Recognition: 1 theorem link
· Lean TheoremKernelBenchX: A Comprehensive Benchmark for Evaluating LLM-Generated GPU Kernels
Pith reviewed 2026-05-12 04:04 UTC · model grok-4.3
The pith
Task category explains nearly three times more variance in LLM GPU kernel correctness than the generation method used.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
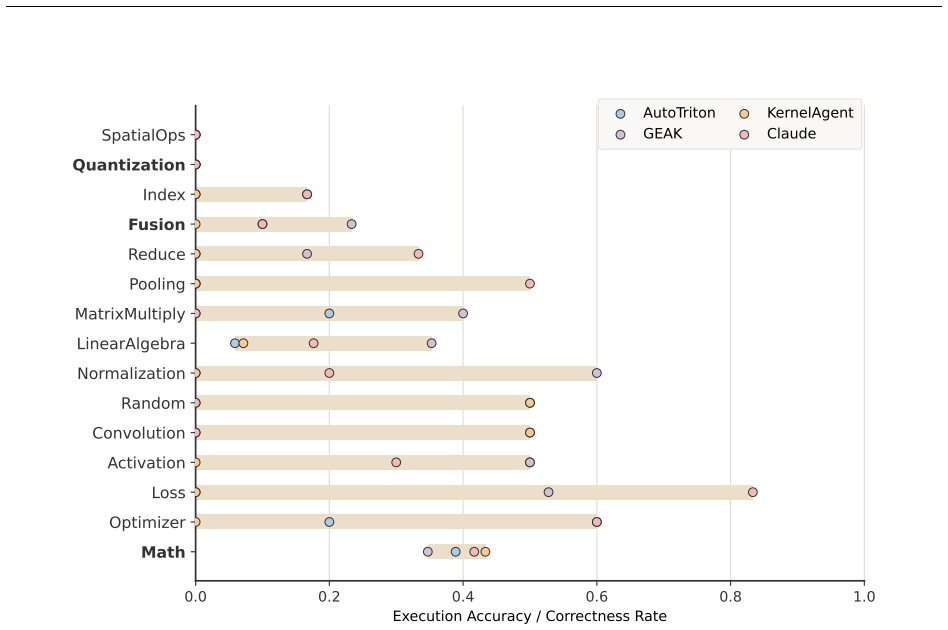
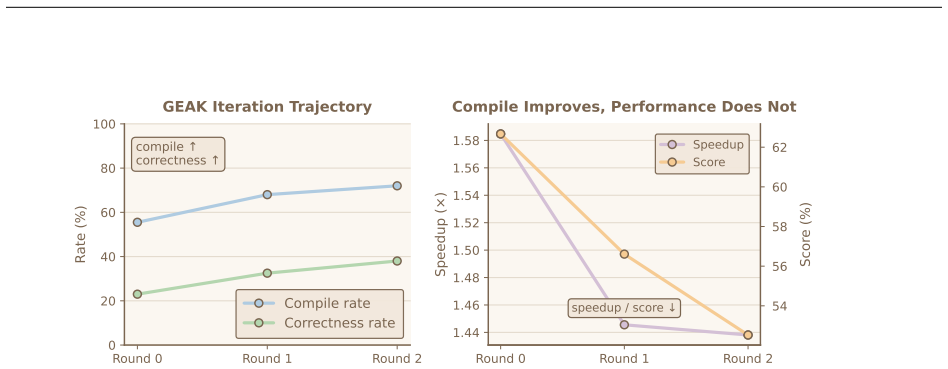
Task structure determines correctness more than method design. Category explains nearly three times more variance in semantic correctness than method (9.4 percent versus 3.3 percent explained deviance). Iterative refinement improves correctness but not performance, with newly rescued kernels underperforming persistently correct ones. Correctness does not imply efficiency, as 46.6 percent of correct kernels are slower than the PyTorch eager baseline and quantization remains unsolved at zero of 30 successes.
What carries the argument
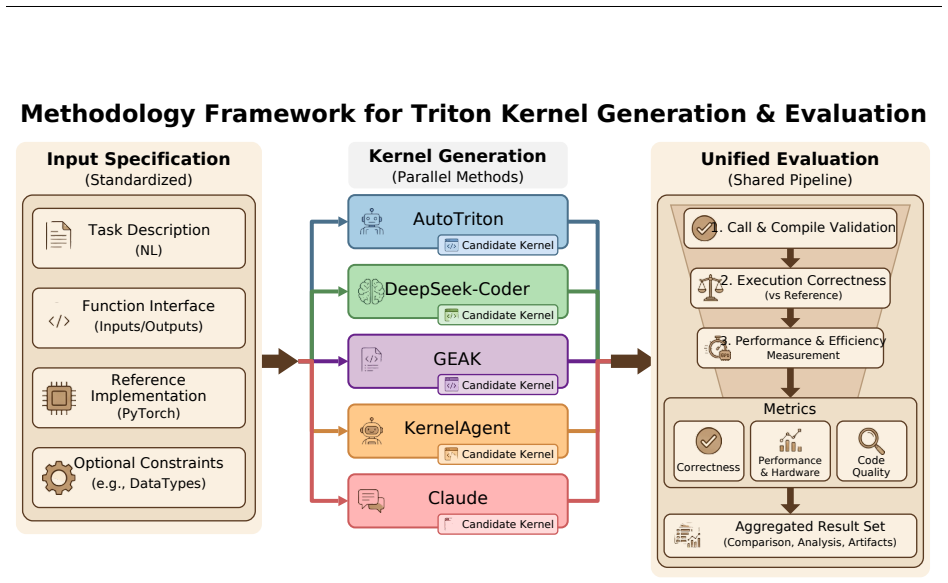
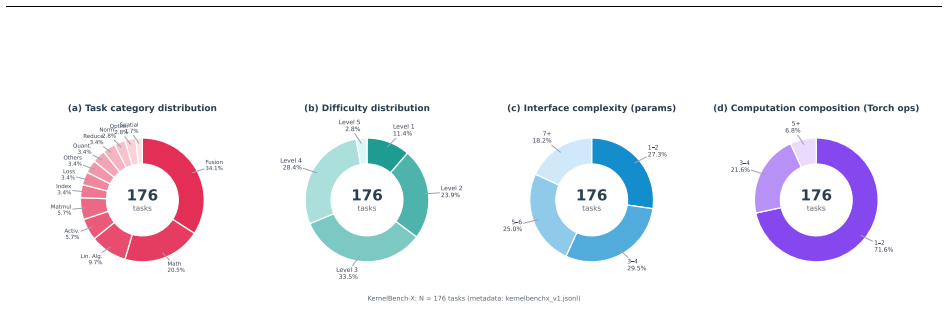
KernelBenchX, a category-aware benchmark of 176 tasks across 15 categories that measures semantic correctness, compile rate, and hardware speedup for LLM-generated GPU kernels.
If this is right
- Future generation methods must target global coordination and numerical precision modeling rather than surface syntax.
- Benchmarks should evaluate correctness and hardware efficiency as separate dimensions.
- Iterative refinement alone cannot close the performance gap between rescued and persistently correct kernels.
- Quantization tasks expose systematic gaps in numerical contract understanding that current methods do not address.
Where Pith is reading between the lines
- Practical LLM kernel tools may work best when restricted to categories that already show high success rates, such as math tasks.
- Hybrid systems that combine LLM generation with post-generation optimization passes could mitigate the efficiency shortfall observed here.
- Extending the benchmark to additional hardware platforms would test whether the category dominance pattern holds beyond the reported cross-hardware variance.
Load-bearing premise
The 176 tasks and five methods chosen are representative enough of real-world LLM kernel generation to support general claims about where capabilities break down.
What would settle it
A new collection of tasks within the same 15 categories, tested with the same five methods, that shows method choice explaining more variance in correctness than category does.
Figures

read the original abstract
LLM-based Triton kernel generation has attracted significant interest, yet a fundamental empirical question remains unanswered: where does this capability break down, and why? We present KernelBenchX, a benchmark designed to answer this question through category-aware evaluation of correctness and hardware efficiency across 176 tasks in 15 categories. Our systematic comparison of five representative methods yields three main findings. First, task structure determines correctness more than method design. Category explains nearly three times more variance in semantic correctness than method (9.4% vs 3.3% explained deviance), and 72% of Fusion tasks fail across all five methods while Math tasks are solved consistently. Second, iterative refinement improves correctness, but not performance. Across GEAK iterations, compile rate rises from 52.3% to 68.8% while average speedup declines from $1.58\times$ to $1.44\times$; newly rescued kernels consistently underperform persistently correct ones ($1.16\times$ vs $1.58\times$ speedup in round~0$\to$1). Third, correctness does not imply efficiency. 46.6% of correct kernels are slower than the PyTorch eager baseline, and cross-hardware speedup variance reaches $21.4\times$. Besides, quantization remains completely unsolved (0/30 successes) despite non-trivial compilation rates, revealing systematic misunderstanding of numerical computation contracts rather than surface-level syntax errors. These findings suggest that future progress depends on handling global coordination, explicitly modeling numerical precision, and incorporating hardware efficiency into generation. The code is available at https://github.com/BonnieW05/KernelBenchX
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KernelBenchX, a benchmark of 176 tasks across 15 categories for evaluating LLM-generated Triton GPU kernels. It systematically compares five representative methods and reports three findings: (1) task category explains nearly three times more variance in semantic correctness than method choice (9.4% vs 3.3% explained deviance), with 72% of Fusion tasks failing across all methods while Math tasks succeed consistently; (2) iterative refinement (e.g., GEAK iterations) raises compile rates from 52.3% to 68.8% but lowers average speedup from 1.58× to 1.44×; (3) correctness does not imply efficiency, as 46.6% of correct kernels underperform the PyTorch baseline, cross-hardware speedup variance reaches 21.4×, and quantization yields 0/30 successes. Code is released at the provided GitHub link.
Significance. If the variance decomposition and failure-mode statistics hold under scrutiny, the work offers a concrete empirical map of current limitations in LLM kernel generation, underscoring the primacy of task structure, the limited benefit of iteration for performance, and the gap between syntactic correctness and hardware efficiency. The release of the benchmark, concrete statistics on variance and failure rates, and open code constitute clear strengths that could inform targeted improvements in modeling global coordination and numerical contracts.
major comments (1)
- [Abstract] Abstract (and the variance analysis section): the central claim that category explains nearly three times more variance than method (9.4% vs 3.3% explained deviance) is load-bearing for the first finding, yet the manuscript provides no equation, model specification (e.g., GLM deviance, pseudo-R², logistic regression), or adjustment for degrees of freedom. With 15 categories (~14 df) versus 5 methods (4 df), the raw deviance ratio may be inflated by factor complexity rather than reflecting substantive dominance; the stress-test concern is therefore material and requires explicit resolution.
minor comments (2)
- The description of the 176 tasks and 15 category definitions should include explicit criteria or examples to allow readers to assess representativeness, which underpins the generalizability of all three findings.
- Notation such as 'round~0→1' and the exact definition of 'newly rescued kernels' versus 'persistently correct ones' could be clarified for precision.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the benchmark's value in mapping limitations of LLM kernel generation. We address the single major comment below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the variance analysis section): the central claim that category explains nearly three times more variance than method (9.4% vs 3.3% explained deviance) is load-bearing for the first finding, yet the manuscript provides no equation, model specification (e.g., GLM deviance, pseudo-R², logistic regression), or adjustment for degrees of freedom. With 15 categories (~14 df) versus 5 methods (4 df), the raw deviance ratio may be inflated by factor complexity rather than reflecting substantive dominance; the stress-test concern is therefore material and requires explicit resolution.
Authors: We agree that the variance analysis requires explicit model specification and equation for reproducibility and to address the degrees-of-freedom concern. Semantic correctness is a binary outcome across task-method pairs. We fit separate generalized linear models (binomial family, logit link) for category alone and for method alone, then compute explained deviance as (null deviance - model deviance) / null deviance. The equation is: explained_deviance = 1 - (D_model / D_null). No df adjustment was applied in the reported figures because the intent was to compare raw explanatory power on this fixed dataset. We acknowledge that the higher df for categories could contribute to the observed ratio and will add both the full specification and an adjusted comparison (e.g., deviance per df and McFadden's pseudo-R²) in the revision to confirm category dominance is not an artifact of complexity. The revised abstract and methods section will include these details. revision: yes
Circularity Check
No circularity: empirical benchmark results derived directly from experimental data
full rationale
The paper presents an empirical benchmark study involving direct execution and evaluation of 176 tasks across 15 categories using five LLM-based kernel generation methods. All reported findings, including the variance decomposition (9.4% vs 3.3% explained deviance for category versus method in semantic correctness), the failure rates per category, and the effects of iterative refinement, are computed from the observed outcomes of these runs. No derivations, equations, or claims reduce to self-definitional inputs, fitted parameters renamed as predictions, or load-bearing self-citations. The analysis is self-contained against the collected data matrix without any reduction by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Category definitions
axioms (1)
- domain assumption The 176 tasks and 15 categories are representative of real-world GPU kernel generation challenges for LLMs.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclearCategory explains nearly three times more variance in semantic correctness than method (9.4% vs 3.3% explained deviance)
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Stark: Strategic team of agents for refining kernels.arXiv preprint arXiv:2510.16996,
Juncheng Dong, Yang Yang, Tao Liu, Yang Wang, Feng Qi, Vahid Tarokh, Kaushik Rangadurai, and Shuang Yang. Stark: Strategic team of agents for refining kernels.arXiv preprint arXiv:2510.16996,
-
[3]
JunfengGong, ZhiyiWei, JunyingChen, ChengLiu, andHuaweiLi. Fromlargetosmall: Transferring cuda optimization expertise via reasoning graph.arXiv preprint arXiv:2510.19873,
-
[4]
Robert Tjarko Lange, Qi Sun, Aaditya Prasad, Maxence Faldor, Yujin Tang, and David Ha. Towards robust agentic cuda kernel benchmarking, verification, and optimization.arXiv preprint arXiv:2509.14279,
-
[5]
Tritonbench: Benchmarking large language model capabilities for generating triton operators
JianlingLi, ShangzhanLi, ZhenyeGao, QiShi, YuxuanLi, ZefanWang, JiachengHuang, WangHaojie WangHaojie, Jianrong Wang, Xu Han, et al. Tritonbench: Benchmarking large language model capabilities for generating triton operators. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 23053–23066, 2025a. Shangzhan Li, Zefan Wang, Ye He, Yuxu...
-
[6]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Anne Ouyang, Simon Guo, Simran Arora, Alex L Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. Kernelbench: Can llms write efficient gpu kernels?arXiv preprint arXiv:2502.10517,
-
[8]
arXiv:2507.23194 [cs.CL] https://arxiv.org/abs/2507.23194
Jianghui Wang, Vinay Joshi, Saptarshi Majumder, Xu Chao, Bin Ding, Ziqiong Liu, Pratik Prab- hanjan Brahma, Dong Li, Zicheng Liu, and Emad Barsoum. Geak: Introducing triton kernel ai agent & evaluation benchmarks.arXiv preprint arXiv:2507.23194,
-
[9]
Tritonrl: Training llms to think and code triton without cheating.arXiv preprint arXiv:2510.17891,
Jiin Woo, Shaowei Zhu, Allen Nie, Zhen Jia, Yida Wang, and Youngsuk Park. Tritonrl: Training llms to think and code triton without cheating.arXiv preprint arXiv:2510.17891,
-
[10]
Towards automated kernel generation in the era of llms.arXiv preprint arXiv:2601.15727,
Yang Yu, Peiyu Zang, Chi Hsu Tsai, Haiming Wu, Yixin Shen, Jialing Zhang, Haoyu Wang, Zhiyou Xiao, Jingze Shi, Yuyu Luo, et al. Towards automated kernel generation in the era of llms.arXiv preprint arXiv:2601.15727,
-
[11]
Efficient attention methods: Hardware- efficient, sparse, compact, and linear attention
Jintao Zhang, Rundong Su, Chunyu Liu, Jia Wei, Ziteng Wang, Haoxu Wang, Pengle Zhang, Huiqiang Jiang, Haofeng Huang, Chendong Xiang, et al. Efficient attention methods: Hardware- efficient, sparse, compact, and linear attention. a. Jintao Zhang, Pengle Zhang, Jun Zhu, Jianfei Chen, et al. Sageattention: Accurate 8-bit attention for plug-and-play inference...
-
[12]
Jintao Zhang, Haoxu Wang, Kai Jiang, Shuo Yang, Kaiwen Zheng, Haocheng Xi, Ziteng Wang, Hongzhou Zhu, Min Zhao, Ion Stoica, et al. Sla: Beyond sparsity in diffusion transformers via fine-tunable sparse-linear attention.arXiv preprint arXiv:2509.24006, 2025a. Jintao Zhang, Jia Wei, Pengle Zhang, Xiaoming Xu, Haofeng Huang, Haoxu Wang, Kai Jiang, Jun Zhu, a...
-
[13]
All proxies correlate only modestly with correctness failure, and are more predictive of compile failure than semantic failure. This confirms that the benchmark’s correctness boundary is structural but not reducible to superficial measures of reference-code complexity. 14 Table 3: Per-category semantic correctness rates (%) for all benchmark categories. C...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.