viability at 25% feature budget and the 20% loss attribution to feature cost.
- [Results presentation] Results presentation: The claims that PIAS is 'viable for the majority of tested scenarios' and that 'on average 20 percent of PIAS loss ... is explained by the budget' are stated without accompanying error bars, statistical significance tests, or per-scenario breakdowns that would allow assessment of consistency across the 2×3×4×10 design.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from an explicit definition of 'viable' (e.g., PIAS outperforming the single best solver by a stated margin on a stated fraction of instances).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional validation and clearer presentation would strengthen the manuscript. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Experimental design / results sections] Experimental design / results sections: No direct validation of sampling-based feature fidelity is reported (e.g., intra-sample variance, correlation with full-budget features, or selector sensitivity to feature perturbation). This is load-bearing for the headline claims, because high variance or bias in low-budget features could cause suboptimal selections, confounding both the reported viability at 25% feature budget and the 20% loss attribution to feature cost.
Authors: We agree that explicit checks on feature fidelity at reduced sampling budgets would improve interpretability of the results. The original experiments emphasize end-to-end PIAS performance across budgets, which provides indirect support for feature utility, but do not include direct fidelity metrics. In the revised manuscript we will add (i) intra-sample variance estimates for the computed features and (ii) correlation analyses between low-budget and full-budget feature vectors on a representative subset of instances. A limited selector-sensitivity analysis under feature perturbation will also be included for selected scenarios. These additions will be reported in a new subsection of the results and will help isolate the contribution of feature noise to the observed performance gaps. revision: partial
-
Referee: [Results presentation] Results presentation: The claims that PIAS is 'viable for the majority of tested scenarios' and that 'on average 20 percent of PIAS loss ... is explained by the budget' are stated without accompanying error bars, statistical significance tests, or per-scenario breakdowns that would allow assessment of consistency across the 2×3×4×10 design.
Authors: We accept that the current presentation lacks the statistical detail needed to evaluate consistency across the full experimental grid. In the revision we will (i) add error bars (standard deviation across independent runs) to all key performance plots and tables, (ii) include per-scenario breakdowns (by portfolio size, problem set, dimensionality, and target budget) either in the main text or as supplementary tables, and (iii) report Wilcoxon signed-rank tests comparing PIAS against the single-best solver, with Holm correction for multiple comparisons. These changes will allow readers to assess both the magnitude and statistical reliability of the reported viability and loss-attribution figures. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential predictions
full rationale
The paper conducts a broad experimental study comparing PIAS performance under varying feature computation budgets against the single best solver across multiple scenarios (portfolios, problem sets, dimensionalities, target budgets). All reported findings, including viability at up to 25% feature budget and the 20% average loss attribution, are direct outputs of these experiments rather than any mathematical derivation, fitted model, or prediction that reduces to the inputs by construction. No equations, ansatzes, uniqueness theorems, or self-citations are invoked as load-bearing steps in a derivation chain. The analysis is self-contained against the performed runs and does not rename known results or smuggle assumptions via prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The algorithms within each portfolio exhibit complementary performance across different problem instances.
Reference graph
Works this paper leans on
-
[1]
Journal of Heuristics29, 1–38 (2023).https://doi
Alissa, M., Sim, K., Hart, E.: Automated algorithm selection: from feature-based to feature-free approaches. Journal of Heuristics29, 1–38 (2023).https://doi. org/10.1007/s10732-022-09505-4
-
[2]
Swarm and Evolution- ary Computation100, 102246 (2026).https://doi.org/10.1016/j.swevo.2025
Andova, A., Cork, J.N., Tuˇ sar, T., Filipiˇ c, B.: A methodology for multi-label algo- rithm selection in constrained multiobjective optimization. Swarm and Evolution- ary Computation100, 102246 (2026).https://doi.org/10.1016/j.swevo.2025. 102246
-
[3]
In: Proceedings of the 14th Annual Conference on Genetic and Evolutionary Computation
Bischl, B., Mersmann, O., Trautmann, H., Preuß, M.: Algorithm selection based on exploratory landscape analysis and cost-sensitive learning. In: Proceedings of the 14th Annual Conference on Genetic and Evolutionary Computation. p. 313–320. GECCO ’12, Association for Computing Machinery, New York, NY, USA (2012). https://doi.org/10.1145/2330163.2330209
-
[4]
Van der Blom, K., Vermetten, D.: On the influence of the feature computation bud- get on per-instance algorithm selection for black-box optimisation - Reproducibility files (Apr 2026).https://doi.org/10.5281/zenodo.19604700
-
[5]
Swarm and Evolutionary Computation101, 102288 (2026)
Cenikj, G., Nikolikj, A., Petelin, G., Van Stein, N., Doerr, C., Eftimov, T.: A survey of features used for representing black-box single-objective continu- ous optimization. Swarm and Evolutionary Computation101, 102288 (2026). https://doi.org/10.1016/j.swevo.2026.102288
-
[6]
Cenikj, G., Petelin, G., Seiler, M., Cenikj, N., Eftimov, T.: Landscape features in single-objective continuous optimization: Have we hit a wall in algorithm selection generalization? Swarm and Evolutionary Computation94, 101894 (2025).https: //doi.org/10.1016/j.swevo.2025.101894
-
[7]
In: Rudolph, G., Kononova, A.V., Aguirre, H., Ker- schke, P., Ochoa, G., Tuˇ sar, T
Dietrich, K., Mersmann, O.: Increasing the diversity of benchmark function sets through affine recombination. In: Rudolph, G., Kononova, A.V., Aguirre, H., Ker- schke, P., Ochoa, G., Tuˇ sar, T. (eds.) Parallel Problem Solving from Nature – PPSN XVII. pp. 590–602. Springer International Publishing, Cham (2022). https://doi.org/10.1007/978-3-031-14714-2_41
-
[8]
Research Report RR-6829, INRIA (2009),https://inria.hal.science/inria-00362633 On the Influence of the Feature Computation Budget on PIAS for BBO 15
Hansen, N., Finck, S., Ros, R., Auger, A.: Real-Parameter Black-Box Optimization Benchmarking 2009: Noiseless Functions Definitions. Research Report RR-6829, INRIA (2009),https://inria.hal.science/inria-00362633 On the Influence of the Feature Computation Budget on PIAS for BBO 15
2009
-
[9]
In: Castillo, P.A., Jim´ enez Laredo, J.L
Jankovic, A., Eftimov, T., Doerr, C.: Towards feature-based performance regression using trajectory data. In: Castillo, P.A., Jim´ enez Laredo, J.L. (eds.) Applications of Evolutionary Computation. pp. 601–617. Springer International Publishing, Cham (2021).https://doi.org/10.1007/978-3-030-72699-7_38
-
[10]
Evolutionary Computation27, 3–45 (2019)
Kerschke, P., Hoos, H.H., Neumann, F., Trautmann, H.: Automated algorithm selection: Survey and perspectives. Evolutionary Computation27, 3–45 (2019). https://doi.org/10.1162/evco_a_00242
-
[11]
Evolutionary Computation27(1), 99–127 (03 2019).https://doi.org/10.1162/ evco_a_00236
Kerschke, P., Trautmann, H.: Automated algorithm selection on continuous black- box problems by combining exploratory landscape analysis and machine learning. Evolutionary Computation27(1), 99–127 (03 2019).https://doi.org/10.1162/ evco_a_00236
2019
-
[12]
arXiv preprint arXiv:2511.12264 (2025).https://doi.org/10.48550/arXiv.2511.12264
Kononova, A.V., van Stein, N., Mersmann, O., B¨ ack, T., Bartz-Beielstein, T., Glasmachers, T., Hellwig, M., Krey, S., Kudela, J., Naujoks, B., et al.: Benchmark- ing that matters: Rethinking benchmarking for practical impact. arXiv preprint arXiv:2511.12264 (2025).https://doi.org/10.48550/arXiv.2511.12264
-
[13]
In: Faust, A., Garnett, R., White, C., Hutter, F., Gardner, J.R
Kostovska, A., Cenikj, G., Vermetten, D., Jankovic, A., Nikolikj, A., Skvorc, U., Korosec, P., Doerr, C., Eftimov, T.: PS-AAS: Portfolio selection for automated algorithm selection in black-box optimization. In: Faust, A., Garnett, R., White, C., Hutter, F., Gardner, J.R. (eds.) Proceedings of the Second International Con- ference on Automated Machine Lea...
2023
-
[14]
In: Rudolph, G., Kononova, A.V., Aguirre, H., Kerschke, P., Ochoa, G., Tuˇ sar, T
Kostovska, A., Jankovic, A., Vermetten, D., de Nobel, J., Wang, H., Eftimov, T., Doerr, C.: Per-run algorithm selection with warm-starting using trajectory- based features. In: Rudolph, G., Kononova, A.V., Aguirre, H., Kerschke, P., Ochoa, G., Tuˇ sar, T. (eds.) Parallel Problem Solving from Nature – PPSN XVII. LNCS, vol. 13398, pp. 46–60. Springer Intern...
-
[15]
L´ opez-Ib´ a˜ nez, M., Vermetten, D., Dreo, J., Doerr, C.: Using the empirical attain- ment function for analyzing single-objective black-box optimization algorithms. IEEE Transactions on Evolutionary Computation29(5), 1774–1782 (2025).https: //doi.org/10.1109/TEVC.2024.3462758
-
[16]
In: Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation
Mersmann, O., Bischl, B., Trautmann, H., Preuss, M., Weihs, C., Rudolph, G.: Exploratory landscape analysis. In: Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation. pp. 829–836. GECCO ’11, Association for Computing Machinery, New York, NY, USA (2011).https://doi.org/10.1145/ 2001576.2001690
-
[17]
Mu˜ noz, M.A., Sun, Y., Kirley, M., Halgamuge, S.K.: Algorithm selection for black- box continuous optimization problems: A survey on methods and challenges. Inf. Sci.317, 224–245 (2015).https://doi.org/10.1016/J.INS.2015.05.010
-
[18]
Evolutionary Computation32(3), 205–210 (09 2024).https://doi.org/10.1162/evco_a_00342
de Nobel, J., Ye, F., Vermetten, D., Wang, H., Doerr, C., B¨ ack, T.: IOHexperi- menter: Benchmarking platform for iterative optimization heuristics. Evolutionary Computation32(3), 205–210 (09 2024).https://doi.org/10.1162/evco_a_00342
-
[19]
Journal of Machine Learning Research12, 2825–2830 (2011)
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., Duchesnay, E.: Scikit-learn: Machine learning in Python. Journal of Machine Learning Research12, 2825–2830 (2011)
2011
-
[20]
In: Correia, J., Smith, S., Qaddoura, R
Prager, R.P., Trautmann, H.: Nullifying the inherent bias of non-invariant ex- ploratory landscape analysis features. In: Correia, J., Smith, S., Qaddoura, R. (eds.) Applications of Evolutionary Computation. pp. 411–425. Springer Nature Switzerland, Cham (2023).https://doi.org/10.1007/978-3-031-30229-9_27 16 Koen van der Blom and Diederick Vermetten
-
[21]
Evolutionary Computation 32(3), 211–216 (09 2024).https://doi.org/10.1162/evco_a_00341
Prager, R.P., Trautmann, H.: Pflacco: Feature-based landscape analysis of continu- ous and constrained optimization problems in Python. Evolutionary Computation 32(3), 211–216 (09 2024).https://doi.org/10.1162/evco_a_00341
-
[22]
Rapin, J., Teytaud, O.: Nevergrad - A gradient-free optimization platform.https: //GitHub.com/FacebookResearch/Nevergrad(2018)
2018
-
[23]
In: Proceedings of the Genetic and Evolutionary Computation Conference Companion
Renau, Q., Dreo, J., Doerr, C., Doerr, B.: Expressiveness and robustness of land- scape features. In: Proceedings of the Genetic and Evolutionary Computation Conference Companion. pp. 2048–2051. GECCO ’19, Association for Comput- ing Machinery, New York, NY, USA (2019).https://doi.org/10.1145/3319619. 3326913
-
[24]
In: Castillo, P.A., Jim´ enez Laredo, J.L
Renau, Q., Dr´ eo, J., Doerr, C., Doerr, B.: Towards explainable exploratory land- scape analysis: Extreme feature selection for classifying BBOB functions. In: Castillo, P.A., Jim´ enez Laredo, J.L. (eds.) Applications of Evolutionary Com- putation. pp. 17–33. Springer International Publishing, Cham (2021).https: //doi.org/10.1007/978-3-030-72699-7_2
-
[25]
In: Smith, S., Correia, J., Cintrano, C
Renau, Q., Hart, E.: On the utility of probing trajectories for algorithm-selection. In: Smith, S., Correia, J., Cintrano, C. (eds.) Applications of Evolutionary Com- putation. pp. 98–114. Springer Nature Switzerland, Cham (2024).https://doi. org/10.1007/978-3-031-56852-7_7
-
[26]
In: Advances in computers, vol
Rice, J.R.: The algorithm selection problem. In: Advances in computers, vol. 15, pp. 65–118. Elsevier (1976).https://doi.org/10.1016/S0065-2458(08)60520-3
-
[27]
Seiler, M.V., Kerschke, P., Trautmann, H.: Deep-ELA: Deep exploratory landscape analysis with self-supervised pretrained transformers for single- and multi-objective continuous optimization problems. Evolutionary Computation pp. 1–27 (02 2025). https://doi.org/10.1162/evco_a_00367
-
[28]
In: Proceedings of the Genetic and Evolutionary Compu- tation Conference
Seiler, M.V., Preuß, O.L., Trautmann, H.: RandOptGen: A unified random prob- lem generator for single- and multi-objective optimization problems with mixed- variable input spaces. In: Proceedings of the Genetic and Evolutionary Compu- tation Conference. p. 76–84. GECCO ’25, Association for Computing Machinery, New York, NY, USA (2025).https://doi.org/10.1...
-
[29]
In: In Contributions to the Theory of Games, volume II, pp
Shapley, L.S.: A value for n-person games. In: In Contributions to the Theory of Games, volume II, pp. 307–317. Princeton University Press. (1953)
1953
-
[30]
In: Singh, H., Ray, T., Knowles, J., Li, X., Branke, J., Wang, B., Oyama, A
Vermetten, D., Rook, J., Preuß, O.L., de Nobel, J., Doerr, C., L´ opez-Iba˜ nez, M., Trautmann, H., B¨ ack, T.: MO-IOHinspector: Anytime benchmarking of multi- objective algorithms using IOHprofiler. In: Singh, H., Ray, T., Knowles, J., Li, X., Branke, J., Wang, B., Oyama, A. (eds.) Evolutionary Multi-Criterion Op- timization. pp. 242–256. Springer Nature...
-
[31]
Vermetten, D., Ye, F., B¨ ack, T., Doerr, C.: MA-BBOB: A problem generator for black-box optimization using affine combinations and shifts. ACM Trans. Evol. Learn. Optim.5(1) (Mar 2025).https://doi.org/10.1145/3673908
-
[32]
University of British Columbia,, Tech
Xu, L., Hutter, F., Hoos, H., Leyton-Brown, K.: Features for SAT. University of British Columbia,, Tech. Rep (2012)
2012
-
[33]
Journal of Artificial Intelligence Research32, 565–606 (2008).https://doi.org/10.1613/jair.2490
Xu, L., Hutter, F., Hoos, H.H., Leyton-Brown, K.: SATzilla: Portfolio-based al- gorithm selection for SAT. Journal of Artificial Intelligence Research32, 565–606 (2008).https://doi.org/10.1613/jair.2490
-
[34]
In: Proceedings of the 18th RCRA Workshop on Experimental Evaluation of Algorithms for Solving Problems with Combinatorial Explosion (RCRA 2011)
Xu, L., Hutter, F., Hoos, H.H., Leyton-Brown, K.: Hydra-MIP: Automated algo- rithm configuration and selection for mixed integer programming. In: Proceedings of the 18th RCRA Workshop on Experimental Evaluation of Algorithms for Solving Problems with Combinatorial Explosion (RCRA 2011). pp. 16–30 (2011)
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.